当前位置:网站首页>On location and scale in CNN
On location and scale in CNN
2022-06-25 18:47:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery come from | You know author | Huang Piao
link | https://zhuanlan.zhihu.com/p/113443895
This article is for academic exchange only , If there is any infringement , Please contact to delete .

Preface
Some time ago, I saw some interesting articles , I also refer to some related discussions , I want to be right here CNN The invariance and equality of translation and scale in , as well as CNN For target relative and absolute positions 、 Discussion on the prediction principle of depth . These are important for some specific tasks , For example, target detection 、 Target segmentation 、 Depth estimation 、 classification / Recognition and confidence map prediction in single target tracking .
1 CNN Whether there is invariance and equality of translation and scale
1.1 Definition of invariance and equality
In the introduction of convolutional neural network (CNN) Before , Our understanding of invariance and equality may come from the traditional image processing algorithms , translation 、 rotate 、 Illumination and scale invariance , such as HOG Gradient direction histogram , because cell The existence of , For translation 、 Rotation has some invariance , In addition, due to the operation of image local contrast normalization , So that it also has a certain invariance for light . Again for instance SIFT feature extraction , It is invariant to the above four points , Because of the scale pyramid , It makes the scale invariant . Here our understanding of invariance is , Translation of the same object 、 rotate 、 Light variation 、 Scale transformation and even deformation , Its attributes should be consistent . Now we give the definition of invariance and equality .
Where invariance (invariance) As we said above , So its form is :
 And for equality (equivalence), seeing the name of a thing one thinks of its function , After the input is transformed , The output also changes accordingly :
And for equality (equivalence), seeing the name of a thing one thinks of its function , After the input is transformed , The output also changes accordingly :
But if we only consider the invariance and equality of the output to the input , It's hard to understand , Because we are more imagining the mapping of feature level , such as :

Then we may consider less about the influence of feature level on output , But in essence , For example, the translation and scale transformation of the target in the image , In the target detection task , It is necessary to make the network have related transformation equality , So we can capture the position and shape of the target . And in image classification 、 target recognition 、 Pedestrian recognition and other tasks , And we must make the network have the invariance of correlation transformation . These two points are also a classic contradiction in the field of object detection and pedestrian retrieval , At present, there seems to be no particularly good solution , It's more about performing different tasks in stages , Prevent feature sharing . such as : In the classic two-stage target detection task , The first stage is rough detection and Foreground Background classification , The second stage is refinement and classification , There is a certain emphasis on . Most of the pedestrian search algorithms are based on the strategy of first detection and then recognition . Except for the problems of invariance and equality , There are also problems of intra class differences , For example, different people are pedestrian categories for detection , For recognition, it's different people , This is also a challenge for feature extraction .
1.2 CNN The execution process of the network
I remember when I first met with deep learning a few years ago , For full connection and CNN Local connection form of , All have translation 、 Scale invariance . For a fully connected network , Because each node of the next layer will connect with the previous layer :

So no matter the input is translated 、 Scale and so on , As long as its properties do not change , All connected networks are more able to capture the invariance . And for convolutional neural networks , We all know two characteristics : Local connection and weight sharing .

For local connections , Because there are too many full connection parameters , It is easy to cause over fitting , And the image field pays more attention to local details , So the local connection is effective . As for weight sharing , It can also reduce parameters , It's very much like a filter in image processing . Our early understanding of its immutability is more to follow a macroscopic feeling , Because of the shift filtering of convolution kernel , The relative position of the features from the upper layer to the next layer remains unchanged , Until the last output , Similar to the full connection effect , So we can get invariance .
1.3CNN Potential network problems and improvements
Just because I just said that the macro is unchanged , Make the input convolute many times 、 After pooling , Microcosmic / The cumulative amplification of changes in detail , So we lose this invariance , Next, I will introduce it with two papers .
The first is to solve CNN Translation invariance is an article of antagonistic attack ICML2019 The paper 《Making Convolutional Networks Shift-Invariant Again》. This article mainly discusses CNN The effect of downsampling on translation invariance in networks :

