当前位置:网站首页>Unity游戏优化(第2版)学习记录8
Unity游戏优化(第2版)学习记录8
2022-06-22 14:49:00 【咸鱼永不翻身】
Unity游戏优化[第二版]学习记录8
第8章 掌握内存管理
一、Mono平台
内存域
第一个内存域——托管域。该域是Mono平台工作的地方,我们编写的任何MonoBehaviour脚本和自定义的C#类在运行时都会在此域实例化对象,因此我们编写的任何C#代码都会很明确与此域交互。它称为托管域,因为内存空间自动被垃圾回收管理。
第二个内存域——本地域,它更微妙,因为我们仅仅间接地与之交互。Unity有一些底层的本地代码功能,它由C++编写,并根据目标平台编译到不同的应用程序中。该域关心内部内存空间的分配,如为各种子系统(诸如渲染管线、物理系统、用户输入系统)分配资源数据(例如纹理、音频文件和网格等)和内存空间。最后,它包括GameObject和Component等重要游戏对象的部分本地描述,以便和这些内部系统交互。这也是大多数内建Unity类(例如Transform和Rigidbody组件)保护其数据的地方。
第三个也是最后一个内存域是外部库,例如DirectX和OpenGL库,也包括项目中包含的很多自定义库和插件。
1、垃圾回收
垃圾回收器(Garbage Collector,GC)有一个重要工作,该工作确保应用程序不使用过多的托管堆内存,不再需要的内存会自动回收。例如,如果创建一个GameObject,接着销毁它,那么GC将标记该GameObject使用的内存空间,以便以后回收。这不是一个立刻的过程,GC只会在需要的时候回收内存。
Unity使用的Mono版本中的GC是一种追踪式的GC,它使用标记与清除策略。该算法分为两个阶段:每个分配的对象通过一个额外的数据位追踪。该数据位标识对象是否被标记(即是否被引用)。这些标记设置为false,标识它尚未被标记(尚未被引用)。
当收集过程开始时,它通过设置对象的标识为true,标记所有依然对程序可访问的对象。第二阶段涉及迭代这类引用,并基于它的标记状态决定它是否应该回收。
2、内存碎片
当以交替顺序分配和释放不同大小的对象时,以及释放大量小对象后分配大量大对象时,就会出现内存碎片。
例如:
(1)一个空的堆空间大小为384个字节,分配了4个大小为64字节的对象分别为A,B,C,D
(2)后来回收了A,C两个对象释放了128字节
(3)接着尝试分配128字节的大对象
此时已被释放的A,C对象由于在内存上不连续(相邻),此时不能从堆上分配一个大于两个独立空间的对象,这就是内存碎片。
3、运行时的垃圾回收
当游戏请求新的内存分配时,CPU在完成分配之前需要花费CPU周期完成下面的任务:
(1)验证是否有足够的连续空间用于分配新对象
(2)如果没有足够空间,迭代所有已知的直接和间接引用,标记它们是否可达
(3)再次迭代所有这些引用,标识未标记的对象用于回收
(4)迭代所有标识对象,以检查回收一些对象是否能为新对象创建足够大的连续空间
(5)如果没有,从操作系统请求新的内存块,以便拓展堆
(6)在新分配的块前面分配新对象,并返回给调用者
4、多线程的垃圾回收
GC运行在两个独立线程上:主线程和所谓的Finalizer Thread。当调用GC时,它运行在主线程上,并标志堆内存块为后续回收。这不会立刻发生,由Mono控制的Finalizer Thread在内存最终释放并可用于重新分配之前,可能会延迟几秒。
可以通过Profiler窗口中Memory Area的Total Allocated块观察此行为(绿线)。垃圾回收后可能需要几秒钟总分配值才会下降。由于这种延迟,不应该依赖内存一旦回收就可用这一观念,而且因此不应该浪费时间尝试消耗可用内存的最后一个字节。必须确保有某种类型的缓冲区用于未来的分配。
二、代码编译
当修改了C#代码,并且从喜欢的IDE(通常是MonoDevelop或功能更丰富的Visual Studio)切换到Unity编辑器时,代码会自动编译。代码会转换为通用中间语言(Common Intermediate Language,CIL),它是本地代码之上的一种抽象。这正是.NET支持多种语言的方式——每种语言都使用不同的编译器,但是它们都会转换成CIL。
在CIL中,中间CIL代码实际上根据需要编译为本地代码。这种及时的本地编译可以通过AOT(Ahead-Of-Time)或JIT(Just-In-Time)编译器完成,选择哪一个取决于目标平台。
