当前位置:网站首页>Mysql入门学习(二)之子查询+关联
Mysql入门学习(二)之子查询+关联
2022-06-23 03:56:00 【默主归沙】
- 关联查询(重点)
1.1 子查询
概述:一个查询的结果作为另一个查询的条件
语法:SELECT 列名 FROM 表名 Where 条件(子查询结果)
案例: 查询工资大于Bruce 的员工信息
1.先查询到 Bruce 的工资(一行一列)
select salary from t_employees where first_name='Bruce';
2.查询工资大于 Bruce 的员工信息
SELECT * FROM t_employees where salary>6000;
3.组合 (子查询)
SELECT * FROM t_employees where salary>(select salary from t_employees where first_name='Bruce');
子查询-----------多行单列的情况
SELECT 列名 FROM 表名 Where 列名 in (子查询结果);
案例1:查询与名为’King’同一部门的员工信息
- 先查询 ‘King’ 所在的部门编号(多行单列)
select department_id from t_employees where last_name='King';
- 再查询80、90号部门的员工信息
select * from t_employees where department_id in (80,90);
- 组合
select * from t_employees where department_id in (select department_id from t_employees where last_name='King');
案例2:工资高于60部门所有人的信息
1.查询 60 部门所有人的工资(多行单列)
select salary from t_employees where department_id=60;
2.查询高于 60 部门所有人的工资的员工信息(高于所有)
select * from t_employees where salary > all(select salary from t_employees where department_id=60);
查询高于 60 部门的工资的员工信息(高于部分)
select * from t_employees where salary > any(select salary from t_employees where department_id=60);
[注意:当子查询结果集形式为多行单列时可以使用 ANY 或 ALL 关键字]
子查询----------作为一张表
语法:SELECT 列名 FROM(子查询的结果集) WHERE 条件;
案例:查询员工表中工资排名前 5 名的员工信息
- 先对所有员工的薪资进行排序(排序后的临时表)
select * from t_employees ORDER BY salary DESC;
- 再查询临时表中前5行员工信息
select * from t_employees LIMIT 0,5;
组合:
select * from (select * from t_employees ORDER BY salary DESC) as emp LIMIT 0,5;
注意:需要给结果集的虚拟表取个别名
直接两个条件的拼接:
select * from t_employees ORDER BY salary DESC LIMIT 0,5;
1.2 合并查询–两张表合在一起(了解)
SELECT * FROM 表名1 UNION SELECT * FROM 表名2 ----去除重复
SELECT * FROM 表名1 UNION ALL SELECT * FROM 表名2 ----没有去除重复
select * from t1 UNION SELECT * from t2;
select * from t1 UNION ALL select * from t2;
应用场景:用得较少,一般只用在特定场景,例如:合并两张班级表;(字段一致)
1.3 连接查询
内连接----两张表中匹配上的记录则查询出来(重点)
SELECT 列名 FROM 表1 连接方式 表2 ON 连接条件
案例: 查询老师表和班级表中匹配的记录
sql标准的方式: inner join on
select t.id,t.name,c.name as classname from teacher t inner JOIN classes c on t.id=c.t_id;
mysql的方式
select * from teacher t,classes c where t.id=c.t_id;
外连接----左外和右外 LEFT JOIN RIGHT JOIN
左外:以左边的表为准,都要显示出来,右边没有匹配,则显示null
右外:以右边的表为准,都要显示出来,左边没有匹配,则显示null
SELECT * FROM teacher t LEFT JOIN classes c ON t.id=c.t_id;
SELECT * FROM teacher t RIGHT JOIN classes c ON t.id=c.t_id;
- DML操作(增删改)(重点)
添加: INSERT INTO 表名(列 1,列 2,列 3…) VALUES(值 1,值 2,值 3…);
添加一条工作岗位信息
select * from t_jobs;
insert into t_jobs(job_id,job_title,min_salary,max_salary) values('QF_GP','QF_1',16000,26000);
修改:UPDATE 表名 SET 列 1=新值 1 ,列 2 = 新值 2,…WHERE 条件;
案例1:修改编号为100的员工的工资为 25000
update t_employees set salary=25000 WHERE employee_id=100;
注意:如果不加where,则会将表中的所有记录都修改了
案例2:修改编号为135的员工信息岗位编号为 ST_MAN,工资为3500
update t_employees SET job_id='ST_MAN',salary=3500 where employee_id=135;
删除: DELETE FROM 表名 WHERE 条件;
注意:删除也往往加where条件,否则删除所有记录
删除编号为135的员工
delete from t_employees WHERE employee_id=135;
