当前位置:网站首页>Stone from another mountain - Intelligent Question and answer technology in wechat search
Stone from another mountain - Intelligent Question and answer technology in wechat search
2022-06-23 15:30:00 【kaiyuan_ sjtu】

author | Yang Tao @ tencent
Today, I'd like to introduce the intelligent Q & a technology in wechat search .
Expand around the following four points :
Background introduction
Q & A based on atlas
Document based Q & A
Future outlook
01
Background introduction
1. From search to Q & A

Search engine is an important way for people to get information , There are many questions and answers query. But traditional search can only return TopK The web page of , Users need to analyze and identify the answers from the web page , Poor experience . The reason is that traditional search engines are only for query and doc do “ matching ”, It is not really a fine-grained understanding query. Intelligent Q & A can make up for this limitation , Its advantage is that it can better analyze query, Direct return to accuracy 、 Reliable answers .
2. Common user Q & A requirements in search scenarios

Q & a fact based on the graph query, The answer form is short answer of entity phrase class . for example “ Andy Lau's wife ”, Or a collection of entities “ Four famous works in China ”, There's still time / Numbers etc. .
The second type is viewpoint type query, The answer is in the form of “ Yes or no ”, For example “ Can the high-speed rail evade tickets ” etc. .
The third type is abstract type query, Different from the first two types of short answers , The answer may need to be a long sentence summary , Usually “ Why? ”、“ What do I do ”、“ How do you do it? ” Other questions .
The last type is list type query, It's usually the process 、 Step related questions , The answer needs to be accurate with a list .
3. The source of knowledge

Structured data , From encyclopedia 、 Douban and other vertical websites infobox. The advantage is high quality , Easy to obtain and process ; The disadvantage is that only the head knowledge is covered , Insufficient coverage . for example “ Yi Jianlian's height ”、“ Infernal Affairs 1 Who is the director of ”.
Unstructured generic text , From encyclopedia 、 Official account and other Internet web page text libraries . The advantage is wide coverage , But the disadvantage is that the text quality is uneven , For medical 、 The coverage and authority of knowledge in the legal and other professional fields are not enough .
Unstructured question and answer Library of professional vertical websites , Question and answer data from vertical websites in the professional field , Usually in the form of question and answer pairs . The advantage is that it has a wide range of professional knowledge 、 High authority .
4. The technical route of intelligent question and answer

There are two main technical routes to support intelligent question answering :KBQA( Q & A based on atlas ) and DocQA( Document based Q & A ).
KBQA The advantage of is that it has strong scalability , It can query various attributes of entities , It also supports reasoning , Can parse complex queries . For example, the example on the right in the figure ,“ How tall is Yao Ming's wife ” The intermediate semantic expression can be parsed , Thus, it can be transformed into the query of knowledge map , Get the answer to the question . The key technology involved is atlas construction ( Include schema structure 、 Entity mining 、 Relationship extraction 、 Open information extraction technology ) And problem analysis ( Include entity Links 、 be based on semantic parsing Method of problem analysis 、 Retrieval based problem analysis methods and other technologies ).
DocQA Compare with KBQA Its advantage is that it has a wider coverage , It can cover more medium and long tail problems , At the same time, it can solve some problems KBQA Difficult to resolve . for example ,“ The first unequal treaty in Chinese history ” This query, It is difficult to parse into a structured expression , The technology involved mainly includes reading comprehension (MRC)、 Open domain Q & A (OpenQA).
02
Q & A based on atlas

KBQA The definition of : Given a natural language problem , Through semantic understanding and analysis of the problem , Then use knowledge base to query 、 Reason out the answer . The difficulties are as follows :
There are a lot of ambiguous entities in open domain knowledge base , for example “ The Great Wall ”、“ Apple ”, There may be many types of entities with the same name in the knowledge base . from query The correct entity identified in is the whole KBQA A key module in .
There are many attributes of knowledge map in open domain , Need from 4000+ Identify the correct attribute in the attribute .
There are many ways to ask in natural language , There are different ways to ask the same attribute , For example, ask Li Bai's birthplace , There can be “ Where is Li Bai from ”、“ Where is Li Bai's hometown ” And so on . The same question may also be for different attributes , for example “ How tall is Yao Ming ”、“ How high is Mount Everest ”, The same is “ How tall ”, But the asking attributes are height and altitude .
1. KBQA Technical solution

