当前位置:网站首页>2、 Training fashion_ MNIST dataset
2、 Training fashion_ MNIST dataset
2022-06-25 08:51:00 【Beyond proverb】
One 、 load fashion_mnist Data sets
fashion_mnist The data in the dataset is 28*28 The size of 10 Classified clothing dataset
One of the training sets 60000 Zhang , Test set 10000 Zhang
from tensorflow import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
fashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
print(train_images.shape)
""" (60000, 28, 28) """
print(test_images.shape)
""" (10000, 28, 28) """
print(train_labels.shape)
""" (60000,) """
print(test_labels.shape)
""" (60000,) """
Just look at the pixel value to see if you can guess what this picture is ?
print(train_images[0])# Look at the first picture of the training set 28*28 Pixel value
""" [[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3] [ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15] [ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66] [ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0] [ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52] [ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56] [ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0] [ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0] [ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0] [ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0] [ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0] [ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0] [ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29] [ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67] [ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115] [ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92] [ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0] [ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0] [ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] """
Output the following photo
plt.imshow(train_images[0])
Two 、 Start training model
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),# The photo is completely flattened , One dimensional array form
keras.layers.Dense(128,activation=tf.nn.relu),#128 Neurons
keras.layers.Dense(10,activation=tf.nn.softmax)# Output layer 0-9, Ten altogether
])
Look at the structure of the model
first floor 784 individual ,flatten Layer to be imported 2828 Expand the image , Line up ,2828=784
The second floor 128 individual ,128 Neurons ;100480 Parameters , First floor 784 And the second floor 128 Full Permutation ,784*128=100352, Each one has a bias Bias term ,100352+128=100480
The third level 10 individual , That is to say 10 classification ,10 Different categories , Output at that time 10 Probability values , What is big is what kind ;1290 Parameters , The second floor 128 Neurons , They are different from 10 Make a full arrangement ,128*10=1280, Each one has a bias Bias term ,1280+10=1290
model.summary()
""" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 _________________________________________________________________ dense (Dense) (None, 128) 100480 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________ """
In order to make the effect better , Normalize the image pixel values in the data set to 0-1 Between
train_images_y = train_images/255# Normalize the training image
Training 50 Time
model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=['accuracy'])# Specify optimization method and loss function
model.fit(train_images_y,train_labels,epochs=50)# Training
Because the normalized image of the training set is transmitted during model training
so , During model evaluation, it is also necessary to normalize the test set
test_images_y = test_images/255# The test image should also be normalized during test evaluation
model.evaluate(test_images_y,test_labels)#evaluate Evaluation effect
""" [0.5110174604289234, 0.8845] """
Select a few from the test set to test , It actually outputs 10 It's worth , That is, the probability of probability , The biggest is the category of forecasts
model.predict([[test_images[0]/255]])
""" array([[2.2063166e-16, 1.1835037e-17, 7.4574429e-23, 2.0577940e-22, 4.3680589e-17, 2.7080047e-08, 3.8249505e-15, 3.4797877e-06, 1.4701404e-10, 9.9999654e-01]], dtype=float32) """
The one with the largest predicted value by the screening model
print(np.argmax(model.predict([[test_images[0]/255]])))
""" 9 """
Look at the actual label of this picture
print(test_labels[0])
""" 9 """
The predicted value is the same as the actual value , It shows that the prediction is correct
Show me this picture
plt.imshow(train_images[0])

边栏推荐
- 《乔布斯传》英文原著重点词汇笔记(一)【 Introduction 】
- 打新债安全性有多高啊
- 故障:Outlook 收发邮件时的 0x800CCC1A 错误
- Is it really safe to pay new debts? Is it risky
- 《乔布斯传》英文原著重点词汇笔记(二)【 chapter one】
- Easyplayer streaming media player plays HLS video. Technical optimization of slow starting speed
- 声纹技术(四):声纹识别的工程部署
- How to implement a system call
- Hyper-v:Hyper-v 第 1 代或第 2 代虚拟机
- 紧急行政中止令下达 Juul暂时可以继续在美国销售电子烟产品
猜你喜欢

cazy長安戰役八卦迷宮

C language: find all integers that can divide y and are odd numbers, and put them in the array indicated by B in the order from small to large

Fault: 0x800ccc1a error when outlook sends and receives mail
二、训练fashion_mnist数据集

五、项目实战---识别人和马

Wechat applet_ 7. Project practice, local life

C#启动程序传递参数丢失双引号,如何解决?
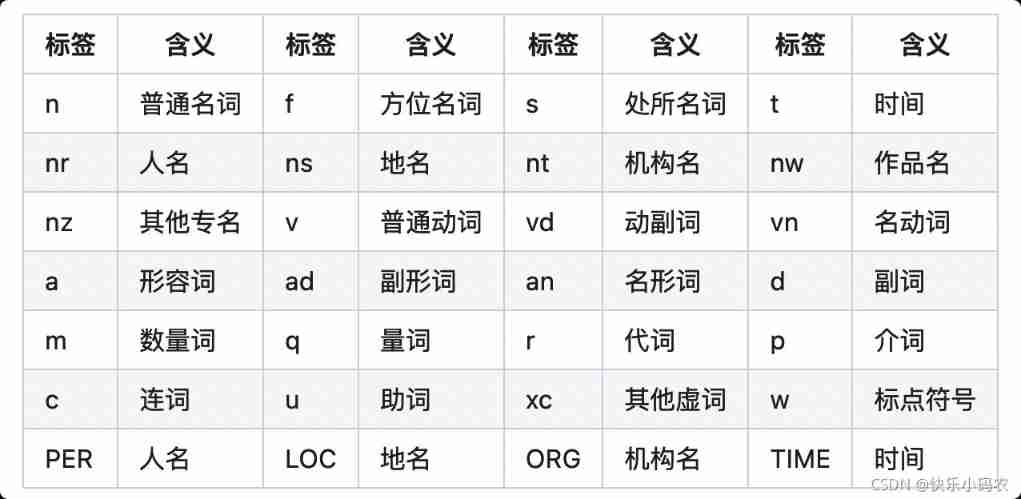
Meaning of Jieba participle part of speech tagging

Exchange: manage calendar permissions

Summary of NLP data enhancement methods
随机推荐
C program termination problem clr20r3 solution
Trendmicro:apex one server tools folder
【强化学习笔记】强化学习中的常见符号
Meaning of Jieba participle part of speech tagging
关于I/O——内存与CPU与磁盘之间的关系
Jmeter中的断言使用讲解
第十五周作业
Sampling strategy and decoding strategy based on seq2seq text generation
城链科技平台,正在实现真正意义上的价值互联网重构!
对常用I/O模型进行比较说明
《乔布斯传》英文原著重点词汇笔记(二)【 chapter one】
LVS-DR模式单网段案例
【OpenCV】—输入输出XML和YAML文件
Swiperefreshlayout+recyclerview failed to pull down troubleshooting
Is it safe to buy stocks and open accounts through the account QR code of the account manager? Want to open an account for stock trading
Fault: 0x800ccc1a error when outlook sends and receives mail
Notes on key words in the original English work biography of jobs (IV) [chapter two]
C language: count the number of characters, numbers and spaces
【MYSQL】索引的理解和使用
城鏈科技平臺,正在實現真正意義上的價值互聯網重構!