当前位置:网站首页>测试-- 自动化测试selenium(关于API)
测试-- 自动化测试selenium(关于API)
2022-06-23 08:16:00 【梦想成为光头强!】
目录
前言
其实博客不应该从这里开始,好多东西是没有写的,基本都是一些关于测试的基础的东西,比如测试的模型,测试的对象,完整的测试用例等等等等。这些之后如果有时间我会写一个博客用来整理。这里的话就先从自动化测试开始吧。
一丶相关定义
这一部分就是大致整理一下关于自动化测试的相关定义和概念。
<1>什么是自动化测试?
所谓自动化测试,指的是软件测试的自动化,在预设条件下运行应用程序或者系统,预设条件包括正常和异常,最后评估运行结果,把人为的测试行为转化为机器执行的过程。
自动化测试包括单元测试,接口测试,UI测试,这三个部分排序是自底向上。
按照这个模型来进行自动化测试可以产生最佳的自贡话测试产出投入比(也就是ROI最佳),可以用较少的投入获得一个很棒的收益。
1.单元测试
最大的投入就是单元测试,单元测试运行的频率也是最高的。Java的单元测试框架就是Junit,单元测试适合项目比较庞大的系统
2.接口自动化
接口测试就是API测试,相对于UI自动化,API自动化更加容易实现,执行起来也更加稳定。它的测试时间段是项目前期接口开发完成,开始进行测试。它的用例维护量比较少,适合接口变动较少的项目。
接口自动化特点如下:
可在产品前期,接口完成后介入
用例维护量小
适合接口变动较小,界面变动频繁的项目
比较常见的测试工具有:RobotFramework,JMeter,SoapUI,TestNG+HttpClient,Postman等
3.UI自动化
测试金字塔告诉我们要尽量多做API层的自动化测试,但是UI层的自动化测试更加贴近用户的需求和软件系统的实际业务,并且有时候我们不得不进行UI层的测试。所谓的UI自动化指的是对系统的界面元素进行操作,用脚本模拟用户的使用,完成功能的正常和异常测试。测试的时间段是项目后期,项目完成前后端的开发和联调后。它的用例维护量比较大,适合界面元素变动小的元素。
UI自动化的特点如下:
用例维护量大
页面相关性强,必须后期项目页面开发完成后介入
UI测试适合与界面变动较小的项目
<2>为什么需要自动化测试?
这个问题应该换一种问法。就是说自动化测试的好处在哪里?
1.可以更方便的进行回归测试
2.节约了资源
3.是一种可靠的测试方式,机器不会出错
4.可以完成很多繁琐的测试
5.能够完成手工测试无法完成的测试
<3>如何实施自动化测试
自动化测试的实施通过自动化框架来实施。这里介绍一下几种比较常见的框架
1.RobotFramework 关键字驱动,底层实现语言Python
2.Django接口 底层实现python
3.selenium unittest框架 python
这里我们主要是学习selenium,那么为什么要选择selenium?
1.免费
2.容易安装
3.支持多语言:java c# JS Python ruby
5.支持多平台:linux Windows Mac
6支持多浏览器:Chrome Firefox dege Opera Safari
7.支持分布式测试:selenium Grid
<4>关于webdriver的原理和安装
关于其原理,可以分为以下几步
1.运行脚本,把浏览器绑定到一个端口,这个端口就是浏览器端的remote server
2.脚本通过commandexecutor,向浏览器发送HTTP请求,控制浏览器进行一系列操作
3.浏览器驱动把指令解析成web service的命令,驱动浏览器进行一系列的操作。

关于安装这里有就两个点是需要注意的!