AOT编译是代码编译的典型行为,它发生于构建流程之前,在一些情况下则在程序初始化之前。不管是哪一种,代码都以及提前编译,没用后续运行时由于动态编译产生的消耗。
JIT编译在运行时的独立线程中动态执行,且在指令执行之前。通常,该动态编译导致代码在首次调用时,运行得稍微慢一点,因为代码必须在执行之前完成编译。然而,只要执行相同的代码块,都不需要重新编译,指令通过之前编译过的本地代码执行。
不是所有平台都支持JIT编译,Unity在下面网址提供了一个完整的限制列表:
https://docs.unity3d.com/Manual/ScriptingRestrictions.html
IL2CPP
几年前,Unity Technologies面临着一个选择,要么选择继续支持Unity越来越难跟上的Mono平台,要么实现自己的脚本后端,Unity Technologies选择了后者,而现在有很多平台支持IL2CPP,它是中间语言到C++的简称。
IL2CPP是一个脚本后端,用于将Mono的CIL输出直接转换为本地C++代码。由于应用程序现在运行本地代码,因此这将带来性能提升。
注意IL2CPP自动在IOS和WebGL项目中启用。对于其它支持的平台,IL2CPP可以通过Edit | Project Settings | Player | Configure | Scripting Backend开启。
可以通过下面网址找到当前支持IL2CPP的平台列表:
https://docs.unity3d.com/Manual/IL2CPP.html
三、分析内存
1、分析内存消耗
无法直接控制本地域中发生的事情,由于没用Unity引擎源码,因此不能直接添加与之交互的代码。但可以通过各种脚本级别的函数间接控制它。
可以通过Profiler窗口的Memory Area观察已经分配了多少内存,以及该内存域预留了多少内存。本地内存分配显示在标记为Unity的值中,甚至可以使用Detailed Mode和采样当前帧,获得更多详细信息。
注意:Edit Mode下的内存消耗通常和独立版本大不相同,因为应用了各种调试以及编辑器挂接数据。应避免使用Edit Mode进行基准测试和测量。
可以使用Profiler.GetRuntimeMemorySize()方法获得特定对象的本地内存分配。
也可以在运行时分别使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()方法确定当前使用和预留的堆空间。
2、分析内存效率
可以用于度量内存管理健康度的最佳指标是简单观察GC的行为。它做的工作越多,所产生的浪费就越多,而程序的性能可能就越差。
可以同时使用Profiler窗口的CPU Usage Area(GarbageCollector复选框)和Memory Area(GC Allocated复选框)以观察GC的工作量和执行时间。这对于一些情况相对简单,比如只分配一个临时的小内存块或销毁GameObject。
然而,内存效率问题的根源分析是一件具有挑战且耗时的操作。当观察GC行为的峰值时,它可能是前一帧分配太多内存的征兆而当前帧只分配了一点内存,此时请求GC扫描许多碎片化的内存,确定是否有足够的空间,并决定是否能分配新的内存块。它清理的内存可能在很长一段时间之前就分配好了,只有应用程序运行了很长时间,才能观察到这些影响,甚至在场景相对空闲时也会发生,并没有突然触发GC的明显原因。更糟的是,Profiler只能指出最后几秒发生了什么,而不能直接显示正在请除什么数据。
如果想要确定没有产生内存泄漏,必须谨慎并严格执行测试程序,在模拟通常的游戏场景或者创造GC在一帧中有太多的工作需要完成的情况时,观察它的内存行为。
四、内存管理性能增强
1、垃圾回收策略
最小化垃圾回收问题的一种策略是在合适的时间手动触发垃圾回收,当确定玩家不会注意到这种行为时就可以偷偷触发垃圾回收。垃圾回收可以通过System.GC.Collect()手动调用。
触发回收的好机会可以是加载场景时,当游戏暂停时,在打开菜单界面后的瞬间,在切换场景时,或任何玩家观察不到或不关心突然的性能下降而打断游戏的行为时。甚至可以在运行时使用Profiler.GetMonoUsedSize()和Profiler.GetMonoHeapSize()方法决定是否需要调用垃圾回收。
