当前位置:网站首页>Deep learning series 45: overview of image restoration
Deep learning series 45: overview of image restoration
2022-06-25 08:07:00 【IE06】
From this issue , Will explore the field of image restoration papers and code . This time, I will read the overview first .
A big assumption of traditional methods is that we believe that we can find similar patch, But if there is no such thing outside the missing area patch, There is no way to correctly repair the image .
1 classic GAN Method
1.1 context encode:U-net generator
2016 Of the benchmark appearing in GAN Algorithm , The generator is a U Type network , The discriminator is a multilayer convolution network . Losses include pixel level reconstruction losses (L2) Counter loss with discriminator output .
1.2 MSNPS: Add a texture generator
2016 Year upgraded context encode, Its generator consists of two parts , Added convolution network for texture generation :
above U Type networks are used to generate content , The loss function includes L2 Losses and counter losses .
The following convolution network is used to generate texture , And find the nearest neural network response outside the missing area to calculate the loss . The practice here is similar to style transfer , Transfer the style of the complete part to the lost part .
1.3 GLCIC: Add local discriminator

Here the generator uses dilation convolution to increase the receptive field .
Training is divided into 3 Step :
- generator L2 Loss , Be careful L2 The loss is calculated in the missing area .
- Training discriminator
- Generators plus counter losses , Alternate training with discriminator
The image post-processing adopts fast marching+ Poisson image blending
1.4 PGGAN: Add matrix discriminator
GLCIC Too dependent on predefined missing areas , However, the deformity in the actual scene is often unknown , Therefore, it still needs to be improved .
A typical GAN The output of the discriminator is 0 ~ 1 Single value of . This means that the discriminator will look at the entire image , Judge whether the image is true or false , We call it GlobalGAN. and PatchGAN The output of the discriminator is a matrix , Every element in this matrix is in 0 To 1 Between . Be careful , Each element represents a local area in the input image .
Combination of the two , be called PGGAN
The structure and GLCIC Very similar , The generation module is changed into the expansion residual network , In addition, the standard deconvolution is changed into interpolation convolution to eliminate artifacts .
1.5 shiftGAN:U-net The generator adds shift Connect

Add boot loss : Between all the connected two layers, the encoding feature and the decoding feature L2 The sum of the losses .
add to shift Connect : By shift operation , The network can effectively borrow the information given by the nearest neighbor outside the missing part , To improve the global semantic structure and local texture details of the generated part . Simply speaking , It is to provide a suitable reference to improve the estimation .
1.6 DeepFill: Generator adds attention
The author proposes a two-stage repair network from coarse to fine :
The first stage is to repair the network roughly : Using hole convolution + The reconstruction loss is first compensated with a fuzzy and rough result ;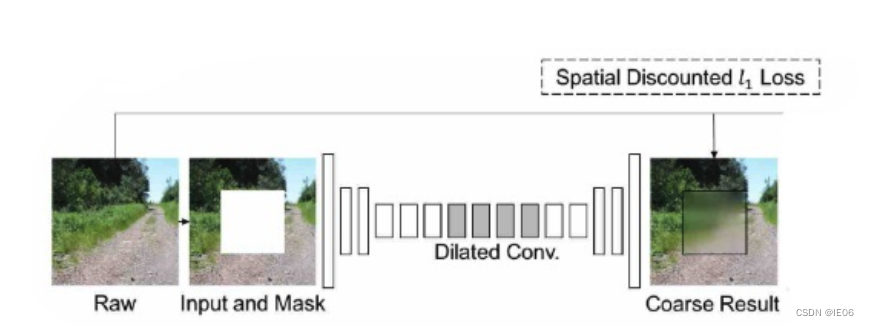
The second stage is to repair the network : Empty convolution with contextual attention modules + Reconstruction losses + overall situation 、 Local GAN-GP Fight losses to further refine the results .
encode Some on the road branches contain semantic attention layers (contextual attention layer) Of encoder; Going down the road is routine encoder. Two ways encoder The output feature graph is finally spliced together to form a feature graph , Finally through decoder Generate repair results .
1.7 DeepFill v2: mask Generated by gated convolution
gated conv Is the core innovation of this article , He is like a soft sieve , There is a selection mechanism for input .( Soft selection , Is multiplied by one 0-1 Number between , The opposite is a hard sieve , Or they all pass , Or stop them all ), It can automatically learn from the data according to the update rules soft mask Parameters of ( Just like the filter coefficient ), As follows :