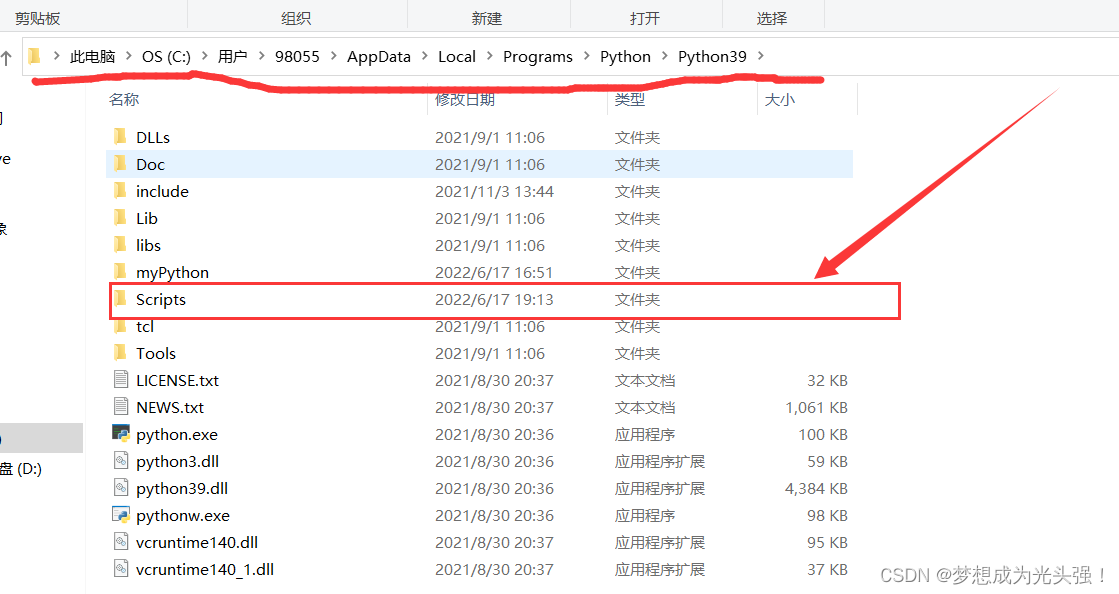
1.注意浏览器驱动和浏览器的版本要一致。
2.下载好压缩包后,把它解析到你Python下的Scripts文件夹,就可以用了。
二丶UI自动化API
前面我们说了,UI自动化指的是对系统的界面元素进行操作,用脚本模拟用户的使用,完成功能的正常和异常测试。所以这里我们就进行对应的操作。
所以这里先通过一个脚本来大致的说一下接下来我们的讲解思路
from selenium import webdriver #导入webdriver工具包,这样就可以使用里面的API
import time #导入time工具包
browser = webdriver.Firefox() ## 获得驱动
time.sleep(3) # 等待三秒
browser.get("http://www.baidu.com") # 打开百度
time.sleep(3) # 等待三秒
browser.find_element_by_id("kw").send_keys("selenium") #通过元素ID进行定位,并且向元素输入内容
time.sleep(3) # 等待三秒
browser.find_element_by_id("su").click() # 通过ID进行定位,并且点击该元素
browser.quit() #退出
这就是一个完整的脚本,这里的话就把这些功能点一个个提出来进行拓展
<1>关于驱动
这个驱动没有什么特别好说的,就是有一点需要特别注意,这一点让我特别把驱动这个知识点拉出来开辟,就是你的浏览器驱动一定要选择对,笔者刚开始选择的是谷歌的驱动,然后UI自动化的测试我是使用百度来讲解的,这个百度有一个毛病,就是它会疯狂的跳出来安全验证,运行一次跳一次,而且无法取消(反正笔者网上是没有搜到对应的方法的),所以如果是新手上路,笔者建议你们选择安装火狐驱动器的驱动,就是这样。
<2>定位元素
打开网站没啥好说的了哈,想打开啥网站就输入啥网址就行,这里定位是重点要说的。主要有以下这些方法。
1.id
首先笔者先贴一下完整的代码,这里后面就只贴关键的代码了
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
time.sleep(1)
#通过id来定位,全局唯一,可以唯一定位一个元素
driver.find_element_by_id("kw").send_keys("梦华录")
time.sleep(3)
driver.find_element_by_id("su").click()
time.sleep(5)
driver.quit()
作者上面有注释的那段代码就是主要的代码,下面讲解的所有代码基本就是换这部分代码,其他的不动。那么关于这里我们主要就是通过前端页面布局的id来定位对应的元素。
比如这段代码