Unity引擎中有一些不同的对象类型,它们实现了IDisposable接口类,例如:NetworkConnection,WWW,UnityWebRequest,UploadHandler,DownloadHandler,VertexHelper,CullingGroup,PhotoCapture,VideoCature,PhraseRecognizer,GestureRecognizer,DictationRecognizer,SurfaceObsercer等。这些都是用于拉取大数据集的工具类,可以调用脚本代码的Dispose()方法,可以确保在需要时及时释放内存缓冲区。
2、手动JIT编译
如果JIT编译导致运行时性能下降,请注意实际上有可能在任何时刻通过反射强制进行方法的JIT编译。反射是C#语言一项有用的特性,它允许代码库探查自身的类型信息、方法、值和元数据。使用反射通常是一个非常昂贵的过程,应该避免在运行时,或者甚至仅在初始化或者其它加载时间使用。不这样做容易导致严重的CPU峰值和游戏卡顿。
可以使用反射手动强制JIT编译一个方法,以获得函数指针:
var method = typeof(MyComponent).GetMethod(“MethodName”);
if (method != null)
{
Method.MethodHandler.GetFunctionPointer();
Debug.Log(“JIT compilation complete!”);
}
前面的代码仅对public方法有用。获取private或protected方法可以通过使用BindingFlags完成。
这类方法应该仅允运行在确定JIT编译会导致CPU峰值的地方。
3、值类型和引用类型
.NET Framework有值类型和引用类型的概念,而当GC在执行标记-清除算法时,只有引用类型需要被GC标记。大的数据集,从类实例化的对象都是引用类型。这也包括数组、委托、所有的类。
引用类型通常在堆上分配,而值类型可以分配在栈或堆上。诸如bool、int和float这些基础数据类型都是值类型的示例。这些值通常分配在栈上,但一旦值类型包括在引用类型中,例如类或数组,那么暗示该值对于栈而言太大,或存在的时间需要比当前的作用域更长,因而必须分配在堆上,与包含它的引用类型绑定在一起。
按值传递和按引用传递
技术上说,每次将数据的值作为参数从一个方法传到另一个,总会复制一些东西,不管它是值类型还是引用类型。传入对象的数据,通常称为按值传递。而只复制引用到另一个参数,则称为按引用传递。
值类型和引用类型之间的一个重要差异是引用类型只不过是指向内存中其它位置的指针,它仅消耗4或8字节(32位或63位,取决于架构),不管它真正指向的是什么。
数据也可以使用ref 关键字,按引用传递,但这和值与引用类型的概念非常不同。可以通过值或引用的方式传递值类型,也可以通过值或引用的方式传递引用类型。这意味着根据传统的类型以及是否使用ref关键字,有4中不同的数据传递情况。
结构体是值类型
Struct类型是C#中一个有趣的特殊情况。struct类型是值类型,class类型是引用类型。
如果使用类的唯一目的是在程序中间某处发送数据块,且数据块的持续存在时间不需要超过当前作用域,那么可以使用struct类型来代替。例如:
public class Test
{
public int a;
public bool b;
public float c;
…
}
可以改成:
public struct Test
{
public int a;
public bool b;
public float c;
…
}
仅将Test的定义从class类型修改为struct类型,就能节省很多不必要的垃圾回收,因为值类型在栈上分配,而引用类型在堆上分配。
这不是一刀切的解决方案。由于结构体是值类型,它将复制整个数据块,并传递到调用栈的下个方法中,不管数据块的大小。要解决此问题,可以使用ref关键字通过引用传递struct对象,以最小化每次复制的数据量(只复制一个指针)。然而,这可能很危险,因为通过引用传递结构体将允许后续方法修改struct对象,这种情况下最好将数据设置为只读。
数组和引用类型
数组是引用类型。
这意味着下面的代码将导致堆分配:
TestStruct[] dataObj = new TestStruct[1000];
for(int i = 0;i < 1000;++i)
{
dataObj[i].data = i;
DoSomething(dataObj[i]);
}
然而,下面的代码功能相同,但不会导致任何堆分配,因为所使用的struct对象是值类型,在栈上创建:
for(int i = 0;i < 1000;++i)
{
TestStruct dataObj = new TestStruct();
dataObj[i].data = i;
