当前位置:网站首页>Read lsd-slam: large scale direct monolithic slam
Read lsd-slam: large scale direct monolithic slam
2022-06-25 04:16:00 【YMWM_】
Catalog
Abstract
We propose a direct ( No features ) Monocular SLAM Algorithm , Compared with the most advanced direct method at present , This algorithm allows the construction of large-scale and consistent environment maps . A high-precision pose estimation method based on direct image alignment is adopted , At the same time, we use the position and attitude map of the key frame and the corresponding semi dense depth map , Real time reconstruction of 3D environment . This is obtained by filtering the small baseline binocular camera . The analytical representation of the scale shift allows the method to be applied to challenging sequences , Including those sequences with large scale changes in the scene . There are two innovations in this paper :(1) stay s i m ( 3 ) \mathfrak{sim(3)} sim(3) A new direct trace method running on , Thus the scale shift can be detected clearly ;(2) An elegant probabilistic solution , The depth value with noise is included in the tracking . The resulting direct monocular SLAM The system is in CPU Run in real time .
1 Introduce
Real time monocular simultaneous positioning and mapping (SLAM) And 3D reconstruction have become more and more popular research topics . Two main reasons are :(1) Their applications in the field of Robotics , Especially in drones (UAV) Navigation applications ;(2) Augmented reality and virtual reality applications are slowly entering the mass market .
Monocular SLAM One of the main benefits of , And one of the biggest challenges , Is its inherent scale ambiguity . The scale of the real world cannot be observed , And will drift over time , This is one of the main sources of error . Its advantage is that it can seamlessly switch between environments of different sizes , Such as indoor desk environment and large-scale outdoor environment . On the other hand , Sensor with scale , Such as depth camera or binocular camera , The range of reliable measurements available is limited , Therefore, this flexibility cannot be provided .
1.1 Related work
A Feature-based approach
Feature-based approach ( Including filter based and key frame based ) The basic idea of is to put the whole problem , That is to estimate the geometric information from the image , Break down into two consecutive steps . First , Extract a set of feature observations from the image . secondly , The position of the camera and the geometry of the scene are calculated as a function of these feature observations .
Although this decoupling simplifies the whole problem , But it also has an important limitation . Only information that conforms to the feature type can be used . especially , When using keys , Contains information about straight or curved edges , Especially in the artificial environment, it forms a large part of the image , Will be discarded . In the past, there have been several methods to compensate for this defect by including edge based or even region based features . However , Because the estimation of high-dimensional feature space is tedious , It is rarely used in practical applications . In order to obtain dense reconstruction , Using multi view geometry, the dense map is reconstructed continuously by using the estimated camera pose .
B Direct method
Direct vision odometer (VO) Method to bypass this limitation , Directly optimize the gray level of the image to obtain geometry , This method can use all the information in the image . In addition to higher accuracy and robustness , Especially in an environment with few key points , This method can provide more information about the environment Geometry , This is very valuable for robotics or augmented reality applications .
although RGB-D Direct image alignment algorithms for cameras or binocular sensors have been well established , But it is not until recently that monocular direct VO Algorithm . In the literature [20,21,24] in , Accurate and completely dense depth maps are calculated using variational formulas , But the calculation of this method is very large , Need the most advanced GPU Run in real time . In the literature [9] in , A semi dense depth filtering formula is proposed , It greatly reduces the computational complexity , This method allows you to CPU Even running in real time on modern smartphones . By combining direct tracking with keys , The literature [10] The high frame rate real-time operation is realized on the embedded platform . However , All these methods are pure visual odometers , They only track the motion of the camera locally , Does not establish a consistent 、 Global and environment map with loopback .
C Pose optimization
This is a famous SLAM technology , For building a consistent global map . The world is represented by several keyframes connected by pose constraints , You can use a common graph optimization framework ( Such as g2o) To optimize .
In the literature [14] in , This paper presents a method based on pose graph RGB-D SLAM Method , This method introduces geometric errors , Allows tracking in scenes with fewer textures . To solve the problem of monocular SLAM Scale drift in , The literature [23] A key point based monocular SLAM System , The system expresses the camera pose as 3D Similarity transformation , Instead of rigid body motion .
1.2 Contribution and outline
We propose a large-scale direct monocular SLAM(LSD-SLAM) Method , This method can not only track the motion of the camera locally , A consistent large-scale environmental map can also be established ( See the picture 1 Sum graph 2). This method uses direct image alignment , Combined with the literature [9] Filter based semi dense depth map estimation is first proposed in . The global map is represented in the form of a pose diagram , Keyframes as vertices ,3D Similar transformation as edge , Elegantly integrated into the scale of the environment , It also allows the detection and correction of cumulative drift . The method in CPU Run in real time , Even run as a odometer on modern smartphones . The main contributions of this paper are as follows .(1) A monocular for large-scale direct SLAM Framework , In particular, a new scale aware image alignment algorithm , The similarity transformation between two key frames can be estimated directly ξ ∈ s i m ( 3 ) \xi \in \mathfrak{sim}(3) ξ∈sim(3).(2) The probability consistently incorporates the uncertainty of the estimated depth into the tracking .