driver.find_element_by_id("kw").send_keys("梦华录")
就是定位到搜索框,然后输入“梦华录”。这里可能会有小伙伴要问了,我怎么知道它的id是多少呢?那我们看看就好了

这里是鼠标移动到搜索框,然后单击鼠标右键,点击检查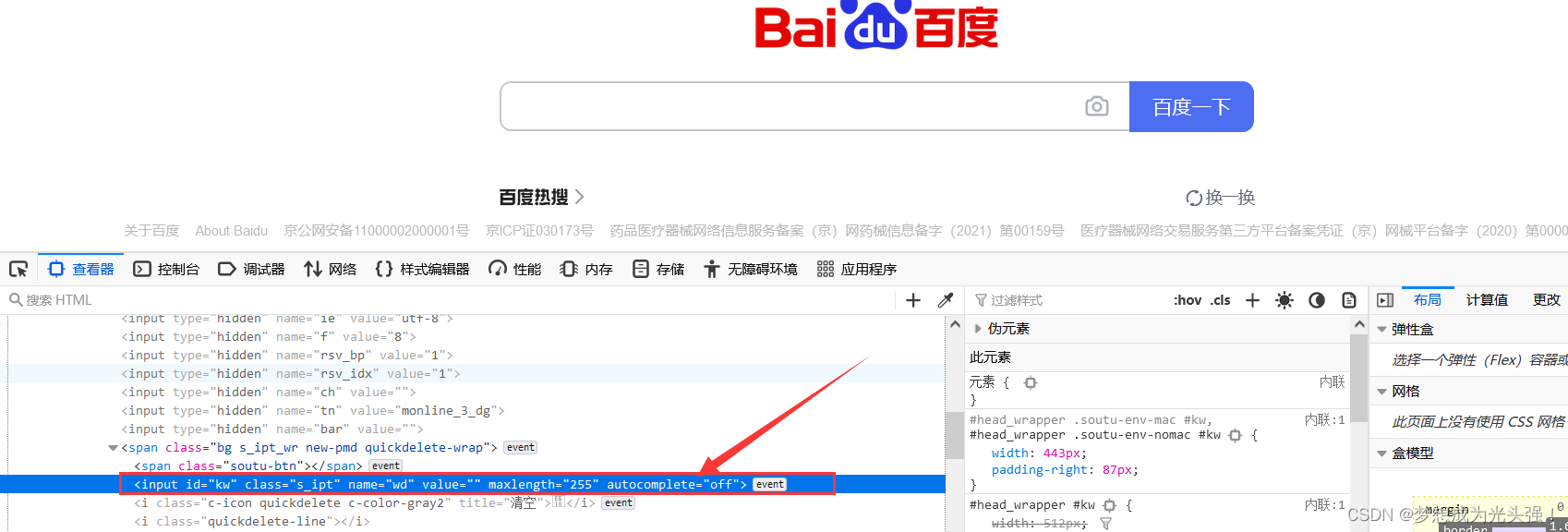
这里就可以看到对应的id是多少。
2.name
通过name来定位有一个需要注意的地方,就是name有可能不是唯一的,如果name不唯一的时候,就会报错。所以确定了name唯一的时候才可以使用哈
#通过name来定位,name有可能不是全局唯一
driver.find_element_by_name("wd").send_keys("红楼梦")
time.sleep(1)
driver.find_element_by_id("su").click()
搜索框的name看下图
3.tag_name和class_name
从上图中其实可以搜素框元素的属性不仅仅有id和name,还有tag_name和class
tag_name:这里其实说的是标签名,比如说搜索框的input就是一个标签名
class_name:这里其实说的就是class属性的名字
# tag_name定位
driver.find_element_by_tag_name("input").send_keys("鲁智深")
driver.find_element_by_tag_name("input").click()
# class name定位
driver.find_element_by_class_name("s_ipt").send_keys("咸蛋超人")
time.sleep(1)
driver.find_element_by_id("su").click()
但是哈,注意了,这两个属性都必须是全局唯一的时候才可以进行使用,不然会报错的。
4.link text
link text是一个文字链接,我们可以通过链接的内容,然后来对元素进行定位。但是要注意这个链接的内容必须唯一,不然就会报错。比如说在百度页面
有这样一个hao123,那么我们就可以通过它来定位
# link text全局唯一
driver.find_element_by_link_text("hao123").click()
然后当我们开始运行当前脚本后,就会直接从百度页面跳转到hao123页面
4.partial link text
通过部分链接定位,这个有时候也会用到。和上面一样,内容必须唯一
# partial link text
driver.find_element_by_partial_link_text("123").click()
5.xpath
这是一个很神奇的东西,基本任何元素都可以通过它来进行定位。那么我们怎样查看一个元素的xpath呢?
