当前位置:网站首页>Thesis reading_ Relation extraction_ CASREL
Thesis reading_ Relation extraction_ CASREL
2022-06-23 05:05:00 【xieyan0811】
Introduce
English title :A Novel Cascade Binary Tagging Framework for Relational Triple Extraction
Chinese title : A cascaded binary annotation framework for extracting relational triples
Address of thesis :https://aclanthology.org/2020.acl-main.136.pdf
field : natural language processing , knowledge
Time of publication :2019
author :Zhepei Wei, Jilin University
Source :ACL
Quantity cited :3
Code and data :
https://github.com/xiangking/ark-nlp
https://github.com/weizhepei/CasRel
Reading time :2022.06.17
Journal entry
It mainly solves the problem of triple overlap , Compared with the previous model , Major adjustments have been made in the architecture .
Introduce
knowledge Information extraction (IE) It is an important part of constructing knowledge map from text . The specific operation is to extract relational triples from the text , It contains : The subject s, Relationship r, The object o. In the early days, pipes were generally used pipeline Method : First identify the entity in the sentence , Then establish a relationship for each entity pair , This may cause error propagation ; Later, there have been some methods based on artificial construction , Extract a joint model of entities and relationships ; After the popularity of the deep learning model , The model can build its own features , It makes relation extraction develop further .
Triple overlap problem , namely : Multiple relational triples in a sentence share the same entity . This problem has not been well solved , because , It breaks the assumptions made earlier to simplify the problem : Every token Marked only once , And each entity pair contains only one relationship .

chart -1 There are three cases :Normal Under the circumstances , The two triples identified do not overlap each other ;EPO Under the circumstances , There are many relationships between two entities ;SEO Under the circumstances , There are multiple overlapping triples .
The previous method separates entity annotation and relationship extraction , The interaction between the two steps is ignored . Due to the uneven distribution of relationship categories , And for a single relationship , Entity pairs do not satisfy the specified relationship in most cases , A large number of negative examples have been formed , There is also the lack of sufficient instances of each category . in addition , The effect of separating logic to deal with overlapping triples is not good .
In order to solve the technical problem , It is proposed that CASREL frame , Take relation as the mapping function from subject to object . It is divided into two steps : The first step is to identify all possible subjects in the sentence ; The second step is to probe various relationships and their corresponding objects for each topic . Finally, an end-to-end cascaded double label is designed ( Subject tag , Relational object labels ) frame .
Method
set up D As the training set ,x For a single piece of training data ,T For all triples contained therein :

Derive from the chain rule , Final , Split the extraction triplet into three parts , First , Search for the subject s; Then in the text x and s Under the condition of , Traverse all possible relationships r, Calculate the corresponding object o Probability of occurrence ; In the section on the right ,R\Tj|s Indicates a relationship that did not occur ,o∅ Is an empty object , That is to say, no corresponding object can be found for an impossible relationship .
To do so , First, it can directly optimize the evaluation criteria at the final triple level , The second allows entities to act as multiple triples , Mutual interference , Supports overlapping ; Third , By the type (3) Inspired a new extraction method , The classification of entity pairs , It becomes a mapping problem .
BERT Encoder
Using pre-trained BERT As a feature extractor , Convert text into vectors . See BERT The paper .
Cascade decoder
The core idea is to extract triples through two-step cascade : Find the subject first , Then find the corresponding relation and object of each subject .

Marked subject
The lower part of the figure is used to identify all subjects in the input sentence , adopt BERT Coding into vectors h, Then incoming Subject Tagger, For each token Check whether it is the start position or the end position of the topic .