Scheme 1 : Retrieval method . hold query And candidate answers ( Candidate nodes in the knowledge map ) Represent as a vector to calculate the similarity . The advantage is that you can train end-to-end , But poor interpretability and scalability , Difficult to handle limitations 、 Aggregation and other complex types query.
Option two : A parsing based approach . hold query Parse into a queryable structured representation , Then go to the knowledge map to query . The advantage of this method is that it is highly interpretable , Maps that fit human understanding show the reasoning process , But rely on high-quality parsing algorithms . Consider the advantages and disadvantages , We mainly use this method in our practical work .
2. KBQA Overall process

First, an example is given to introduce KBQA The overall process of :
Entity link , Identify query Entity in , And associated to the nodes in the graph ;
Relationship recognition ,query The specific properties of the query ;
Topic Entity recognition , When query When multiple entities are involved , Determine which entity is the primary entity of the problem ;
Conditions / Constraint identification , analysis query Some constraints involved in ;
Query reasoning , Combine the results of the previous steps into query reasoning statements , Get the answer through the knowledge map .
In the whole process , The key modules are entity link and relationship recognition , The following two modules are mainly introduced .
3. KBQA- Entity link

Entity link , Recognize all entities from the text mention, Then link them to the corresponding knowledge map . Here is an example of entity linking .
First, through NER、SpanNER Other methods , Yes query Conduct mention distinguish ; According to the identified mention, Recall candidate entities in the knowledge map , And perform entity disambiguation , In essence, it is the sorting and scoring of recall entities . Sometimes, due to incomplete knowledge map data , There is no corresponding entity in the library , So there is usually a step “Top1 verification ”, That is, after sorting top1 The results were scored again , determine top1 Whether the result is the final entity .

Here is a brief introduction to a knowledge map used in our work ——TopBase. It is from TEG-AI The platform department builds and maintains a knowledge map focusing on general fields . At the data level, there are more than 50 fields , More than 300 entity types , Billion level entities and billion level triples . We have made a relatively complete automated construction process for this map , Including downloading 、 extract 、 Denoise 、 The fusion 、 Calculation and indexing steps . Due to structured InfoBox The data may be incomplete , We also built an unstructured data extraction platform .

