当前位置:网站首页>ZUCC_ Principles of compiling language and compilation_ Experiment 05 regular expression, finite automata, lexical analysis
ZUCC_ Principles of compiling language and compilation_ Experiment 05 regular expression, finite automata, lexical analysis
2022-06-24 08:29:00 【The stars don't want to roll】
Compiling language principle and compiling experiment report
| Course name | Programming language principle and compilation |
|---|---|
| Experimental projects | Regular expressions 、 Finite automaton 、 Lexical analysis |
Experimental content
One 、 Reading Courseware , Read textbook No 2 Chapter
Understand lexical elements token The concept of , Understand the types of lexical elements , Lexical semantic value
- Lexical element is the smallest grammatical unit with independent meaning
- identifier ( Variable name , Function name , Class name ……); keyword (if while for function static); constant ( Int ,Float, Complex,Boolean,Symbol…); Operator (+ - * / ^ *= :=); Delimiter ([ ] {} () ; ,); character string (“asf”)
- The identifier is generally the sequence number in the symbol table , For keywords and operators and delimiters can be empty , For constants and strings, it is the sequence number in itself or symbol table
Understand the basics of regular expressions , And the combination method ( choice 、 Connect 、 repeat )
- Regular expressions represent string patterns that conform to a particular format , Used to describe the structure of lexical elements
- If r and s All regular expressions , Respectively represent language L and L(s), that :
- r|s Is a regular expression , The language of expression is
L(r)∪L(s) - rs Is a regular expression , Presentation language
L(r)•L(s) - r* Is a regular expression , Presentation language
(L(r))*
- r|s Is a regular expression , The language of expression is
understand The longest match , Priority
- When the prefix of the input string is successfully matched with multiple end states , Always select the longest prefix to match
- ‘*’ > ‘.’ > ‘|’, The last two are both left-sided
understand p13 2-1 2-2
understand NFA 、DFA,DFA Minimization method
- Deterministic finite automata (DFA): For a given input symbol , Just do the only action ( No, ε Edge transfer )
- Nondeterministic finite automata (NFA): For the same input symbol , There are many actions to choose from
- Treat the state set as a state . Whether the transition of each state on the subset is equivalent , If equivalent , Then these states can be merged .
Automata.js Enter regular expression , View results
Two 、 Write the following regular expression
1、 tabs \t And spaces \t \t
^(\t|\s)*$
2、C/C++ Language notes // /* a/**/sfasfd */ Look for network resources
/\*[^*]*\*+([^/*][^*]*\*+)*/
https://blog.csdn.net/zhangpeterx/article/details/88115338
3、 String constant “this is a string”
^"[a-zA-Z\s]+"$

4、 Floating point numbers 3.14159
^(-?\d+)(\.\d+)?$
https://blog.csdn.net/weixin_39867296/article/details/111611301

Study URL Examples of matching regular expressions
(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]
https://www.cnblogs.com/speeding/p/5097790.html
3、 ... and 、 Please explain what is with practical examples ( p13) The longest matching rule 、 Rule order takes precedence
The longest matching rule : For the input substring ‘if8’, It can be combined with reserved words ‘if’ Match two characters , It can also match the identifier by three characters , Longer matches are preferred here . therefore ‘if8’ Is an identifier. . Another example is using greedy matching in regular matching , For example, expressions : a.*b To match ababab, It will match the longest possible string , Here is ababab.g
Rule order takes precedence : For the input substring ‘if 89’, The first match is the reserved word ‘if’, So change the substring to start with a reserved word .
Four 、 Consider the following regular expression , Draw the corresponding NFA/DFA
( a b ∣ a c ) ∗ ( 0 ∣ 1 ) ∗ 1100 1 ∗ ( 01 ∣ 10 ∣ 00 ) ∗ 11 (ab|ac)^{*}\\ (0|1)^{*} 11001^{*}\\ (01|10|00)^{*} 11 (ab∣ac)∗(0∣1)∗11001∗(01∣10∣00)∗11
1、 structure NFA


