当前位置:网站首页>Double buffer technology asynchronous log system
Double buffer technology asynchronous log system
2022-06-26 04:06:00 【Dreamers on the road】
1. Problem scenario
In design mode , producer - The consumer model must be at the top of the list , In the actual development process , It's also often necessary to use this pattern .
In books that explain design patterns , Only from an abstract point of view to producers - Explain the consumer model . Faced with practical programming problems , We need to analyze the specific problems .
Here's a usage scenario , You can stop and think about how to solve the problem :
You need to implement a log Library , Each thread calls the log Library API Function to write log information , All log information needs to be persisted to the local file system .
Let's analyze , What problems need to be solved :
- Multithread call log Library API, therefore API Functions must be thread safe .
- Log information can't predict frequency , Consider peaks and troughs .
- Log information needs to be persisted to the local file system , It's about file manipulation , And the file's IO The operating speed is relative to CPU It's very slow for me .
- Every log information should not be written to the file immediately , Instead, it should be cached in memory , When the amount of data accumulates to a certain size, it is written to the file ( Of course , Also consider writing files on a regular basis ).
2. Solutions
Let's go back to the producers - On the consumer model . When books introduce this model , It's usually synchronous mode , namely :
- The producer generates a data and informs the consumer , Then wait for the data to be “ consumption ”;
- After the consumer receives the notice from the producer ,“ consumption ” data , Then inform the producer to continue production .
Production and consumption alternate , So I call it synchronous mode .
however , In the logging system mentioned above , Obviously not in synchronous mode . Because the speed of log generation and file writing cannot be estimated , for example : In a certain scenario, log generation is very fast , In another scenario, log generation is particularly slow .
For such needs , producer ( The generation of logs ) And consumers ( Write the log to a file ) Speed mismatch , Obviously, different threads should be used to execute . here , Do you immediately think of using message queuing for data buffering , It solves the problem of speed mismatch ? That's it :
- producer : Insert log information into the head of the queue ( The team )
- consumer : Read log information from the end of the queue ( Out of the team )
Of course , You also consider that because they are different threads , When operating on the same queue , You need a lock (Mutex) To protect message queues . That's about it :

It looks perfect , But there's a problem : Every time a consumer reads a log message from the message queue, it , Write to file system , But writing files is time-consuming . Get data from message queue frequently , And it's locked every time , It will certainly affect the efficiency of the producer's log writing , Because the producer also has to lock the message queue to insert the log information into the head of the queue , If the message queue is locked by the consumer at this time , Then producers have to wait sadly ~~ This will greatly affect the overall throughput of the log system .
3. Use double buffering
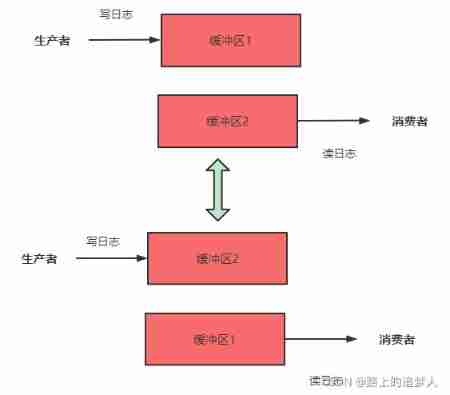
Since consumers are slow to write files , It must not affect the writing efficiency of the producer , So we can use two message queues to store : Log information being written , Reading log information for , It's called “ Double buffering ” technology . That's what it looks like with pictures :