DoSomething(dataObj[i]);
}
注意,当分配引用类型的数组时,就是在创建引用的数组,每个引用都可以引用堆上的其它位置。然而,当分配值类型的数组时,是在堆上创建值类型的压缩列表。每个值类型由于不能设置为null,会初始化为0,而引用类型数组的每个引用会初始化为null,因为还没有被赋值。
字符串是不可变的引用类型
字符串本质上是字符数组,因此它们是引用类型,遵循与其它引用类型相同的所有规则:它们在堆上分配,从一个方法复制到另一个方法时唯一复制的就是指针。由于字符串是一个数组,这暗示着它包含的字符在内存中必须是连续的。然而,我们经常会扩大、连接或合并字符串,以创建其它字符串。这可能导致我们对字符串的工作方式做出错误的假设。我们可能会假设,由于字符串是如此常见、无所不在的对象,对它们执行操作既快速又低消耗。遗憾的是,这是错误的。字符串并不快速,只是比较方便。
字符串对象类是不可变的,这意味着它们不能在分配内存之后变化。所以,当改变字符串时,实际上在堆上分配了一个全新的字符串以替代它,原来的内容会复制到新的字符数组中,并且根据需要修改对应字符,而原来的字符串对象引用现在指向新的字符串对象。在此情况下,旧的字符串不再被引用,不会在标记-清除过程中标记,最终被GC清除。
下面的代码阐明了字符串和普通引用类型的不同之处:
void TestFunction()
{
string testString = “Hello”;
DoSomething(testString);
Debug.Log(testString);
}
void DoSomething(string localString)
{
localString = “world!”;
}
该示例将输出Hello。实际上是,由于引用通过值传递,DoSomething()作用域中的local String变量开始时引用内存中和testString一样的位置,这就有了两个引用。然而,一旦修改localString的值,就会发生一点冲突。字符串是不可变的,因而不能修改它们,因此,必须分配一个包含值”World!”的字符串并将它的引用赋给localString的值,此时”Hello”字符串的引用数量变为1(只有testString变量的引用)。因此,testString的值没有改变,调用DoSomething()之后,会在堆上创建一个新字符串,随后被垃圾回收,并没有修改任何数据。
如果修改DoSomething()的方法定义,通过ref关键字传入字符串的引用,输出就会变为”World!”。
总结一下:
· 如果通过值传递值类型,就只能修改其数据的副本值。
· 如果通过引用传递值类型,就可以修改传入的原始数据。
· 如果通过值传递引用类型,就可以修改原始引用的对象。
· 如果通过引用传递引用类型,就可以修改原始引用的对象或数据集。
4、字符串连接
void CreateFloatingDamageText(DamageResult result)
{
String outputTest = result.attacker.GetCharacterName() + “ dealt ” +
result.totalDamegeDealt.ToString() + “ ” +
result.damegeType.ToString() + “ damage to ” +
result.defener.GetCharacterName() + “ (” +
result.damageBlocked.ToString() + “ blocked)”
}
该函数输出如下字符串:
Dwarf dealt 15 Slashing damage to Orc (3 blocked)
该函数充满一些字符串字面量(在程序初始化期间分配的硬编码字符串),例如” dealt”” damage to ”” blocked)”等,它们对编译器而言是最简单的构造,编译器能提前为它们分配内存。然而,因为在合并字符串中使用了其它本地变量,该字符串不能在构建时编译,因此在运行时每次调用方法的时候,动态地生成完整的字符串。
每次执行+或+=操作符时,将进行新的堆分配:一次只合并一对字符串,每次都会为新字符串分配堆内存。接着,一次的合并结果被送到下一次处理,与下一个字符串进行合并,以此类推,直到构建除最终的字符串对象。
因此,前面的示例将导致在一条语句中分配了9个不同的字符串(注意操作符从右往左处理):
“3 blocked)”
“ (3 blocked)”
“Orc (3 blocked)”
