当前位置:网站首页>Meaning of Jieba participle part of speech tagging
Meaning of Jieba participle part of speech tagging
2022-06-25 08:28:00 【Happy little yard farmer】
Part of speech tagging of stuttering participles
The default mode is to use jieba.posseg.cut(), Include 24 POS Tags ( Lowercase letters ).
paddle There are more patterns 4 Proper name category labels ( Capital ).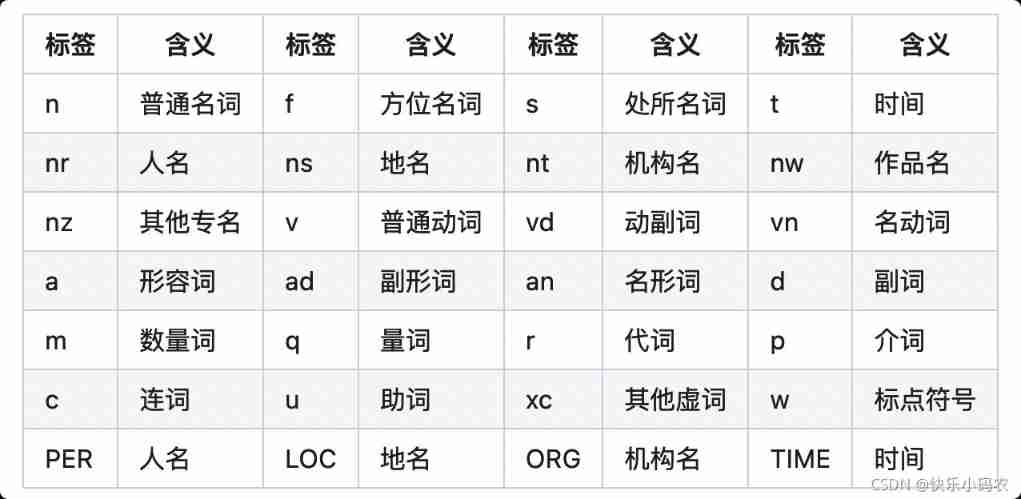
jieba.posseg.POSTokenizer(tokenizer=None)Create a new custom word splitter ,tokenizer Parameter to specify the internal use ofjieba.TokenizerWord segmentation is .jieba.posseg.dtLabel the word breaker for the default part of speech .- Mark the part of speech of each word after sentence segmentation , Adopt and ictclas Compatible notation .
- except jieba Default segmentation mode , Provide paddle Part of speech tagging function under the mode .paddle The mode uses delayed loading , adopt
enable_paddle()install paddlepaddle-tiny, also import Related codes ; - Usage examples
>>> import jieba
>>> import jieba.posseg as pseg
>>> words = pseg.cut(" I love tian 'anmen square in Beijing ") #jieba The default mode
>>> jieba.enable_paddle() # start-up paddle Pattern . 0.40 We started to support , Earlier versions did not support
>>> words = pseg.cut(" I love tian 'anmen square in Beijing ",use_paddle=True) #paddle Pattern
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
I r
Love v
Beijing ns
The tiananmen square ns
Welcome to my official account. 【SOTA Technology interconnection 】, I will share more dry goods .

边栏推荐
- 使用apt-get命令如何安装软件?
- 打新债安不安全 有风险吗
- The difference between personal domain name and enterprise domain name
- First experience Amazon Neptune, a fully managed map database
- How to calculate the D value and W value of statistics in normality test?
- Similarity calculation method
- Nodehandle common member functions
- Data-centric vs. Model-centric. The Answer is Clear!
- 五分钟快速搭建一个实时人脸口罩检测系统(OpenCV+PaddleHub 含源码)
- 软件工程复习题
猜你喜欢









随机推荐
Can I grant database tables permission to delete column objects? Why?
Stimulsoft Ultimate呈现报告和仪表板
什么是SKU和SPU,SKU,SPU的区别是什么
What are the indicators of VIKOR compromise?
After using the remote control of the working machine, problems occurred in the use of the local ROS, and the roscore did not respond
Paper:Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Almost taken away by this wave of handler interview cannons~
Use pytorch to build mobilenetv2 and learn and train based on migration
Niuke: flight route (layered map + shortest path)
4个不可不知的采用“安全左移”的理由
Wechat applet introduction record
With the beauty of technology enabled design, vivo cooperates with well-known art institutes to create the "industry university research" plan
Deep learning series 45: overview of image restoration
Common action types
Socket problem record
leetcode.13 --- 罗马数字转整数
The difference between personal domain name and enterprise domain name
面试前准备好这些,Offer拿到手软,将军不打无准备的仗
Cloud computing exam version 1 0
Retrieval model rough hnsw