当前位置:网站首页>Learn NLP with Transformer (Chapter 3)
Learn NLP with Transformer (Chapter 3)
2022-07-25 10:17:00 【黑小板】
Task03 BERT
本次学习参照Datawhale开源学习:https://github.com/datawhalechina/learn-nlp-with-transformers
内容大体源自原文,结合自己学习思路有所调整。
个人总结:
一、BERT模型结构基本上就是Transformer的encoder部分。BERT训练过程分为预训练和微调。预训练使用大量语料,减少重复性工作;然后在预训练好的参数基础上增加一个与任务相关的神经网络层,并在该任务的数据上进行微调训,以针对具体任务取得好的效果。
二、BERT基于Masked language model进行预训练。一是将输入文本序列的部分随机Mask掉,让BERT来预测这些被Mask的词语;还有就是判断两个句子是否是相邻句子。
3. BERT
随着Transformer论文和代码的发布,以及它在机器翻译等任务上取得的成果,开始让人们认为它是LSTM的替代品。一部分原因是:1. 因为 Transformer 可以比 LSTM 更好地处理长期依赖,2. Transformer可以对输入进行并行运算。但怎么才能用它来做文本分类呢?你怎么才能使用它来预训练一个语言模型,并能够在其他任务上进行微调?
沿着LSTM语言模型预训练的路子,将LSTM替换成Transformer结构后,直接语言模型预训练的参数给予下游任务监督数据进行微调。与最开始用于翻译seq2seq的Transformer对比来看,相当于只使用了Decoder部分。有了Transformer结构和语言模型任务设计,直接使用大规模未标记的数据不断得预测下一个词:只需要把 7000 本书的文字依次扔给模型 ,然后让它不断学习生成下一个词即可。
BERT是2018年10月由Google AI研究院提出的一种预训练模型。BERT的全称是Bidirectional Encoder Representation from Transformers。BERT旨在通过联合调节所有层中的左右上下文来预训练深度双向表示。因此,只需要一个额外的输出层,就可以对预训练的BERT表示进行微调,从而为广泛的任务(比如回答问题和语言推断任务)创建最先进的模型,而无需对特定于任务进行大量模型结构的修改。
那么BERT具体干了一件什么事情呢?如下图所示,BERT首先在大规模无监督语料上进行预训练,然后在预训练好的参数基础上增加一个与任务相关的神经网络层,并在该任务的数据上进行微调训,最终取得很好的效果。BERT的这个训练过程可以简述为:预训练+微调(finetune),已经成为最近几年最流行的NLP解决方案的范式。

3.1. BERT句子分类
要想很好的理解BERT,最好先理解一下BERT的使用场景,明确一下输入和输出,最后再详细学习BERT的内在模型结构和训练方法。因此,在介绍模型本身涉及的BERT相关概念之前,让我们先看看如何直接应用BERT。
先来看一下如何使用BERT进行句子分类,假设我们的句子分类任务是:判断一个邮件是“垃圾邮件”或者“非垃圾邮件”,如下图所示。当然除了垃圾邮件判断,也可以是其他NLP任务,比如:
- 输入:电影或者产品的评价。输出:判断这个评价是正面的还是负面的。
- 输入:两句话。输出:两句话是否是同一个意思。

为了能够使用BERT进行句子分类,我们在BERT模型上增加一个简单的classifier层,由于这一层神经网络参数是新添加的,一开始只能随机初始化它的参数,所以需要用对应的监督数据来训练这个classifier。由于classifier是连接在BERT模型之上的,训练的时候也可以更新BERT的参数。

3.2. 模型结构
通过上面的例子,了解了如何使用BERT,接下来让我们更深入地了解一下它的工作原理。BERT原始论文提出了BERT-base和BERT—large两个模型,base的参数量比large少一些,可以形象的表示为下图的样子。

