当前位置:网站首页>爱可可AI前沿推介(6.23)
爱可可AI前沿推介(6.23)
2022-06-23 11:20:00 【智源社区】
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:目标检测的语言驱动上下文图像合成、图像GAN的非朗伯逆向渲染、重新思考3D GAN的训练、重初始化何时有效、免费(认证)对抗鲁棒性、大语言模型关于变化的规划和推理基准、自监督图块嵌入袋、全局上下文视觉Transformer、面向无人驾驶的3D目标检测综述
1、[CV] DALL-E for Detection: Language-driven Context Image Synthesis for Object Detection
Y Ge, J Xu, B N Zhao, L Itti, V Vineet
[University of Southern California & Microsoft Research]
DALL-E检测: 目标检测的语言驱动上下文图像合成。物体剪切和粘贴已经成为一种有前途的方法,可以有效地生成大量带标签的训练数据。它涉及到将前景物体掩码合成到背景图像上。当背景图像与物体相适应时,为训练目标识别模型提供有用的上下文信息。虽然该方法可以很容易地产生大量的标记数据,但为下游任务寻找一致的上下文图像仍然是一个难以解决的问题。本文提出一种新的规模化自动生成上下文图像的范式。其核心是利用上下文的语言描述和语言驱动的图像生成之间的相互作用。上下文的语言描述是通过在代表上下文的一小部分图像上应用图像描述方法来提供的。然后,这些语言描述被用于用基于语言的DALL-E图像生成框架来生成不同的上下文图像集。然后将这些图像与物体合成,为分类器提供一个增强的训练集。在四个目标检测数据集上证明了所提出方法比之前的上下文图像生成方法的优势。本文还强调了该数据生成方法在分布外和零样本数据生成场景中的合成特性。
Object cut-and-paste has become a promising approach to efficiently generate large sets of labeled training data. It involves compositing foreground object masks onto background images. The background images, when congruent with the objects, provide helpful context information for training object recognition models. While the approach can easily generate large labeled data, finding congruent context images for downstream tasks has remained an elusive problem. In this work, we propose a new paradigm for automatic context image generation at scale. At the core of our approach lies utilizing an interplay between language description of context and language-driven image generation. Language description of a context is provided by applying an image captioning method on a small set of images representing the context. These language descriptions are then used to generate diverse sets of context images using the language-based DALL-E image generation framework. These are then composited with objects to provide an augmented training set for a classifier. We demonstrate the advantages of our approach over the prior context image generation approaches on four object detection datasets. Furthermore, we also highlight the compositional nature of our data generation approach on out-of-distribution and zero-shot data generation scenarios.
https://arxiv.org/abs/2206.09592