2 Preliminary preparation (preliminaries)
In this chapter , We briefly summarize the relevant mathematical concepts and symbols . Specially , We use lie algebra to express the position and posture ( The first 2.1 section ), The weighted least squares of direct image alignment on the Lee flow is derived ( The first 2.2 section ), It also briefly introduces the propagation of uncertainty ( The first 2.3 section ).
Symbol . We use bold capital letters ( R \pmb{R} RRR) According to matrix , Use bold lowercase letters to represent vectors ( ξ \pmb{\xi} ξξξ). The order of the matrix n n n Line record [ ⋅ ] n [\cdot]_n [⋅]n. The image is recorded as I : Ω → R I:\ \Omega \rightarrow \mathbb{R} I: Ω→R, among Ω ⊂ R 2 \Omega \subset \mathbb{R}^2 Ω⊂R2 Is the normalized pixel coordinates , R \mathbb{R} R Represents a one-dimensional real number . Pixel level inverse depth map is marked as D : Ω → R + D:\ \Omega \rightarrow \mathbb{R}^+ D: Ω→R+. The pixel level inverse depth variance graph is marked as V : Ω → R + V: \ \Omega \rightarrow \mathbb{R}^+ V: Ω→R+. In the whole article , We use d d d To indicate the depth of the road marking z z z Reciprocal , namely d = z − 1 d=z^{-1} d=z−1.
2.1 3D Rigid body transformation and similarity transformation
3D Rigid body transformation . 3D rigid body transformation G ∈ S E ( 3 ) \pmb{G} \in \mathrm{SE}(3) GGG∈SE(3) Represents the rotation and translation of three dimensions , Write it down as
G = ( R t 0 1 ) R ∈ S O ( 3 ) , t ∈ R 3 (1) \pmb{G}=\begin{pmatrix} \pmb{R} & \pmb{t} \\ \pmb{0} & 1 \end{pmatrix} \ \ \pmb{R} \in \mathrm{SO}(3), \ \pmb{t}\in \mathbb{R}^3 \tag{1} GGG=(RRR000ttt1) RRR∈SO(3), ttt∈R3(1)
In the process of optimization , Need a minimum representation of camera pose , It consists of the corresponding elements of the related Lie algebra ξ ∈ s e ( 3 ) \pmb{\xi} \in \mathfrak{se}(3) ξξξ∈se(3) give . Lie algebras are transformed into Lie groups by exponential mapping , namely G = e x p s e ( 3 ) ( ξ ) \pmb{G}=\mathrm{exp}_{se(3)}(\pmb{\xi}) GGG=expse(3)(ξξξ). The inverse transformation of the mapping is ξ = l o g S E ( 3 ) ( G ) \pmb{\xi}=\mathrm{log}_{SE(3)}(\pmb{G}) ξξξ=logSE(3)(GGG). Besides , We use s e ( 3 ) \mathfrak{se}(3) se(3) To represent the pose , Write vectors directly ξ ∈ R 6 \pmb{\xi}\in \mathbb{R}^6 ξξξ∈R6. From the coordinate system i i i Move a point to the coordinate system j j j The transformation of is recorded as ξ j i \pmb{\xi}_{ji} ξξξji. For convenience , We will connect the pose and pose operators ∘ : s e ( 3 ) × s e ( 3 ) → s e ( 3 ) \circ: \mathfrak{se}(3) \times \mathfrak{se}(3) \rightarrow \mathfrak{se}(3) ∘:se(3)×se(3)→se(3) Defined as ,
ξ k i : = ξ k j ∘ ξ j i : = l o g S E ( 3 ) ( e x p s e ( 3 ) ( ξ k j ) ⋅ e x p s e ( 3 ) ( ξ j i ) ) (2) \pmb{\xi}_{ki} :=\pmb{\xi}_{kj} \circ \pmb{\xi}_{ji} := \mathrm{log}_{SE(3)}\big( \mathrm{exp}_{se(3)}(\pmb{\xi}_{kj}) \cdot \mathrm{exp}_{se(3)}(\pmb{\xi}_{ji}) \big) \tag{2} ξξξki:=ξξξkj∘ξξξji:=logSE(3)(expse(3)(ξξξkj)⋅expse(3)(ξξξji))(2)
further , We define the three-dimensional projection warp function ω \omega ω, It takes a point in the image p \pmb{p} ppp And its inverse depth d d d adopt ξ \pmb{\xi} ξξξ To the camera coordinate system ,