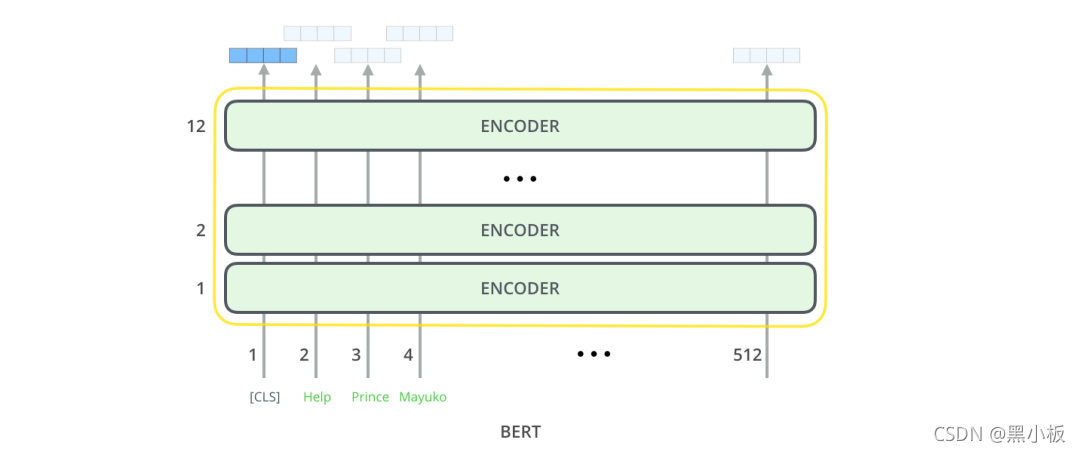
BERT模型结构基本上就是Transformer的encoder部分,BERT-base对应的是12层encoder,BERT-large对应的是24层encoder。

3.3. 模型输入
BERT模型输入有一点特殊的地方是在一句话最开始拼接了一个[CLS] token,如下图所示。这个特殊的[CLS] token经过BERT得到的向量表示通常被用作当前的句子表示。除了这个特殊的[CLS] token,其余输入的单词类似篇章2.2的Transformer。BERT将一串单词作为输入,这些单词多层encoder中不断向上流动,每一层都会经过 Self-Attention和前馈神经网络。

3.4. 模型输出
BERT输入的所有token经过BERt编码后,会在每个位置输出一个大小为 hidden_size(在 BERT-base中是 768)的向量。
对于上面提到的句子分类的例子,我们直接使用第1个位置的向量输出(对应的是[CLS])传入classifier网络,然后进行分类任务,如下图所示。

3.5. 预训练任务:Masked Language Model
知道了模型输入、输出、Transformer结构,那么BERT是如何无监督进行训练的呢?如何得到有效的词、句子表示信息呢?以往的NLP预训练通常是基于语言模型进行,比如给定语言模型的前3个词,让模型预测第4个词。但是,BERT是基于Masked language model进行预训练的:将输入文本序列的部分(15%)单词随机Mask掉,让BERT来预测这些被Mask的词语。如下图所示:

这种训练方式最早可以追溯到Word2vec时代,典型的Word2vec算法便是:基于词C两边的A、B和D、E词来预测出词C。
3.6. 预训练任务:相邻句子判断
除了masked language model,BERT在预训练时,还引入了一个新的任务:判断两个句子是否是相邻句子。如下图所示:输入是sentence A和sentence B,经过BERT编码之后,使用CLS token的向量表示来预测两个句子是否是相邻句子。

3.7. BERT的应用
BERT论文展示了BERT在多种任务上的应用,如下图所示。可以用来判断两个句子是否相似,判断单个句子的情感,用来做抽取式问答,用来做序列标注。

3.8. BERT特征提取
由于BERT模型可以得到输入序列所对应的所有token的向量表示,因此不仅可以使用最后一程BERT的输出连接上任务网络进行微调,还可以直接使用这些token的向量当作特征。比如,可以直接提取每一层encoder的token表示当作特征,输入现有的特定任务神经网络中进行训练。