删除姓Peter,并且名为 Hall 的员工
delete FROM t_employees where first_name='Peter' and last_name='Hall';
清空整表数据(TRUNCATE)
TRUNCATE TABLE 表名; —此删除更彻底,会将表全删除,然后再创建空表
TRUNCATE table t1;
- 数据类型
用于约束存储值的类型
重点记住的类型: int double(5,2) date datetime char VARCHAR
3.1 创建表
create table student(
id int(4),
name VARCHAR(20)
);
3.2 数据表的修改
ALTER TABLE 表名 操作;
向现有表中添加列
alter table student add age int;
修改表中的列信息
alter table student MODIFY name VARCHAR(30);
删除表中的列
alter table student drop age;
修改列名
alter table student CHANGE name st_name VARCHAR(20);
修改表名
alter table student rename t_student;
删除数据表
drop table student;
- 约束
问题:创建一张表,能否插入两条完全相同的数据,如果可以,有什么弊端
弊端:不能确定唯一的记录
实体完整性约束==
4.1 主键约束
一条记录的唯一标识,往往设置到id中,不能为null
create table student(
id int(4) primary KEY,
name VARCHAR(20)
);
INSERT INTO student(id,name) values(1,'张三');
INSERT INTO student(id,name) values(2,'张三');
4.2 唯一约束
确保该字段唯一的,可以为null,往往设置在非id字段中
create table student(
id int(4) primary KEY,
name VARCHAR(20) UNIQUE,
age int UNIQUE
);
INSERT INTO student(id,name,age) values(1,'张三',22);
INSERT INTO student(id,name,age) values(2,'张小三',25);
4.3 主键自增长列
(常用:primary KEY auto_increment)
create table student(
id int(4) primary KEY auto_increment,
name VARCHAR(20) UNIQUE,
age int
);
INSERT INTO student(name,age) values('康洋',22);
INSERT INTO student(name,age) values('康小洋',25);
INSERT INTO student(name,age) values('康大洋',28);
INSERT INTO student(id,name,age) values(8,'康中洋',28);
INSERT INTO student(age) values(28);
说明:主键自增长,从1开始,每次自增1
域完整性约束
限制列的单元格的数据正确性。
4.4 非空约束
create table student(
id int(4) primary KEY auto_increment,
name VARCHAR(20) UNIQUE NOT NULL,
age int
);
4.5 默认值约束
create table student(
id int(4) primary KEY auto_increment,
name VARCHAR(20) UNIQUE NOT NULL,
age int default 30
);
INSERT INTO student(name,age) values('康洋',22);
INSERT INTO student(name) values('康小洋');
4.6 引用完整性约束(外键约束)
两张表中的约束关系
主表中的主键,在从表中可以设置成外键;外键的值必须设置为主键的值
从表中设置约束,参考主表的主键
注意:当两张表存在引用关系,要执行删除操作,一定要先删除从表(引用表),再删除主表(被引用表)
- 事务(重点)
概述:事务往往是多个sql捆绑,要么都成功,则进行提交;有一个失败,则回滚
5.1. 模拟转账功能
create table account(
id int PRIMARY key auto_increment,
name VARCHAR(20) UNIQUE NOT NULL,
money double(8,2)
);
select * from account;
insert into account(name,money) values('黄雨鹏',200000);
insert into account(name,money) values('陈道',100000);
start TRANSACTION; 开启事务
update account set money=money-20000 where id=1;
//中间可能出现了异常
update account set money=money+20000 where id=2;
commit; 都成功则提交
ROLLBACK; 如果出现异常则回滚
5.2 事务的原理
开启事务后,sql语句都放在了缓冲区(回滚段);只有所有SQL正常执行,执行到commit,才写入到数据库中
否则,如果出现异常则会执行到rollback,删除回滚段
5.3 事务的特性(ACID)
原子性:不可分割的整体,要么事务都成功,要么都失败
一致性:不管事务是否成功,总体数据是不会改变的
隔离性:处在事务中的线程,和其他操作的线程是隔离的,互不影响的
持久性:一旦进行了提交,则永久性的写到了数据库中
应用场景:
一般用在安全性较高的项目,例如金融项目,商城项目等
- 权限管理(了解)
场景:一般在公司给你分配一个非管理员的账户,可能只负责查询或添加
创建一个zs的用户
create user 'zs' IDENTIFIED by '123';
用户授权
GRANT ALL ON mydb1.account TO 'zs';
撤销用户权限
REVOKE ALL on mydb1.account from 'zs';
删除用户
drop user 'zs';
也可以进行图形化用户管理操作
边栏推荐
猜你喜欢