ω ( p , d , ξ ) : = ( x ′ / z ′ y ′ / z ′ 1 / z ′ ) w i t h ( x ′ y ′ z ′ 1 ) = e x p s e ( 3 ) ( ξ ) ( p x / d p y / d 1 / d 1 ) (3) \omega(\pmb{p},d,\xi):=\begin{pmatrix} x'/z' \\ y' / z' \\ 1/z' \end{pmatrix} \ \ with \ \ \begin{pmatrix} x' \\ y' \\ z' \\ 1 \end{pmatrix} = \mathrm{exp}_{se(3)}(\pmb{\xi})\begin{pmatrix} \pmb{p}_x/d \\ \pmb{p}_y/d \\ 1/d\\ 1 \end{pmatrix} \tag{3} ω(ppp,d,ξ):=⎝⎛x′/z′y′/z′1/z′⎠⎞ with ⎝⎜⎜⎛x′y′z′1⎠⎟⎟⎞=expse(3)(ξξξ)⎝⎜⎜⎛pppx/dpppy/d1/d1⎠⎟⎟⎞(3)
3D Similarity transformation . A three-dimensional similarity transformation S ∈ S i m ( 3 ) \pmb{S} \in Sim(3) SSS∈Sim(3) Including rotation 、 Zoom and pan .
S = ( s R t 0 1 ) w i t h R ∈ S O ( 3 ) , t ∈ R 3 a n d s ∈ R + (4) \pmb{S}=\begin{pmatrix} s\pmb{R} & \pmb{t} \\ \pmb{0} & 1 \end{pmatrix} \ \ with \ \ \pmb{R} \in SO(3), \ \pmb{t}\in \mathbb{R}^3 \ and \ s\in \mathbb{R}^+ \tag{4} SSS=(sRRR000ttt1) with RRR∈SO(3), ttt∈R3 and s∈R+(4)
For rigid body transformations , The minimal representation is given by the related Lie algebra ξ ∈ s i m ( 3 ) \pmb{\xi} \in \mathfrak{sim}(3) ξξξ∈sim(3) Given , Now it has an extra degree of freedom , namely ξ ∈ R 7 \pmb{\xi} \in \mathbb{R}^7 ξξξ∈R7. Exponential mapping and logarithmic mapping , Pose connection (concatenation) And projection warp Functions can be similarly defined as s e ( 3 ) \mathfrak{se}(3) se(3) The situation of , Further details can be found in the literature [23].
2.2 Weighted Gauss Newton optimization methods on Lie algebraic manifolds
The Gauss Newton method is used to minimize the photometric error of the two images ,
E ( ξ ) = ∑ i ( I r e f ( p i ) − I ( ω ( p i , D r e f ( p i ) , ξ ) ) ) 2 ⏟ = : r i 2 ( ξ ) (5) E(\pmb{\xi})=\sum_i \underbrace{\big( I_{ref}(\pmb{p}_i) - I(\omega(\pmb{p}_i, D_{ref}(\pmb{p}_i), \pmb{\xi})) \big)^2}_{=:r_i^2(\xi)} \tag{5} E(ξξξ)=i∑=:ri2(ξ)(Iref(pppi)−I(ω(pppi,Dref(pppi),ξξξ)))2(5)
Suppose there are independent identically distributed Gaussian residuals , The above formula gives a pair of ξ \pmb{\xi} ξξξ Maximum likelihood estimation of . We use the left multiplication formula : From the initial estimate ξ ( 0 ) \pmb{\xi}^{(0)} ξξξ(0) Start , In each iteration , By solving E E E Gauss Newton second order approximation of the minimum value to calculate the left multiplication increment δ ξ ( n ) \delta \pmb{\xi}^{(n)} δξξξ(n).
δ ξ ( n ) = − ( J T J ) − 1 J T r ( ξ ( n ) ) w i t h J = ∂ r ( ϵ ∘ ξ ( n ) ) ∂ ϵ ∣ ϵ = 0 (6) \delta \pmb{\xi}^{(n)} = -(\pmb{J}^T\pmb{J})^{-1}\pmb{J}^T\pmb{r}(\pmb{\xi}^{(n)}) \ \ with \ \ \pmb{J} = \frac{\partial \pmb{r}(\pmb{\epsilon} \circ \pmb{\xi}^{(n)})}{\partial \pmb{\epsilon}} \bigg|_{\epsilon=0} \tag{6} δξξξ(n)=−(JJJTJJJ)−1JJJTrrr(ξξξ(n)) with JJJ=∂ϵϵϵ∂rrr(ϵϵϵ∘ξξξ(n))∣∣∣∣ϵ=0(6)
among J \pmb{J} JJJ Is the stacking residual vector r = ( r 1 , ⋯ , r n ) T \pmb{r} = (r_1,\cdots,r_n)^T rrr=(r1,⋯,rn)T Multiply left increment ϵ \pmb{\epsilon} ϵϵϵ The derivative of , J T J \pmb{J}^T\pmb{J} JJJTJJJ Gauss Newton method E E E The Hessian matrix approximation of . Then the new estimate is obtained by multiplying the calculated update ,