点击检查之后出现以下信息
鼠标移动蓝色行,也就是搜索框对应的元素位置,单击鼠标右键 --> 复制 -->Xpath,然后就可以使用Xpath定位了。(这里截不了图,所以没放图片)
# xpath 任何元素都可以定位,注意查看xpath的过程
driver.find_element_by_xpath("//*[@id='kw']").send_keys("迪迦")
driver.find_element_by_xpath("//*[@id='su']").click()
time.sleep(10)
这里对应的搜索页面
6.css selector
CSS使用选择器来为页面元素绑定元素,这些选择器可以被selenium用作另外的定位策略。
对应的代码如下:
# css selector
driver.find_element_by_css_selector("#kw").send_keys("麦克斯")
driver.find_element_by_css_selector("#su").click()
<3>操作元素对象
1.submit
这是递交表单,只有表单元素才可以。啥意思呢?看下面

百度搜索页面,按钮“百度一下”元素的类型type=“submit”,所以把“百度一下”的操作从click 换成submit 可以达到相同的效果
# 尝试submit type一定要是submit才可以
driver.find_element_by_css_selector("#kw").send_keys("徐渭熊")
driver.find_element_by_css_selector("#su").submit()
time.sleep(3)
2.clear
clear() 用于清除输入框的内容,比如百度输入框里默认有个“请输入关键字”的信息,再比如我们的登陆框一般默认会有“账号”“密码”这样的默认信息。clear 可以帮助我们清除这些信息。
# clear
driver.find_element_by_css_selector("#kw").send_keys("徐渭熊")
driver.find_element_by_css_selector("#su").submit()
time.sleep(3)
driver.find_element_by_css_selector("#kw").clear()
driver.find_element_by_css_selector("#kw").send_keys("开心超人")
driver.find_element_by_css_selector("#su").submit()
这里会先显示“徐渭熊”的搜索界面,然后清空搜索框,接着去搜索“开心超人”。
3.text
这里是获取元素的文本信息,举个例子
获得下这个
text = driver.find_element_by_id("bottom_layer").text
print(text)
最后在控制台输出如下

<4>添加等待
1.sleep休眠
添加休眠的第一步,就是引入time包,接下里就可以在脚本中自由的添加休眠时间了,这里的休眠指的是固定休眠
import time
然后休眠语句如下:
time.sleep(要休眠的时间/秒)
这是固定的休眠
2.隐式等待
这种的就比较智能,它是在一个范围时间内的智能等待,什么意思呢?隐式地等待并非一个固定的等待时间,当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它以轮询的方式不断的判断元素是否被定位到。直到超出设置的时长
driver.implicitly_wait(要休眠的时间/秒)
在休眠的时间中如果说可以继续往下执行了,就去执行。如果休眠的时间里没有等待可以继续往下执行的执行就会报错。
<5>打印信息
这里的操作也很简单,直接上代码
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
time.sleep(2)
driver.maximize_window() #这里窗口最大化
#信息打印title