那么我们是使用最后一层的向量表示,还是前几层的,还是都使用呢?下图给出了一种试验结果:

3.9. 与CNN对比
对于那些有计算机视觉背景的人来说,根据BERT的编码过程,会联想到计算机视觉中使用VGGNet等网络的卷积神经网络+全连接网络做分类任务,如下图所示,基本训练方法和过程是类似的。

3.10. 词嵌入(Embedding)进展
回顾词嵌入
单词不能直接输入机器学习模型,而需要某种数值表示形式,以便模型能够在计算中使用。通过Word2Vec,我们可以使用一个向量(一组数字)来恰当地表示单词,并捕捉单词的语义以及单词和单词之间的关系(例如,判断单词是否相似或者相反,或者像 “Stockholm” 和 “Sweden” 这样的一对词,与 “Cairo” 和 "Egypt"这一对词,是否有同样的关系)以及句法、语法关系(例如,“had” 和 “has” 之间的关系与 “was” 和 “is” 之间的关系相同)。
人们很快意识到,相比于在小规模数据集上和模型一起训练词嵌入,更好的一种做法是,在大规模文本数据上预训练好词嵌入,然后拿来使用。因此,我们可以下载由 Word2Vec 和 GloVe 预训练好的单词列表,及其词嵌入。下面是单词 “stick” 的 Glove 词嵌入向量的例子(词嵌入向量长度是 200)。

单词 “stick” 的 Glove 词嵌入embedding向量表示:一个由200个浮点数组成的向量(四舍五入到小数点后两位)。
由于这些向量都很长,且全部是数字,所以在文章中我使用以下基本形状来表示向量:

语境问题
如果我们使用 Glove 的词嵌入表示方法,那么不管上下文是什么,单词 “stick” 都只表示为一个向量。一些研究人员指出,像 “stick” 这样的词有多种含义。为什么不能根据它使用的上下文来学习对应的词嵌入呢?这样既能捕捉单词的语义信息,又能捕捉上下文的语义信息。于是,语境化的词嵌入模型应运而生:ELMO。

语境化的词嵌入,可以根据单词在句子语境中的含义,赋予不同的词嵌入。
ELMo没有对每个单词使用固定的词嵌入,而是在为每个词分配词嵌入之前,查看整个句子,融合上下文信息。它使用在特定任务上经过训练的双向LSTM来创建这些词嵌入。
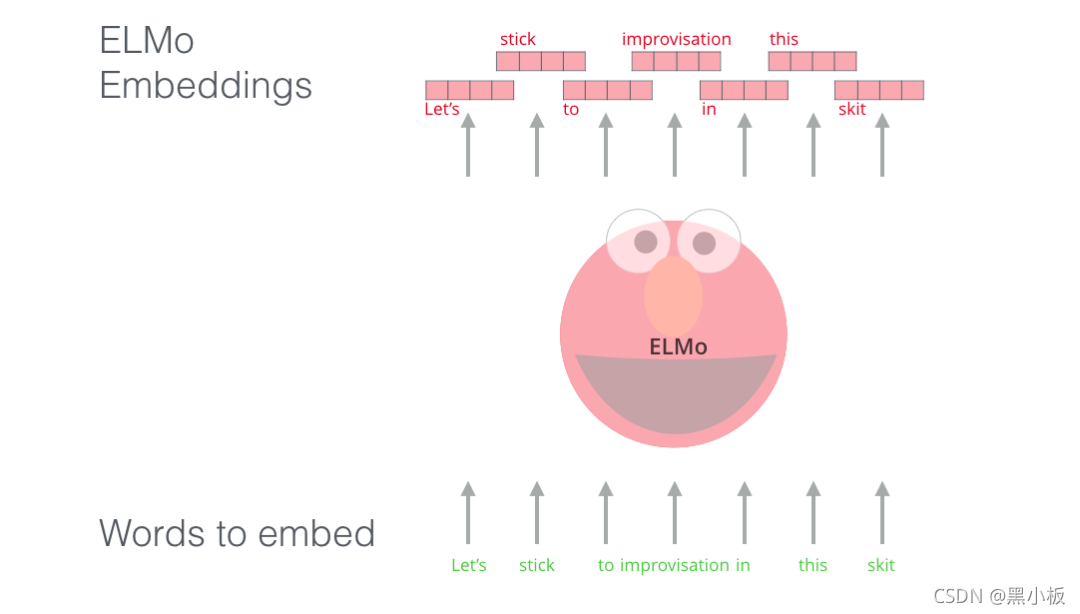
ELMo 在语境化的预训练这条道路上迈出了重要的一步。ELMo LSTM 会在一个大规模的数据集上进行训练,然后我们可以将它作为其他语言处理模型的一个部分,来处理自然语言任务。
那么 ELMo 的秘密是什么呢?
ELMo 通过训练,预测单词序列中的下一个词,从而获得了语言理解能力,这项任务被称为语言建模。要实现 ELMo 很方便,因为我们有大量文本数据,模型可以从这些数据中学习,而不需要额外的标签。