In addition, in response to free-form Of mask, Used Markovian discriminiator, Score the matrix whose size is smaller than the original drawing . Against the loss used Hinge loss.
1.8 PatialConv: Handle freeMask
The central idea is this , If there are no effective pixels in the receptive field ( That is to say, all are mask 了 ), Then the convolution operation is not performed ; In other cases , Only effective pixels are convoluted .
Besides ,mask Also constantly updated :
1.9 CTSDG: Discriminator adds edge detection

More like MSNPS, The generator starts from the image 、 Edges are generated separately , The discriminator is also from the image 、 The edge is divided into two branches for judgment .
1.10 EdgeConnect: Add edge generator and edge discriminator

The functions of this project are deepfill v2 More like , Use contour as a priori to guide image generation .
Pictured above , The left half of G1 and D1 Used to learn the outline , The right half G2 and D2 Is used to generate the final image .
G1 and G2 Both use void convolution + Residual module ;D1 and D2 All use PatchGAN, That is to divide the discrimination picture into 70x70 To judge , Average the discrimination results .
The original image patching task required RGB Value the missing area of the image , If the norm distance is used to calculate the reconstruction loss L r e c L_{rec} Lrec Words , Always get blurred pictures ( Average the results of possible repair modes ); If the characteristic distance is used to calculate the countermeasure loss L a d v L_{adv} Ladv Words , I always get pictures with obvious artificial traces ( Artifact )( Find a similar result from the training memory and post it ). Context encoder Context Encoder The combination of the two is used in the way of parameter weighting , It just balances these two shortcomings .
In that case , Reduce the difficulty of the image repair task , Do not repair the three channel RGB chart , Instead, repair the binary graph with only contour . Fix after getting the outline picture , Turn it into a style migration task ( Convert the outline to a color picture ). This process , The process of recovering high frequency information and low frequency information is decoupled , So as to solve the image repair task .
边栏推荐
- MySQL简单权限管理
- Not afraid of losing a hundred battles, but afraid of losing heart
- 黑点==白点(MST)
- 深度学习系列48:DeepFaker
- 剑指offer刷题(中等等级)
- 2160. minimum sum of the last four digits after splitting
- Opencv minimum filtering (not limited to images)
- 2265. number of nodes with statistical value equal to the average value of subtree
- Electronics: Lesson 014 - Experiment 15: intrusion alarm (Part I)
- 【红旗杯?】补题
猜你喜欢

allgero报错:Program has encountered a problem and must exit. The design will be saved as a .SAV file

Introduction to the main functions of the can & canfd comprehensive test and analysis software lkmaster of the new usbcan card can analyzer

网络模型——OSI模型与TCP/IP模型

唐老师讲运算放大器(第七讲)——运放的应用

Apache CouchDB 代码执行漏洞(CVE-2022-24706 )批量POC

Electronics: Lesson 014 - Experiment 15: intrusion alarm (Part I)

Importer des données dans MATLAB

PH neutralization process modeling

C # set up FTP server and realize file uploading and downloading

Electronics: Lesson 009 - Experiment 7: study relays
随机推荐
CAN透传云网关CANIOT,CANDTU记录CAN报文远程收发CAN数据
Electronics: Lesson 012 - Experiment 11: light and sound
bat启动.NET Core
50. pow (x, n) - fast power
417-二叉树的层序遍历1(102. 二叉树的层序遍历、107.二叉树的层次遍历 II、199.二叉树的右视图、637.二叉树的层平均值)
剑指offer刷题(中等等级)
图像超分综述:超长文一网打尽图像超分的前世今生 (附核心代码)
Apache CouchDB 代码执行漏洞(CVE-2022-24706 )批量POC
电子学:第009课——实验 7:研究继电器
Force deduction 76 questions, minimum covering string
网络模型——OSI模型与TCP/IP模型
Machine learning notes linear regression of time series
What are the problems with traditional IO? Why is zero copy introduced?
【论文学习】《VQMIVC》
三台西门子消防主机FC18配套CAN光端机进行光纤冗余环网组网测试
【补题】2021牛客暑期多校训练营4-n
2021ICPC网络赛第一场
飞机引气系统的建模与故障仿真
MySQL简单权限管理
Opencv daily function structure analysis and shape descriptor (8) Fitline function fitting line