The picture above is for a window respectively from 0~7 The amount of translation , The difference between the feature map and non translation , It can be seen clearly , There's a wave in the feature map . Accordingly , The first half is using pix2pix The resulting image , We can see that as the amount of translation increases , The vertical line in the window changed from two to one . This shows the traditional CNN The network does not have translation invariance .
First , The author did such a small experiment , using maxpooling For a one-dimensional vector [0011001100] Pool , So we get the vector [01010]:

next , If you translate the input one unit to the right , Then we get the vector [111111]:

Obviously , Translation equality and invariance are lost . Then the author did further experiments , Using cosine distance to describe translation equality , use VGG Network pair Cifar Data sets are tested :

The darker the color, the greater the difference , You can see every time maxpooling All increase the difference of features , But the author will max and pool The operation is separated , In order to distinguish the effect of taking the maximum value from that of downsampling :

Obviously , Downsampling has a greater effect on translation equality , and CNN The operations involved in downsampling include : Pooling (maxpooling and average pooling) And convolution with steps (strided convolution). To this end, the author puts forward a new concept called Anti_aliasing Method , Chinese is called anti aliasing . In the field of traditional signal processing, anti aliasing technology , Generally, either increase the sampling frequency , But because the image processing task generally needs to downsampling , This is not suitable for . Or use image blur (bluring) technology , according to Nyquist Sampling theory , Is the given sampling frequency , By reducing the frequency of the original signal, the signal can be reconstructed , As shown in the figure below . The original image of blur processing and unprocessed is sampled down , Get the two pictures at the bottom of the picture , The image sampled from the original image after blur processing can also see some outlines , However, the image sampled from the unprocessed original image is even more chaotic .

The author just uses the fuzzy way , Three different kinds of blur kernel:
Rectangle-2:[1, 1], Similar to mean pooling and nearest neighbor interpolation ;
Triangle-2:[1, 2, 1], Similar to bilinear interpolation ;
Binomial-5:[1, 4, 6, 4, 1], This is used in the pyramid of Laplace .
Each nucleus needs to be normalized , Divided by the sum of all the elements in the core , Then add it to the desampling process , I.e. before desampling blur kernel Do convolution filtering :

We can see that the effect is very good :


See... For code and model :
https://richzhang.github.io/antialiased-cnns perhaps
https://github.com/adobe/antialiased-cnns
The second one was published in the same year JMLR A paper on 《Why do deep convolutional networks generalize so poorly to small image transformations?》. The author first gives some examples , They represent translation 、 The influence of scale and slight image difference on the confidence of network prediction classification :

The author thinks that CNN Neglecting the sampling theorem , Before that Simoncelli And so on Shiftable multiscale transforms The second sampling fails in translation invariance , They said in the article :
We can't simply rely on convolution and subsampling for translation invariance in the system , The translation of the input signal does not mean the simple translation of the transformation coefficient , Unless this translation is a multiple of each subsampling factor .
In our existing network framework , The deeper the network , The more downsampling times , So there are more problems . Then , The author puts forward several points :
If
It is a convolution operation that satisfies the invariance of translation , So global pooling operation It also satisfies the translation invariance ;For feature extractors
And desampling factors , If the input translation can be reflected in the output linear interpolation :
By Shannon - Nyquist's theorem knows , Meet the requirement of displacement , Ensure that the sampling frequency is at least the highest signal frequency 2 times .
Next , The author tries to improve these problems :
Anti-Aliasing , This is the method we just introduced ;
Data to enhance , Currently in many image tasks , We basically use random cuts 、 Multiscale 、 Color jitter and other data enhancement means , It also makes the network learn some invariance ;
Reduce downsampling , In other words, it only depends on the reduction of the input scale by convolution , This applies only to small images , Mainly because of the high cost of calculation .
2 CNN Prediction of location and depth information
2.1CNN How to get the location information of the target
First contact with neural networks and deep learning related tasks , My feeling is that this kind of algorithm is essentially a classification task , For example, image segmentation is the classification of foreground and background and the classification of specific categories , Recognition task is the task of distinguishing between classes . Among them, the task of image segmentation is used CNN Partial equality in , So how to get the target position regression in the target detection task ? What we can know is also the search of the target location , In a single target tracking task , There is a confidence map :