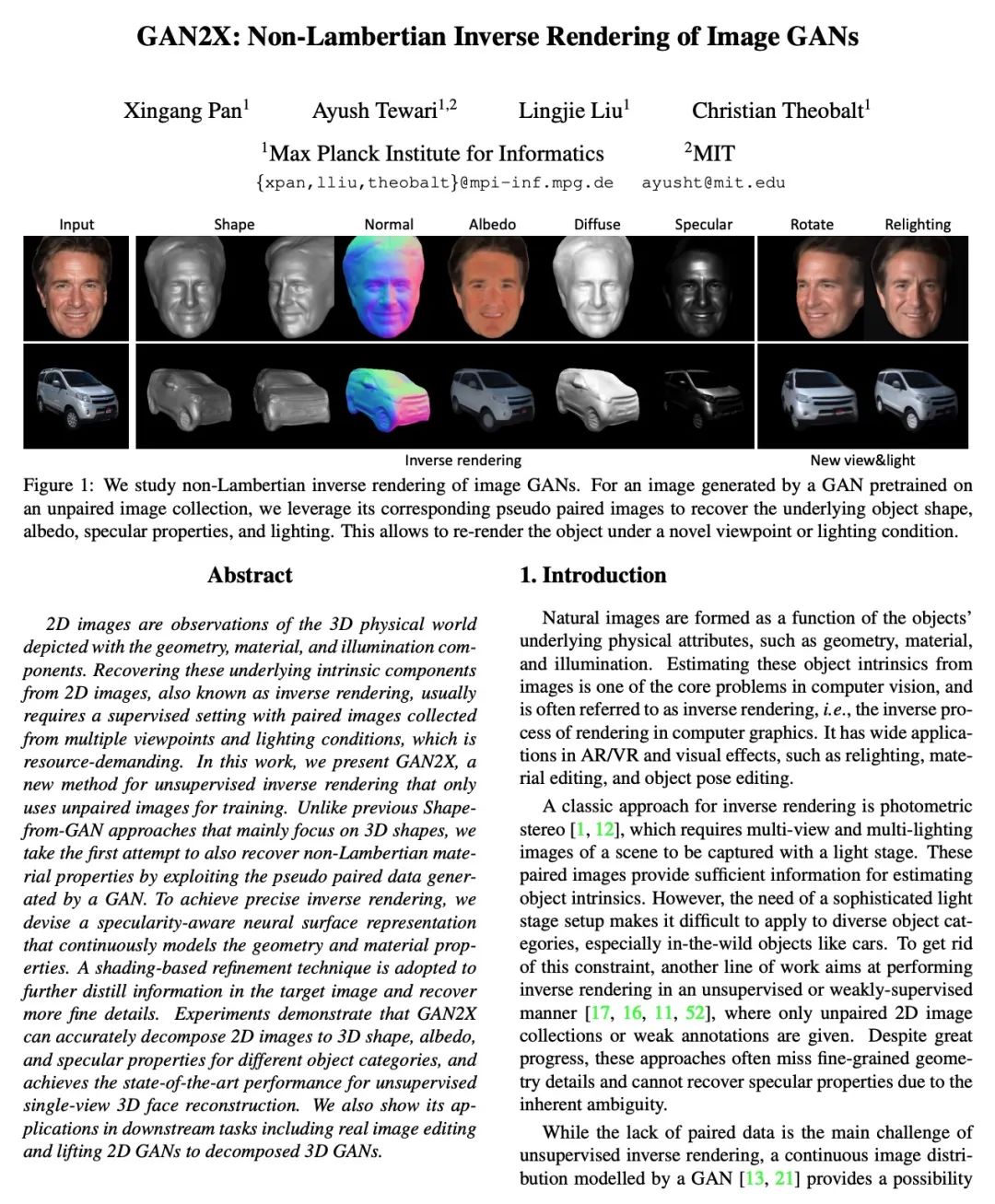
2、[CV] GAN2X: Non-Lambertian Inverse Rendering of Image GANs
X Pan, A Tewari, L Liu, C Theobalt
[Max Planck Institute for Informatics]
GAN2X:图像GAN的非朗伯逆向渲染。2D图像是对3D物理世界的观察,描述的是几何、材料和光照成分。从2D图像中恢复这些潜在的内在成分,也被称为逆向渲染,通常需要在有监督的情况下从多个视角和照明条件下收集成对的图像,对资源要求很高。本文提出GAN2X,一种用于无监督反演的新方法,只用未配对的图像进行训练。与之前主要关注3D形状的Shapefrom-GAN方法不同,本文首次尝试通过利用GAN生成的伪配对数据来恢复非朗伯材料属性。为实现精确的逆向渲染,本文设计了一种高光感知神经表面表示,对几何体和材料属性进行连续建模。采用一种基于阴影的细化技术来进一步提炼目标图像中的信息,并恢复更多精细的细节。实验表明,GAN2X能准确地将2D图像解缠为3D形状、反照率和不同对象的高光属性,并在无监督的单视角3D人脸重建中取得了最先进的性能。本文还展示了其在下游任务中的应用,包括真实图像编辑和将2D GAN提升到分解的三维GAN。
2D images are observations of the 3D physical world depicted with the geometry, material, and illumination components. Recovering these underlying intrinsic components from 2D images, also known as inverse rendering, usually requires a supervised setting with paired images collected from multiple viewpoints and lighting conditions, which is resource-demanding. In this work, we present GAN2X, a new method for unsupervised inverse rendering that only uses unpaired images for training. Unlike previous Shapefrom-GAN approaches that mainly focus on 3D shapes, we take the first attempt to also recover non-Lambertian material properties by exploiting the pseudo paired data generated by a GAN. To achieve precise inverse rendering, we devise a specularity-aware neural surface representation that continuously models the geometry and material properties. A shading-based refinement technique is adopted to further distill information in the target image and recover more fine details. Experiments demonstrate that GAN2X can accurately decompose 2D images to 3D shape, albedo, and specular properties for different object categories, and achieves the state-of-the-art performance for unsupervised single-view 3D face reconstruction. We also show its applications in downstream tasks including real image editing and lifting 2D GANs to decomposed 3D GANs.
https://arxiv.org/abs/2206.09244