“ damage to Orc (3 blocked)”
“Slashing damage to Orc (3 blocked)”
“ Slashing damage to Orc (3 blocked)”
“15 Slashing damage to Orc (3 blocked)”
“ dealt 15 Slashing damage to Orc (3 blocked)”
“Dwarf dealt 15 Slashing damage to Orc (3 blocked)”
这使用了262个字符而不是49个。因此,这样滥用字符串连接的程序,会浪费大量内存,来生成不必要的字符串。
StringBuilder
传统的观点认为,如果大致知道结果字符串的最终大小,那么可以提前分配一个适当的缓冲区,以减少不必要的内存分配。这正是StringBuilder类的目标。StringBuilder实际上是一个基于可变字符串的对象,工作方式类似于动态数组。它分配额一块空间,可以将未来的字符串对象复制到其中,并在超过当前大小时分配额外的空间。当然,应该尽可能预判需要的最大大小,并提前分配足够大小的缓冲区,以避免拓展缓冲区。
当使用StringBuilder时,可以通过调用ToString()方法取出结果字符串对象。这依然会为已经完成的字符串进行内存分配,但至少只分配了一个大字符串,而不像使用+或+=操作符那样分配很多较小的字符串。
字符串格式化
如果不知道结果字符串的最终大小,使用StringBuilder不可能会生成大小合适的缓冲区。得到的缓冲区要么太大(浪费空间),要么太小,这种情况更糟,因为必须在生成完整的字符串时不停扩大缓冲区。此时,最好使用各种字符串不同格式化方法的一种。
字符串类有3个生成字符串的方法:string.Format()、string.Join()、string.Concat()。每个方法的操作都有所不同。但最终输出都是一样的。分配一个新的字符串对象,包含传入的字符串对象的内容。而这些都是一步完成的,没有多余的字符串分配。
在给定的情况下,很难说哪种字符串生成方法更有利,因此最简单的方法是使用前面描述的其中一种传统方式。每当使用一种字符串操作方法遇到性能不佳的情况时,也应该尝试另一种方法,检查它是否会带来性能改善。
5、装箱(Boxing)
C#中一切皆对象,这意味着它们都继承自System.Object类。甚至int、float和bool等基本数据类型,都隐式从System.Object中继承,它本身是一个引用类型。每当这些值类型以处理对象的方式隐式地处理时,CLR会自动创建一个临时对象来存储或装箱内部的值,以便将其视为典型的引用类型对象。显然,这将导致堆分配,以创建包含的容器。
装箱和将值类型作为引用类型的成员变量不同。装箱仅在通过转化或强制转化将值类型视为引用类型时发生。
例如,下面的代码将整型变量i装箱在对象obj中:
int i = 128;
object obj = i;
下面的代码使用对象表示obj以替代保存在整型中的值,并拆箱回整型,将其保存在i中。最终i的值为256:
int i = 128;
object obj = i;
obj = 256;
i = (int)obj; // i = 256
同样的,这些类型可以动态修改:
int i = 128;
object obj = i;
obj = 512f;
float f = (float)obj; // b = 512f
同理以相同的方法转化为bool也是可以的。
注意,尝试将obj拆箱到一个不是最新赋值的类型时,将引发InvalidCastException异常:
int i = 128;
object obj = i;
obj = 512f;
i = (int)obj;
以上代码中,由于最近一次转化是float类型,这里将抛出InvalidCastException异常
装箱可以是隐式的,如前面的示例所示,也可以是显式的,通过类型强制转化为System.Object。拆箱必须显示强制类型转化为它的原始类型。当值类型传递到使用System.Object作为参数的方法时,装箱会隐式进行。
将System.Object作为参数的String.Format()方法就是这样的示例。
只要函数使用System.Object作为参数而传递了值类型,就应该意识到由于装箱而导致堆分配。
6、数据布局的重要性
本质上,我们希望将大量引用类型和值类型分开。如果是值类型(例如结构体)内有一个引用类型,那么GC将关注整个对象,以及它所有成员数据、间接引用的对象。当发生标记-清除时,必须在移动之前验证对象的所有字段。然而,如果将不同类型分离到不同数组中,那么GC可以跳过大量数据。