ξ ( n + 1 ) = δ ξ ( n ) ∘ ξ ( n ) (7) \pmb{\xi}^{(n+1)}=\delta \pmb{\xi}^{(n)} \circ \pmb{\xi}^{(n)} \tag{7} ξξξ(n+1)=δξξξ(n)∘ξξξ(n)(7)
In order to be robust to outliers from occlusion or reflection , Researchers have proposed different weighting schemes , Thus, an iterative reweighted least square problem is obtained . In each iteration , Calculate a weight matrix W = W ( ξ ( n ) ) \pmb{W}=\pmb{W}(\pmb{ξ}^{(n)}) WWW=WWW(ξξξ(n)), Reduce the weight of larger residuals . The error function of iterative solution is ,
E ( ξ ) = ∑ i w i ( ξ ) r i 2 ( ξ ) (8) E(\pmb{\xi})=\sum_iw_i(\pmb{\xi})r_i^2(\pmb{\xi}) \tag{8} E(ξξξ)=i∑wi(ξξξ)ri2(ξξξ)(8)
Update the calculation to ,
δ ξ ( n ) = − ( J T W J ) − 1 J T W r ( ξ ( n ) ) (9) \delta \pmb{\xi}^{(n)}=-(\pmb{J}^T\pmb{W}\pmb{J})^{-1}\pmb{J}^T\pmb{W}r(\pmb{\xi}^{(n)}) \tag{9} δξξξ(n)=−(JJJTWWWJJJ)−1JJJTWWWr(ξξξ(n))(9)
Assume that the residuals are independent , Inverse of Hessian matrix of the last iteration ( J T W J ) − 1 (\pmb{J}^T\pmb{WJ})^{-1} (JJJTWJWJWJ)−1 Is the covariance of the left multiply error ∑ ξ \pmb{\sum}_{\xi} ∑∑∑ξ It is estimated that ,
ξ ( n ) = ϵ ∘ ξ t r u e w i t h ϵ ∼ N ( 0 , Σ ξ ) (10) \pmb{\xi}^{(n)} = \pmb{\epsilon} \circ \pmb{\xi}_{true} \ \ with \ \ \pmb{\epsilon} \sim \mathcal{N}(0,\pmb{\Sigma}_{\xi}) \tag{10} ξξξ(n)=ϵϵϵ∘ξξξtrue with ϵϵϵ∼N(0,ΣΣΣξ)(10)
actually , The residuals are highly correlated , therefore Σ ξ Σ_ξ Σξ Just a lower bound —— But it contains valuable information about the correlation between noises in different degrees of freedom . Be careful , We follow the left multiplication convention , Equivalent results can be obtained by using the right multiplication convention . However , Estimated covariance Σ ξ Σ_ξ Σξ Depending on the order of multiplication , When used in the pose graph optimization framework , This has to be taken into account . The left multiplication convention used here is consistent with the literature [23] Agreement , And for example ,g2o The default type implementation in is the right multiplication convention .
2.3 The spread of uncertainty
Uncertainty propagation is a statistical tool , Used to derive functions f ( X ) f(\pmb{X}) f(XXX) The uncertainty of the output , Input by it X \pmb{X} XXX The uncertainty of . hypothesis X \pmb{X} XXX It's a Gaussian distribution , The covariance is Σ X \pmb{Σ_X} ΣXΣXΣX, be f ( X ) f(\pmb{X}) f(XXX) The covariance of can be approximated ( Use f Jacobian matrix of J f \pmb{J}_f JJJf) by ,
Σ f ≈ J f Σ X J f T (11) \pmb{\Sigma}_f \approx \pmb{J}_f \pmb{\Sigma_X}\pmb{J}_f^T \tag{11} ΣΣΣf≈JJJfΣXΣXΣXJJJfT(11)
3 Large scale direct monocular SLAM
We started with 3.1 The complete algorithm is outlined in section , And in 3.2 Section briefly introduces the representation of the global map . And then in 3.3 section ( Track new frames )、3.4 section ( Depth map estimation )、3.5 section ( Keyframe to keyframe tracking ) And finally 3.6 section ( Map optimization ) Three main components of the algorithm are described in .
3.1 Complete algorithm
The algorithm consists of tracking 、 Depth map estimation and map optimization are three main parts , Pictured 3 Shown .

