当前位置:网站首页>Ansible practice of Nepal graph
Ansible practice of Nepal graph
2022-06-23 01:56:00 【NebulaGraph】

This article was first published in Nebula Graph official account NebulaGraphCommunity,Follow & Look at the practice of Dachang database technology

background
stay Nebula-Graph In our daily tests , We'll always deploy it on the server Nebula-Graph. In order to improve efficiency , We need a tool , Can help us deploy quickly , The main demand :
- You can use non root Account deployment Nebula Graph, So we can set up for this user cgroup Do resource restrictions .
- The configuration file can be changed on the operating machine , And then distributed to the deployed cluster , It is convenient for us to do all kinds of parameter adjustment tests .
- You can use scripts to call , It's convenient for us to inherit on the testing platform or tool in the future .
Tool selection , In the early days Fabric and Puppet, The newer tools are Ansible and SaltStack.
Ansible stay GitHub There are 40K+ star, And in 2015 By the Red Hat Acquisition , The community is more active . Many open source projects provide Ansible How to deploy , such as Kubernetes Medium kubespray and TiDB Medium tidb-ansible.
Put it all together , We use Ansible To deploy Nebula Graph.
Ansible Introduce
characteristic
Ansible It's open source. , Automated deployment tools (Ansible Tower It's commercial ). It has the following characteristics :
- The default protocol is based on SSH, Compared with SaltStack No Additional deployment is required agent.
- Use playbook, role, module To define the deployment process , More flexible .
- Operational behavior idempotent .
- Modular development , Abundant modules .
The advantages and disadvantages are obvious
- Use SSH agreement , The advantage is that most machines can pass the password as long as they have an account by default Ansible Complete deployment , And the performance will be worse .
- Use playbook To define the deployment process ,Python Of Jinja2 As template rendering engine , For familiar people, it will be more convenient , And for those who haven't used it , It will increase the cost of learning .
Sum up , It is suitable for batch deployment of small batch machines , No need to care about additional deployment agent Scene , It matches our needs .
Deployment logic
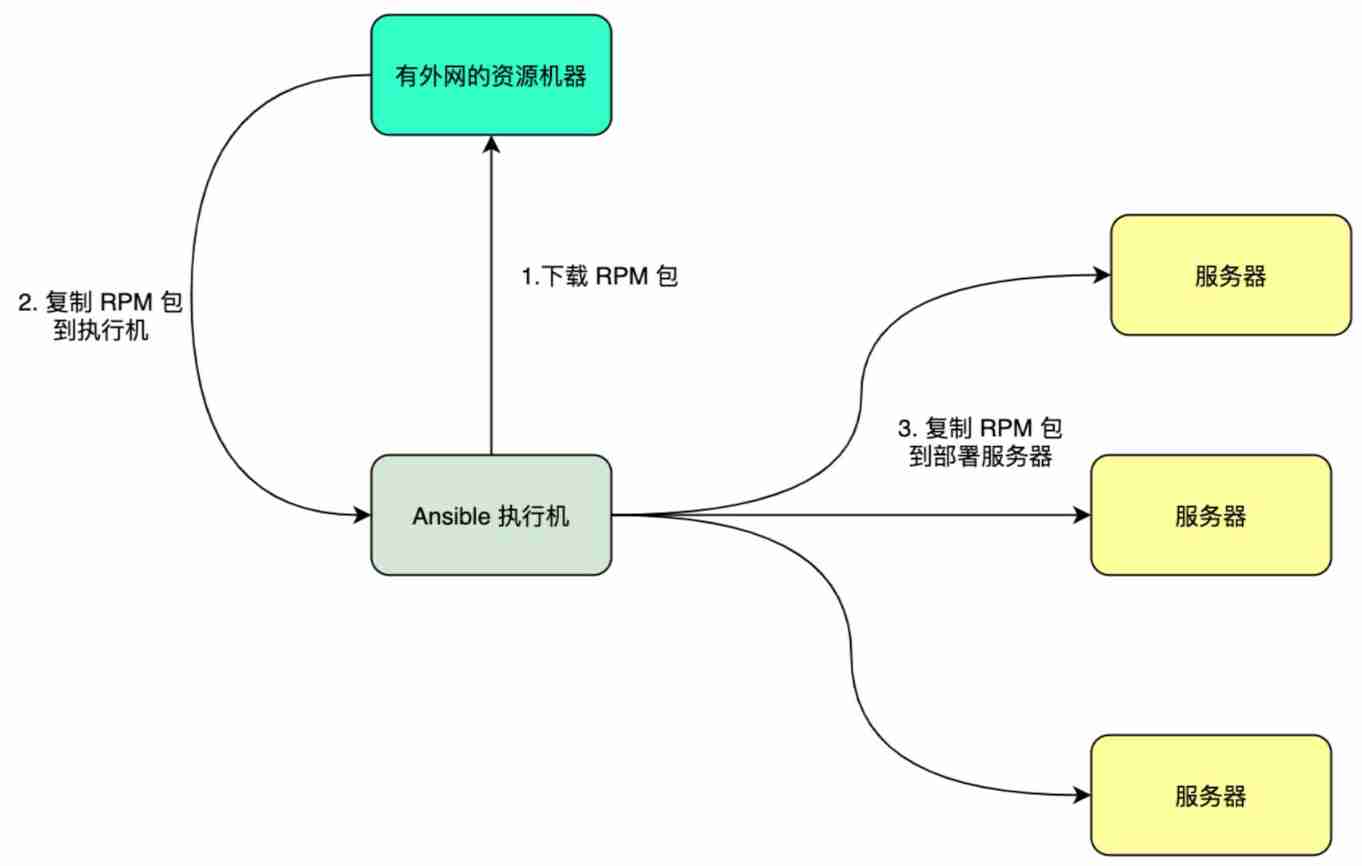
Usually for offline deployment , Machines can be divided into 3 Roles .
- Ansible Actuator : function Ansible Machine , Need to be able to pass SSH Connect to all the machines .
- Resource machine with external network : Running tasks that need to be connected to the Internet , For example, download. RPM package .
- The server : The server that runs the service , Network isolation is possible , Deploy by executor