title = driver.title
print(title)
#信息打印url
url = driver.current_url
print(url)
运行结果如下:
<6>浏览器的操作
1.浏览器最大化
这个我们上面刚写,很简单
driver.maximize_window()
2.设置浏览器宽和高
还是一行语句
driver.set_window_size(400,1000)
怎么实验呢?这里贴一下完全的代码
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
time.sleep(2)
# 设置浏览器的长和宽
driver.find_element_by_id("kw").send_keys("一拳超人")#搜索框输入一拳超人
driver.find_element_by_id("su").click()#点击搜索按键
time.sleep(4)
driver.maximize_window() #窗口最大化
time.sleep(3)
driver.set_window_size(400,1000) #设置窗口的长和宽
time.sleep(3)
driver.quit()
3.浏览器的前进和后退
代码如下
driver.forward()#前进
driver.back()#后退
就相当于我们浏览器的这两个按钮
4.浏览器滚动条的控制
浏览器滚动条的控制需要依靠js脚本,注意这个嗷!JS脚本
#将浏览器滚动条滑到最顶端
document.documentElement.scrollTop=0
#将浏览器滚动条滑到最底端
document.documentElement.scrollTop=10000
具体应用如下:
# 浏览器滚动条的控制
js0 = "var q=document.documentElement.scrollTop=10000" #拉到最底端
driver.execute_script(js0)
time.sleep(3)
js1 = "var q = document.documentElement.scrollTop = 0" #拉到顶端
driver.execute_script(js1)
<7>键盘事件
1.键盘按键用法
如果要使用键盘,第一步就是先引入keys包
from selenium.webdriver.common.keys import Keys
然后通过send_keys()调用按键,语句如下(示例)
driver.find_element_by_id("account").send_keys(Keys.TAB)
driver.find_element_by_name("password").send_keys(Keys.ENTER)
其实也就是定位到元素,然后如果说需要通过键盘操作元素的话,就写对应的语句调用就好啦。
2.组合键盘按键
这个是什么意思呢?就想象我们平时用的最多的ctrl + C 和 ctrl + V。要使用组合键盘按键,第一步还是先导入包
from selenium.webdriver.common.action_chains import ActionChains #组合按键
然后想用什么按键,就用一下语句(示例)
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')
driver.find_element_by_id("su").send_keys(Keys.CONTROL,'x')
这里语句的意思就是:定位到id为kw的元素,然后全选该元素的内容
<8>鼠标事件
如果说想要使用鼠标,那么第一步也是先导包
from selenium.webdriver.common.action_chains import ActionChains
然后就是定位到我们的元素,假设这里定位到元素b
b = driver.find_element_by_id("su")
然后想要对我们的元素操作什么就使用对应语句即可
context_click() 右击
double_click() 双击
drag_and_drop() 拖动