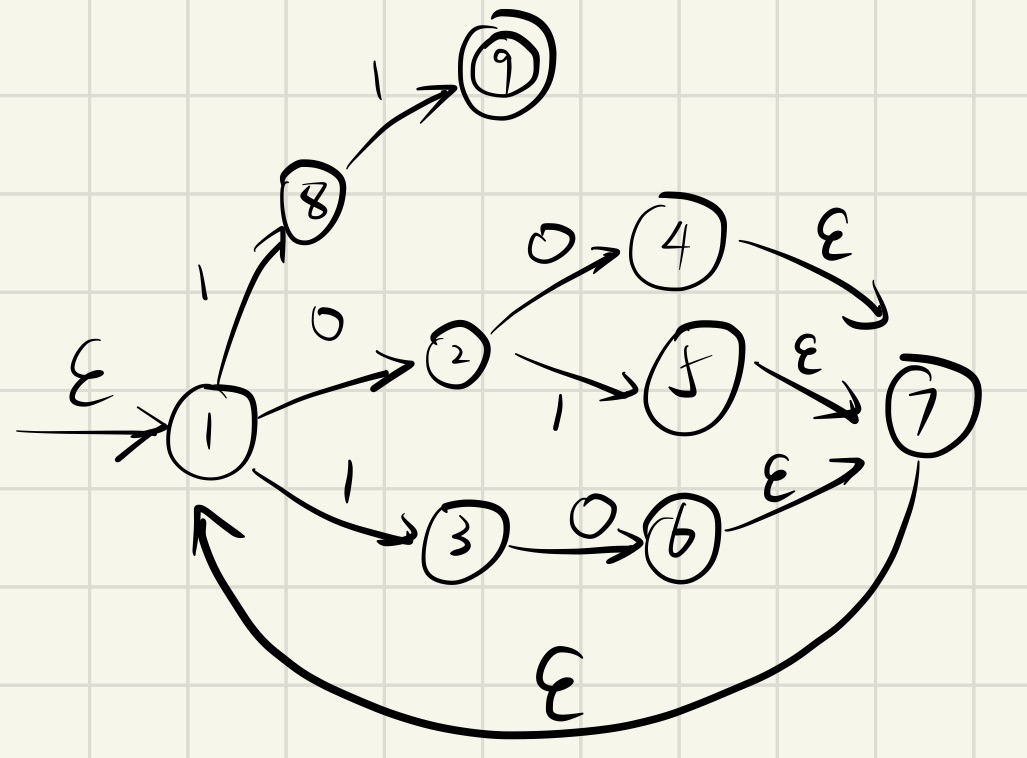
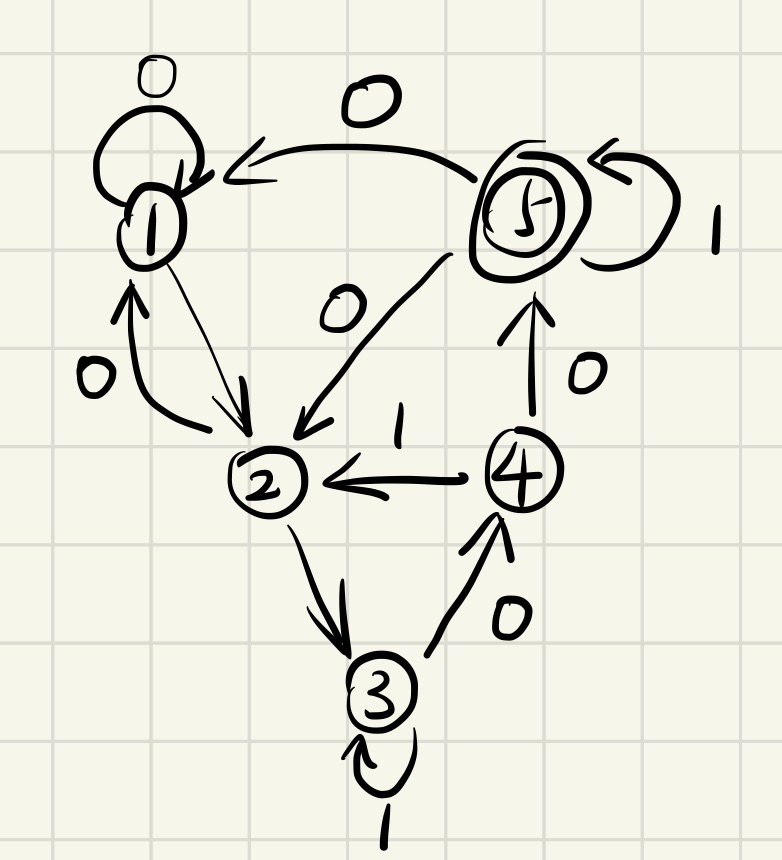
2、 structure DFA



