当前位置:网站首页>[elt.zip] openharmony paper Club - memory compression for data intensive applications
[elt.zip] openharmony paper Club - memory compression for data intensive applications
2022-06-25 18:33:00 【ELT. ZIP】
- This article from the
ELT.ZIPThe team ,ELT<=>Elite( elite ),.ZIP In compressed format ,ELT.ZIP That is to compress the elite . - member :
- Sophomore at Shanghai University of engineering and Technology
- Sophomores of Hefei Normal University
- Sophomores at Tsinghua University
- Freshman of Chengdu University of Information Engineering
- Freshmen of Heilongjiang University
- Freshman of South China University of Technology
- We are from
6 A place toClassmate , We areOpenHarmony Growth plan gnawing paper Clubin , AndHuawei 、 Soft power 、 Runhe software 、 Rio d information 、 ShenkaihongWait for the company , Study and ResearchOperating system technology…
List of articles
【 Looking back 】
① 2 month 23 Japan 《 I'm here for a series of tours 》 And Why is Lao Zi —— ++ Interpretation of compression coding from the perspective of overview ++
② 3 month 11 Japan 《 I'm here for a series of tours 》 And I'll show you the scenery —— ++ Multidimensional exploration universal lossless compression ++
③ 3 month 25 Japan 《 I'm here for a series of tours 》 And I witnessed the vicissitudes of life —— ++ Turn over those immortal poems ++
④ 4 month 4 Japan 《 I'm here for a series of tours 》 And I visited a river —— ++ Count the compressed bits of life ++
⑤ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— One article penetrates the cutting edge of multimedia ++
⑥ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— You shouldn't miss these little scenery ++
⑦ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Analysis of sparse representation of medical images ++
⑧ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Computer vision data compression application ++
⑨ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Ignite the spark of main cache compression technology ++
⑩ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Immediate Conquest 3D Trellis compression coding ++
⑪ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Cloud computing data compression scheme ++
⑫ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Big data framework performance optimization system ++
⑬ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Internet of things swing door trend algorithm ++
⑭ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Electronic device software update compression ++
⑮ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Artificial intelligence short string compression ++
⑯ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Multi tier storage hierarchical data compression ++
⑰ 6 month 3 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— High throughput lossless data compression scheme ++
⑱ 6 month 3 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Fast random access string compression ++
⑲ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club ——gpu Efficient lossless compression of floating point numbers on ++
⑳ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club — A deep neural network compression algorithm ++
㉑ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club — Hardware accelerated fast lossless compression ++
【 This issue focuses on 】
Uncover Google Apps EROFS The reason for going to AndroidEROFS Why can it shine in the field of file compression systemsThe mystery of the LZ4m How to bring new vitality to the memory compression field
【 technology DNA】

【 Intelligent scene 】
| ********** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ***************** | ***************** | ******************** |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| scene | Autopilot / AR | Voice signals | Streaming video | GPU Rendering | science 、 Cloud computing | Memory reduction | Scientific application | Medical images | database server | Artificial intelligence image | Text transfer | GAN Media compression | Image compression | File synchronization | Database system | General data | System data reading and writing |
| technology | Point cloud compression | Sparse fast Fourier transform | Lossy video compression | Grid compression | Dynamic selection compression algorithm framework | lossless compression | Hierarchical data compression | Medical image compression | Lossless universal compression | Artificial intelligence image compression | Short string compression | GAN Compressed on-line multi particle distillation | Image compression | File transfer compression | Fast random access string compression | High throughput parallel lossless compression | Enhanced read-only file systems |
| Open source project | Draco / Based on deep learning algorithm /PCL/OctNet | SFFT | AV1 / H.266 code / H.266 decode /VP9 | MeshOpt / Draco | Ares | LZ4 | HCompress | DICOM | Brotli | RAISR | AIMCS | OMGD | OpenJPEG | rsync | FSST | ndzip | EROFS |
Introduce
With the rapid development of the Internet , We have entered “ Big data era ”. For most like Tiktok 、 Taobao and other applications , Its huge amount of data 、 The complexity of the data will undoubtedly bring many problems ; Take Taobao for example , Open Taobao APP, A lot of information will be pushed to you , Like words 、 picture 、 Live video and so on will bring huge expenses in data . If you can try to compress these “ Data intensive (data-intensive)” Data brought by application , So for mobile phones 、 Computers and other consumer devices , People will switch from expensive high-end devices to cheaper models equipped with small memory .