But the confidence graph is essentially obtained by searching the region , Therefore, it can be approximated to the recognition process of multiple sub areas , So target location in single target tracking can also be understood by classification , But target detection is not easy to understand with classification .
Now let's think about a question , What information does the network we designed contain ? Image features 、 Network structure ( Convolution kernel size 、padding). We can see from the last chapter that , The network can learn certain equality :

therefore , Through constant training , In the final feature output, the network can pass the corresponding feature value and area size , Combine a certain number of times ( Downsampling ) Estimate the target scale . But for the location of the target , Our eyes determine the position of the target through the coordinate system , That is, the distance between the target and the edge of the image , But how does the Internet understand this information ?《How much Position Information Do Convolutional Neural Networks Encode?》 The article answers .
The author first did a group of experiments :

For different input images , Use a variety of mask Disturbance ,H、V、G They represent levels 、 Vertical and Gaussian distribution , In this way, many kinds of groundtruth, For this point, we may be familiar with the Gaussian distribution with the target center as the mean in single target tracking . Results found :

GT It's three distributions groundtruth,PosENet It's the author's network , No, padding. We can see PosENet There's no location information , It's the same thing . And exist padding Of VGG and ResNet They all predicted the location distribution . thus it can be seen padding The role of location , The content of the previous chapter is also supplemented ,padding It also has influence on translation invariance and equality .
But here we may not understand , I did a little test , But not necessarily , Just for my understanding :
There are two different positions on it “ The goal is ” Convolution results of , You can see , From the output results can not get any position reflection , If you join padding:
The first thing we can know is , Joined the zero-padding after , The output of the target edge relative to the center is smaller , Secondly, the farther the target is from the edge of the image , In its feature mapping 0 The more times . So I guess the Internet is to let padding That's the opposite , without padding, The farther the target is from the edge , Also appear 0 The more times , But the problem is that we can't follow padding The resulting edge value is small , A special distribution with a large central value . Of course , The above is just my personal understanding , Just to help me deepen my impression . Some people also said that they joined in padding Affected CNN The translational equivalence of , Thus making CNN Learned location information , But that's not a good explanation .
But about padding The problem of , stay CVPR2019 A single target tracking algorithm SiamRPN++ It also discusses . What's the starting point Siamese The network can't be expanded into a large network , The reason is padding It affects the translational equality , So that the distribution of the target position is shifted . So the author uses the random disturbance of the target center , Make the network overcome its own deviation :

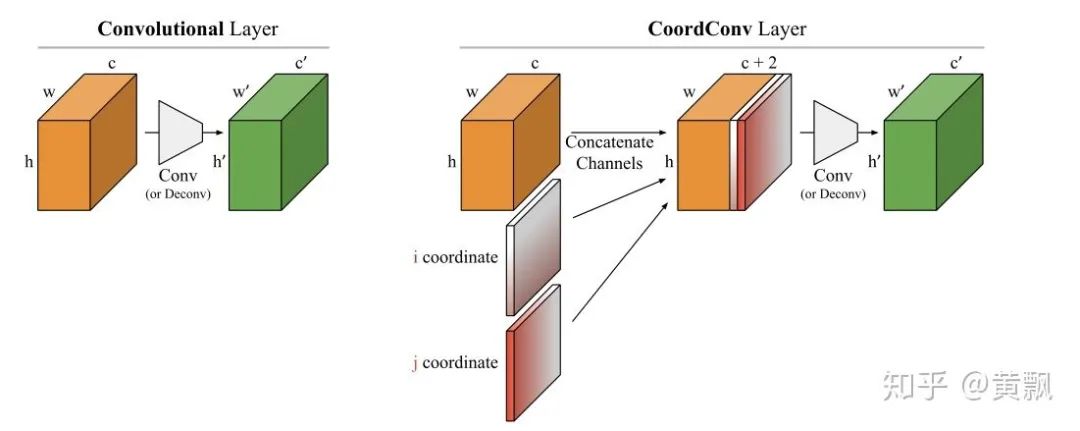
There are also some studies that explore how to make CNN Combine absolute location information , The more famous one should be the popular one at present SOLO Single stage strength segmentation algorithm .SOLO The starting point is very simple , We all know that semantic segmentation only needs to segment different categories of objects , And the division of strength for the same category of individuals also need to distinguish . But obviously , Targets of the same category can be distinguished as long as their positions and shapes are different . therefore SOLO It's the place and the shape ( Simplify with size ) Information comes together . To be specific , It is to divide the image of the input system into S x S The grid of , If the center of the object falls into the mesh cell , Then this grid cell is responsible for predicting semantic categories and splitting the object instance .