3、 To minimize the DFA


5、 ... and 、 Study code/lex.zip understand lex The operation principle of lexical generation tool
In the actual compiler Lexical analyzer
Lexer, Is parsed by the parserParsercall , See the following topic for details calcvar Code
Lex Is a lexical analyzer generation tool , It supports the use of regular expressions to describe the patterns of lexical units , This paper gives a specification of lexical analyzer , And generate the corresponding implementation code . Lex The input method of the program is called Lex Language , and Lex The program itself is called Lex compiler ,Flex yes Lex An alternative implementation of the compiler ( lex,flex Relationship and cc,gcc The relationship is very similar ).
Lex How to use the program As shown in the figure below :

One Lex The program usually consists of the following parts :
- Declaration part : The declaration section usually includes
Variable,Explicit constantsAnd the definition of regular expressions ,Explicit constantsIs an identifier whose value is a number , Used to represent the type of lexical unit . - Conversion rules : The transformation rule has the following form :
Pattern { action }. Each pattern is a regular expression , You can use the regular definitions given in the declaration section . The action part is a code snippet , Usually use C Language writing . - Auxiliary function : This section defines the functions required for each action , It can also include main function , This part of the code will be put in the output C In the code .
Lex How the program works :
Lex The program provides a function int yylex() And two variables yyleng,yytext For external use ( Usually a parser ) Read , call .