Want to let “ Data intensive ” The data generated by the application “ Lose weight ” It's not easy , because “ Compression has always been a dilemma ”, Want a high compression ratio , It's not about performance ( Compression speed ) On the decrease , It's hard to have the best of both worlds . But for an application , The user experience should not be too bad , This is directly related to data compression in memory , Because the performance of memory access will seriously affect the performance of the whole system , So Wilson And so forth WKdm Algorithm , The algorithm makes use of the rules observed from the memory data , This shows a very good compression speed , But its poor compression ratio is the key to its success “ stumbling block ”. therefore , The author compares the algorithm proposed in this paper with it .
In this paper, , A new compression algorithm is proposed ,LZ4m; and Wilson Proposed WKdm Algorithm is the same , Speed up by frequently observed features in memory data LZ4 Algorithm input stream scanning ; secondly , in the light of LZ4 Algorithm , The author modified the coding scheme , The compressed data can be expressed in a more concise form , It turns out that ,LZ4m In compression and decompression speed than LZ4 The algorithm improves 2.1x and 1.8x, Compression ratio marginal loss Less than 3%.
LZ4 analysis
Many compression algorithms with low compression delay are based on Lempel-Ziv Algorithm Of , But it still has shortcomings , Because the longest matching and some longer matching are difficult to reduce the time and space overhead , Thus incurring high time and space expenses . therefore , In practice , You usually change the strategy to quickly identify long enough substrings .
LZ4 It is in Lempel-Ziv One of the most successful compression algorithms developed on the basis of , The following is right LZ4 To explain the matching process :
In terms of algorithm
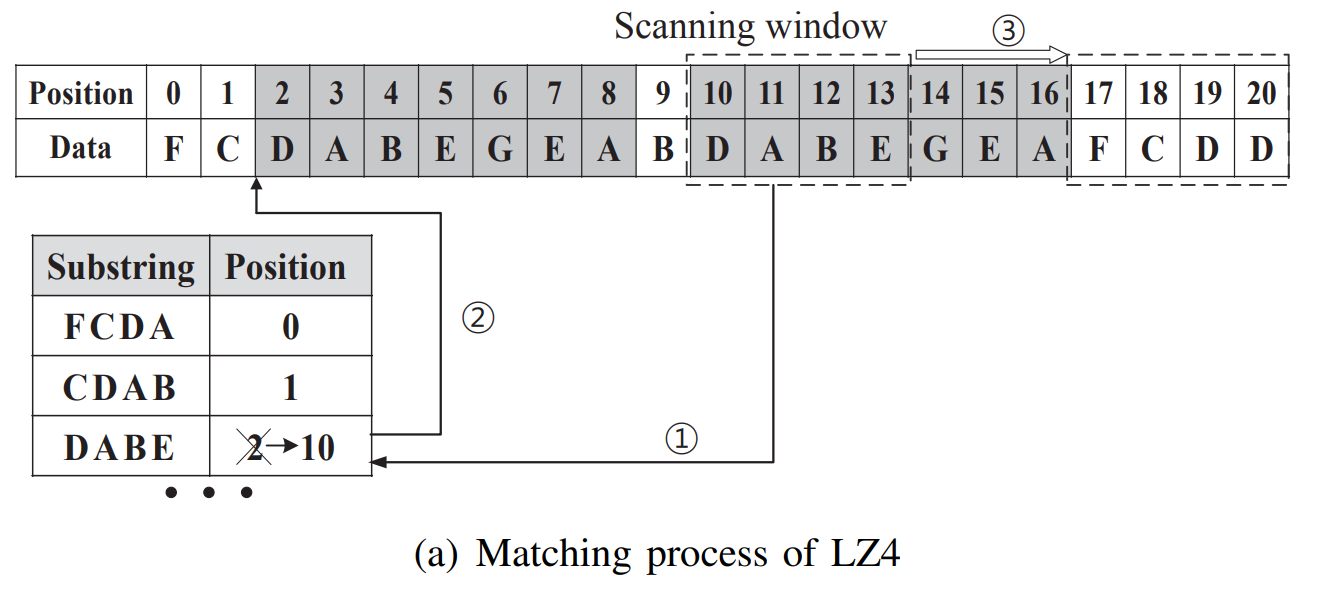
- LZ4 Mainly in its
The sliding windowAndHashtablepart , Slide the window every time you scan 4 Byte input stream , And check whether the string in the window has appeared before . - To assist in matching ,LZ4 A hash table is maintained , And will 4 A string of bytes is mapped from the beginning of the input stream .
- If the hash table contains the string in the current sliding window , Then the matching string will continue from the current scan position , Two substrings with the same prefix can match a longest substring , The corresponding hash table entry is updated to the current starting scanning position .
- Slide the window to continue moving , Constantly update the entries of substrings that are not in the hash table , Until the sliding window reaches the end .
structurally