track The component keeps track of new camera images . in other words , It uses the pose of the previous frame as initialization , Estimate their rigid body pose relative to the current keyframe ξ ∈ s e ( 3 ) \pmb{\xi} \in \mathfrak{se}(3) ξξξ∈se(3).
Depth map estimation The component uses the tracked frame to refine or replace the current key frame . Depth is achieved by pixel level filtering , Plus the literature [9] The interleaved space regularization proposed in . If the camera moves too far , A new key frame will be initialized by projection from the points in the existing near key frame .
Once a keyframe is replaced with a tracking reference , Therefore, its depth map will not be further refined (refine), It will be Map optimization Components are merged into the global map . To detect loop and scale drift , The similarity transformation from the current frame to the nearest key frame is estimated by scale perception ξ ∈ s i m ( 3 ) \pmb{\xi} \in \mathfrak{sim}(3) ξξξ∈sim(3).
initialization . To guide LSD-SLAM System , Initialize the first key frame with random depth map and large variance . In the first few seconds , If the camera has enough translational motion , The algorithm will “ lock ” To a specific configuration , And converges to the correct depth configuration after several key frames are propagated . The attached video shows some examples . A more comprehensive assessment of this ability to converge without special initial guidance is beyond the scope of this article , And leave it for future work .
3.2 Map representation
The map is represented as the pose map of the key frame . Every keyframe K i \mathcal{K}_i Ki Contains camera pictures I i : Ω i → R I_i: \Omega_i\rightarrow \mathbb{R} Ii:Ωi→R And inverse depth map D i : Ω D i → R + D_i:\Omega_{D_i}\rightarrow \mathbb{R}^+ Di:ΩDi→R+ And inverse depth variance V i : Ω D i → R + V_i:\Omega_{D_i}\rightarrow \mathbb{R}^+ Vi:ΩDi→R+. Be careful , The depth map and variance are defined only for a subset of pixels Ω D i ⊂ Ω i \Omega_{D_i} \subset \Omega_i ΩDi⊂Ωi, Contains all image regions near a sufficiently large gray gradient , So it is semi dense . Edges between keyframes contain similar transformations ξ j i ∈ s i m ( 3 ) \pmb{\xi}_{ji}\in \mathfrak{sim}(3) ξξξji∈sim(3) Relative alignment of , And the corresponding covariance matrix Σ j i \pmb{\Sigma}_{ji} ΣΣΣji.
3.3 Track new frames : direct s e ( 3 ) \mathfrak{se}(3) se(3) image alignment
From existing keyframes K i = ( I i , D i , V i ) \mathcal{K}_i=(I_i,D_i,V_i) Ki=(Ii,Di,Vi) Start , New images are calculated by minimizing variance normalized photometric errors I j I_j Ij The relative three-dimensional pose of ξ j i ∈ s e ( 3 ) \pmb{\xi}_{ji} \in \mathfrak{se}(3) ξξξji∈se(3),
E p ( ξ j i ) = ∑ p ∈ Ω D i ∥ r p 2 ( p , ξ j i ) σ r p ( p , ξ j i ) 2 ∥ δ (12) E_p(\pmb{\xi}_{ji})=\sum_{p\in \Omega_{D_i}} \bigg \Vert \frac{r_p^2(p,\xi_{ji})}{\sigma^2_{r_p(p,\xi_{ji})}} \bigg \Vert_\delta \tag{12} Ep(ξξξji)=p∈ΩDi∑∥∥∥∥σrp(p,ξji)2rp2(p,ξji)∥∥∥∥δ(12)
w i t h r p ( p , ξ j i ) : = I i ( p ) − I j ( ω ( p , D i ( p ) , ξ j i ) ) (13) with \ \ r_p(p,\xi_{ji}) := I_i(p)-I_j(\omega(p,D_i(p), \xi_{ji})) \tag{13} with rp(p,ξji):=Ii(p)−Ij(ω(p,Di(p),ξji))(13)
σ r p ( p , ξ j i ) 2 : = 2 σ I 2 + ( ∂ r p ( p , ξ j i ) ∂ D i ( p ) ) 2 V i ( p ) (14) \sigma^2_{r_p(p,\xi_{ji})}:=2\sigma^2_I+\bigg(\frac{\partial r_p(p,\xi_{ji})}{\partial D_i(p)}\bigg)^2V_i(p) \tag{14} σrp(p,ξji)2:=2σI2+(∂Di(p)∂rp(p,ξji))2Vi(p)(14)
among ∥ ⋅ ∥ \Vert \cdot \Vert ∥⋅∥ yes Huber norm ,
∣ ∣ r 2 ∣ ∣ δ : = { r 2 2 δ i f ∣ r ∣ ≤ δ ∣ r ∣ − δ 2 o t h e r w i s e (15) || r^2||_\delta:=\begin{cases} \frac{r^2}{2\delta} \ \ \ \ \mathrm{if}\ |r| \leq \delta \\ \\ |r| - \frac{\delta}{2} \ \ \ \ \mathrm{otherwise} \end{cases} \tag{15} ∣∣r2∣∣δ:=⎩⎪⎨⎪⎧2δr2 if ∣r∣≤δ∣r∣−2δ otherwise(15)
Applied to normalized residuals . The residual variance is calculated using covariance propagation , As the first 2.3 Section , And using the inverse depth variance V i V_i Vi. further , We assume that the gray level of the image is Gaussian noise σ I 2 \sigma_I^2 σI2. As the first 2.2 Section , Use iterative reweighted Gauss Newton optimization to achieve minimization .
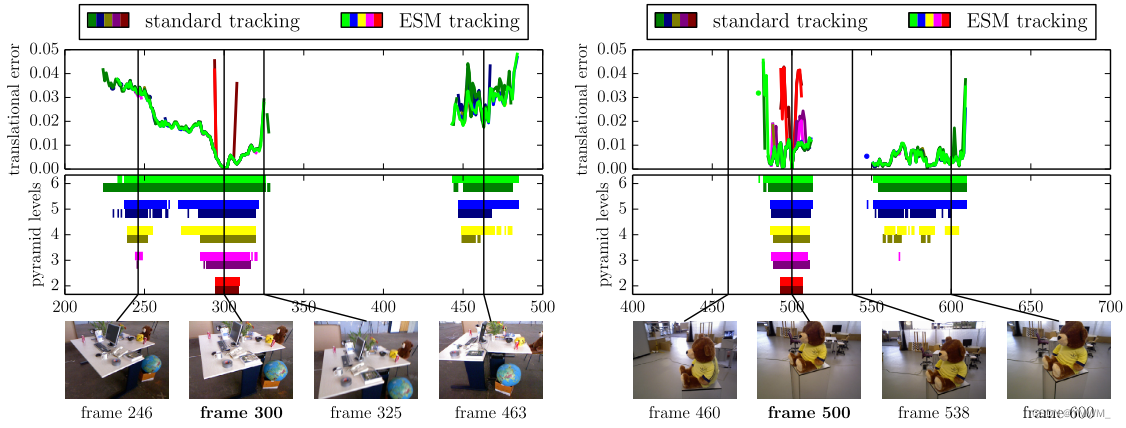
Compared with the previous direct method , The formula presented in this paper explicitly considers the varying noise in depth estimation . This is related to the direct monocular SLAM Especially relevant , The noise of different pixels varies greatly , It depends on how long they are visible . This is related to the treatment RGB-D The data method is the opposite , The uncertainty of the latter inverse depth is approximately constant . chart 4 It shows the performance of this weighting in different types of motion . Be careful , The depth information of the new image is unknown , Therefore, the scale of the new image is not determined , And in s e \mathfrak{se} se(3) Perform minimization on .