3、[CV] EpiGRAF: Rethinking training of 3D GANs
I Skorokhodov, S Tulyakov, Y Wang, P Wonka
[KAUST & Snap Inc.]
EpiGRAF:重新思考3D GAN的训练。最近生成式建模的一个趋势,是从2D图像集合中建立3D感知生成器。为了归纳3D偏差,这种模型通常依赖于体渲染,而这种渲染在高分辨率下是昂贵的。在过去的几个月里,出现了10多项工作,通过训练一个单独的2D解码器对由纯3D生成器产生的低分辨率图像(或特征张量)进行上采样来解决该扩展问题。但这种解决方案是有代价的:它不仅破坏了多视图的一致性(即当摄像机移动时,形状和纹理会发生变化),还以低保真度学习几何。本文明有可能通过遵循一种完全不同的路线,即简单地逐图块地训练模型,来获得一个具有SotA图像质量的高分辨率3D生成器。本文以两种方式重新审视并改进这一优化方案。首先,设计了一种位置和尺度感知判别器,以便在不同比例和空间位置的图块上工作。其次,修改了基于退火β分布的图块采样策略,以稳定训练并加速收敛。由此产生的模型,即EpiGRAF,是一种高效、高分辨率、纯3D生成器,在256和512分辨率的四个数据集上对其进行了测试。它获得了最先进的图像质量、高保真的几何形状,并且比基于upsampler的同类产品的训练速度快≈2.5倍。
A very recent trend in generative modeling is building 3D-aware generators from 2D image collections. To induce the 3D bias, such models typically rely on volumetric rendering, which is expensive to employ at high resolutions. During the past months, there appeared more than 10 works that address this scaling issue by training a separate 2D decoder to upsample a low-resolution image (or a feature tensor) produced from a pure 3D generator. But this solution comes at a cost: not only does it break multi-view consistency (i.e. shape and texture change when the camera moves), but it also learns the geometry in a low fidelity. In this work, we show that it is possible to obtain a high-resolution 3D generator with SotA image quality by following a completely different route of simply training the model patch-wise. We revisit and improve this optimization scheme in two ways. First, we design a locationand scale-aware discriminator to work on patches of different proportions and spatial positions. Second, we modify the patch sampling strategy based on an annealed beta distribution to stabilize training and accelerate the convergence. The resulted model, named EpiGRAF, is an efficient, high-resolution, pure 3D generator, and we test it on four datasets (two introduced in this work) at 256 and 512 resolutions. It obtains state-of-the-art image quality, high-fidelity geometry and trains ≈2.5× faster than the upsampler-based counterparts. Code/data/visualizations: https://universome.github.io/epigraf
https://arxiv.org/abs/2206.10535





4、[LG] When Does Re-initialization Work?
S Zaidi, T Berariu, H Kim, J Bornschein, C Clopath, Y W Teh, R Pascanu
[University of Oxford & Imperial College London & DeepMind]
重初始化何时有效?在最近的工作中,人们观察到在训练期间重新初始化神经网络可以提高泛化能力。然而,它既没有在深度学习实践中广泛采用,也没有在最先进的训练方案中经常使用。这就提出了一个问题:重初始化何时有效,以及它是否应该与数据增强、权重衰减和学习率规划等正则化技术一起使用。本文对标准训练和精选的重初始化方法进行了广泛的经验比较,以回答这个问题,在各种图像分类基准上训练了超过15000个模型。首先确定,在没有任何其他正则化的情况下,这些方法始终有利于泛化。然而,当与其他精心调整的正则化技术一起部署时,重初始化方法几乎没有为泛化提供额外的好处,尽管最佳泛化性能对学习率和权重衰减超参数的选择变得不那么敏感。为了研究重初始化方法对噪声数据的影响,本文还考虑了标签噪声下的学习。令人惊讶的是,在这种情况下,重初始化大大改善了标准训练,即使在有其他精心调整的正则化技术的情况下。
Re-initializing a neural network during training has been observed to improve generalization in recent works. Yet it is neither widely adopted in deep learning practice nor is it often used in state-of-the-art training protocols. This raises the question of when re-initialization works, and whether it should be used together with regularization techniques such as data augmentation, weight decay and learning rate schedules. In this work, we conduct an extensive empirical comparison of standard training with a selection of re-initialization methods to answer this question, training over 15,000 models on a variety of image classification benchmarks. We first establish that such methods are consistently beneficial for generalization in the absence of any other regularization. However, when deployed alongside other carefully tuned regularization techniques, re-initialization methods offer little to no added benefit for generalization, although optimal generalization performance becomes less sensitive to the choice of learning rate and weight decay hyperparameters. To investigate the impact of re-initialization methods on noisy data, we also consider learning under label noise. Surprisingly, in this case, re-initialization significantly improves upon standard training, even in the presence of other carefully tuned regularization techniques.
https://arxiv.org/abs/2206.10011