Specially ,SOLO The algorithm uses CoordConv Strategy ( Code :github.com/uber-researc), The algorithm combines the coordinate information of each feature area , So that the network can learn to remember the absolute position information of features .SOLO Through this strategy... Has been promoted 3.6AP, And the demonstration only needs one layer to provide this information to achieve stable improvement .
2.2CNN How to predict the depth information of the target
Depth estimation is a similar problem , The difference is , There is no depth information in the image , But how does the network get in-depth information .How Do Neural Networks See Depth in Single Images? This article gives an answer , About this article NaiyanWang The teacher has discussed in the blog , I'll sort it out here .

We can see , The absolute depth of an object has a lot to do with the camera's pose , that CNN How to learn the absolute information that needs geometric priori ? The author did such an experiment :

In the picture above, the author did three experiments : Change the target position and size at the same time 、 Change only position and size , We don't seem to see anything wrong with the qualitative results above , Here are the quantitative results :

You can find , Scale has no effect on the prediction of depth information , in other words CNN The network estimates the depth through the target ordinate , So the network is actually over fitting the training set , From this, we can learn the corresponding relationship between depth and relative position in some fixed scenes .
The influence of camera motion on depth prediction is also discussed , Since the depth is related to the target ordinate , that pitch The influence of the angle should be great :
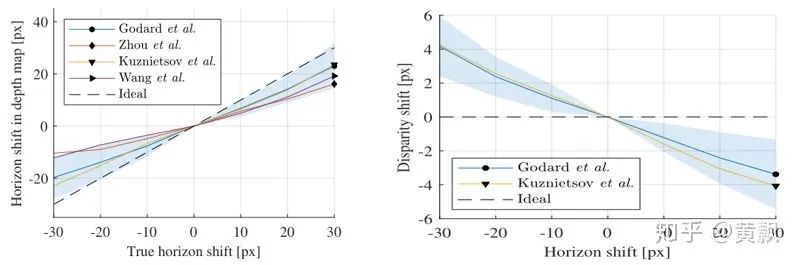
You can find ,pitch It really has a big impact , Relative roll The impact is relatively small :

Finally, the influence of color and texture on depth estimation is discussed :

You can find , Just change the color and texture of the target , The effect of depth estimation will also decrease , Can be CNN How much is the Internet in training “ lazy ”, I don't know if the above experiments become a means of data enhancement, it will make the depth estimation network invalid or strong .
2020.3.18 to update
I happened to read an article yesterday CVPR2020 The article 《On Translation Invariance in CNNs: Convolutional Layers can Exploit Absolute Spatial Location》, It also mentions CNN The problem of translation invariance and absolute position information coding are discussed , The starting point is CNN Boundary problems in .
The author first takes three convolutions as an example ,full/same/valid, The difference between them is padding Size , I won't elaborate on the specific way , Give me a schematic diagram :


The red part means padding, The green part indicates the boundary area . Obviously ,valid The rightmost... Of the convolution kernel in the model 1 It will never work on the green part 1,same Right most convolution kernel in mode 1 It will never work on the green part 1 . The author zero-padding and circular-padding The two models give an example :

You can see Class-1 Neither of the first two examples in has detected 1,valid and same+zero-padding The mode is sensitive to the absolute position of the region to be convoluted . Then the author analyzes the number of times each position is convoluted :
This leads to the problem that a fixed pixel can be detected when it is far from the image boundary , So the author added different sizes of black border around the picture to test :

What's interesting is that , After adding the black boundary, the accuracy of classification has declined obviously , Just different training strategies and different backbone The ability of anti-jamming is different .