When calling yylex When , The program will start from yyin Read in characters one by one in the input stream pointed to by the pointer , The program found the longest connection with a pattern Pi After the matching string , The string will be saved to yytext variable , And set up yyleng The variable is the length of the string , The string is also a lexical unit analyzed by the lexical analyzer .
then , The lexical analyzer will execute the pattern Pi Corresponding action Ai, And use yylex The function returns Ai The return value of ( It is usually the type of lexical unit ).
https://www.bwangel.me/2019/12/15/flex/
6、 ... and 、 Look at the warehouse https://gitee.com/sigcc/plzoofs Catalog calcvar Language program
1、 Compile the program , function ,https://gitee.com/sigcc/plzoofs/blob/master/calcvar/README.markdown Refer to the instructions to run in debug mode
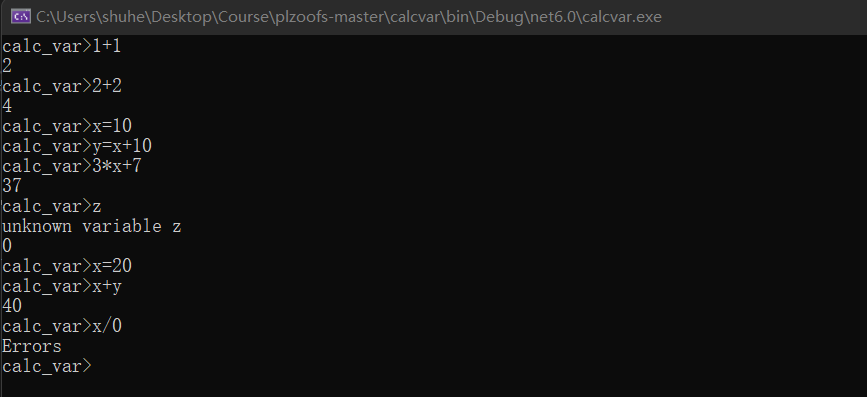
View the lexical elements token, Grammar tree
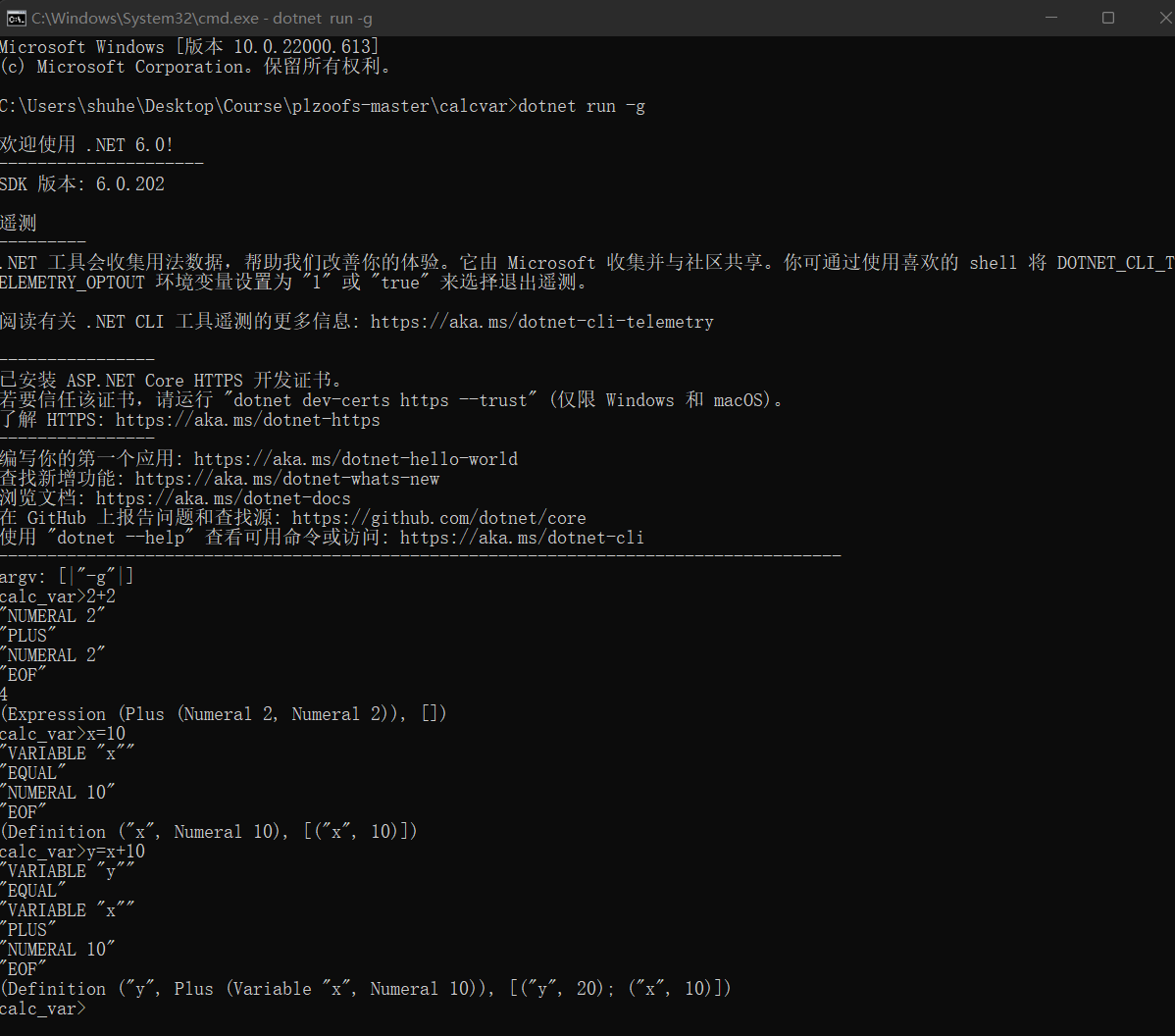
2、 Understand the binding and storage of variable values in the environment
3、 understand The lexical description file lexer.fsl Code for
Random coding knowledge | Using FSLexYacc, the F# lexer and parser (thanos.codes)
4、 Preliminary understanding of grammar description file parser.fsy Code for
dotnet run -vn see dotnet Call the command of lexical analyzer generation tool , The contents are as follows , The specific path is different
dotnet "C:\Users\gm\.nuget\packages\fslexyacc\10.2.0\build\/fslex/netcoreapp3.1\fslex.dll" -o "Scanner.fs" --module Scanner --unicode Scanner.fsl
...
dotnet "C:\Users\gm\.nuget\packages\fslexyacc\10.2.0\build\/fsyacc/netcoreapp3.1\fsyacc.dll" -o "Parser.fs" --module Parser Parser.fsy
dotnet "C:\Users\shuhe\.nuget\packages\fslexyacc\10.2.0\build\fslex\netcoreapp3.1\fslex.dll" -o "Scanner.fs" --module Scanner --unicode Scanner.fsl

