当前位置:网站首页>The solution of distributed system: directory, message queue, transaction system and others
The solution of distributed system: directory, message queue, transaction system and others
2022-06-24 12:03:00 【Hua Weiyun】
One 、 A directory service (ZooKeeper)
A distributed system is a whole composed of many processes , Every part of the whole , Will have some state , For example, load conditions , The mastery of certain data and so on . And the data related to other processes , In recovery 、 It's very important to expand and shrink .
Simple distributed systems , You can record this data through a static configuration file : Connection correspondence between processes , Their IP Address and port, etc . However , A highly automated distributed system , It is necessary to keep these state data dynamically . In this way, the program can do it by itself disaster and Load balancing The job of .
Some programmers write their own DIR service ( A directory service ), To record the running status of processes in the cluster . The process in the cluster will interact with this DIR Automatic association of services , This is disaster recovery 、 Capacity expansion 、 When the load is balanced , It's automatically based on these DIR Data in service , To adjust the destination of the request , So as to avoid the fault machine 、 Or connect to a new server .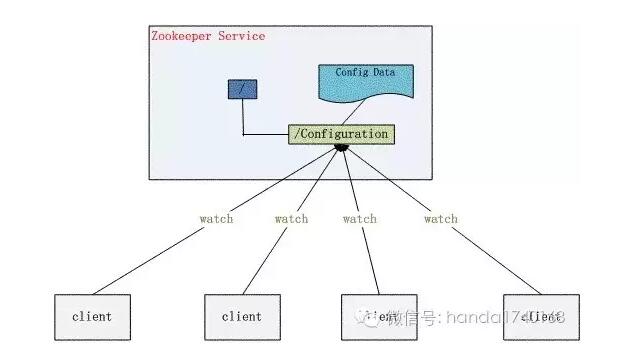
However , If you just use a process to do the job , So this process becomes the cluster's “ Single point ”—— It means , If the process fails , Then the whole cluster may not work ( A single point of failure ). Therefore, the directory service storing the cluster state also needs to be distributed . Fortunately, there is ZooKeeper This excellent open source software , It is a distributed directory server .
ZooKeeper You can simply start an odd number of processes , To form a small cluster of directory services . This cluster will be available to all other processes , It's a huge “ Configuration tree ” The ability of . This data will not just be stored in a Zookeeper In progress , It's based on a very secure algorithm , Let multiple processes host . This makes Zookeeper Become an excellent distributed data storage system .
because Zookeeper Data storage structure of , It is a tree system similar to file directory , So we often take advantage of its functions , Bind each process to one of them “ m. ” On , And then by checking these “ Branch ”, To forward the server request , We can simply solve the problem of request routing ( Who will do it ) The problem of . In addition, you can also use the “ Branch ” State of the payload of the marked process on , So load balancing is easy to do .
Directory service is one of the most important components in distributed system . and ZooKeeper It's a good open source software , It's just for this task .
Two 、 Message Queuing service (ActiveMQ、ZeroMQ、Jgroups)
If two processes want to communicate across machines , We almost all use TCP/UDP These agreements . But using the Internet directly API To write cross process communication , It's a very troublesome thing . In addition to writing a lot of the underlying socket Out of code , Also deal with things like : How to find the process to interact with data , How to protect the integrity of data packets from loss , If the other process of communication fails , Or how the process needs to be restarted and so on . These questions include Capacity expansion and disaster 、 Load balancing And so on .
In order to solve the problem of inter process communication in distributed system , People have come up with an effective model , Namely “ Message queue ” Model . Message queuing model , It's the interaction between processes , Abstract processing of message by message , And for the news , There are some. “ queue ”, That's the pipe , To hold messages . Each process can access one or more queues , Reading messages from inside ( consumption ) Or write a message ( production ). Because there is a cache pipeline , You can safely change the state of the process . When the process starts , It will automatically consume messages . And the routing of the message itself , It's also determined by the stored queue , In this way, the complex routing problem , It becomes a question of how to manage static queues .
General Message Queuing service , It's all about simple “ The delivery ” and “ collect ” Two interfaces , But the management of message queue itself is more complicated , Generally speaking, there are two kinds . Part of the Message Queuing service , Point to point queue management is advocated : Between each pair of communication nodes , Each has a separate message queue . The advantage of this approach is that information from different sources , Can not affect each other , Not because there are too many messages in a queue , Crowding out the message cache space of other queues . And the program that processes the message can also define the priority of processing itself —— Charge first 、 Multiprocessing a queue , And less processing of other queues .
But this kind of peer-to-peer message queuing , A large number of queues will be added as the cluster grows , This is a complex matter for memory occupation and operation and maintenance management . So more advanced message queuing services , Start by allowing different queues to share memory space , And the address information of the message queue 、 Create and delete , It's all automated .—— These automations often need to rely on the “ A directory service ”, To register the queue ID The corresponding Physics IP And ports . For example, many developers use ZooKeeper To act as the central node of the Message Queuing service ; But similar Jgropus Such software , Maintain a cluster state to store the information of each node .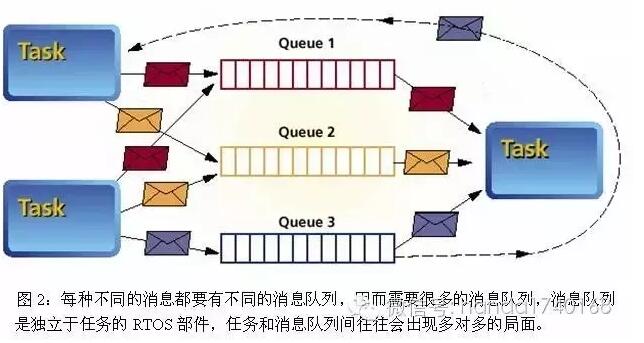