5、[LG] (Certified!!) Adversarial Robustness for Free!
N Carlini, F Tramer, K (Dj)Dvijotham, J. Z Kolter
[Google & CMU]
免费(认证)对抗鲁棒性。本文展示了如何通过完全依赖现成预训练模型来实现对L2范数界内扰动的最先进的认证对抗鲁棒性。结合预训练的去噪扩散概率模型和标准的高精度分类器,实例化了Salman等人的去噪平滑方法。使得能证明在对抗扰动约束下71%的ImageNet准确性在ε = 0.5的L2范数内,使用任意方法比之前认证的SoTA提高了14个百分点,或比去噪平滑提高30个百分点。只使用预训练的扩散模型和图像分类器来获得这些结果,而无需任何微调或重新训练模型参数。
In this paper we show how to achieve state-of-the-art certified adversarial robustness to `2-norm bounded perturbations by relying exclusively on off-the-shelf pretrained models. To do so, we instantiate the denoised smoothing approach of Salman et al. by combining a pretrained denoising diffusion probabilistic model and a standard high-accuracy classifier. This allows us to certify 71% accuracy on ImageNet under adversarial perturbations constrained to be within an `2 norm of ε = 0.5, an improvement of 14 percentage points over the prior certified SoTA using any approach, or an improvement of 30 percentage points over denoised smoothing. We obtain these results using only pretrained diffusion models and image classifiers, without requiring any fine tuning or retraining of model parameters.
https://arxiv.org/abs/2206.10550



另外几篇值得关注的论文:
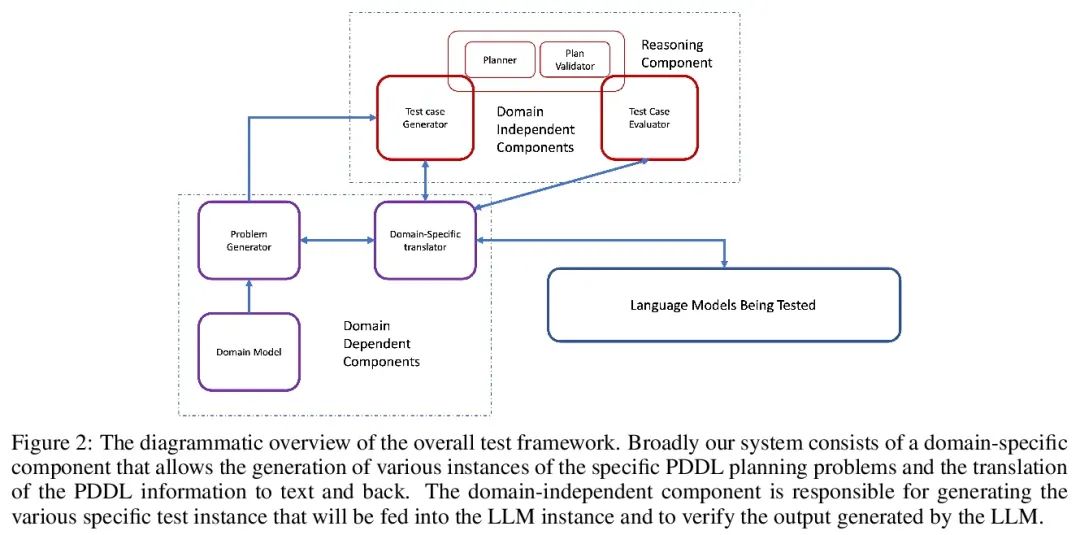
[CL] Large Language Models Still Can't Plan (A Benchmark for LLMs on Planning and Reasoning about Change)
大型语言模型仍然无法规划(大语言模型关于变化的规划和推理基准)
K Valmeekam, A Olmo, S Sreedharan, S Kambhampati
[Arizona State University]
https://arxiv.org/abs/2206.10498


[CV] Intra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding
Intra-Instance VICReg:自监督图块嵌入袋
Y Chen, A Bardes, Z Li, Y LeCun
[Meta AI & Redwood Center]
https://arxiv.org/abs/2206.08954





[CV] Global Context Vision Transformers
全局上下文视觉Transformer
A Hatamizadeh, H Yin, J Kautz, P Molchanov
[NVIDIA]
https://arxiv.org/abs/2206.09959