dotnet "C:\Users\shuhe\.nuget\packages\fslexyacc\10.2.0\build\/fsyacc\netcoreapp3.1\fsyacc.dll" -o "Parser.fs" --module Parser Parser.fsy

understand fsproj Project file parameters , These parameters are passed to the above command
<FsLex Include="lexer.fsl">
<OtherFlags>--module Lexer --unicode</OtherFlags>
</FsLex>
<FsYacc Include="parser.fsy">
<OtherFlags>--module Parser</OtherFlags>
</FsYacc>
【 translate 】Python Lex Yacc manual - P_Chou - Blog Garden (cnblogs.com)
7、 ... and 、 Study CLex.fsl structure , understand MicroC Lexical analyzer of
Run in debug mode microC Interpreter , compiler -g Specific view ReadME.md
dotnet build -v n interpc.fsproj

dotnet "C:\Users\shuhe\.nuget\packages\fslexyacc\10.2.0\build\fslex\netcoreapp3.1\fslex.dll" -o "CLex.fs" --module CLex --unicode CLex.fsl

dotnet "C:\Users\shuhe\.nuget\packages\fslexyacc\10.2.0\build\/fsyacc\netcoreapp3.1\fsyacc.dll" -o "CPar.fs" --module CPar CPar.fsy


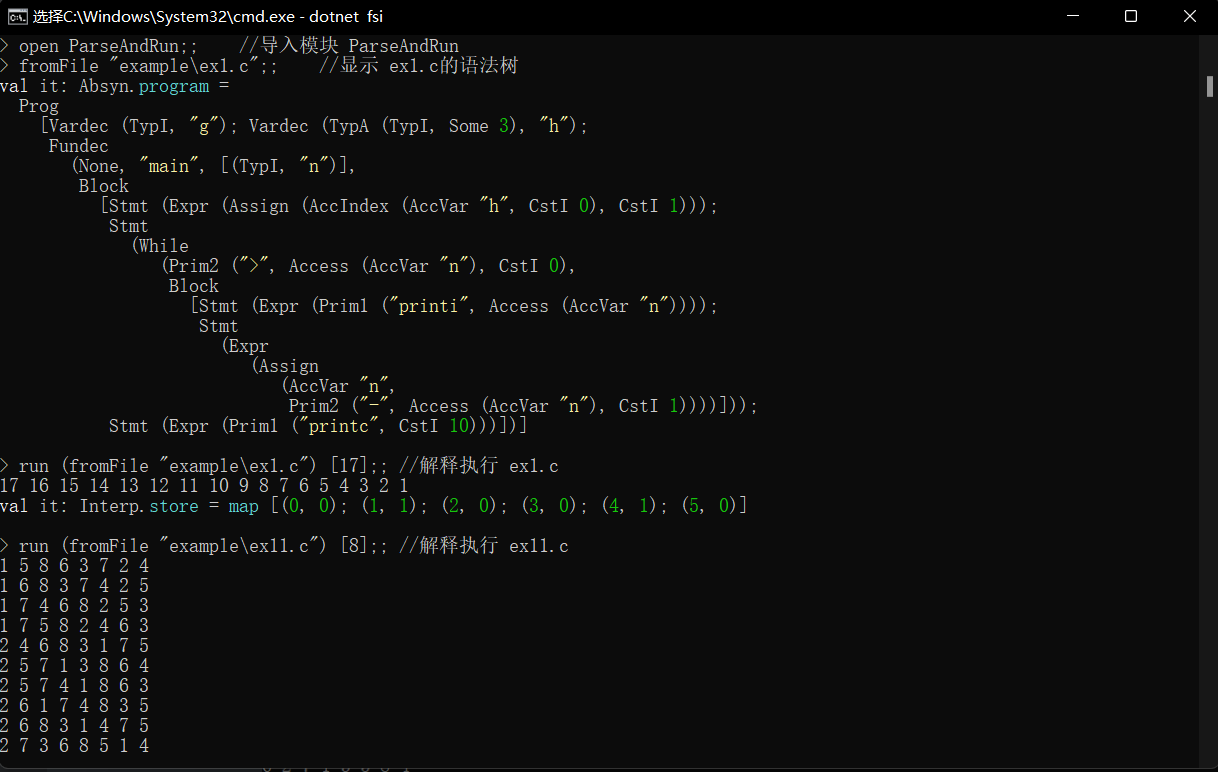

understand The meaning of the word element , Pay attention to the types of lexical elements , And the corresponding semantic value <Type,Value>
“token” There are many books that translate the word “ mark ”, We think that the more appropriate translation should be “ Word symbols ”. It is a programming language “ The smallest lexical unit with independent meanings ”, In this sense, it is related to our natural language “ word ” Have the same meaning . however , It's not exactly the same , Because of the “token” It's not just about “ word ”, It also includes punctuation marks 、 The operator 、 Separator, etc . Translate it into “ Word symbols ” Just to reflect this – spot . But for the sake of brevity , We use “ word ” The word" .-— translator's note
VOID Semantic value and type are the same
NAME “n” The type is
NAMEThe semantic value is “n”CSTINT 1 The type is
CSTINTThe semantic value is “1”
~ microc>dotnet run -p .\interpc.fsproj -g ex1.c 8
Micro-C interpreter v 1.1.0 of 2021-3-22
interpreting ex1.c ...inputargs:[8]
Token:
VOID, NAME "main", LPAR, INT, NAME "n", RPAR, LBRACE, WHILE, LPAR, NAME "n", GT, CSTINT 0, RPAR, LBRACE, PRINT, NAME "n", SEMI, NAME "n", ASSIGN, NAME "n", MINUS, CSTINT 1, SEMI, RBRACE, PRINTLN, SEMI, RBRACE, EOF