3.4 Depth map estimation
Key frame selection . If the camera is too far from the existing map , A new keyframe will be created from the most recent tracking image . We weighted the relative distance and relative angle of the current key frame ,
d i s t ( ξ j i ) : = ξ j i T W ξ j i (16) \mathrm{dist}(\pmb{\xi}_{ji}):=\pmb{\xi}_{ji}^T\pmb{W}\pmb{\xi}_{ji} \tag{16} dist(ξξξji):=ξξξjiTWWWξξξji(16)
among W \pmb{W} WWW Is a diagonal matrix containing weights . Please note that , As described in the next section , Each key frame is scaled , The average inverse depth is 1. therefore , This threshold is relative to the current scene scale , And make sure that there is enough possibility to carry out stereoscopic comparison of small baseline .

Depth map creation . Once a new frame is selected as a key frame , Its depth map will be initialized by the projection points in the previous key frame , Then according to the literature [9] The method proposed in this paper performs a spatial regularization and outer point elimination . then , Zoom depth map , The average inverse depth is 1 . This scaling factor will be incorporated directly into s i m \mathfrak{sim} sim(3) Camera pose . Last , It replaces the previous key frame , And it is used to track the subsequent new frames .
Depth map refinement (refinement). Refine the current key frame by using the tracked frame that has not become a key frame . For an image area where the stereoscopic accuracy is expected to be large enough , Perform a large number of very effective small baseline stereo comparisons , Such as Literature [9] Described in . The results are merged into the existing depth map , To improve it and possibly add new pixels , This is the use of literature [9] The filtering method proposed in .
3.5 Constraint acquisition : direct s i m ( 3 ) \mathfrak{sim}(3) sim(3) image alignment
s i m ( 3 ) \mathfrak{sim}(3) sim(3) Direct image alignment on . And RGB-D SLAM Or binocular SLAM comparison , Monocular SLAM In essence, the scale is fuzzy , That is, the absolute scale of the real world is unobservable . On a long track , This leads to scale drift , This is one of the main sources of error . Besides , All distances are defined by scale only , This leads to threshold based outlier culling or parameterized robust kernel ( Such as Huber) The definition is not clear . We use the inherent correlation between scene depth and tracking accuracy to solve this problem . The depth map of each created key frame is scaled , The average inverse depth is 1. In return , Edges between keyframes are estimated to be s i m ( 3 ) \mathfrak{sim}(3) sim(3) The elements in , The scale difference between key frames is elegantly integrated , also , Especially for large loops , Allows explicit detection of accumulated scale drift .
So , We propose a new method in s i m ( 3 ) \mathfrak{sim}(3) sim(3) Direct on 、 Scale shift aware image alignment , This method is used to align two keyframes with different scales . Except for photometric residuals r p r_p rp outside , We also add depth residuals r d r_d rd, It penalizes the standard deviation of the inverse depth between keyframes , Allow direct estimation of the scaling transformation between them . The total error function to be minimized is ,
E ( ξ j i ) : = ∑ p ∈ Ω D i ∥ r p 2 ( p , ξ j i ) σ r p ( p , ξ j i ) 2 + r d 2 ( p , ξ j i ) σ r d ( p , ξ j i ) 2 ∥ δ (17) E(\pmb{\xi}_{ji}):=\sum_{p \in \Omega_{D_i}} \bigg \Vert \frac{r_p^2(\pmb{p}, \pmb{\xi}_{ji})}{\sigma^2_{r_p(p,\xi_{ji})}}+\frac{r_d^2(\pmb{p},\pmb{\xi}_{ji})}{\sigma^2_{r_d(p,\xi_{ji})}} \bigg \Vert_\delta \tag{17} E(ξξξji):=p∈ΩDi∑∥∥∥∥σrp(p,ξji)2rp2(ppp,ξξξji)+σrd(p,ξji)2rd2(ppp,ξξξji)∥∥∥∥δ(17)
Where photometric residuals r p 2 r_p^2 rp2 And its variance σ r p 2 \sigma_{r_p}^2 σrp2 By formula (13) And the formula (14) Give respectively . The depth residual and its variance are calculated as ,
r d ( p , ξ j i ) : = [ p ′ ] 3 − D j ( [ p ′ ] 1 , 2 ) (18) r_d(\pmb{p}, \pmb{\xi}_{ji}):=[\pmb{p}']_3-D_j([\pmb{p}']_{1,2}) \tag{18} rd(ppp,ξξξji):=[ppp′]3−Dj([ppp′]1,2)(18)
σ r d ( p , ξ j i ) 2 : = V j ( [ p ] 1 , 2 ′ ) ( ∂ r d ( p , ξ j i ) ∂ D j ( [ p ′ ] 1 , 2 ) ) 2 + V i ( p ) ( ∂ r d ( p , ξ j i ) ∂ D i ( p ) ) 2 (19) \sigma_{r_d(p,\xi_{ji})}^2:=V_j([\pmb{p}]'_{1,2}) \bigg( \frac{\partial r_d(\pmb{p}, \pmb{\xi}_{ji})}{\partial D_j([\pmb{p}']_{1,2})} \bigg)^2 + V_i(\pmb{p})\bigg( \frac{\partial r_d(\pmb{p}, \pmb{\xi}_{ji})}{\partial D_i(\pmb{p}) } \bigg)^2 \tag{19} σrd(p,ξji)2:=Vj([ppp]1,2′)(∂Dj([ppp′]1,2)∂rd(ppp,ξξξji))2+Vi(ppp)(∂Di(ppp)∂rd(ppp,ξξξji))2(19)
among p ′ : = ω s ( p , D i ( p ) , ξ j i ) \pmb{p}':=\omega_s(\pmb{p}, D_i(\pmb{p}), \pmb{\xi}_{ji}) ppp′:=ωs(ppp,Di(ppp),ξξξji) Represents the transformed point . Please note that ,Huber The norm is applied to the sum of normalized photometric and depth residuals —— This explains the fact that , If one is an outlier , The other is usually an outlier . Be careful , about s i m ( 3 ) \mathfrak{sim}(3) sim(3) Tracking on , Need to include depth error , Because only relying on photometric errors can not constrain the scale . Using iterative reweighting Gauss - Newton algorithm ( The first 2.2 section ) Yes s e ( 3 ) \mathfrak{se}(3) se(3) Minimize direct image alignment on . In practice , s i m ( 3 ) \mathfrak{sim}(3) sim(3) Tracking is only computationally better than s e ( 3 ) \mathfrak{se}(3) se(3) Tracking is a little more expensive , Because only a few extra calculations are required .