Another kind of message queue , It's like a public mailbox . A Message Queuing service is a process , Any user can post or receive messages in the process . This makes it easier to use message queues , Operation and maintenance management is also more convenient . No ** In this way , Any message from sending to processing , At least two interprocess communications , The delay is relatively high .** And because there's no scheduled delivery 、 Charge constraints , So it's easier to BUG.
No matter which Message Queuing service you use , In a distributed server-side system , Interprocess communication is a problem that must be solved , So as a server-side programmer , When writing distributed system code , The most used code is based on message queue driver , It also led directly to EJB3.0 hold “ Message driven Bean” Add to the specification .
3、 ... and 、 Transaction system
In a distributed system , Transaction is one of the most difficult technical problems to solve . Since a process may be distributed among different processes , Any process can fail , And this failure problem needs to cause a rollback . Most of this rollback involves many other processes . This is a diffusive multiprocess communication problem . To solve transaction problems on Distributed Systems , There must be two core tools : One is a stable state storage system ; Another is a convenient and reliable broadcasting system .
The state of any step in a transaction , Must be visible throughout the cluster , And also have the ability of disaster recovery . This requirement , It's usually made up of clusters “ A directory service ” To undertake . If our directory service is robust enough , So we can put the processing state of each transaction , Write to the directory service synchronously .Zookeeper Once again, it can play an important role in this place .
If a transaction breaks , Need to roll back , So this process involves several steps that have been performed . Maybe this rollback only needs to be rolled back at the entrance ( Join there to save the data needed for rollback ), You may also need to roll back on each processing node . If it's the latter , Then you need the abnormal nodes in the cluster , Broadcast one to all other related nodes “ Roll back ! Business ID yes XXXX” Such news . The bottom layer of this broadcast is usually hosted by the Message Queuing service , But similar Jgroups Such software , Direct delivery of broadcasting services .
Now we're talking about transactional systems , But actually distributed systems often need “ Distributed lock ” function , It's also something that this system can do at the same time . So-called “ Distributed lock ”, That is, a constraint that allows each node to check before executing . If we have an efficient and atomically operated directory service , So this lock state is actually a kind of “ One step transaction ” State records of , The rollback operation defaults to “ Suspend operation , Try again later ”. such “ lock ” The way , It's simpler than transaction , So it's more reliable , So now more and more developers , Willing to use this “ lock ” service , Not to achieve a “ Transaction system ”.
Four 、 Automated deployment tools (Docker)
** Because of the biggest demand of distributed system , It's at run time ( There may be a need to interrupt service ) To change the service capacity : Expand or shrink .** When some nodes in the distributed system fail , New nodes are also needed to get back to work . If these are still like the old-fashioned Server Management , By filling in the form 、 declare 、 Enter the machine room 、 Install the server 、 Deploy software …… This set of practices , That's definitely not efficient .
** In a distributed system environment , We usually use “ pool ” The way to manage services .** We will apply for a batch of machines in advance , Then run the service software on some machines , Others serve as backup . Obviously, our batch of servers can't serve only one business , Instead, it will provide multiple different service carriers . Those backup servers , It will become a common backup for multiple businesses “ pool ”. As business needs change , Some servers might “ sign out ”A Service and “ Join in ”B service .
This frequent service change , Rely on highly automated software deployment tools . Our operation and maintenance personnel , You should master the deployment tools provided by the developers , Instead of a thick manual , To do this kind of operation and maintenance .** Some experienced development teams , It will unify all the underlying business frameworks , With a view to most of the deployment 、 Configuration tools can be managed by a common system .** And the open source community , There are similar attempts , The most well-known is RPM Installation package format , However RPM It's still too complicated to pack , It doesn't meet the deployment requirements of server-side programs . So it came back later Chef Is the representative of the programmable universal deployment system .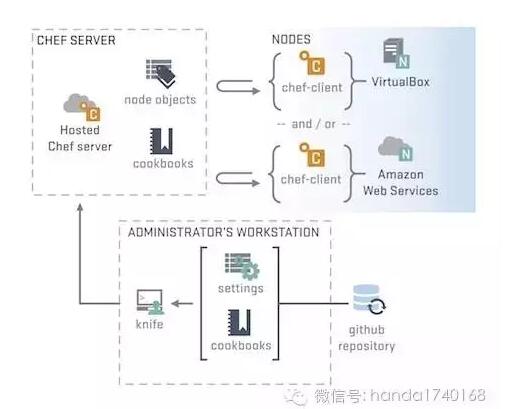