Task logic
Ansible in , There are mainly three levels of tasks :
- Module
- Role
- Playbook
Module It is divided into CoreModule and CustomerModule, yes Ansible Basic unit of task .
When running a task , First Ansible Will be based on module Code for , Substituting parameters into , Make a new one Python file , adopt SSH Remote tmp Folder , And then through SSH Remote execution Python Return the output to , Finally, delete the remote directory .
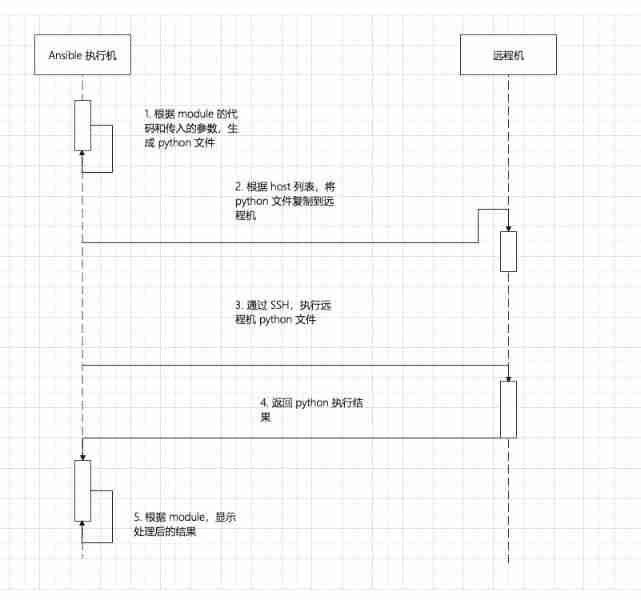
# Set not to delete tmp file export ANSIBLE_KEEP_REMOTE_FILES=1# -vvv see debug Information ansible -m ping all -vvv<192.168.8.147> SSH: EXEC ssh -o ControlMaster=auto -o ControlPersist=30m -o ConnectionAttempts=100 -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o 'User="nebula"' -o ConnectTimeout=10 -o ControlPath=/home/vesoft/.ansible/cp/d94660cf0d -tt 192.168.8.147 '/bin/sh -c '"'"'/usr/bin/python /home/nebula/.ansible/tmp/ansible-tmp-1618982672.9659252-5332-61577192045877/AnsiballZ_ping.py && sleep 0'"'"''You can see this log output ,AnsiballZ_ping.py It is based on module Generated Python file , You can log in to that machine , perform Python Look at the results .
python3 AnsiballZ_ping.py#{"ping": "pong", "invocation": {"module_args": {"data": "pong"}}}Returned to run Python Standard output of documents , then Ansible Then do additional processing to the returned results .
Role It's serial module A series of tasks , Can pass register To pass context parameters .
A typical example :
- Create directory
- If the directory is created successfully , continue installation , Otherwise, exit the whole deployment project .
Playbook Is the organization deploying machines and role Relationship between .
By means of inventory Grouping different machines , Use different methods for different groups role To deploy , Complete very flexible installation and deployment tasks .
When playbook Once defined , Different environments , Just change inventory Machine configuration in , You can complete the same deployment process .
Module customization
Customize filter
Ansible Use Jinja2 As template rendering engine , It can be used Jinja2 Self contained filter , such as
# Use default filter, Default output 5ansible -m debug -a 'msg={{ hello | default(5) }}' all occasionally , We'll need to customize it filter To manipulate variables , The typical scene is nebula-metad Of Address --meta_server_addrs.
- When only 1 individual metad When , The format is
metad1:9559, - When there is 3 individual metad When , The format is
metad1:9559,metad2:9559,metad3:9559
stay ansible playbook Under the project , newly build filter_plugins Catalog , Create a map_fomat.py Python file , The contents of the document :