move_to_element() 移动
比如拿右击来举例
## 关于右击
ActionChains(driver).context_click(b).perform()

<9>定位一组元素
比如说哈,比如说
类似于上图这种的前端页面,如果说我们想要同时给他们打上勾,那我们按照上面的操作来说,我们可以怎么做?
第一种是不是就是可以写多行代码,一行代码定位一个方框,打一个勾?类似下面这种
# 勾选里面的所有checkbox
driver.find_element_by_id("c1").click()
driver.find_element_by_id("c2").click()
driver.find_element_by_id("c3").click()
这里补充一下前面这几个小方框的前端源码,以防有小伙伴看不懂
后面两个大致都是相同的。
然后这里我们还可以使用另外一个种方式,就是数组遍历。我们可以很清楚的看到
小方框和小圆框都是Input标签,所以其实可以根据tagname用数组对其进行接收,然后根据type类型的不同对其进行筛选,大致操作如下
# 定位一组tag name 都为input的元素
buttons = driver.find_elements_by_tag_name("input")
for button in buttons:
if button.get_attribute('type') == 'checkbox':
button.click()
<10>多层框架/窗口定位
1.多层框架
什么意思呢?比如如下的情景应用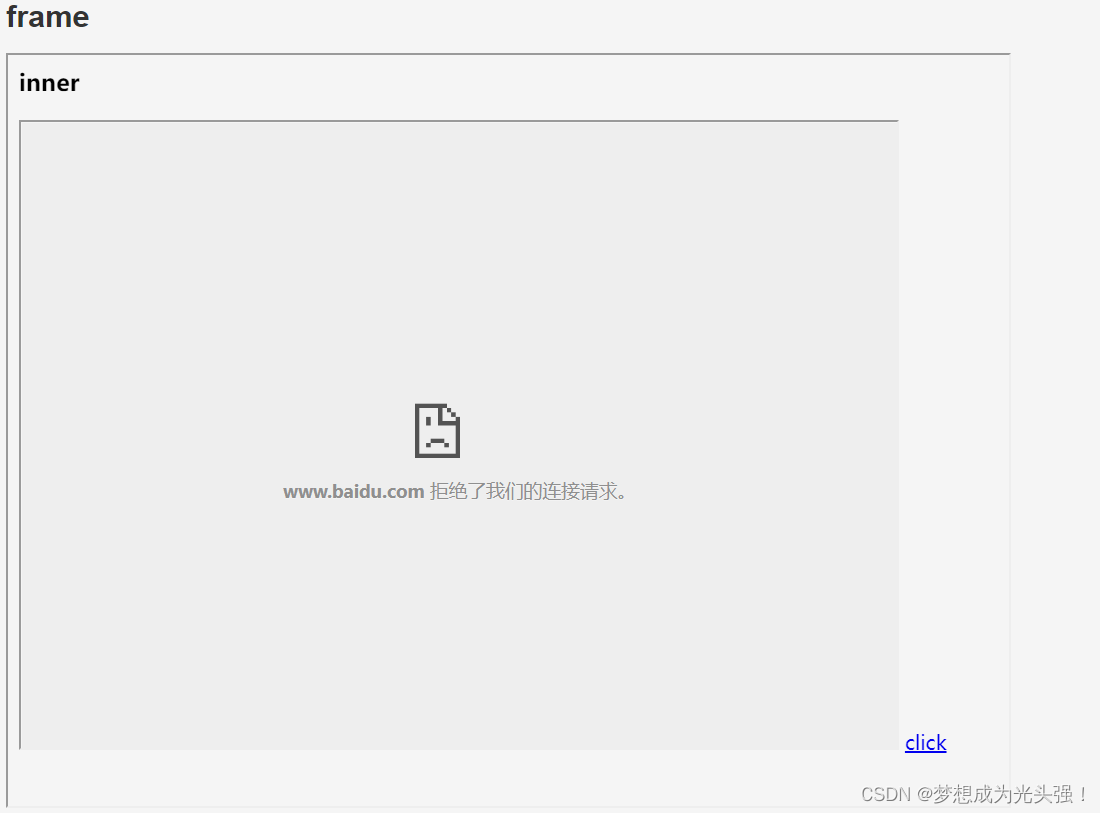
你想直接定位click并且点击可不可以呢?肯定是不可以的
click是inner页面上的元素,如果你想直接定位到click是不现实的。那我们怎么办呢?那就要先从frame页面跳转到inner页面,因为inner页面是frame页面上的元素,所以可以跳转,然后再从inner页面对click元素进行操作。
这里涉及到的语法知识点如下:
switch_to.frame(name_or_id_or_frame_element):通过frame的id或者name或者frame自带的其它属性来定位框架
switch_to.default_content:从frame中嵌入的页面里跳出,跳回到最外面的默认页面中。
2.多层窗口
有可能嵌套的不是框架,而是窗口,还有真对窗口的方法:switch_to.window
用法与switch_to.frame 相同:
driver.switch_to.window("windowName")
<11>层级定位
比如如下示例画面
有时候我们需要定位的元素在页面没有直接展示,而是需要对页面元素经过一系列的操作之后,才展示出来,这个时候就需要层级定位。
对应语法操作如下:
driver.maximize_window()
# 定位link1,点击
driver.find_element_by_link_text("Link1").click()
driver.implicitly_wait(10)
# 定位 Another Action
action = driver.find_element_by_link_text("Another action")
# 高亮显示Another action, 把鼠标移动到 Another action上面
ActionChains(driver).move_to_element(action).perform()
之后的画面展示如下:
<12>下拉框
下拉框和上面的比较类似,一般元素一次定位就能直接定位到,但是下拉框里的内容就需要两次定位,先定位到下拉框对下拉框进行操作之后,在定位到下拉框里面的选项。
这里定位下拉框方式很多,比如xpath,比如tag_name等
然后下拉框展开之后,我们想要对选项选择就有两种不同的方式。
第一种就是用数组接收,然后遍历,根据我们要选择的元素的独特之处进行筛选。
for option in options:
if option.get_attribute('value') == '9.03':