Next, the candidate entity recall module is introduced . The traditional way is to use entity vocabulary , Make the original names and aliases of all entities in the knowledge map into a vocabulary , In case of recall mention Do vocabulary recall . There are usually two questions :
① Incomplete vocabulary leads to low recall rate , For example, Baolong and suoba in the picture , If you don't dig out the alias, you can't recall .
② Some entities mention There are many entities recalled , The disambiguation module will take a long time , For example, Zhang Wei in the picture , There may be dozens or hundreds of different types of people in the knowledge base .
To solve these two problems , The main solution is based on vector recall : take Query And entities are represented as vectors respectively , Then calculate the similarity . The matching model is a two tower model , The training data is Query And its corresponding entity mention. Names are used for candidate entities 、 Description information and introduction are used as model input , Match and recall through this model .
There is a problem in the training process , There are many negative examples in this task , If random sampling is adopted directly , Most of the negative examples are simple , Make it difficult to learn well . The solution adopted is : Use the model of the last round to get query As a negative example , The training model is integrated with the current training set , Iterating over the process . The advantage of this is , In the process of iterative training , Difficult negative examples will be added in each round , Let difficult negative examples learn better . You can see from the table that this kind of training is more effective .
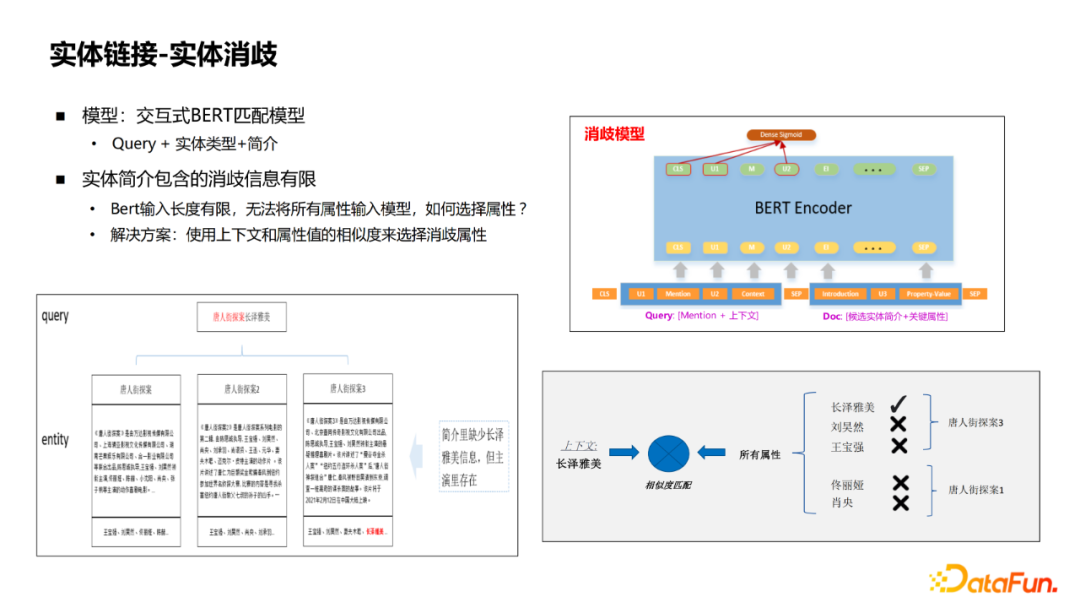
After the entity is recalled , The next process is entity disambiguation , The model used is interactive BERT Match model , take Query And an introduction to the entity 、 The description information is spliced together for scoring . But it is not enough to describe an entity only with a brief introduction , For example, in 《 Chinatown detective 》 in ,“ Yamami nagazawa ” Not in the profile , Only in the actor attribute . therefore , More importantly, the attribute values of entities are added to the disambiguation model . But the attribute values of entities are very large , It is impossible to join all of them , The scheme adopted is to recall the attributes roughly , use query Do lightweight similarity calculation with the attribute value of the entity , For example, word bag 、word2vec The vector of TopK Other methods , Splice here for disambiguation .
4. KBQA- Relationship recognition

Relationship recognition is to identify which relationship or attribute of the entity the question is asking , To complete this task , Whether it is a rule-based policy approach or a model-based approach , The first thing to do is to dig the template library of relationships , Common methods :
① Based on seed triples , This is a classic method . Find some common triples of attributes and relationships from the knowledge map , Go back to mark this question and answer right , Match the question to the subject , Match the paragraph answer to the object , There is reason to think that this question is asking this attribute . After matching some data , It can be done strategically or manually , Mining templates for each relationship or attribute .
② For the attribute with seed question , You can use a question based approach pattern How to extend : Using the synonymous matching model from query log Search for synonymous extended questions in , You can use query Click log or open source dataset training model , When there is a seed question of an attribute , Use this model to match query log Get data , Combined with manual or machine verification to obtain the extended method .
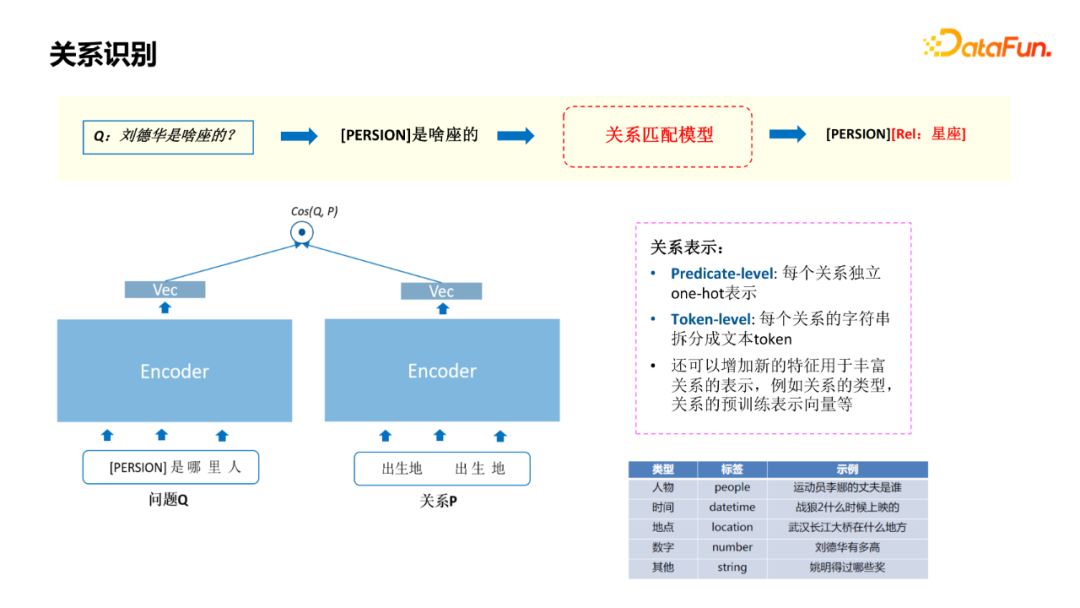
Just now, I introduced the construction of the template library , Our model is also based on matching . As identified on the left of the figure mention With it type To replace , adopt Encoder Get vector ; As shown on the right , It's about relationships encode. The representation of a relationship has two parts , The first part is to be independent of each relationship one-hot Express , The second part is to split the string of each relationship into text token. Another advantage of this model is that it can add some new features , A representation used to enrich relationships , As shown in the right part of the figure . For example, the object type of relation , And the pre training representation vector , It can further improve the training effect of the model .