ELMo预训练过程是一个典型的语言模型:以 “Let’s stick to” 作为输入,预测下一个最有可能的单词。当我们在大规模数据集上训练时,模型开始学习语言的模式。例如,在 “hang” 这样的词之后,模型将会赋予 “out” 更高的概率(因为 “hang out” 是一个词组),而不是输出 “camera”。
在上图中,我们可以看到 ELMo 头部上方展示了 LSTM 的每一步的隐藏层状态向量。在这个预训练过程完成后,这些隐藏层状态在词嵌入过程中派上用场。

ELMo 通过将LSTM模型的隐藏成表示向量(以及初始化的词嵌入)以某种方式(向量拼接之后加权求和)结合在一起,实现了带有语境化的词嵌入。

边栏推荐
- 【flask高级】结合源码解决flask经典报错:Working outside of application context
- Flask框架——消息闪现
- DICOM medical image viewing and browsing function based on cornerstone.js
- 三万字速通Servlet
- Flask framework - Message flash
- 2021 jd.com written examination summary
- C class library generation, use class library objects to data bind DataGridView
- AI system frontier dynamics issue 43: ONEFLOW V0.8.0 officially released; GPU finds human brain connections; AI doctoral online crowdfunding research topic
- HCIP实验(03)
- Flame framework - Flame WTF form: file upload, verification code
猜你喜欢

HCIA实验(07)综合实验

JS collection
Electromagnetic field and electromagnetic wave experiment I familiar with the application of MATLAB software in the field of electromagnetic field
Qt | 鼠标事件和滚轮事件 QMouseEvent、QWheelEvent

使用Three.js实现炫酷的赛博朋克风格3D数字地球大屏

100W了!

Disabled and readonly and focus issues

【flask高级】结合源码详解flask的运行机制(出入栈)

Acquisition and compilation of UE4 source code

HCIA实验(06)

随机推荐
HCIP实验(04)
redis 哨兵,高可用的执行者
Flask框架——Session与Cookie
微波技术基础实验一 滤波器的设计
BGP联邦实验
Configuration of OSPF protocol (take Huawei ENSP as an example)
Configuration of static routes (take Huawei ENSP as an example)
信号完整性(SI)电源完整性(PI)学习笔记(三十三)102条使信号完整性问题最小化的通用设计规则
湖仓一体电商项目(二):项目使用技术及版本和基础环境准备
基于cornerstone.js的dicom医学影像查看浏览功能
JS bidirectional linked list 02
【信息系统项目管理师】思维导图系列精华汇总
使用Numpy进行高程统计及可视化
js 双向链表 02
2021 CEC written examination summary
Flask框架——Flask-WTF表单:文件上传、验证码
Acquisition and compilation of UE4 source code
API supplement of JDBC
美国机场围棋风格可视化专题图:ArcGIS Pro版本
HCIA experiment (10) nat