For multi topic detection , You need to pair the start and end positions , Use the latest start-end Matching method , Ignore end stay start What happened before . If the prediction is correct ,start And end Will appear in pairs .
Specify the relationship marker object
The upper part of the figure shows the process of identifying the object , chart -2 in , Color distinguishes the different subjects recognized , Like orange Jackie R. Brown When recognized as a subject , It's a person's name , So there is no Capital of The relationship between , Although it may exist Work in Relationship , But there is no mention of . therefore , The reaction is also orange in the upper part of the figure , Yes Birth_place Relationship found two possible objects , Namely Washington and United States Of America.
except BERT The vector representation of the output , The vector representation of the subject is also taken into account v:

For each topic , Use the same decoder . Since the subject may be more than one word , Length is not fixed , Use the method of taking the mean value of the vector to calculate the vector of the subject in the above formula v.
When the relationship does not exist , The probability calculation method is as follows :

For an empty object , Marking of each start and end position y All for 0. Pictured -2 in Work in All corresponding positions are 0( See the description below for details ).
Objective function
Objective function J(Θ) The calculation method is as follows :

experiment
Data sets
Two public datasets were used in the experiment NYT and WebNLG. Relationship types are distributed differently :
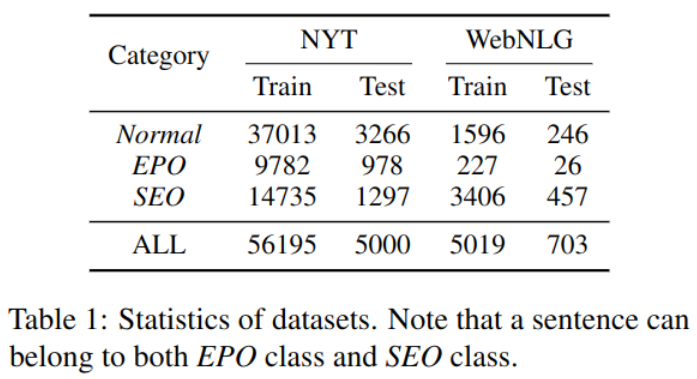
experimental result
To compare the effects of different encoders , stay CASREL Three kinds of encoders are tested in , At the bottom is the use of pre training BERT, The best effect ,random No pre training BERT Model ,LSTM Don't use BERT. Even without predictive training BERT,CASREL The model is also better than other models , In the process of the training BERT The model effect is further improved .

When triples overlap and a sentence contains multiple triples ,CASREL The effect is especially obvious .

边栏推荐
- centos7安装postgresql8.2.15及存储过程创建
- A mvc5+easyui enterprise rapid development framework source code BS framework source code
- ICer技能02makefile脚本自跑vcs仿真
- Welcome to the CSDN markdown editor
- 七年码农路
- An understanding of free() (an error in C Primer Plus)
- mysql json
- Can bus Basics
- Composer by installation laravel
- Official download and installation of QT and QT vs tools plug-ins
猜你喜欢

TabControl style of WPF basic control

PCB -- bridge between theory and reality

PaddlePaddle模型服务化部署,重新启动pipeline后出现报错,trt报错
【Proteus仿真】Arduino UNO+PCF8574+LCD1602+MPX4250电子秤

Precautions for running high-frequency and high-speed signal lines near PCB board - basic principles for high-frequency and high-speed signal design

A mvc5+easyui enterprise rapid development framework source code BS framework source code

2 万字 + 20张图|细说 Redis 九种数据类型和应用场景

Abnova liquidcell negative enrichment cell separation and recovery system
【图论】—— 二分图

Reinstallation of cadence16.3, failure and success
随机推荐
Freemodbus parsing 1
Cloud native database is in full swing, and the future can be expected
Less than a year after development, I dared to ask for 20k in the interview, but I didn't even want to give 8K after the interview~
The solution to prompt "this list creation could be rewritten as a list literal" when adding elements to the list using the append() method in pychart
Go learning record II (window)
开发一年不到,来面试居然敢开口要20K,面完连8K都不想给~
Precautions for running high-frequency and high-speed signal lines near PCB board - basic principles for high-frequency and high-speed signal design
Thinkphp6 template replacement
Gson typeadapter adapter
395. redundant path
Cloud function realizes fuzzy search function
AlertManager告警的单独使用及prometheus配置告警规则使用
Icer Skill 02makefile script Running VCS Simulation
Left and right values
dolphinscheduler 2.0.5 spark 任务测试总结(源码优化)
Flask Foundation: environment setup + configuration + mapping between URL and attempt + redirection + database connection
ICer技能03Design Compile
Shadertoy basic teaching 02. Drawing smiling faces
What are the types of independent station chat robots? How to quickly create your own free chat robot? It only takes 3 seconds!
Small problems in the spoole framework for TCP communication in PHP