The problem of poor robustness is often encountered in the process of making relational models , Here's why :
① user Query Often very short , And the expression is diverse .
② Query Small changes in expression can easily lead to model prediction errors .
The solution to this problem is to introduce confrontation learning , It is mainly used on the sample side and the training side .
On the sample side, more... Can be generated in a variety of ways “ Counter samples ”, Sample enhancement is used to improve the robustness and generalization ability of the model . As shown in the figure, for the original sample , Can pass seq2seq、 Back translation or synonym replacement to generate extended confrontation samples , But some of the generated samples may not be synonymous , It's noise , This can be judged by a synonymous model or strategy . Finally, the generated samples and the original samples are combined for training , Improve the robustness of the model .
On the training side , Disturbances can be added to the training process , Adopt the way of confrontational learning , Implicit construction “ Counter samples ”. Confrontation training is generally a two-step process , The first is to generate disturbances : Select the gradient direction ( send loss The largest direction ); The second is Embedding After adding disturbance to the layer, the model is trained normally again ( send loss Minimum ).
5. KBQA- Complex query parsing

People usually search for simple things Query, But there are also some complications Query, The relationship recognition model just introduced is difficult to handle and complex Query Of . The figure lists some complex Query Example , Multi hop 、 Multiple qualification 、 Ordinal number 、 Whether or not and counting are both complex problems that users often search Query type .
these Query The relationships involved may be multiple , And there are many entities involved . Therefore, it is difficult to handle this situation with the just mentioned relationship recognition model . Because it is a multi relationship 、 Multi entity , It can be represented as a graph , Here are some query graphs , In this way , The simple single entity just now 、 The single hop Q & A is expanded to Query Graph Structure , We hope to use such a more complex graph structure to parse more complex Query.