例如,如果有一个结构体对象数组,如下代码所示,那么GC需要迭代每个结构体的每个成员,这是相当耗时的:
public struct MyStruct
{
int myInt;
float myFloat;
bool myBool;
string myString;
}
MyStruct[] arrayOfStructs = new MyStruct[1000];
然而,如果每次将所有数据块重新组织到多个数组,那么GC会忽略所有基本数据类型,只检查字符串对象。下面的代码将使GC清除更快:
int[] myInts = new int[1000];
float[] myFloats = new floar[1000];
bool[] myBools = new bool[1000];
string[] myStrings = new string[1000];
这样做的原因是减少GC要检查的间接引用。当数据划分到多个独立数组(引用类型),GC会找到3个值类型的数组(string数组为引用类型数组),标记数组,接着立刻继续其它工作,因为没有理由标记值类型数组的内容。此时,GC不需要迭代额外的3000条数据(mtInts、myFloats和myBools中的3000个值)。
7、Unity API中的数组
Unity API中有很多指令会导致堆内存分配,例如:
GetComponent(); //(T[])
Mesh.vertices; //(Vector3[])
Camera.allCameras; //(Camera[])
每次调用Unity返回数组的API方法时,将导致分配该数据的全新版本。这些方法应该尽可能避免,或者仅调用很少次数并缓存结果,避免比实际所需要更频繁的内存分配。
Unity有一些其它的API调用,需要给方法提供一个数组,接着将需要的数据写入数组。例如提供Partical[]数组给ParticalSystem,以获取它的粒子数据。这些类型的API调用的好处是可以避免重复分配大型数据,然而,缺点是数组需要足够大,以容纳所有对象。如果需要获取的对象数持续增加,就会不断分配更大的数组。如果是粒子系统,需要确定创建的数组足够大,以包含任何给定时刻生成的最大数量的粒子对象。
8、对字典键使用InstanceID
字典用于映射两个不同对象之间的关联,它可以快速找出是否存在一个映射,如果是,它映射的是什么。常见的做法是将MonoBehaviour或ScriptableObject引用作为字典的键,但这会导致一些问题。当访问字典元素时,需要调用一些从UnityEngine.Object中继承的方法,这些对象类型都是从该类中继承。这使元素的比较和映射的获取相对较慢。
这可以通过使用Object.Get Instance ID()改进,它返回一个整数,用于表示该对象的唯一标识值,在整个程序的生命周期中,该值不会发生变化,也不会在两个对象之间重用。
最好以某种方式将这个值缓存到对象中,并将它作为字典中的键,那么元素的比较将比直接使用对象引用快两到三倍。
9、foreach循环
在Unity的C#代码中,很多foreach循环最终会在调用期间导致不必要的堆内存分配,因为它们在堆上分配了一个Enumerator类的对象,而不是在栈上分配结构体。
对于传统数组使用foreach循环是安全的。Mono编译器秘密地将数组的foreach循环转化为简单的循环。
成本可以忽略不计,因为堆分配成本不会随着迭代次数的增加而增加。只分配了一个Enumerator对象,并反复使用,总的来说,它只需要占用少量内存。
注意,对一个Transfrom组件执行foreach通常是迭代Transfrom组件的子节点的缩写。例如:
foreach(Transform child in transform)
{
//do stuff with ‘child’
}
然而,这将导致前述的堆分配问题。因此,应该避免该代码风格,而使用如下代码:
for(int i = 0;i < transform.childCount;++i)
{
Transform child = transform.GetChild(i);
//do stuff with ‘child’
}
10、协程
如前所述,启动一个协程消耗少量内存,但注意在方法调用yield时不会再有后续消耗。如果内存消耗和垃圾回收是严重的问题,应该尝试避免产生太多短时间的协程,并避免在运行时调用太多StartCoroutine()。