Understand keyword handling
- identifier Name Put it in the keyword function keyword The final treatment of
Comprehension notes To deal with
//A singleSingle line comment processing rules , Call the response handler ,
// Parameter is lexbuf
// After processing lexbuf The content has been updated , Comments section filter
// call Token The rule function continues the processing after the comment section
| “/*” { Comment lexbuf; Token lexbuf } // Multiline comment , call Comment The rules
/* */Multiple linesMultiline comment , call Comment The rules ,
and Comment = parse
| “/*” { Comment lexbuf; Comment lexbuf } // Nested processing of annotations
| “*/” { () } // End of comment processing
| ‘\n’ { lexbuf.EndPos <- lexbuf.EndPos.NextLine; Comment lexbuf } // Comments cross line processing
| (eof | ‘\026’) { failwith “Lexer error: unterminated comment” } // Multiline comments are not enclosed
| _ { Comment lexbuf } // In any other case, continue to process subsequent characters
and EndLineComment = parse
| ‘\n’ { lexbuf.EndPos <- lexbuf.EndPos.NextLine } // Update end of line position , return
| (eof | ‘\026’) { () } // End of file ,26 yes CTRL+Z Of ASCII code , It is also a terminator , () Exit back
| _ { EndLineComment lexbuf } // Continue to read lexbuf Middle next character
Understand the blank Line break To deal with
| '\n' { lexbuf.EndPos <- lexbuf.EndPos.NextLine; Token lexbuf } // Line feed // EndPos It's a built-in type Position Example , Indicates the end position of the current line
Understand the handling of strings (MicroC Only lexical analysis , Not fully implemented )
| ‘"’ { CSTSTRING (String [] lexbuf) } // Call string processing rules
and String chars = parse | '"' { Microsoft.FSharp.Core.String.concat "" (List.map string (List.rev chars)) } // End of string , By character array chars Construct string // Because it is a list when it is constructed cons :: operation // You need to use List.rev Flip character array // :: Is said Add it to the front | '\\' ['\\' '"' 'a' 'b' 't' 'n' 'v' 'f' 'r'] // character string "\a" After reading lexical analyzer To see is "\\a" { String (cEscape (lexemeAsString lexbuf) :: chars) lexbuf } | "''" { String ('\'' :: chars) lexbuf } | '\\' { failwith "Lexer error: illegal escape sequence" } | (eof | '\026') { failwith "Lexer error: unterminated string" } // End of file... In string | ['\n' '\r'] { failwith "Lexer error: newline in string" } // Carriage return in string | ['\000'-'\031' '\127' '\255'] { failwith "Lexer error: invalid character in string" } // Appears in the string ASCII Control characters | _ { String (char (lexbuf.LexemeChar 0) :: chars) lexbuf } // Will read the 1 Characters added to the temporary chars Array
Understand the handling of escape characters (MicroC Only lexical analysis , Not fully implemented )