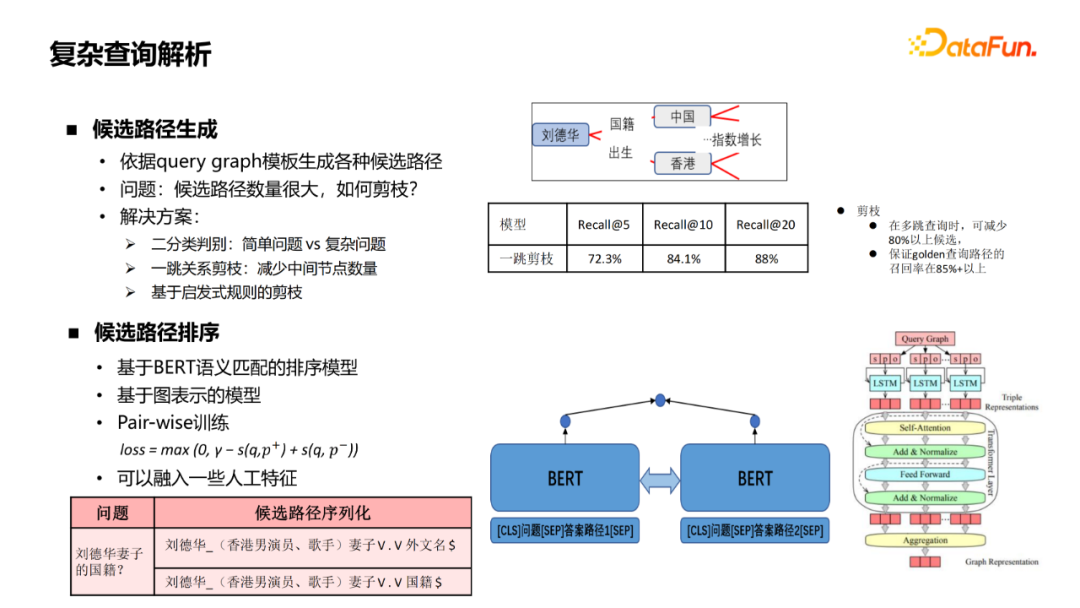
There are two key modules for complex queries , One is candidate path generation , basis query graph The template generates various candidate paths , But the number of generated paths is very large , Several common pruning schemes :
Two classification discrimination : Simple problem or complex problem
One jump relationship pruning : Reduce the number of intermediate nodes
Pruning based on heuristic rules
By these means , On the basis of ensuring a certain recall rate , Candidates can be reduced by 80% to 90% .
There are generally two schemes for sorting candidate paths :
① be based on BERT A sort model for semantic matching .BERT You need to enter a sentence , So first, the query graph is serialized into a piece of text , And then search together with the problem splicing , Get matching score , Then based on the pair-wise The method of training . The disadvantage of this method is , Serialized the query graph , There is no better use of the structured information of the graph .
② Model based on graph representation .Query Graph It's made up of triples , Go separately encode These triples , obtain encode vector , adopt Transformer Layer to do their interaction , Finally, they will be aggregation Get the representation of the candidate query graph . This method is better than serialization between .
In addition to these deep semantic words , Some relevant artificial features can also be incorporated to further improve the effect .

In addition to the method just introduced , Another category Query Parsing method is grammar based parsing . Support quick configuration , Support complex and new queries .
The grammar used is context free grammar (CFG), Semantic representation uses abstract semantic representation (AMR).
As shown in the figure, a simple process . For one Query, First, I will identify entities and attributes , Then label it , Then the syntax is parsed through the tag according to the configured syntax rules , for example CYK And so on , Get a formal representation . Next, we need to infer the related predicate , Some attribute relationships , Finally, an actual query is generated .
03
Document based Q & A

DocQA It refers to the use of search + Machine reading comprehension and other technologies , Extract answers to user questions from the open text library . There are several difficulties :
① The accuracy of the extracted answer fragments .
② Ability to read unanswered paragraphs . Many times the paragraph does not contain an answer , So try to avoid taking out some wrong answers from the paragraphs .
③ The relevance of the recalled paragraph to the problem . Only the relevance is guaranteed , The following model can extract the correct answer .
1. DocQA Overall process

① in the light of Query Log Filter the question and answer intention .
② Through the retrieval module to retrieve the corresponding paragraphs in the paragraph library .
③ For the retrieved TopK The paragraph , Make one Reader Model ( More paragraphs -MRC).
④ Reorder and reject the answers .
⑤ Output the final answer .
You can see that the most important parts in the whole process are the retrieval module and multi paragraph MRC modular .
2. DocQA- Semantic retrieval