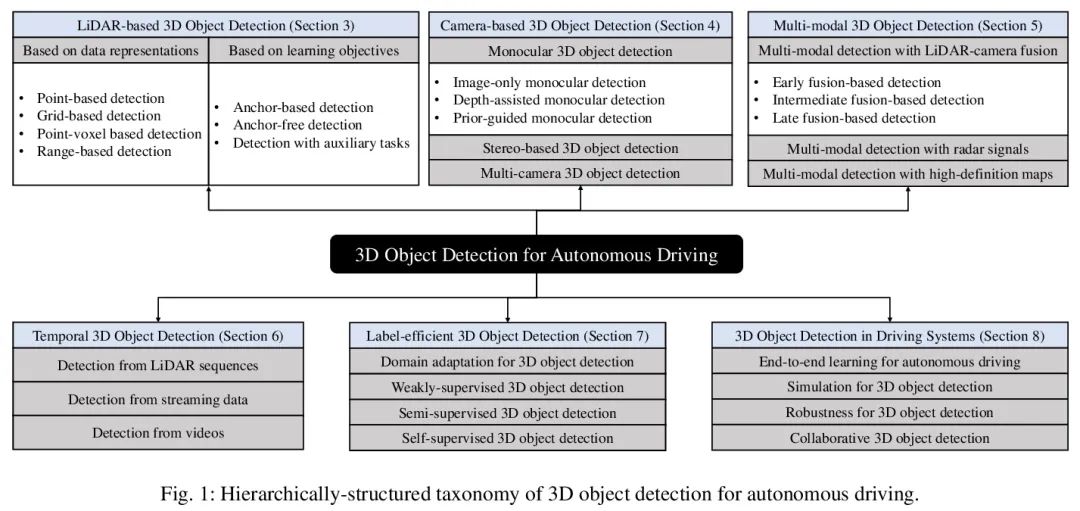
[CV] 3D Object Detection for Autonomous Driving: A Review and New Outlooks
面向无人驾驶的3D目标检测:回顾与展望
J Mao, S Shi, X Wang, H Li
[The Chinese University of Hong Kong & Max Planck Institute for Informatics]
https://arxiv.org/abs/2206.09474




边栏推荐
- 你真的理解LDO的输出电容吗!?
- Vone新闻 | 旺链科技赋能众享链网自组织管理,打造企业级联盟DAO
- How to write a literature review? What should I do if I don't have a clue?
- Comment Huawei Cloud réalise l'architecture mondiale de réseau audio - vidéo en temps réel à faible latence
- A child process is created in the program, and then the parent and child processes run independently. The parent process reads lowercase letters on the standard input device and writes them to the pip
- Force buckle 1319 Number of connected network operations
- Android security / reverse interview questions
- 攻防演练合集 | 3个阶段,4大要点,蓝队防守全流程纲要解读
- 【云舟说直播间】-数字安全专场明天下午正式上线
- Esp32-cam, esp8266, WiFi, Bluetooth, MCU, hotspot create embedded DNS server
猜你喜欢

Over a year, time has changed. Chinese chips have made breakthroughs, but American chips are difficult to sell

Rancher 2.6 new monitoring QuickStart

Economic common sense
Go zero micro Service Practice Series (VI. cache consistency assurance)

The simplest DIY serial port Bluetooth hardware implementation scheme

直播带货app源码搭建中,直播CDN的原理是什么?

长安LUMIN是否有能力成为微电市场的破局产品
Comment Huawei Cloud réalise l'architecture mondiale de réseau audio - vidéo en temps réel à faible latence

Win10 微软输入法(微软拼音) 不显示 选字栏(无法选字) 解决方法

tensorflow2的GradientTape求梯度

随机推荐
实战监听Eureka client的缓存更新
Monitor the cache update of Eureka client
1154. 一年中的第几天
At 14:00 today, 12 Chinese scholars started ICLR 2022
【云舟说直播间】-数字安全专场明天下午正式上线
Win10 微软输入法(微软拼音) 不显示 选字栏(无法选字) 解决方法
最简单DIY基于STM32F407探索者开发板的MPU6050陀螺仪姿态控制舵机程序
坦然面对未来,努力提升自我
Explain in detail the method of judging the size end
A child process is created in the program, and then the parent and child processes run independently. The parent process reads lowercase letters on the standard input device and writes them to the pip
Openharmony application development [01]
Argmax function notes - full of details
Esp32-cam high cost performance temperature and humidity monitoring system
More than observation | Alibaba cloud observable suite officially released
STM32F103ZET6单片机双串口互发程序设计与实现
quarkus+saas多租户动态数据源切换实现简单完美
ESP32-CAM、ESP8266、WIFI、蓝牙、单片机、热点创建嵌入式DNS服务器
“芯”有灵“蜥”,万人在线!龙蜥社区走进 Intel MeetUp 精彩回顾
运行时应用自我保护(RASP):应用安全的自我修养
MAUI使用Masa blazor组件库