- The input stream is encoded into a coding unit , One
Coding unit (Encoding unit)fromThe first one (Token)andThe main body (Body)Two parts . - Every
Coding unitAre subject to 1 Bytes ofThe first oneStart ,The first oneThe first four digits of are used to indicateThe main body (Body)OfLiteral lengthSize , The last four digits of the first part are used to indicateMatching lengthSize . - If the string exceeds 15 byte , That's the first
Literal lengthOf 4 All the seats are 1 when (1111), The literal length of the first part will be subtracted 15 And put it onThe first onehinderThe main bodyOn . The main body (Body)fromLiteral dataAndMatch descriptionform , amongMatch descriptionfromBackward match offsetAndMatching lengthform .- The offset in the body is determined by 2 Byte encoding , therefore LZ4 It goes back to 64 KB(
2^16/1024) To find a match . - Follow closely on a
matching (Match)The rest after thatmatching (Match)Code in a similar way , Only the text length field in the tag is set to0000, alsoThe main body (Body)omittedLiteral (Literal)part .
LZ4m analysis
because LZ4 It's a kind of General compression algorithm , There is no special optimization for a specific aspect , Its compression ratio and decompression speed are not fully released for a certain field . therefore , Here we will use the characteristics of data in memory to LZ4 Make changes .
Secondly, the data in memory . The data in memory consists of virtual memory pages , It contains data from the application's heap and stack . The heap and stack contain constants 、 Variable 、 Pointers and arrays of basic types , This data is usually structured , And align with the word boundary of the system .
Through the author's observation , It is found that scanning data in the granularity of matching words can accelerate data compression without significantly losing compression opportunities . Besides , because 4 Bytes for its sake , Larger granularity can represent length and offset in fewer bits , Substrings can be encoded in a more concise form .

According to the above information , The author puts forward LZ4m Algorithm , The box LZ4 Represents data in memory . In the figure below is LZ4 And LZ4m The difference between , At first glance there may be no difference , The sliding window 、 Hashtable , Both should have ; But a closer look reveals ,LZ4m The first part of LZ4 More Offset (Offset), Other parts ( Include The literal length of the first part , The matching length of the head as well as The literal offset of the body ) Changes have also been made to the memory size .
because 4 Byte alignment , To get the offset of the element in the structure , The length is 4 Multiple of bytes , The two least important bits are always 00( It's like 0,4,8,12 use Binary representation as 0000、0100、1000、1100, The last two are always 0, We can delete it to save space ), such The first one (Token) Of Literal length (Literal length)、 Matching length (Match length) as well as The main body (Body) Of Match offset (Match offset) Can be shortened 2 position .