For the retrieval module , Common problems are as follows :
① The sample of domain specific relevance annotation is limited , How to use limited annotations to further improve the generalization ability of the model .
② Inconsistency between training and prediction : Matching model in the training process , The general method is In Batch Negative The way , from Batch Others in Query The corresponding paragraph is used as this Query Negative example of , Because we use full database retrieval in the prediction process , The whole library may reach millions or tens of millions , This will lead to over recall when retrieving predictions , Recalled many wrong paragraphs , This method will cause inconsistency between training and prediction .
There are several optimization schemes for this problem :
① Use a lot of ( problem 、 The paragraph ) Q & A pairs select some high-quality ones through strategy and manual selection to construct pre training tasks , Equivalent to the BERT Based on the training model , Improve the effect of the model through two pre training . from Batch Internal selection Negative Change from Batch Choose from outside Negative, Generally, when training the matching model , If the mode of multi machine and multi card is adopted , You can take other cards Query The paragraph serves as the... Of the current card Query Negative example of , Every Query Negative case size of , It will start from batch_size Upgrade to gpu_num * batch_size, In this way, there will be more negative cases , The model will be more fully trained , It can greatly alleviate the inconsistency between training and prediction
② You can use a lot of < problem , answer >pair To generate far supervised training samples to enhance model training samples .< problem , answer > There are many ways to get to the source of , You can collect some question and answer pairs of open source data sets , perhaps KBQA This kind of question and answer to answer is right , With question and answer pairs, they can be introduced to generate remotely supervised samples .
The figure below shows the whole process : First, the current model will be used to compare the collected QA Right Q To recall TopK Paragraph of , If it's the first time , May adopt bm25 This unsupervised way to recall paragraphs . After recalling the paragraph, you can use QA Right A Go back to these paragraphs . Mark back to as a positive example , Those that are not marked back are regarded as negative examples . In this way, the far supervised samples and labeled samples can be combined to train the matching model , And then go on iterating . This iterative method can introduce more difficult negative examples , Let the model learn better .
3. DocQA- Answer extraction
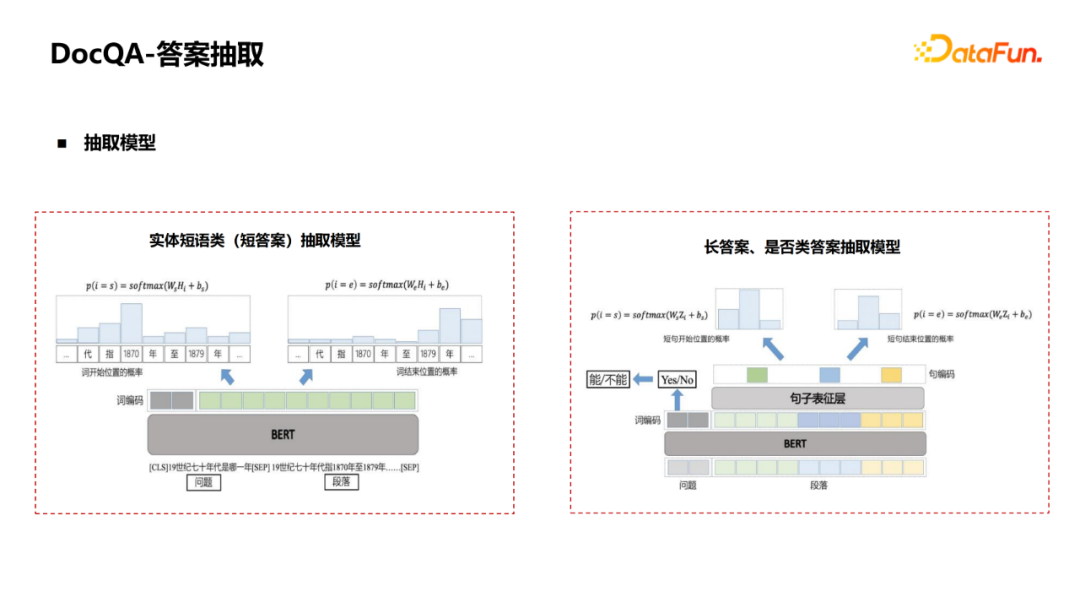
Next, we introduce answer extraction (MRC).
Generally, for entity phrase class ( Short answer ) extract , Will put questions and paragraphs together , Use one BERT To predict the beginning and end of a segment . But this method can not be well applied to the extraction of long answer and whether or not answer , At this time, it is necessary to modify the model . For example, add a classification chart , Judge whether the answer is yes “ yes ” still “ no ”; For the long answer class , Aggregate sentences , from token Level aggregate into sentence representation , After the sentence level representation , You can predict the beginning and end of the sentence level .

