当前位置:网站首页>二、训练fashion_mnist数据集
二、训练fashion_mnist数据集
2022-06-25 07:56:00 【beyond谚语】
一、加载fashion_mnist数据集
fashion_mnist数据集中数据为28*28大小的10分类衣物数据集
其中训练集60000张,测试集10000张
from tensorflow import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
fashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
print(train_images.shape)
""" (60000, 28, 28) """
print(test_images.shape)
""" (10000, 28, 28) """
print(train_labels.shape)
""" (60000,) """
print(test_labels.shape)
""" (60000,) """
光看像素值是不是能猜到这个图片是啥了?
print(train_images[0])#看一下训练集第一张图片28*28像素点的值
""" [[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0 0 1 4 0 0 0 0 1 1 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62 54 0 0 0 1 3 4 0 0 3] [ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134 144 123 23 0 0 0 0 12 10 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178 107 156 161 109 64 23 77 130 72 15] [ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216 216 163 127 121 122 146 141 88 172 66] [ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229 223 223 215 213 164 127 123 196 229 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228 235 227 224 222 224 221 223 245 173 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198 180 212 210 211 213 223 220 243 202 0] [ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192 169 227 208 218 224 212 226 197 209 52] [ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203 198 221 215 213 222 220 245 119 167 56] [ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240 232 213 218 223 234 217 217 209 92 0] [ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219 222 221 216 223 229 215 218 255 77 0] [ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208 211 218 224 223 219 215 224 244 159 0] [ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230 224 234 176 188 250 248 233 238 215 0] [ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223 255 255 221 234 221 211 220 232 246 0] [ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221 188 154 191 210 204 209 222 228 225 0] [ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117 168 219 221 215 217 223 223 224 229 29] [ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245 239 223 218 212 209 222 220 221 230 67] [ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216 199 206 186 181 177 172 181 205 206 115] [ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191 195 191 198 192 176 156 167 177 210 92] [ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209 210 210 211 188 188 194 192 216 170 0] [ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179 182 182 181 176 166 168 99 58 0 0] [ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] """
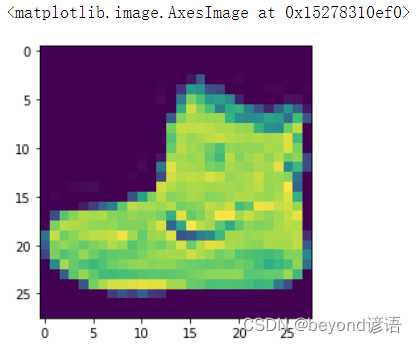
输出以下这个照片
plt.imshow(train_images[0])
二、开始训练模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)),#照片完全展平,一维数组形式
keras.layers.Dense(128,activation=tf.nn.relu),#128个神经元
keras.layers.Dense(10,activation=tf.nn.softmax)#输出层0-9,一共十个
])
查看模型的结构
第一层784个,flatten层将输入的2828图像进行展开,排列成一行,2828=784
第二层128个,128个神经元;100480个参数,第一层的784和第二层的128全排列,784*128=100352,每一个都有一个bias偏置项,100352+128=100480
第三层10个,也就是10分类,10个不同的类别,到时候输出10个概率值,哪个大就是哪一类;1290个参数,第二层128个神经元,分别于10进行全排列,128*10=1280,每一个都有一个bias偏置项,1280+10=1290
model.summary()
""" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 _________________________________________________________________ dense (Dense) (None, 128) 100480 _________________________________________________________________ dense_1 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________ """
为了使得效果更好,将数据集中的图像像素值都归一化到0-1之间
train_images_y = train_images/255#对训练图像归一化
训练50次
model.compile(optimizer="adam",loss="sparse_categorical_crossentropy",metrics=['accuracy'])#指定优化方法和损失函数
model.fit(train_images_y,train_labels,epochs=50)#训练
因为模型训练的时候传入的时训练集归一化之后的图像
故,模型评估的时候也需要对测试集进行归一化图像
test_images_y = test_images/255#测试评估的时候需要对测试图像也要归一化
model.evaluate(test_images_y,test_labels)#evaluate评估效果
""" [0.5110174604289234, 0.8845] """
从测试集中挑选几个进行测试,实际上会输出10个值,也就是可能性的概率值,最大的就是预测的类别
model.predict([[test_images[0]/255]])
""" array([[2.2063166e-16, 1.1835037e-17, 7.4574429e-23, 2.0577940e-22, 4.3680589e-17, 2.7080047e-08, 3.8249505e-15, 3.4797877e-06, 1.4701404e-10, 9.9999654e-01]], dtype=float32) """
筛选模型预测出的值最大的那个
print(np.argmax(model.predict([[test_images[0]/255]])))
""" 9 """
看下这个图片的实际标签
print(test_labels[0])
""" 9 """
预测值和实际值一样,说明预测对了
展示下这个图片
plt.imshow(train_images[0])

边栏推荐
- 城链科技平台,正在实现真正意义上的价值互联网重构!
- LVS-DR模式单网段案例
- tp6自动执行的文件是哪个?tp6核心类库有什么作用呢?
- Trendmicro:apex one server tools folder
- Check whether the point is within the polygon
- Is there any risk in the security of new bonds
- SharePoint:SharePoint Server 2013 与 ADRMS 集成指南
- leetcode. 13 --- Roman numeral to integer
- 初识生成对抗网络(12)——利用Pytorch搭建WGAN-GP生成手写数字
- 如何实现一个系统调用
猜你喜欢

How to calculate the correlation coefficient and correlation degree in grey correlation analysis?

What are the indicators of VIKOR compromise?

How to become a software testing expert? From 3K to 17k a month, what have I done?

《树莓派项目实战》第五节 使用Nokia 5110液晶屏显示Hello World

InfluxDB时序数据库

声纹技术(六):声纹技术的其他应用
UEFI:修复 EFI/GPT Bootloader

(翻译)采用字母间距提高全大写文本可读性的方式

How to interpret the information weight index?

LVS-DR模式多网段案例
随机推荐
On which platform is it safe to buy shares and open an account? Ask for sharing
What does openid mean? What does "token" mean?
The city chain technology platform is realizing the real value Internet reconstruction!
City Chain technology platform, really Realizing value Internet reconstruction!
Retrieval model rough hnsw
cazy长安战役八卦迷宫
Fault: 0x800ccc1a error when outlook sends and receives mail
C language "recursive series": recursive implementation of 1+2+3++ n
4 reasons for adopting "safe left shift"
想要软件测试效果好,搭建好测试环境是前提
Sharepoint:sharepoint server 2013 and adrms Integration Guide
Advanced technology Er, meet internship position information
Analysis of a video website m3u8 non perceptual encryption
Trendmicro:apex one server tools folder
What are the indicators of VIKOR compromise?
(翻译)采用字母间距提高全大写文本可读性的方式
35岁腾讯员工被裁员感叹:北京一套房,存款700多万,失业好焦虑
C language: count the number of characters, numbers and spaces
Sharepoint:sharepoint 2013 with SP1 easy installation
UEFI:修复 EFI/GPT Bootloader