After the advent of virtual machine technology ,PaaS The platform provides strong support for automatic deployment : If we press a PaaS Platform specification to write the application , You can completely leave the application to the platform for deployment , Calculation of bearing capacity 、 Deployment planning is done automatically . The best in this field is Google Of AppEngine: We can use it directly Eclipse Develop a local Web application , And then upload it to AppEngine Inside , All deployment is complete .AppEngine Will be automatically based on this Web Application visits , To expand 、 Shrinkage capacity 、 Fault recovery .
However , A truly revolutionary tool , yes Docker Appearance . Although the virtual machine 、 Sandbox technology is not a new technology for a long time , But really use these technologies as *** Deployment tools *** The time is not long .Linux Efficient lightweight container technology , Provides ease of deployment —— It can be found in various libraries 、 Packaging applications in a collaborative software environment , And then randomly deploy in any one Linux On the system .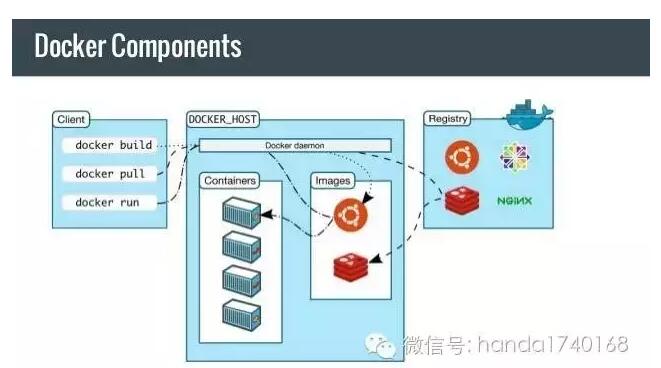
To manage a large number of distributed server-side processes , We really need to work a lot , Optimize their deployment management efforts . Unifies the server side process the movement standard , It is the basic condition to realize automatic deployment management . We can use “ operating system ” As a norm , use Docker technology ; It can also be based on “Web application ” As a norm , Adopt some PaaS Platform technology ; Or define some more specific specifications yourself , Develop a complete distributed computing platform .
5、 ... and 、 The log service (log4j)
Server side logs , It has always been an important and easily overlooked issue . A lot of teams at the beginning , Just think of logging as development debugging 、 exclude BUG The auxiliary tools of . But it will soon be discovered , After the service is operational , The log is almost the only effective means that the server-side system can use to understand the program situation at runtime .
Although we have all kinds of profile Tools , However, most of these tools are not suitable for opening on the service of formal operation , Because it will seriously reduce its performance . So we need to analyze it according to the log more often . Although logs are essentially lines of text information , But because of its great flexibility , So it will be very valued by the development and operation and maintenance personnel .
Log itself is a very vague thing in concept . You can open any file you like , And then write some information . But modern server systems , Generally, we will make some standardized requirements for logs : The log must be line by line , This is more convenient for future statistical analysis ; Each line of log text , There should be some unified head , For example, date and time are basic requirements ; Log output should be hierarchical , such as fatal/error/warning/info/debug/trace wait , Programs can adjust the level of output at run time , So as to save the consumption of log printing ; The head of the log usually needs some similar users ID perhaps IP Header information like address , It is used to quickly locate and filter a batch of log records , Or there are some other fields that can be used to filter and narrow down the viewing range of logs , It's called dyeing function ; Log files also need to have “ Roll back ” function , That is, to keep multiple files of a fixed size , Avoid long-term operation , Fill up the hard disk .
Because of the above needs , So the open source community provides a lot of game log component libraries , For example, famous log4j, And a large number of log4X Family library , These are widely used and well received tools .
However, compared with the log printing function , The collection and statistics functions of logs are often ignored . As a distributed system programmer , I'm sure I want to start from a centralized node , Can collect statistics to the whole cluster log situation . And there are some log statistics , Even hope to get it repeatedly in a very short time , Used to monitor the health of the entire cluster . Do that , You have to have a distributed file system , It's used to store logs that keep coming in ( These logs tend to go through UDP Send the protocol ). And on this file system , You need to have a similar Map Reduce The statistical system of Architecture , Only in this way can the massive log information , Fast statistics and alarms . Some developers will use it directly Hadoop System , Some use Kafka As a log storage system , Then build your own statistical program .
Log service is the dashboard of distributed operation and maintenance 、 Periscope . Without a reliable logging service , The whole system may run out of control . So no matter how many nodes you have in your distributed system , It takes a lot of effort and dedicated development time , To build a system for automatic statistical analysis of logs .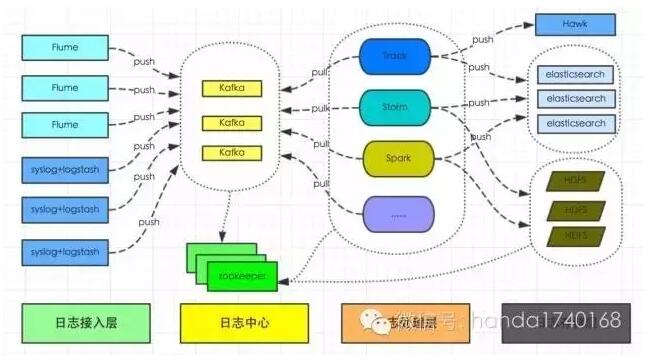
6、 ... and 、 Expanding reading
边栏推荐
- ArrayList # sublist these four holes, you get caught accidentally
- 08. Tencent cloud IOT device side learning - device shadow and attributes
- C语言循环语句介绍(foe、while、do...while)
- 怎么申请打新债 开户是安全的吗
- Group planning - General Review
- 深度学习~11+高分疾病相关miRNA研究新视角
- 不用做实验的6分+基因家族纯生信思路~
- [深度学习][pytorch][原创]crnn在高版本pytorch上训练loss为nan解决办法
- 计组-总复习
- 我真傻,招了一堆只会“谷歌”的程序员!
猜你喜欢