【C语言】关键字

JSP入门级笔记

【Mac】安全性与隐私中没有任何来源选项
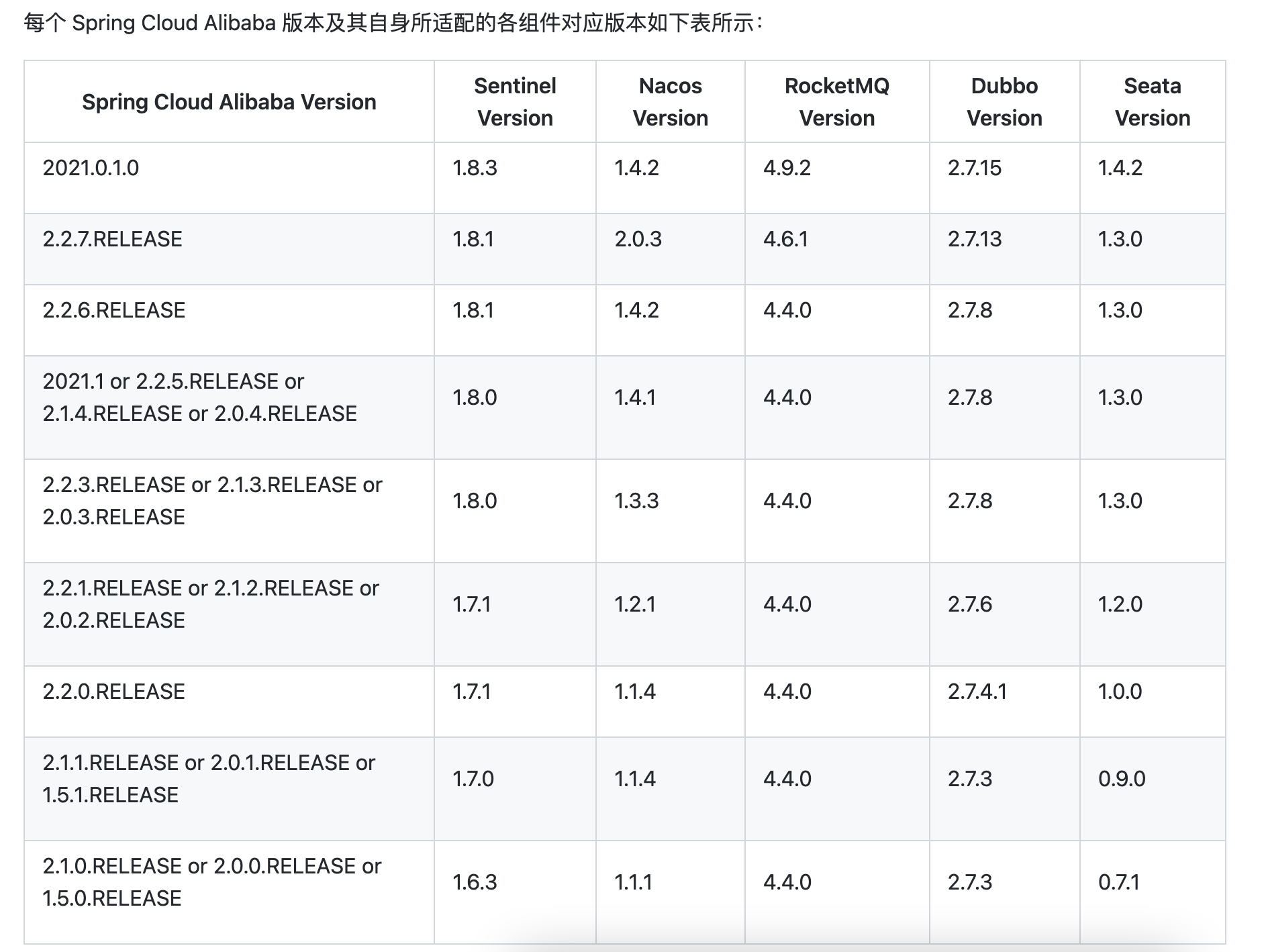
【微服务|Nacos】Nacos版本相关问题一览

OSPF shunt test

What is the average annual salary of an outsourced tester who has worked for 5-8 years?

I have been engaged in software testing for 5 years and have changed jobs for 3 times. I have understood the field of software testing

Web 应用程序安全测试指南

直接插入排序——【常见排序法(1/8)】

Missing essential plugin
随机推荐
A compiler related bug in rtklib2.4.3 B34
投资风险管理
三层架构实验
gis利器之Gdal(三)gdb数据读取
C language stack implementation
Rtklib new version 2.4.3 B34 test comparison
百度飞桨“万有引力”2022首站落地苏州,全面启动中小企业赋能计划
图片降噪DeNoise AI
Arduino flame sensor (with code)
8 years' experience: monthly salary of 3000 to 30000, the change of Test Engineer
Post processing of multisensor data fusion using Px4 ECL
如何进行探索性数据分析
李宏毅《机器学习》丨5. Tips for neural network design(神经网络设计技巧)
Servlet self study notes
计算欧式距离和余弦相似度
② Cocoapods principle and podspec file uploading operation
Cookie-Session讲解
Three methods of GNSS velocity calculation
vmware网络连接出错Unit network.service not found
Introduction and use of precise ephemeris