Besides , because LZ4m In order to 4 Byte granularity compression 4KB The page of , So the offset needs at most 10 position , Therefore, the offset of 2 The most significant bits are placed in The first one (Token) in , Take the rest 8 Place in The main body in .
assessment
- take LZ4 and LZO1x Evaluation is the representative of general algorithm , take WKdm Evaluated as a professional Algorithm . The paper collects the memory data by exchanging the data cleared from the main memory .
- The compression ratio is the average of the pages , The smaller the compression ratio, the smaller the compression size of the same data .WKdm Has the largest compression ratio , The second is LZ4m,LZ4, And finally LZO1x, The velocity is normalized to LZ4m. And general algorithm ( namely LZ4 and LZO1x) comparison ,LZ4m Shows comparable compression ratios , Only reduced 3%.
- LZ4m It is superior to these algorithms in speed up to 2.1× and 1.8× Used for compression and decompression respectively .LZ4m The compression ratio and decompression speed are higher than WKdm many , But the price is that the compression speed decreases 21%. Sum up ,LZ4m In case of loss of compression ratio , A substantial increase in LZ4 Compression of / Decompression speed .
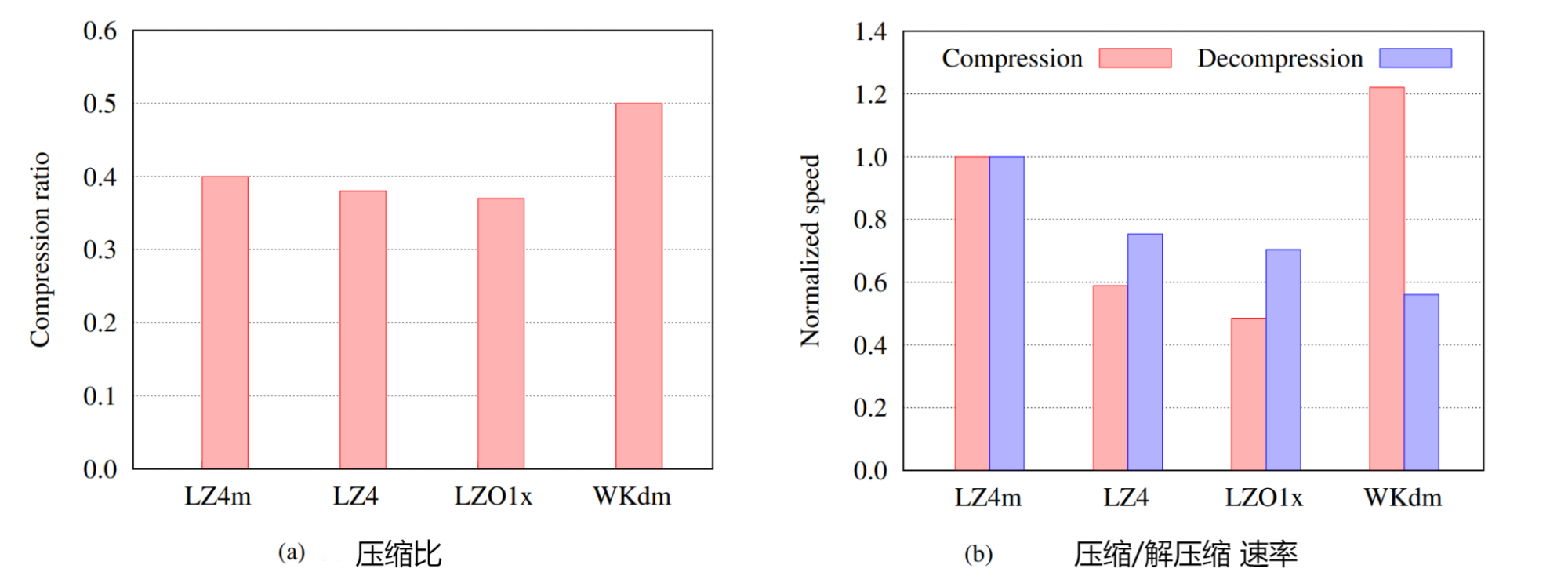
- The following figure shows the cumulative distribution of page compression .LZ4m The compression ratio curve of is only inferior to LZO and LZ4 Some algorithms , There is no big difference . and WKdm Show obvious compression ratio curve , Far behind other algorithms . also 6.8% Your page is simply unusable WKdm Compress , The proportion of using other pages is less than 1%. This shows that WKdm The compression acceleration of can be offset by its poor compression ratio
- Further comparison 4 The meaning of byte granularity matching offset and matching length , We will start with tracking the matching length , As shown in the original LZ4 and LZ4m The length of the matching substring is calculated in the result , Compare with cumulative match count . Magnified LZ4 and LZ4m The matching length is 0 To 32 Between the original results , The increased granularity only reduces the occurrence of total length matching 2.5%, It means 4 The byte granularity scheme has little effect on the chance of finding a match , The disadvantage in matching length is also negligible .