Constraint search . Insert a new key frame in the map K i \mathcal{K}_i Ki after , Some possible loopback keyframes K j 1 , ⋯ , K j n \mathcal{K}_{j1},\cdots,\mathcal{K}_{jn} Kj1,⋯,Kjn Collected . We use the ten closest keyframes , And a large-scale loopback key frame candidate detected by the appearance based mapping algorithm . To avoid inserting the wrong loop or inserting the wrong trace loop , We execute a Back tracking inspection . For each candidate K j k \mathcal{K}_{jk} Kjk, We track independently ξ j k i \pmb{\xi}_{j_ki} ξξξjki and ξ i j k \pmb{\xi}_{ij_k} ξξξijk. Only if the two estimates are statistically similar , That is, if
e ( ξ j k i , ξ i j k ) : = ( ξ j k i ∘ ξ i j k ) T ( Σ j k i + A d j j k i Σ i j k A d j j k i T ) − 1 ( ξ j k i ∘ ξ i j k ) (20) e(\pmb{\xi}_{j_ki},\pmb{\xi}_{ij_k}):=(\pmb{\xi}_{j_ki} \circ \pmb{\xi}_{ij_k})^T \Big(\pmb{\Sigma}_{j_ki} +\mathrm{Adj}_{j_ki}\pmb{\Sigma}_{ij_k}\mathrm{Adj}_{j_ki}^T \Big)^{-1} (\pmb{\xi}_{j_ki} \circ \pmb{\xi}_{ij_k} ) \tag{20} e(ξξξjki,ξξξijk):=(ξξξjki∘ξξξijk)T(ΣΣΣjki+AdjjkiΣΣΣijkAdjjkiT)−1(ξξξjki∘ξξξijk)(20)
Small enough , They are added to the global map . therefore , Using the adjoint matrix A d j j k i \mathrm{Adj}_{j_ki} Adjjki take Σ i j k \pmb{\Sigma}_{ij_k} ΣΣΣijk Transform to the correct tangent space .
s i m ( 3 ) \mathfrak{sim}(3) sim(3) The convergence radius of the trace . An important limitation of direct image alignment is the inherent non convexity of the problem , Therefore, a sufficiently accurate initialization is required . Although for the tracking of new camera frames , A good enough initialization is available ( Given by the pose of the previous frame ), But when looking for loopback constraints , Is not the case, , Especially for large loops .
One solution to this is to use a very small number of keys to compute better initialization . Use depth values from existing inverse depth maps , This requires aligning two sets of 3D points , This can be done by Horn The closed form solution is effectively given by the method of . However , We found in practice that , Even for large loops , The convergence radius is also large enough . especially , We find that the convergence radius can be greatly increased by the following measures .
Efficient second order minimization (ESM). Although our results confirm previous work , namely ESM Does not significantly increase the accuracy of dense image alignment , But we observe that it does slightly increase the convergence radius .
From coarse to fine . Although pyramid method is usually used for direct image alignment , But what we found was that , from 20 × 15 20\times15 20×15 The very low resolution of pixels starts , Much smaller than usual , Helps to increase the radius of convergence .
For the evaluation of the performance of these measures, see 4.3 section .
3.6 Map optimization
The map consists of a set of keyframes and tracked s i m ( 3 ) \mathfrak{sim}(3) sim(3) Constraints consist of , In the background, the pose graph optimization framework is used for continuous optimization . Minimizing the error function , According to the first 2.2 The left multiplication convention of stanzas , Defined by ,
E ( ξ W 1 ⋯ ξ W n ) : = Σ ( ξ j i , Σ j i ) ∈ ε ( ξ j i ∘ ξ W i − 1 ∘ ξ W j ) T Σ j i − 1 ( ξ j i ∘ ξ W i − 1 ∘ ξ W j ) (21) E(\pmb{\xi}_{W1}\cdots\pmb{\xi}_{Wn}) := \underset{(\xi_{ji},\Sigma_{ji}) \in \varepsilon}{\Sigma} (\pmb{\xi}_{ji} \circ \pmb{\xi}_{Wi}^{-1} \circ \pmb{\xi}_{Wj})^T \pmb{\Sigma}_{ji}^{-1} (\pmb{\xi}_{ji} \circ \pmb{\xi}_{Wi}^{-1} \circ \pmb{\xi}_{Wj}) \tag{21} E(ξξξW1⋯ξξξWn):=(ξji,Σji)∈εΣ(ξξξji∘ξξξWi−1∘ξξξWj)TΣΣΣji−1(ξξξji∘ξξξWi−1∘ξξξWj)(21)
among W W W Indicates the world system .
4 result
We are right. LSD-SLAM A quantitative assessment was carried out , Including the use of public data sets , And the challenging outdoor tracks recorded with a hand-held monocular camera . Some of the tracks evaluated are shown in the supplementary video .
4.1 Qualitative results of large trajectories
We tested the algorithm on several long and challenging trajectories , This includes many camera rotations 、 Large scale changes and big loops . chart 7 Shows an approximate 500m Long track , It takes time before and after finding the big loop 6 minute . chart 8 Shows a challenging track , There are great changes in scene depth , It also includes a loop .