11、闭包
闭包是指有权访问另一个函数作用域中变量的函数。匿名方法和lambda表达式可以是闭包,但并不总是闭包。
例如:
System.Func<int, int> anon = (x) => { return x; };
int result = anon(5);
上述代码中的匿名函数不是闭包,因为它是自包含的,和其它本地定义的函数的功能一样。然而,如果匿名函数拉入它作用域之外的数据,该匿名函数会成为闭包,因为它封闭了所需数据的环境。下面的代码将导致闭包:
int i = 1024;
System.Func<int, int> anon = (x) => { return x + i; };
int result = anon(5);
为了完成该事务u,编译器必须定义新的自定义类,它引用可访问的数据值i所在的环境。在运行时,它在堆上创建相应的对象并将它提供给匿名函数。注意这包含了值类型,该值类型最初在栈上分配,这可能会破坏最初在栈上分配它们的目的。因此,第二个方法的每次调用都会导致堆分配以及无法避免的垃圾回收。
12、.NET库函数
.NET类库提供了海量通用的功能,以帮助程序员解决在日常开发中可能遇到的大量问题。
.NET类库中也有两大特性通常会在使用时造成重大的性能问题。这两个特性是LINQ和正则表达式。
LINQ提供了一种方式,把数组数据视为小型数据库,对它们使用类似SQL的语法进行查询。简单的代码风格和复杂的底层系统(通过使用闭包)暗示着,它有相当大的性能消耗。LINQ是一个好用的工具,但确实不适用于高性能、实时的应用程序,例如游戏,甚至不能运行在不支持JIT的平台上,例如IOS。
同时,通过Regex类使用的正则表达式允许执行重复的字符串解析,以查找匹配特定格式的子串,替换部分字符串,或从不同输入构造字符串。正则表达式是另一个非常有用的工具,但如果不需要它的特性时,直接的字符串替换可能更高效。
13、临时工作缓冲区
如果习惯为某个任务使用大型临时工作缓冲区,就应该寻找重用它们的机会,而不是一遍又一遍地重新分配它们,因为这样可以降低分配和垃圾回收所涉及的开销。应该将这些功能从针对特性情况的类中提取到包含大工作区的通用类上,以便多个类重用它。
14、对象池
谈到临时工作缓冲区,对象池时通过避免释放和重新分配,来最小化和建立对内存使用的控制的一种极好方法。当一个对象被回收时,只是隐藏它,使它休眠,直到再次需要它,此时它从之前的一个已回收对象中重新生成,并用来代替可能需要新分配的对象。
15、预制池
前面的对象池方案对于传统C#对象非常有用,但不适用于GameObject和MonoBehaviour等专门的Unity对象。这些对象往往会占用大量运行时内存,当创建和销毁它们时,会消耗大量CPU,在运行时还可能导致大量垃圾回收。例如,在小型RPG游戏的生命周期中,可能会产生一千个兽人,但在任何给定时刻,只需要一小部分,可能是10个。最好能像前面那样使用类似的池,例如Unity预制体,可以减少不需要的开销,避免创建和销毁不必要的990个兽人。
我们的目标是将绝大多数对象的实例化推到场景初始化时进行,而不是让它们在运行时创建。这可以节省大量运行时CPU,并避免由于对象创建和销毁以及垃圾回收带来的大量CPU峰值,但代价是场景加载时间和运行时内存消耗的增加。
(简写其中的代码部分,步骤如下标题所示)
可池化的组件
预制池系统
预置池
生成对象
预先生成实例
对象的回收
预制池和场景加载
预制池总结
16、IL2CPP优化
如果使用IL2CPP且需要从应用程序中挤出最后一点性能,那么可以查看下面链接中的系列博文:
https://blogs.unity3d.com/2016/07/26/il2cpp-optimizations-devirtualization/
https://blogs.unity3d.com/2016/08/04/il2cpp-optimizations-faster-virtual-method-calls/
https://blogs.unity3d.com/2016/08/11/il2cpp-optimizations-avoid-boxing/
17、WebGL优化
Unity Technologies还发布了一些关于WebGL应用的博文,其中还包括一些所有WebGL开发者都应该知道的关于内存管理的重要信息。可以在下面的链接中找到:
https://blogs.unity3d.com/2016/09/20/understanding-memory-in-unity-webgl/