// String escape handler let cEscape s = match s with | "\\\\" -> '\\' | "\\\"" -> '\"' | "\\a" -> '\007' | "\\b" -> '\008' | "\\t" -> '\t' | "\\n" -> '\n' | "\\v" -> '\011' | "\\f" -> '\012' | "\\r" -> '\r' | _ -> failwith "Lexer error: impossible C escape"
8、 ... and 、 Big job grouping , And determine the language Decaf/MicroC/ Tiger ... Start to implement lexical analyzer ( Choose your own language )
Big homework lexical part
Read the language specification use
fslexImplement its lexical analyzer- Textbook appendix p360 page Tiger language norm
Note the nested annotation implementation
/* /* */ */Note the string implementation
"" '' " ' ' "
Nine 、 Reading books
The nature of computation The first 3 Chapter The automaton part , Understand the manual implementation of table driven method NFA,DFA Technology
https://bb.zucc.edu.cn/bbcswebdav/users/j04014/books/Understanding.ComputationRuby For language use, see The first 1 Chapter
The first 2 Chapter Will be used later , Preview in advance
Ten 、( Optional ) read JFLAP-simple tutorial.pdf use JFLAP Structural problems in 4 Of NFA/DFA, And screenshot , Keep the file . JFLAP stay bb On soft Directory , The operation mode is
java -jar JFLAP.jar
边栏推荐
- 487. number of maximum consecutive 1 II ●●
- Scénarios d'utilisation de la promesse
- Five level classification of loans
- Small sample fault diagnosis - attention mechanism code - Implementation of bigru code parsing
- 有关iframe锚点,锚点出现上下偏移,锚点出现页面显示问题.iframe的srcdoc问题
- Longhorn installation and use
- 将mysql的数据库导出xxx.sql,将xxx.sql文件导入到服务器的mysql中。项目部署。
- Permission model DAC ACL RBAC ABAC
- 【微服务~Nacos】Nacos服务提供者和服务消费者
- Dart development server, do I have a fever?
猜你喜欢

搜索与推荐那些事儿

ZUCC_编译语言原理与编译_实验03 编译器入门

Opencv实现图像的基本变换

Permission model DAC ACL RBAC ABAC
![Fundamentals of 3D mathematics [17] inverse square theorem](/img/59/bef931d96883288766fc94e38e0ace.png)
Fundamentals of 3D mathematics [17] inverse square theorem

LabVIEW查找n个元素数组中的质数

2021-03-09 comp9021 class 7 Notes

ZUCC_编译语言原理与编译_实验04 语言与文法

Swift foundation features unique to swift
问题4 — DatePicker日期选择器,2个日期选择器(开始、结束日期)的禁用
随机推荐
All you know is the test pyramid?
Ordinary token
1279_ Vsock installation failure resolution when VMware player installs VMware Tools
Easyplayerpro win configuration full screen mode can not be full screen why
2021-03-09 comp9021 class 7 Notes
Five level classification of loans
3D数学基础[十七] 平方反比定理
Future trends in automated testing
2021-03-16 comp9021 class 9 notes
51 single chip microcomputer_ External interrupt and timer / Counter interrupt
Getting started with ffmpeg
JVM underlying principle analysis
Paper notes: multi label learning dm2l
51单片机_外部中断 与 定时/计数器中断
Detailed explanation of etcd backup and recovery principle and actual record of stepping on the pit
dhcp、tftp基础
[graduation season] Hello stranger, this is a pink letter
Tool functions – get all files in the project folder
到底哪一首才是唐诗第一?
问题4 — DatePicker日期选择器,2个日期选择器(开始、结束日期)的禁用