For the answer extraction module , The first question is MRC The cost of sample labeling is high , It is difficult to obtain large-scale annotation samples in the field . Generally, the pre training language model is used (BERT)+Finetune The way , The pre training model is used for reference BERT Have learned some knowledge well , It can greatly improve the model effect . but MLM and MRC Tasks vary greatly ,MLM The main task is mask some token, Use the sentence context to predict these token, Mainly learn the morphology between words 、 Grammar and other language model features .MRC Is to give a question and related paragraphs , Find the answer to the question in the paragraph , Mainly learn to understand problems and paragraphs .
So for this question , A better solution is to build one that is consistent with MRC Task approaching pre training tasks . One of the ways in last year's paper was to use segment selection Mask+ Retrieve to construct something like MRC Pre training samples for .
The specific process is shown in the figure : First, you need to have a text library , Choose some sentences to do entity recognition , Then randomly mask Drop the entity , Use wildcards instead of . This sentence can be regarded as a Query, Go to the paragraph library to retrieve TopK Paragraph of , After policy filtering , These paragraphs can be regarded as SSPT A sample of , The shape of this sample and MRC The shape of the sample is relatively similar .

The second question is :SSPT How to deal with the noise contained in the constructed samples ? One solution is to add a question and answer context prediction task . We can determine whether the noise sample is by modeling the semantic correlation between the words around the answer and the question . For a noise sample , The words around the answer have nothing to do with the question , We hope that the loss of Q & a context prediction task is large , For normal samples , The words around the answer item are related to the question , The loss of Q & a context prediction task is small .
There are three steps to do this :
① Define... For each word in the context label, Use some words in the context of a paragraph as its Related words , Let's assume that the words closer to the answer , The more likely it is to become a related word . therefore , Heuristics define the probability that each word in a paragraph belongs to the context label, The closer you get to the answer, the higher the probability , The farther away, the lower the probability , Decays exponentially .
② Estimate the probability that each word belongs to the context . use BERT And an extra matrix to calculate the start and end , For each word, its interval will be accumulated , To figure out the probability that the word belongs to the context .
③ At last, we get the label And probability , We can calculate the loss of context of the prediction task through the algorithm of cross entropy , Finally, our loss function is answer The loss of extraction plus the loss of this task .
It is hoped that the sample loss for this kind of noise is too large , The loss of normal samples is smaller . Finally, after defining the overall loss , You can use co-teaching Denoising algorithm to train the model , The greater the sample loss , The lower the weight , To achieve the purpose of sample denoising .

The third problem is that paragraph independent training leads to poor effect of multi paragraph extraction . The figure shows the multi paragraph extraction process , Each paragraph will be extracted with an answer , Will choose the final answer according to the score .
However, each paragraph is trained independently during training , Scores are not comparable between different paragraphs . The solution to this problem is to unify the paragraphs , For each paragraph , adopt encoder After getting the vector , Splice vectors , Make a big picture softmax To do the overall loss . The advantage of this is , The final score is comparable even across paragraphs .

Another common problem : The beginning and end of the forecast will generally be 0/1 label , It is impossible to distinguish between good and bad wrong candidate answers . The corresponding solution is to label soft turn , By calculating the word coincidence rate between the candidate answer and the standard answer, we can calculate the distribution of the advantages and disadvantages of different candidate answers . Put the whole answer span The pros and cons are transformed into the probability distributions of the start and end tags . First, calculate the merit matrix of all candidate answers , Transform it into a probability distribution , Then get each answer and start / The probability distribution of the end position . It will be the same 0/1 Of hard Express , Into a kind of soft Express .
04
Future outlook

