当前位置:网站首页>标准化、最值归一化、均值归一化应用场景的进阶思考
标准化、最值归一化、均值归一化应用场景的进阶思考
2022-06-22 14:29:00 【日拱一两卒】
本文属于知识点总结,内容属于摘抄和整理
一、基本概念


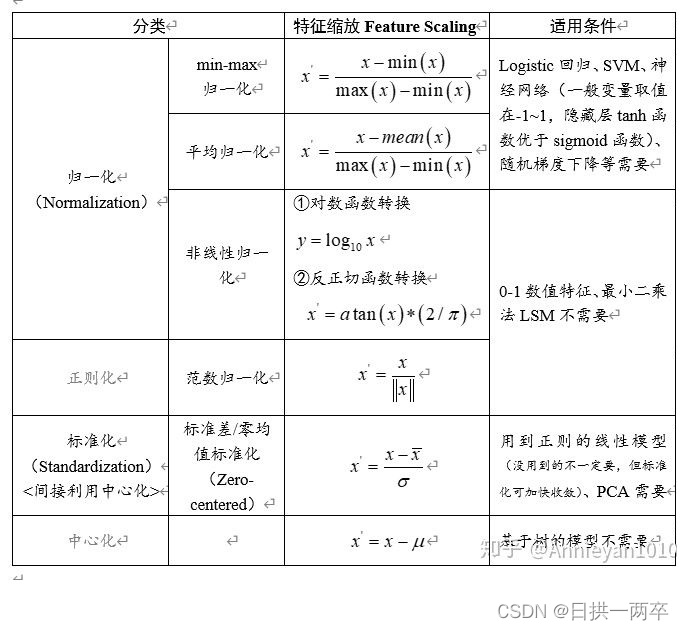
二、 不同归一化方法描述:
2.1 最值归一化
将原始数据线性化的方法转换到[0 1]的范围,该方法实现对原始数据的等比例缩放。通过利用变量取值的最大值和最小值(或者最大值)将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级影响,改变变量在分析中的权重来解决不同度量的问题。由于极值化方法在对变量无量纲化过程中仅仅与该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。

2.2 均值归一化
均值归一化和最值归一化基本一样,只是分母上是x-mean(x),数据会被压缩在[-1,1]的区间

2.3 标准化方法
即每一变量值与其平均值μ之差除以该变量的标准差σ。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异,从而转换后的各变量在聚类分析中的重要性程度是同等看待的。而实际分析中,经常根据各变量在不同单位间取值的差异程度大小来决定其在分析中的重要性程度,差异程度大的其分析权重也相对较大。

2.4 非线性归一化
- 对数函数转换:y = log10(x)
- 反余切函数转换:y = atan(x) * 2 / π
- 经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(V, 2)还是log(V, 10)等。
2.5 中心化
每一变量值与其平均值μ之差