# -*- encoding: utf-8 -*-from jinja2.utils import soft_unicodedef map_format(value, pattern): """ e.g. "{{ groups['metad']|map('map_format', '%s:9559')|join(',') }}" """ return soft_unicode(pattern) % (value)class FilterModule(object): """ jinja2 filters """ def filters(self): return { 'map_format': map_format, }{{ groups['metad']|map('map_format', '%s:9559')|join(',') }} That is the value we want .
Customize module
Customize module Need to meet Ansible The format of the frame , Including getting parameters , Standard return , Error return, etc .
Written customization module, Need to be in ansible.cfg Middle configuration ANSIBLE_LIBRARY, Give Way ansible To be able to obtain .
Please refer to the official website for details :https://ansible-docs.readthedocs.io/zh/stable-2.0/rst/developing_modules.html
Nebula Graph Of Ansible practice
because Nebula Graph It's not complicated to start , Use Ansible To complete Nebula-Graph It's very simple to deploy .
- download RPM package .
- Copy RPM Package to deployer , After decompressing , Put in destination folder .
- Update profile .
- adopt shell start-up .
Use the universal role
Nebula Graph There are three components ,graphd、metad、storaged, The three components are named and started in the same format , You can use a generic role,graphd、metad、storaged Reference the common role.
On the one hand, it is easier to maintain , On the other hand, the deployed services are more fine-grained . such as A B C Machine deployment storaged, Only C Machine deployment graphd, that A B On the machine , There will be no graphd Configuration file for .
# General purpose role, Using variables install/task/main.yml- name: config {{ module }}.conf template: src: "{{ playbook_dir}}/templates/{{ module }}.conf.j2" dest: "{{ deploy_dir }}/etc/{{ module }}.conf" # graphd role, Pass in the variable nebula-graphd/task/main.yml- name: install graphd include_role: name: install vars: module: nebula-graphdstay playbook in ,graphd To run on the same machine group graphd Of role, If A B be not in graphd Machine group of , Will not graphd Configuration file upload for .
After this deployment , You can't use it Nebula-Graph Of nebula.service start all To start it all , Because some machines don't have them nebula-graphd.conf Configuration file for . Allied , Can be in playbook in , Through parameters , To specify different machine groups , Pass different parameters .
# playbook start.yml- hosts: metad roles: - op vars: - module: metad - op: start- hosts: storaged roles: - op vars: - module: storaged - op: start- hosts: graphd roles: - op vars: - module: graphd - op: startThis would be equivalent to many times ssh To execute the startup script , Although the implementation efficiency is not high start all Better , But the start and stop of the service will be more flexible .