① Analysis of complex problems . In addition to the ones just listed , In fact, there are many complicated questions that users often ask , For example, multiple intentions 、 Multi condition problem . For these Query It is difficult to analyze and solve well , Need stronger query graph Expression and higher resolution algorithm .
② Improve MRC The stability of the model . When the question is asked in a different way , Or there are entities with the same answer type in the paragraph and the context is similar to the question , It is easy to cause model extraction errors . This is also a hot topic in academic research , There are also many achievements , For example, add some confrontation samples or confrontation sentences . This is also an important work in the future .
③ Short answer extraction of entity classes with conditions and across fragments . Most of the time, a question is a short answer question of entity phrase , But it may be conditional in the paragraph , Under different conditions , The answer to short entities may be different . therefore , Not only do you have to draw out long sentences , It is more accurate to extract these conditions and their corresponding answers .
05
Q&A
Q1:KBQA Based on Seed - based triples in the , Is it necessary to maintain a table of standard questions and similar questions ?
A1: Unwanted , We will select some triples for the attribute , Go and mark back some questions and answers , For those questions on the backscript , It is suspected to ask this attribute . Do some De-noising for these problems , Add manual strategy or manual audit , Finally, get clean training data for each attribute , Maintenance of similar tables is not involved . Just introduced a method , Get some pattern after , Through the synonymous model Query log Some extended questions are matched in , These questions are then handled by strategy , Finally, we get some more questions about this relationship .
Q2:KBQA In the relationship identification of, after identifying the relationship , How to distinguish whether the identified entity is a subject or an object ?
A2: Generally, a single model will be used in the process of identification , The question is known SP have to O Or according to PO have to S.
Q3: In relation recognition , How to select negative samples ? How to deal with attributes that are literally similar but have different meanings ?
A3: It would be simpler if negative examples were randomly selected , The general method is to introduce manual annotation , For example, extend the question , Synonym matching is a way to get samples . When marking, they will naturally look very similar , But in fact, the wrong question is marked out , In a way similar to active learning , Keep adding some difficult negative samples , To improve the accuracy of identifying difficult negative samples .
Communicate together
I want to learn and progress with you !『NewBeeNLP』 At present, many communication groups in different directions have been established ( machine learning / Deep learning / natural language processing / Search recommendations / Figure network / Interview communication / etc. ), Quota co., LTD. , Quickly add the wechat below to join the discussion and exchange !( Pay attention to it o want Notes Can pass )

边栏推荐
- golang 重要知识:waitgroup 解析
- 操作系统底层知识总结(面试)
- MySQL高级语句二
- How is it safe to open an account for futures? Which futures company has a relatively low handling fee for futures and is suitable for retail investors to open an account?
- 32. compose beautiful touch animation
- golang 重要知识:sync.Once 讲解
- MySQL advanced statement I
- Explain in detail the principle and implementation of redis distributed lock
- After nine years at the helm, the founding CEO of Allen Institute retired with honor! He predicted that Chinese AI would lead the world
- How can genetic testing help patients fight disease?
猜你喜欢

Diffraction of light

变压器只能转换交流电,那直流电怎么转换呢?

Raspberry PI installing the wiring pi

Millions of bonuses are waiting for you to get. The first China Yuan universe innovation and application competition is in hot Recruitment!

volatile~多线程下变量不可见

这届文娱人,将副业做成了主业

Important knowledge of golang: sync Cond mechanism

Moher College - manual SQL injection vulnerability test (MySQL database)

The "shoulder" of sales and service in the heavy truck industry, Linyi Guangshun deep ploughing product life cycle service
重卡界销售和服务的“扛把子”,临沂广顺深耕产品全生命周期服务
随机推荐
RF Analyzer Demo搭建
golang 重要知识:定时器 timer
Important knowledge of golang: mutex
[pyside2] pyside2 window is on the top of Maya (note)
golang 重要知识:atomic 原子操作
Une compréhension simple du tri rapide
快速排序的简单理解
Moher College - manual SQL injection vulnerability test (MySQL database)
Arrays in JS
MySQL series: storage engine
Starting from 3, add paging function in the business system
A transformer can only convert alternating current. How can I convert direct current?
电子学会图形化一级编程题解析:猫捉老鼠
js的slice()和splice()
重卡界销售和服务的“扛把子”,临沂广顺深耕产品全生命周期服务
Force deduction solution summary 513- find the value of the lower left corner of the tree
Sfod: passive domain adaptation and upgrade optimization, making the detection model easier to adapt to new data (attached with paper Download)
golang 重要知识:sync.Cond 机制
volatile~多线程下变量不可见
Simple tutorial of live streaming with OBS