option.click()
第二种,如果我们知道了元素的下标,那么就不用筛选,直接用下标进行操作就好。
options[3].click()
<13>弹出框
1.原生态弹窗
怎么说呢?emmm,看下面的应用场景

在我们点击对应的链接之后,会跳出来一个弹出框,我们需要在弹出框上进行一些操作,这里就又有新的语法,因为此时我们的定位还是在默认框哪里,所以我们需要获得窗口的操作句柄。
# 定位元素,点击,使得弹出框出现
driver.find_element_by_id("tooltip").click()
time.sleep(3)
# 定位弹出框/获得弹出框的操作句柄
alert = driver.switch_to.alert
然后呢,就是对于弹窗的关闭
alert.accept()
2.输入信息
这个其实有点类似于对话框,和上面的操作其实差不多一样。这里先稍微提一下应用场景。

输入名字之后下面就会进行显示,代码如下:
driver.find_element_by_tag_name("input").click()
time.sleep(3)
# 先获得弹出框的操作句柄
alert = driver.switch_to.alert
alert.send_keys("光头强")
time.sleep(4)
# 关闭信息展示弹框
alert.accept()
<14>DIV对话框/DIV块的处理
这种就是适用于页面特别复杂,元素特别多,没有id,没有name,tag_name还给你重复。比如说下图
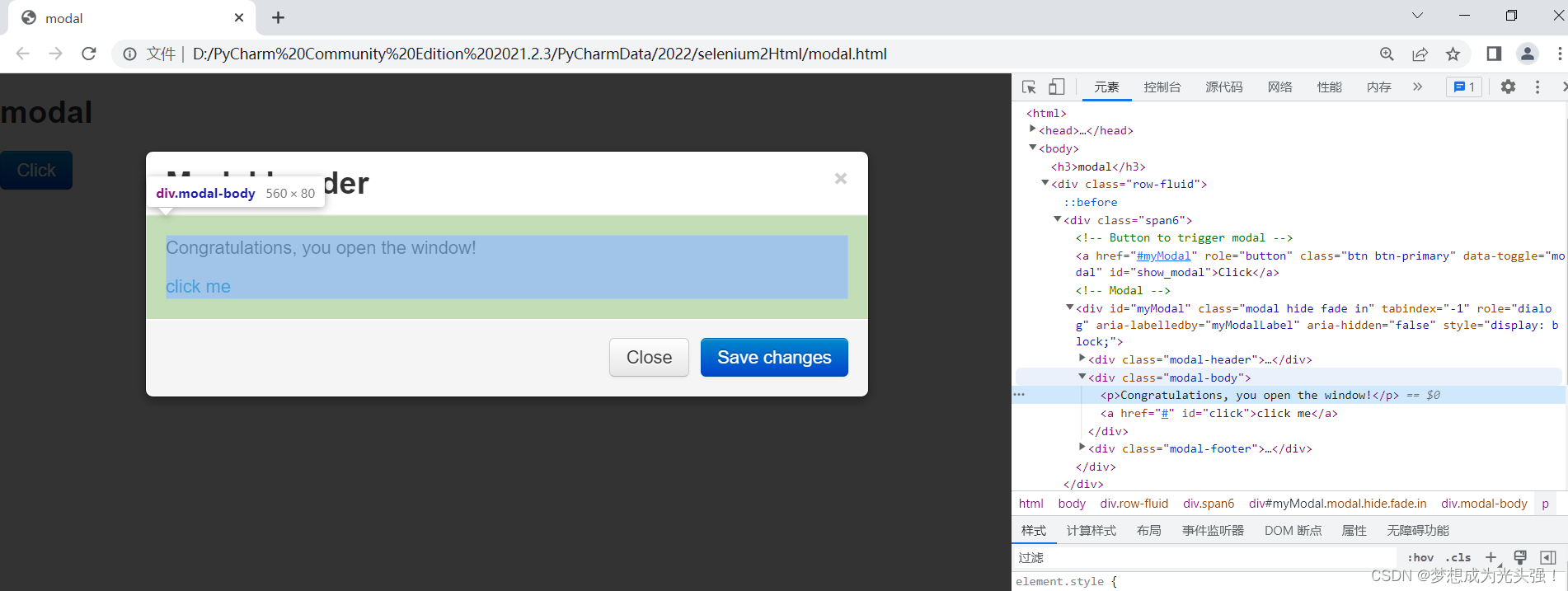
像这种的就是要先定位到div模块,然后在定位到的div模块的基础上去精确寻找需要的定位。对应的代码如下:
# 点击click 出现弹框
driver.find_element_by_link_text("Click").click()
time.sleep(3)
# 点击div 框框里面的click me,让弹出框内容发生变化
div1 = driver.find_element_by_class_name("modal-body")
div1.find_element_by_link_text("click me").click()
time.sleep(4)
# 定位div 在定位具体的button
div2 = driver.find_element_by_class_name("modal-footer")
buttons = driver.find_elements_by_tag_name("button")
buttons[0].click()
time.sleep(6)
主要其实就是一个定位的先后次序。
<15>上传文件
这个就是最简单的一个,一行代码解决
driver.find_element_by_name("file").send_keys("C:\\Users\\18591\\Pictures/test.jpg")
如果说在页面上有上传文件的选项
就用上面哪行代码就好,但是前提是你的文件要有,要存在!
边栏推荐
- Hongmeng reads the resource file
- ThreadPoolExecutor线程池实现原理与源码解析
- Two bug fixes in aquatone tool
- 史上最污技术解读,60 个 IT 术语我居然秒懂了......
- Production environment server environment setup + project release process
- PCB电路板特性检查项目都有哪些?
- 论文阅读【Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset】
- [cloud computing] GFS ideological advantages and architecture
- Fillet the tabbar with the flutter
- Qualcomm 9x07 two startup modes