Use vars_prompt end playbook
When you only want to update binary , When you don't want to delete the data directory ,
Can be in remove Of playbook in , add to vars_prompt Secondary confirmation , If it's confirmed again , Data will be deleted , Or you'll quit playbook.
# playbook remove.yml- hosts: all vars_prompt: - name: confirmed prompt: "Are you sure you want to remove the Nebula-Graph? Will delete binary only (yes/no)" roles: - removeAnd in the role in , The value of secondary confirmation will be verified
# remove/task/main.yml---- name: Information debug: msg: "Must input 'yes', abort the playbook " when: - confirmed != 'yes'- meta: end_play when: - confirmed != 'yesThe effect is as shown in the picture , The deletion can be confirmed again , If not for yes, It will be cancelled playbook, This will remove only the binary , Without deleting nebula Cluster data .

Communication graph database technology ? Join in Nebula Communication group please first Fill in your Nebulae Business card ,Nebula The little assistant will pull you into the group ~~
Recommended reading
- 【 Application and challenge of ten billion level chart data in Kwai Fu safety intelligence 】
- 【 Meituantu database platform construction and business practice 】
- 【Nebula Graph Practice of data governance in Weizhong bank 】
- 【 Figure database selection | 360 The history of graph database migration in the field of mathematics 】
边栏推荐
- HDU - 7072 double ended queue + opposite top
- Branch and loop statements (including goto statements) -part2
- Array part
- 7.new, delete, OOP, this pointer
- Cmake configuration error, error configuration process, Preject files may be invalid
- Uint8 serializing and deserializing pits using stringstream
- Freshman C language summary post (hold change) Part1 output diamond
- How to download online printing on Web pages to local PDF format (manual personal test)
- 8. destruct, construct, deep copy, shallow copy, assignment operator overload
- Up the Strip
猜你喜欢

Zabbix5 series - use temperature and humidity sensor to monitor the temperature and humidity of the machine room (XX)

SQL programming task02 job - basic query and sorting

Ch340 and PL2303 installation (with link)

2D prefix and
Debian10 LVM logical volumes

1. Mx6u bare metal program (6) - timer

Cmake simple usage

C language games: sanziqi (simple version) implementation explanation
![[hdu] P6964 I love counting](/img/ff/f8e79d28758c9bd3019816c8f46723.png)
[hdu] P6964 I love counting

Garbled code of SecureCRT, double lines, double characters, unable to input (personal detection)
随机推荐
Bc116 xiaolele changed to digital
[hdu] P7079 Pty loves lines
JS prototype and prototype chain Paramecium can understand
Modulenotfounderror: no module named 'rospy', PIP could not find the installation package
Using WordPress to create a MySQL based education website (learning notes 2) (technical notes 1) xampp error1045 solution
SQL programming task05 job -sql advanced processing
[CodeWars] Convert Decimal Degrees to Degrees, Minutes, Seconds
//1.14 comma operator and comma expression
JS request path console reports an error failed to launch 'xxx' because the scheme does not have a registered handler
C language game minesweeping [simple implementation]
Cmake passing related macros to source code
JS to paste pictures into web pages
C. Unstable String
【CodeWars】What is between?
165. cat climbing
Data skew analysis of redis slice cluster
Debian10 LVM logical volumes
//1.8 char character variable assignment integer
Do you know the memory components of MySQL InnoDB?
Primary pointer part