当前位置:网站首页>scrapy+scrapyd+gerapy 爬虫调度框架
scrapy+scrapyd+gerapy 爬虫调度框架
2022-06-25 10:45:00 【阿J~】
文章目录
一、scrapy
1.1 概述
Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试.
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 后台也应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫.
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持.
1.2 构成
Scrapy框架主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。下面我们分别介绍各个组件的作用。
(1)、调度器(Scheduler):
调度器,说白了把它假设成为一个URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是 什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。
(2)、下载器(Downloader):
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy的下载器代码不会太复杂,但效率高,主要的原因是Scrapy下载器是建立在twisted这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。
(3)、 爬虫(Spider):
爬虫,是用户最关心的部份。用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。 用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。
(4)、 实体管道(Item Pipeline):
实体管道,用于处理爬虫(spider)提取的实体。主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
(5)、Scrapy引擎(Scrapy Engine):
Scrapy引擎是整个框架的核心.它用来控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。
1.3 安装和使用
安装
pip install scrapy(或pip3 install scrapy)
使用
创建新项目:scrapy startproject 项目名
创建新爬虫:scrapy genspider 爬虫名 域名
启动爬虫: scrapy crawl 爬虫名
二、scrapyd
2.1 简介
scrapyd是一个用于部署和运行scrapy爬虫的程序,它允许你通过JSON API来部署爬虫项目和控制爬虫运行,scrapyd是一个守护进程,监听爬虫的运行和请求,然后启动进程来执行它们
2.2 安装和使用
安装
pip install scrapyd(或pip3 install scrapyd)
pip install scrapyd-client(或pip3 install scrapyd-client)
文件配置
vim /usr/local/python3/lib/python3.7/site-packages/scrapyd/default_scrapyd.conf

启动
scrapyd

访问 ip:6800,出现此页面则启动成功
三、gerapy
3.1 简介
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 方便地控制爬虫运行
- 直观地查看爬虫状态
- 实时地查看爬取结果
- 简单地实现项目部署
- 统一地实现主机管理
- 轻松地编写爬虫代码
3.2 安装使用
安装
pip install gerapy(或pip3 install gerapy)

安装完后先建立软链接
ln -s /usr/local/python3/bin/gerapy /usr/bin/gerapy
初始化
gerapy init

初始化数据库
cd gerapy
gerapy migrate
报错sqllite 版本过低
解决办法:升级sqllite
下载
wget https://www.sqlite.org/2019/sqlite-autoconf-3300000.tar.gz --no-check-certificate
tar -zxvf sqlite-autoconf-3300000.tar.gz
安装
mkdir /opt/sqlite
cd sqlite-autoconf-3300000
./configure --prefix=/opt/sqlite
make && make install
建立软连接
mv /usr/bin/sqlite3 /usr/bin/sqlite3_old
ln -s /opt/sqlite/bin/sqlite3 /usr/bin/sqlite3
echo “/usr/local/lib” > /etc/ld.so.conf.d/sqlite3.conf
ldconfig
vim ~/.bashrc 添加 export LD_LIBRARY_PATH=“/usr/local/lib”
source ~/.bashrc
查看当前sqlite3的版本
sqlite3 --version

重新初始化gerapy 数据库

配置账密
gerapy createsuperuser
启动gerapy
gerapy runserver
gerapy runserver 0.0.0.0:9000 # 外部访问 9000端口启动

由于没有启动scrapy 这里的主机未0

启动scrapyd后,配置scrapyd的主机信息
配置成功后就会加入到主机列表里
四、scrapy+scrapyd+gerapy的结合使用
4.1 创建scrapy项目
进到gerapy的项目目录
cd ~/gerapy/projects/
然后新建一个scrapy项目
scrapy startproject gerapy_test
scrapy genspider baidu_test www.baidu.com
修改scrapy.cfg 如下

在使用scrapyd-deploy 上传到scrapyd,先建立软连接再上传
ln -s /usr/local/python3/bin/scrapyd-deploy /usr/bin/scrapyd-deploy
scrapyd-deploy app -p gerapy_test

4.2 部署打包scrapy项目
然后再gerapy页面上可以看到我们新建的项目,再打包一下




运行之前还需修改下scrapy代码

修改完后再运行代码
4.3 运行
运行成功,本次的部署就ok了!