4.2 Quantitative assessment
We are publicly available RGB-D Evaluation on dataset LSD-SLAM. Please note that , For monocular SLAM Come on , This is a very challenging benchmark , Because it contains fast rotational motion 、 Strong motion blur and rolling shutter artifacts . We use the first depth map to start the system , And get the correct initial scale . chart 9 The absolute trajectory error is given , And compared with other methods .

4.3 s i m ( 3 ) \mathfrak{sim}(3) sim(3) The convergence radius of the trace
We calculate the convergence radius of two sample sequences , The result is shown in Fig. 10 Shown . Even if direct image alignment is a nonconvex optimization problem , We found that using the 3.5 Measures in section , Very large camera movements can also be tracked . It can be seen that , These methods only increase the convergence radius , It has no significant effect on tracking accuracy .
5 Conclusion
We propose a new direct ( No features ) Monocular SLAM Algorithm , We call it LSD-SLAM, It can be CPU Run in real time . And the existing direct methods ( All are pure odometer methods ) comparison , It maintains and tracks on a global map of the environment , It contains the pose map of key frames , And the related probabilistic semi dense depth map . This approach consists mainly of two key innovations .(1) stay s i m ( 3 ) \mathfrak{sim}(3) sim(3) Align the two keys directly on the , Explicitly merge and detect scale shifts .(2) A new probabilistic approach , The estimation of noise is added to the depth map tracking . The map is represented as a point cloud , A semi dense and highly accurate 3D reconstruction of the environment is given . Our experiments show that , This method can reliably track and plot the length over 500 M's hand-held track , Especially large-scale changes in the same sequence ( The average inverse depth is less than 20 Cm to greater than 10 rice ) And big spin , Proved its universality 、 Robustness and flexibility .
reference
A little
边栏推荐
- Jilin University 22 spring March "official document writing" assignment assessment-00034
- WMS仓储管理系统的使用价值,你知道多少
- Zoran community
- 【LeetCode】148. 排序链表
- Upgrade cmake
- MySQL modifies and deletes tables in batches according to the table prefix
- Standing wave ratio calculation method
- How much do you know about the use value of WMS warehouse management system
- Vigilance against over range collection of privacy - ten mobile app violations
- 1280_C语言求两个无符号整形的平均值
猜你喜欢

1. Phase II of the project - user registration and login
Cesium 加载显示热力图

MySQL插入过程报错1062,但是我没有该字段。

acmStreamOpen返回值问题

1280_C语言求两个无符号整形的平均值

Development of trading system (I) -- Introduction to trading system

"Grammar sugar" -- my new programming knowledge

1. first knowledge of chromatic harmonica
佐喃社区

Lecture record: history and development of strapdown inertial navigation solution

随机推荐
Qt编译数据库插件通用步骤说明
Mathematical analysis_ Notes_ Chapter 3: limits
Lecture record: history and development of strapdown inertial navigation solution
Text keyword extraction: ansj
Development of trading system (V) -- Introduction to Sinovel counter
Development of trading system (VII) -- Analysis of trading delay
Where is the red area of OpenCV?
Smart wind power: operation and maintenance of digital twin 3D wind turbine intelligent equipment
讲座记录《惯性导航的新应用——惯性测量》
无法安装redis接口
《悉达多》:一生之书,可以时常反刍
2D 照片变身 3D 模型,来看英伟达的 AI 新“魔法”!
Is opencv open source?
AI quantitative transaction (I) -- Introduction to quantitative transaction
Teach you how to install win11 system in winpe
Hot and cold, sweet and sour, want to achieve success? Dengkang oral, the parent company of lengsuanling, intends to be listed on the main board of Shenzhen Stock Exchange
Development of trading system (VIII) -- Construction of low delay network
Numpy NP tips: squeeze and other processing of numpy arrays
Simple integration of client go gin -update
MySQL order by