猜你喜欢

How to start Jupiter notebook in CONDA virtual environment

开源技术交流丨批流一体数据同步引擎ChunJun数据还原-DDL功能模块解析

通信方式总结及I2C驱动详解
实战监听Eureka client的缓存更新
What are open source software, free software, copyleft and CC? Can't you tell them clearly?

论文阅读【Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset】
![Vulnhub | dc: 3 | [actual combat]](/img/97/e5ba86f2694fe1705c13c60484cff6.png)
Vulnhub | dc: 3 | [actual combat]
![Vulnhub | DC: 4 | [combat]](/img/33/b7422bdb18f39e9eb55855dbf1d584.png)
Vulnhub | DC: 4 | [combat]

Does huangrong really exist?

目标检测中的多尺度特征结合方式
随机推荐
Dongyuhui, the "square face teacher", responded that the popularity was declining: do a good job of live broadcasting of agricultural products to benefit farmers and consider supporting education
Basic use of check boxes and implementation of select all and invert selection functions
Optimize your gradle module with a clean architecture
APM performance monitoring practice of jubasha app
Vulnhub | DC: 3 |【实战】
开源技术交流丨批流一体数据同步引擎ChunJun数据还原-DDL功能模块解析
Crawler frame
Go data types (II) overview of data types supported by go and Boolean types
Focus! Ten minutes to master Newton convex optimization
Data assets are king, analyzing the relationship between enterprise digital transformation and data asset management
Ad object of Active Directory
十多年前的入职第一天
GTEST death test
Arclayoutview: implementation of an arc layout
MySQL brochure notes 5 InnoDB record storage structure
5-旋转的小菊-旋转画布和定时器
Interpretation of the most dirty technology in history, I can understand 60 it terms in seconds
为什么用生长型神经气体网络(GNG)?
Introduction to typescript and basic types of variable definitions
Openvino series 18 Real time object recognition through openvino and opencv (RTSP, USB video reading and video file reading)