2.6 图示
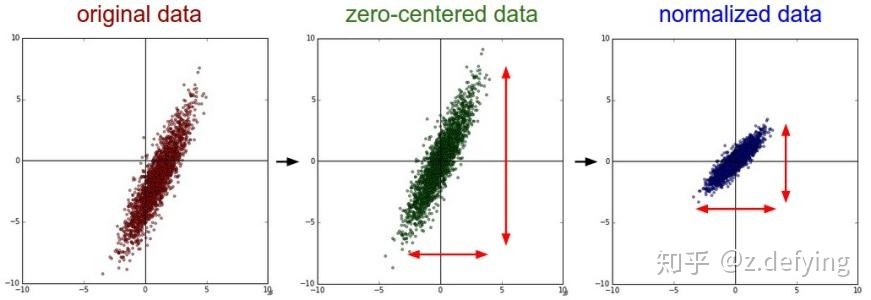
原始数据分布、零均值化数据分布、归一化数据分布

可以看到 mean 归一化和标准化都将数据分布中心移到原点,归一化没有改变数据分布的形状,而标准化使样本数据的分布近似为某种分布。
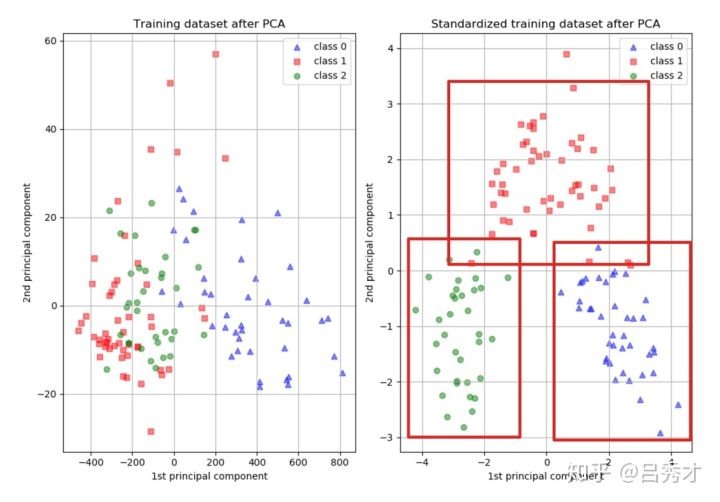
标准化对PCA降维的影响
三、如何选择
归一化和标准化的区别:归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1, 1]区间内,仅由变量的极值决定,因区间放缩法是归一化的一种。标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
标准化和中心化的区别:标准化是原始分数减去平均数然后除以标准差,中心化是原始分数减去平均数。 所以一般流程为先中心化再标准化。
什么时候用归一化?什么时候用标准化?
- 如果对输出结果范围有要求,用归一化。
- 如果数据较为稳定,不存在极端的最大最小值,用归一化。
- 如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
一般来说,建议优先使用标准化。
3.1 哪些模型必须归一化/标准化
3.1.1 SVM
不同的模型对特征的分布假设是不一样的。比如SVM 用高斯核的时候,所有维度共用一个方差,这不就假设特征分布是圆的么,输入椭圆的就坑了人家,所以简单的归一化都还不够好。
3.1.2 KNN、PCA、Kmeans
需要度量距离的模型,一般在特征值差距较大时,都会进行归一化/标准化。不然会出现“大数吃小数”。
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,标准化表现更好。在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。有时候,我们必须要特征在0到1之间,此时就只能用归一化。
3.1.3 神经网络
1)数值问题
归一化/标准化可以避免一些不必要的数值问题。输入变量的数量级未致于会引起数值问题吧,但其实要引起也并不是那么困难。因为tanh的非线性区间大约在[-1.7,1.7]。意味着要使神经元有效,tanh( w1x1 + w2x2 +b) 里的 w1x1 +w2x2 +b 数量级应该在 1 (1.7所在的数量级)左右。这时输入较大,就意味着权值必须较小,一个较大,一个较小,两者相乘,就引起数值问题了。
2)求解需要
a. 初始化:在初始化时我们希望每个神经元初始化成有效的状态,tanh函数在[-1.7, 1.7]范围内有较好的非线性,所以我们希望函数的输入和神经元的初始化都能在合理的范围内使得每个神经元在初始时是有效的。
b. 梯度:以输入-隐层-输出这样的三层BP为例,我们知道对于输入-隐层权值的梯度有2ew(1-a^2)*x的形式(e是誤差,w是隐层到输出层的权重,a是隐层神经元的值,x是输入),若果输出层的数量级很大,会引起e的数量级很大,同理,w为了将隐层(数量级为1)映身到输出层,w也会很大,再加上x也很大的话,从梯度公式可以看出,三者相乘,梯度就非常大了。这时会给梯度的更新带来数值问题。
c. 学习率:由(2)中,知道梯度非常大,学习率就必须非常小,因此,学习率(学习率初始值)的选择需要参考输入的范围,不如直接将数据归一化,这样学习率就不必再根据数据范围作调整。 隐层到输出层的权值梯度可以写成 2ea,而输入层到隐层的权值梯度为 2ew(1-a^2)x ,受 x 和 w 的影响,各个梯度的数量级不相同,因此,它们需要的学习率数量级也就不相同。对w1适合的学习率,可能相对于w2来说会太小,若果使用适合w1的学习率,会导致在w2方向上步进非常慢,会消耗非常多的时间,而使用适合w2的学习率,对w1来说又太大,搜索不到适合w1的解。如果使用固定学习率,而数据没归一化,则后果可想而知。
3.2 机器学习中哪些算法可以不做归一化
概率模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。像svm、线性回归之类的最优化问题就需要归一化。决策树属于前者。归一化也是提升算法应用能力的必备能力之一。
模型算法里面有没关于对距离的衡量,没有关于对变量间标准差的衡量。比如decision tree 决策树,他采用算法里面没有涉及到任何和距离等有关的,所以在做决策树模型时,通常是不需要将变量做标准化的。
四、不同归一化与不同激活函数之间的关系
4.1 sigmoid函数
首先以Sigmoid为激活函数来作为例子,Sigmoid函数的图像,公式如下:



Z型更新
当然这是对于第一层的情况而言的,经过第一层的激活函数Sigmoid输出后,所有的输出值范围都在[0,1]之间,也就是都大于0,所以后面的第二层、第三层到最后一层,在反向传播时,由于输入的 x 符号都为正一致,就会出现Z型更新现象,使得网络收敛速度很慢,这就是Sigmoid函数非零均值导致的问题。所以对于Sigmoid函数来说,第2、3到最后层神经网络,是存在Z型更新问题的,对于输入数据的零均值化,能够避免第一层神经网络的Z型更新问题。
为了避免Z型更新的情况,将输入进行零均值化,这样某次输入就会是正负掺杂的输入,每个 ω 的梯度符号和输入 x 相关,也就不会全部都一样,也就不会Z型更新了。
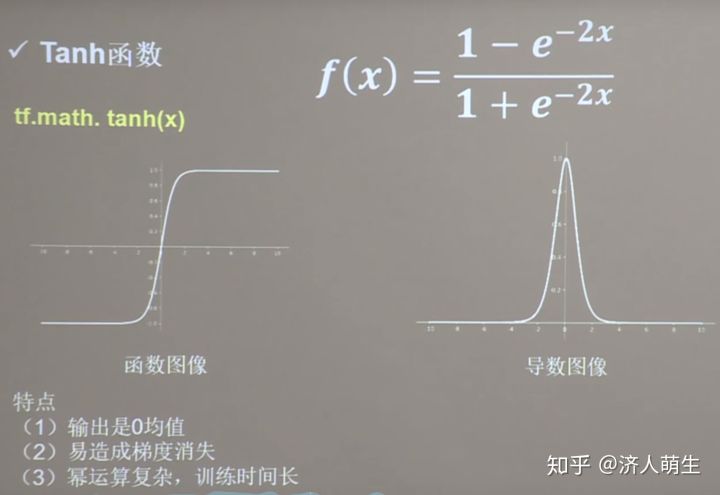
4.2 tanh函数
tanh函数也是经典的激活函数之一,函数图像,公式如下所示:

4.3 ReLU函数
ReLU是目前最通用的激活函数,函数图像、公式如下所示:


五、一些例子
5.1 逻辑回归必须要进行标准化吗?
这取决于我们的逻辑回归是不是用正则。如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。
举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是: 身高 = 体重*x ,x就是我们训练出来的参数。当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。
假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。
如果不用正则,那么标准化对逻辑回归有什么好处吗?答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
做标准化有什么注意事项吗?最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!
5.2 PCA需要标准化吗?
再来看一下,如果将预测房价的变量,用PCA方法来降维,会不会对结果产生影响。我们看出在标准化前,用一个成分就能解释99%的变量变化,而标准化后一个成分解释了75%的变化。 主要原因就是在没有标准化的情况下,我们给了居住面积过大权重,造成了这个结果。

5.3 Kmeans,KNN需要标准化吗?
Kmeans,KNN一些涉及到距离有关的算法,或者聚类的话,都是需要先做变量标准化的。
举例:我们将3个城市分成两类,变量有面积和教育程度占比;三个城市分别是这样的:
城市A,面积挺大,但是整天发生偷盗抢劫,教育程度低;
城市B,面积也挺大,治安不错,教育程度高;
城市C,面积中等,治安也挺好,教育程度也挺高;


我们如果不做标准化,直接做聚类模型的话,A城市和B城市分在一块儿了,你想想,一个治安挺好的城市和一个整体偷盗抢劫城市分在一起,实在是有点违反常理。
参考链接:
标准化和归一化 - nxf_rabbit75 - 博客园 (cnblogs.com)
归一化 (Normalization)、标准化 (Standardization)和中心化/零均值化 (Zero-centered) - 简书 (jianshu.com)
机器学习中常见的几种归一化方法以及原因_UESTC_C2_403的博客-CSDN博客_极差法归一化
边栏推荐
- C语言学生成绩排名系统
- How to open an account in flush? Is online account opening safe?
- The IPO of Tian'an technology was terminated: Fosun and Jiuding were shareholders who planned to raise 350million yuan
- 三菱机械臂demo程序
- 【newman】postman生成漂亮的测试报告
- ROS2前置基础教程 | 使用CMakeLists.txt编译ROS2节点
- Charles 乱码问题解决
- How MySQL modifies the storage engine to InnoDB
- 排序之归并排序
- 2020年蓝桥杯省赛真题-走方格(DP/DFS)
猜你喜欢

Countdown to the conference - Amazon cloud technology innovation conference invites you to build a new AI engine!

The summary of high concurrency experience under the billion level traffic for many years is written in this book without reservation

Are there many unemployed people in 2022? Is it particularly difficult to find a job this year?

What are strong and weak symbols in embedded systems?

What happened to those who didn't go to college
ROS2前置基础教程 | 小鱼教你用CMake依赖查找流程

TDengine 连接器上线 Google Data Studio 应用商店

HMS Core新闻行业解决方案:让技术加上人文的温度

Meet webassembly again

Ml notes matrix fundamental, gradient descent
随机推荐
What does Alibaba cloud's cipu release mean for enterprise customers?
打新债安全性有多高
宏源期货开户安全么?宏源期货公司可以降低手续费?
TDengine 连接器上线 Google Data Studio 应用商店
全新混合架构iFormer!将卷积和最大池化灵活移植到Transformer
flutter video_ Player monitors and automatically plays the next song
封装api时候token的处理
2020年蓝桥杯省赛真题-走方格(DP/DFS)
小白操作Win10扩充C盘(把D盘内存分给C盘)亲测多次有效
那些没考上大学的人,后来过的怎样
After 17 years, Liu Yifei became popular again: ordinary people don't want to be eliminated, but they also need to understand this
快速排序quick_sort
口令安全是什么意思?等保2.0政策中口令安全标准条款有哪些?
PowerPoint 教程,如何在 PowerPoint 中添加水印?
鸿世电器冲刺创业板:年营收6亿 刘金贤股权曾被广德小贷冻结
接了个私活项目,一下赚了15250,还有必要做主业吗?
再次认识 WebAssembly
After 100 days, Xiaoyu built a robot communication community!! Now invite moderators!
Charles 乱码问题解决
Is it difficult for flush to open an account? Is it safe to open an account online?