https://blogs.unity3d.com/2016/12/05/unity-webgl-memory-the-unity-heap/
五、Unity、Mono和IL2CPP的未来
Unity使用.NET3.5类库的功能,目前它已经有10年历史了。这限制了.NET类库中可以使用的类,限制了C#语言特性,限制了性能,因此在此期间类库已经做了很多性能增强。然而,Unity2017(及之后的版本)可以通过Edit | Project Settings | Player | Configuration | Scripting Runtime Version修改为Experiment(.NET 4.6 Equivalent)。该设置升级了Mono运行库,并允许使用.NET4.6的功能。
查看Unity的路线图,以了解Unity Technologies正在做什么以及期待它们何时出现,参考网址是:
https://unity3d.com/unity/roadmap
即将到来的C# Job System
(看了一下,此技术Unity已经出了)
C# Job System的理念时能够创建在后台线程中运行的简单任务,以减轻主线程的工作负载。C# Job System非常适合于并行性差的任务,例如让成千上万个简单的AI代理同时在一个场景中操作等。当然,也可以用于传统多线程行为,在后台执行一些不需要立刻得到结构的计算。C# Job System也引入了一些编辑器技术改进,获得比简单将任务移到独立线程中更大的性能提升。
编写多线程的一个大问题时存在竞争条件、死锁和难以重现和调试的bug的风险。C# Job System旨在使这些任务比平常更简单。
Unity创始人之一Joachim Ante在Unite Europe2017上推出C# Job System的演讲,可以通过网址找到演讲:
https://www.youtobe.com/watch?v=AXUvnk7Jws4
边栏推荐
- 推进兼容适配,使能协同发展 GBase 5月适配速递
- Rosbag use command
- uni开发微信小程序自定义相机自动检测(人像+身份证)
- The difference between nvarchar and varchar
- Be an we media video blogger, and share the necessary 32 material websites
- 二分查找(整数二分)
- 【LeetCode】9、回文数
- 信创研究:国产数据库聚焦信创市场,华为Gauss有望成为最强
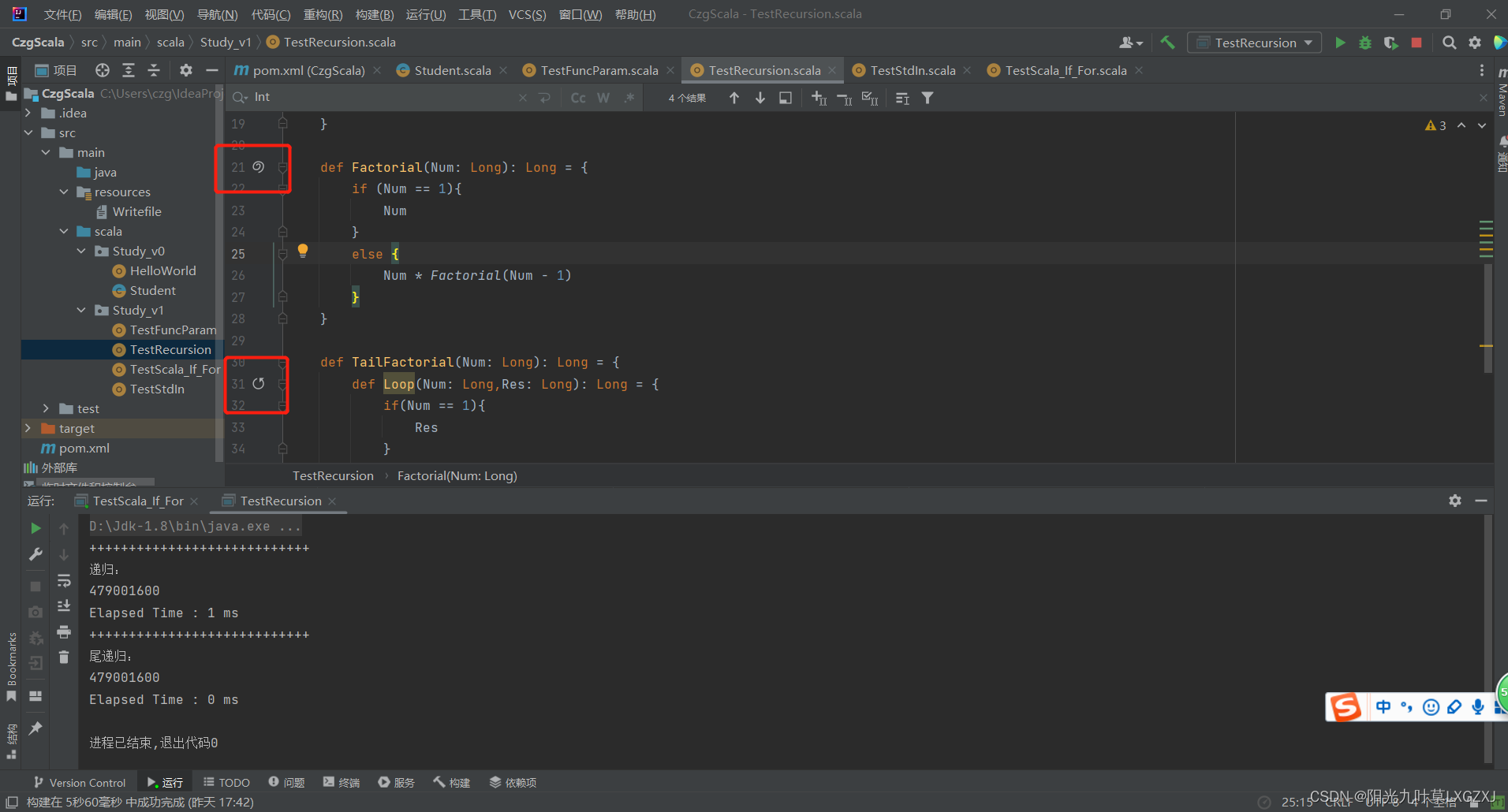
- Scala language learning-05-a comparison of the efficiency of recursion and tail recursion
- stack和queue的模拟实现
猜你喜欢


![[Shangshui Shuo series] day three - VIDEO](/img/42/0911fee2a36f6dda345a571a31acd5.png)




随机推荐
Scala语言学习-04-函数作为参数传入函数-函数作为返回值
mysql - sql执行过程
【山大会议】WebRTC基础之对等体连接
小程序开发----自定义有效期缓存
Scala language learning-04-function passed in as parameter function as return value
phantomJs使用总结
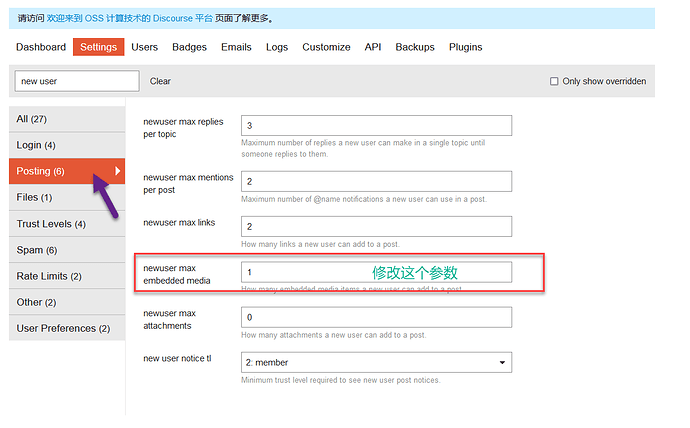
Trust level of discover
[Newman] postman generates beautiful test reports
【山大会议】软件性能优化及bug修复
HMS Core新闻行业解决方案:让技术加上人文的温度
迷宫问题(BFS记录路径)
Hello, big guys. Error reporting when using MySQL CDC for the first time
B树和B+树
【山大会议】注册页的编写
阿里云中间件的开源往事
标准化、最值归一化、均值归一化应用场景的进阶思考
着力打造网红产品,新捷途X70S焕新上市,8.79万起售
#进程地址空间
【山大会议】应用设置模块
Alibaba cloud middleware's open source past