- Relationship between time and compression ratio , By measuring the compression time of each page and averaging the time of pages with the same compression ratio, the compression speed of the algorithm can be obtained . The time to compress a well compressed page is similar in the algorithm . Compared with LZ4 and LZO1x,LZ4m Shows excellent compression speed . because LZ4m The scanning process , If no prefix match is found , The scan window will be advanced 4 Bytes , This increases scanning speed by four times on pages that are difficult to compress .
- The decompression speed of the algorithm and the average decompression speed divided by the compression ratio , The speed is obtained in the same way as the average compression speed . LZ4m The decompression speed is better than other algorithms in almost the whole range of compression ratio .

Conclusion
- LZ4 It is the most efficient compression algorithm at present , More emphasis on compression and decompression speed , The compression ratio is not the first .
- A popular universal compression algorithm is optimized by using the inherent characteristics of memory data , According to the data ,LZ4m Can greatly improve the compression / Decompression speed , There is no substantial loss of compression ratio .
- LZ4m Optimized for small block size . The maximum offset is 270( stay LZ4 In Chinese, it means 65535).
- LZ4m The developers plan to use this new compression algorithm in real-world memory compression systems . But from 2017 No more code can be found after years .

reference
边栏推荐
- Command records of common data types for redis cli operations
- Training of long and difficult sentences in postgraduate entrance examination day85
- C ASP, net core framework value transfer method and session use
- Addition, deletion, modification and query of mysql~ tables (detailed and easy to understand)
- Matlab中图形对象属性gca使用
- Detailed explanation of route add command
- . How to exit net worker service gracefully
- Under what circumstances do you need to manually write the @bean to the container to complete the implementation class
- Redis6
- [in depth understanding of tcapulusdb technology] tcapulusdb model
猜你喜欢
Use pagoda to set up mqtt server

快手616战报首发,次抛精华引新浪潮,快品牌跃入热榜top3

【深入理解TcaplusDB技术】TcaplusDB构造数据

Slam visuel Leçon 14 leçon 9 filtre Kalman

Ruffian Heng embedded semimonthly issue 57

Dell R530内置热备盘状态变化说明

05 virtual machine stack

【深入理解TcaplusDB技术】TcaplusDB运维单据

【深入理解TcaplusDB技术】单据受理之创建业务指南

【深入理解TcaplusDB技术】如何实现Tmonitor单机安装
随机推荐
03 runtime data area overview and threads
RMAN备份数据库_重启RMAN备份
将Graph Explorer搬上JupyterLab:使用GES4Jupyter连接GES并进行图探索
Detailed explanation of route add command
Part 5:vs2017 build qt5.9.9 development environment
RMAN backup database_ Use RMAN for split mirror backup
Leetcode force buckle (Sword finger offer 26-30) 26 Substructure of tree 27 Image of binary tree 28 Symmetric binary tree 29 Print matrix 30 clockwise Stack containing min function
Training of long and difficult sentences in postgraduate entrance examination day87
【路径规划】如何给路径增加运动对象
[deeply understand tcapulusdb technology] tmonitor module architecture
How to develop the hash quiz game system? Hash quiz game system development application details case and source code
Interrupt operation: abortcontroller learning notes
【ELT.ZIP】OpenHarmony啃论文俱乐部—数据密集型应用内存压缩
Hash of redis command
Iet attends the 2022 World Science and technology community development and Governance Forum and offers suggestions for building an international science and technology community
[deeply understand tcapulusdb technology] create a game zone
. How to exit net worker service gracefully
jvm问题复盘
【深入理解TcaplusDB技术】单据受理之建表审批
C# asp,net core框架传值方式和session使用