五、填坑
5.1 运行scrapy爬虫报错

解决办法:修改lzma源代码如下
try:
from _lzma import *
from _lzma import _encode_filter_properties, _decode_filter_properties
except ImportError:
from backports.lzma import *
from backports.lzma import _encode_filter_properties, _decode_filter_properties

5.2 scrapyd 运行 scrapy 报错
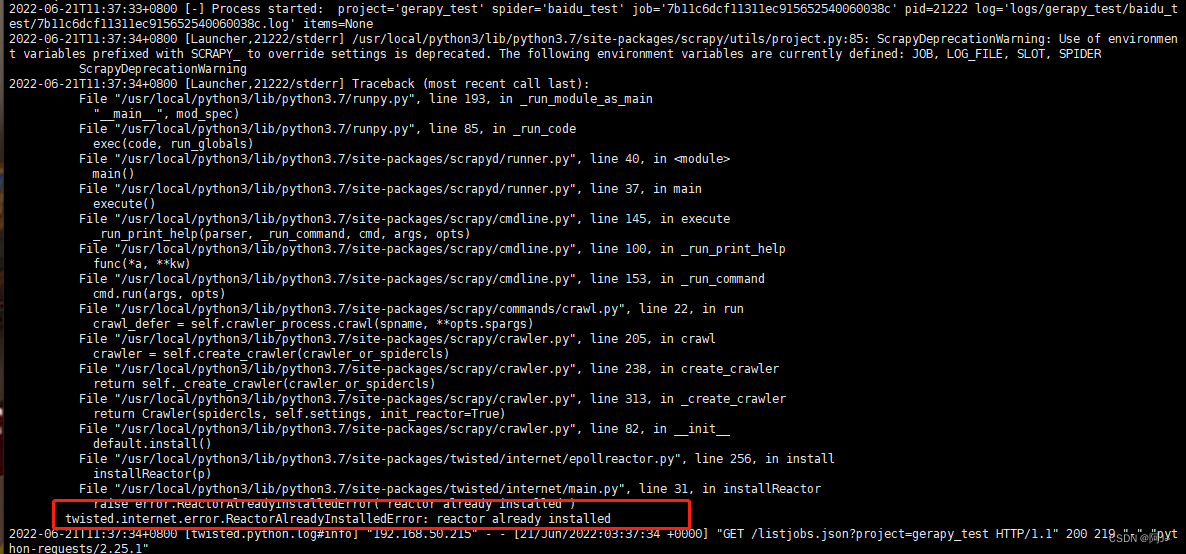
解决办法:降低scrapy版本 pip3 install scrapy==2.5.1
边栏推荐
- 看完这篇 教你玩转渗透测试靶机Vulnhub——DriftingBlues-7
- Tutorial on installing SSL certificates in Microsoft Exchange Server 2007
- 视频会议一体机的技术实践和发展趋势
- 西门子PLCS7-200使用(一)---开发环境和组态软件入门
- The title of my composition is - "my district head father"
- 好好思考
- 垃圾回收机制
- 【观察】ObjectScale:重新定义下一代对象存储,戴尔科技的重构与创新
- CDN+COS搭建图床超详细步骤
- Daily Mathematics Series 52: February 20
猜你喜欢

FPGA displays characters and pictures based on VGA

TASK03|概率论
![[paper reading | deep reading] drne:deep recursive network embedding with regular equivalence](/img/48/4e8d367b49f04a2a71a2c97019501f.png)
[paper reading | deep reading] drne:deep recursive network embedding with regular equivalence

之前字符串反转的题目

软件测试 避免“试用期被辞退“指南,看这一篇就够了

報名開啟|飛槳黑客馬拉松第三期如約而至,久等啦

【论文阅读|深读】LINE: Large-scale Information Network Embedding

西门子PLCS7-200使用(一)---开发环境和组态软件入门

Network remote access using raspberry pie

NuxtJS实战案例
随机推荐
CSRF攻击
无心剑中译伊玛·拉扎罗斯《新巨人·自由女神》
Application of global route guard
学会自学【学会学习本身,比学什么都重要】
WPF binding expression and binding data source (I)
A five-year technical Er, based on the real experience of these years, gives some suggestions to the fresh students
[paper reading | deep reading] line: large scale information network embedding
Remove the problem of orange border on the desktop control in WebView
看完这篇 教你玩转渗透测试靶机Vulnhub——DriftingBlues-7
Binder explanation of Android interview notes
撸一个随机数生成器
Output reading: apply what you have learned
WPF prism framework
Performance memory
Google Earth Engine (Gee) - evaluate réalise le téléchargement en un clic de toutes les images individuelles dans la zone d'étude (certaines parties de Shanghai)
【图像融合】基于形态学分析结合稀疏表征实现图像融合附matlab代码
16 种企业架构策略
一个五年北漂的技术er,根据这些年的真实经历,给应届生的一些建议
Detailed explanation of Android interview notes handler
Shen Lu, China Communications Institute: police open source Protocol - ofl v1.1 Introduction and Compliance Analysis