How to write controller layer code gracefully?
[Architect (Part 41)] installation of server development and connection to redis database

FreeRTOS概述与体验

如何开发短信通知和语音功能医院信息系统(HIS系统)

TP-LINK 1208 router tutorial (2)

链接器 --- Linker

《opencv学习笔记》-- 图像的载入和保存

Qt: 判断字符串是否为数字格式
How is the e-commerce red envelope realized? For interview (typical high concurrency)

Turn 2D photos into 3D models to see NVIDIA's new AI "magic"!
![[Architect (Part 41)] installation of server development and connection to redis database](/img/b5/a2f4a0b3a75bdfa2493e2c010d73b2)
随机推荐
《opencv学习笔记》-- 感兴趣区域(ROI)、图像混合
Clickhouse deployment and basic usage 1
【直播回顾】战码先锋第七期:三方应用开发者如何为开源做贡献
我在深圳,到哪里开户比较好?现在网上开户安全么?
可变参数模板实现max(接受多个参数,两种实现方式)
Based on am335x development board arm cortex-a8 -- acontis EtherCAT master station development case
Multi gate mixture of experts and code implementation
How is the e-commerce red envelope realized? For interview (typical high concurrency)
Jenkins remote publishing products
《opencv学习笔记》-- 图像的载入和保存
LS-DYNA新手入门经验
2022年有什么低门槛的理财产品?钱不多
链接器 --- Linker
It's so difficult for me. Have you met these interview questions?
GLOG从入门到入门
广发证券靠谱吗?开证券账户安全吗?
Code is really - omnipotent! Refuse to fight
11+的基于甲基化组和转录组综合分析识别葡萄膜黑色素瘤中新的预后 DNA 甲基化特征~
I just did it! Visualization of character relationships in Douluo continent
Influence of DEX optimization on arouter lookup path