In order to quantitatively analyze the difference of each convolution strategy for boundary treatment , Built a classified dataset , Special points are all distributed on the boundary :

The results are quite different :

You can find , It's the same as the previous observation , The generalization ability of the first two strategies is very poor , And based on Circular padding and full convolution The best pattern is . Then in order to reduce the influence of the boundary , Using the convolution translation invariance mentioned in the previous article blur pooling+Tri3 Convolution kernel . Then contrast S-conv+circular padding and F-conv The robustness of the two strategies for different image diagonal translation :


Results show Full conv The mode works better , In the follow-up experiments, it also shows that it can reduce the risk of over fitting , More efficient for small datasets .
The code is going to be open source :github.com/oskyhn/CNNs-Without-Borders
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- LeetCode-78-子集
- Regular expression summary
- Training of long and difficult sentences in postgraduate entrance examination English Day82
- 【C语言练习——打印上三角及其变形(带空格版)】
- Redis6
- Analysis on China's aluminum foil output, trade and enterprise leading operation in 2021: dongyangguang aluminum foil output is stable [figure]
- 网络安全检测与防范 测试题(二)
- Training of long and difficult sentences in postgraduate entrance examination day90
- [deeply understand tcapulusdb technology] one click installation of tmonitor background
- 158_模型_Power BI 使用 DAX + SVG 打通制作商業圖錶幾乎所有可能
猜你喜欢

JVM understanding
Command records of common data types for redis cli operations

Kwai 616 war report was launched, and the essence was thrown away for the second time to lead the new wave. Fast brand jumped to the top 3 of the hot list

SVN介绍及使用总结
![Analysis of China's road freight volume, market scale and competition pattern in 2020 [figure]](/img/93/fd2cfa315c2f6d232078f7b20a7eb1.jpg)
Analysis of China's road freight volume, market scale and competition pattern in 2020 [figure]
![Overview and trend analysis of China's foreign direct investment industry in 2020 [figure]](/img/b3/73e01601885eddcd05b68a20f83ca8.jpg)
Overview and trend analysis of China's foreign direct investment industry in 2020 [figure]

【ELT.ZIP】OpenHarmony啃论文俱乐部—见证文件压缩系统EROFS

Redis6
快手616战报首发,次抛精华引新浪潮,快品牌跃入热榜top3
![Analysis on planting area, output and import of sugarcane in Guangxi in 2021: the output of sugarcane in Guangxi accounts for 68.56% of the total output of sugarcane in China [figure]](/img/c9/f2a8c3c4ddf28d96d8bfc7bc31a4fe.jpg)
Analysis on planting area, output and import of sugarcane in Guangxi in 2021: the output of sugarcane in Guangxi accounts for 68.56% of the total output of sugarcane in China [figure]
随机推荐
Training of long and difficult sentences in postgraduate entrance examination day83
Pycharm 使用过程中碰到问题
[deeply understand tcapulusdb technology] create a game zone
R语言使用DALEX包的model_profile函数基于条件依赖CDP方法解释多个分类模型中某个连续特征和目标值y的关系(Conditional Dependence Plots)
GNU nano
跳一跳小游戏辅助(手动版本)py代码实现
[elt.zip] openharmony paper Club - memory compression for data intensive applications
Analysis on policy, output and market scale of China's natural gas hydrogen production industry in 2020 [figure]
Analysis of China's medical device industry development environment (PEST) in 2021: the awareness of medical care is enhanced, and the demand for medical device products is also rising [figure]
Development status of China's hydrotalcite industry in 2020 and analysis of major enterprises: the market scale is rapidly increasing, and there is a large space for domestic substitution [figure]
Training of long and difficult sentences in postgraduate entrance examination day88
如何快速关闭8080端口
Leetcode force buckle (Sword finger offer 26-30) 26 Substructure of tree 27 Image of binary tree 28 Symmetric binary tree 29 Print matrix 30 clockwise Stack containing min function
Analysis of global tea production, consumption and import and export trade: China's tea production ranks first in the world [figure]
Training of long and difficult sentences in postgraduate entrance examination day81
Use pagoda to set up mqtt server
TCP/IP 测试题(五)
158_模型_Power BI 使用 DAX + SVG 打通制作商業圖錶幾乎所有可能
solidity获取季度时间
初探Oracle全栈虚拟机---GraalVM