Notice... In the picture above , The space in memory used to cache logs does not have to use message queues , Because log information is often of string type , Just use a continuous heap or stack space to store it , So in the picture we use “ buffer 1”、“ buffer 2” To express .
In this model , The producer sends to the buffer 1 Write log information in ; And consumers get out of the buffer 2 Read log information in , In this case , No matter how slow the consumer's file writing operation is, it will not affect the producer's log generation .
here , You must say : buffer 1 And buffer 2 It's two separate memory spaces , When the buffer 1 How to write the content after it is full “ Copy ” To the buffer 2 What about China? ?
Good question , This is also the key point for log system to achieve high throughput !
4. Buffer switching
The most intuitive idea is that at some point ( such as : buffer 1 It's full. , buffer 2 empty , timing ), Put the buffer on 1 The content in is memcpy Or other system functions , Copy to buffer 2 in . Of course, both buffers need to be locked in the process of copying data , Copy or move in the critical area , And the mobile operation should be as fast as possible , Only in this way can we have the least impact on producers and consumers . But if the amount of data is large , Mobile operation is still time-consuming .
Think again , In fact, what we need is not a real mobile operation , But there's a place for producers to store the data they generate , There's also a place for consumers to read data , As long as the goal is achieved .
There's a better way , It is to exchange the addresses of two buffers directly . We just need to point the producer to the buffer when writing data 1 Pointer to the buffer again 2, The buffer that the consumer points to when reading data 2 Pointer to the buffer again 1, This achieves the purpose of swapping buffers .
- Before swap buffer : The producer sends to the buffer 1 In the journal , Consumers from the buffer 2 Read the log in Chinese .
- After swapping buffers : The producer sends to the buffer 2 In the journal , Consumers from the buffer 1 Read the log in Chinese .
When performing an exchange operation , You also need to lock these two buffers . But what's operating in this critical region is : Swap the buffer space pointed to by two pointers , So the execution speed will be very fast .
In terms of language , about C It's about exchanging two 4 Address of byte , about C++ You can take advantage of container type swap function .
This is a better way to understand :
In the figure : On the left is what it looked like before the swap operation , On the right is what it looks like after the swap operation . You can see that producers and consumers operate different buffers at any time , So there's no interaction , And also achieve the purpose of rapid exchange of content .
Through such a double buffer technology to achieve the log system , The actual test found that , The throughput is much higher than many open source log libraries . If you are interested in , It's easy to test .
【 summary 】
Write here , What I want to express is basically over .
You may have other doubts , such as : When to swap buffers ? What to do when the write buffer is full ? That's another topic .
In this actual use scenario , Through double buffering technology , It solves the problem of asynchronous operation and speed mismatch between producers and consumers , Improve the overall throughput of the log system .
边栏推荐
- Small record of neural network learning 71 - tensorflow2 deep learning with Google Lab
- Link monitoring pinpoint
- Open source! Vitae model brushes the world's first again: the new coco human posture estimation model achieves the highest accuracy of 81.1ap
- Parse JSON interface and insert it into the database in batch
- Webrtc series - 7-ice supplement of network transmission preference and priority
- ABP framework Practice Series (III) - domain layer in depth
- Detailed explanation of globalkey of flutter
- win10 系统打开的软件太小,如何变大(亲测有效)
- Daily tests
- What's wrong with connecting MySQL database with eclipse and then the words in the figure appear
猜你喜欢
![[LOJ 6718] nine suns' weakened version (cyclic convolution, arbitrary modulus NTT)](/img/fd/0c299b7cc728f2d6274eea30937726.png)
[LOJ 6718] nine suns' weakened version (cyclic convolution, arbitrary modulus NTT)

After a test of 25K bytes, I really saw the basic ceiling

判断两个集合的相同值 ||不同值

Quanergy欢迎Lori Sundberg出任首席人力资源官

如何解决 Iterative 半监督训练 在 ASR 训练中难以落地的问题丨RTC Dev Meetup

使用Jsoup提取接口中的图片

軟件調試測試的十大重要基本准則
2021 year end summary

Wechat applet is bound to a dynamic array to implement a custom radio box (after clicking the button, disable the button and enable other buttons)

The stc-isp burning program for 51 single chip microcomputer always shows that "the target single chip microcomputer is being detected..." the cold start board does not respond
随机推荐
R language and machine learning
Using jsup to extract images from interfaces
Use soapUI to access the corresponding ESB project
力扣79单词搜索
VHDL设计
【QT】资源文件导入
Small record of neural network learning 71 - tensorflow2 deep learning with Google Lab
(15) Blender source code analysis flash window display menu function
Li Kou 79 word search
High performance computing center roce overview
How do wechat applets delay? Timing? Execute a piece of code after? (kengji)
VHDL design
線程同步之讀寫鎖
MySQL est livré avec l'outil de test de performance MySQL lap pour effectuer des tests de résistance
Quanergy欢迎Lori Sundberg出任首席人力资源官
How does virtual box virtual machine software accelerate the network speed in the virtual system?
钉钉开放平台-小程序开发实战(钉钉小程序服务器端)
MySQL common statements
The style of the mall can also change a lot. DIY can learn about it
Webrtc series - 6-connections tailoring for network transmission