当前位置:网站首页>Semantic segmentation cvpr2020 unsupervised intra domain adaptation for semantic segmentation through self supervision
Semantic segmentation cvpr2020 unsupervised intra domain adaptation for semantic segmentation through self supervision
2022-06-25 05:26:00 【HheeFish】
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision: Self supervised adaptive semantic segmentation in unsupervised domain
Paper download
Open source code
0. Abstract
The semantic segmentation method based on convolutional neural network has made remarkable progress . However , These methods rely heavily on annotated data , It's labor-intensive . To overcome this limitation , The automatic annotation data generated from the graphics engine is used to train the segmentation model . However , Models trained from synthetic data are difficult to transform into real images . To solve this problem , Previous work considered directly adjusting the model from source data to unmarked target data ( To reduce the gap between domains ). For all that , These techniques do not take into account the large distribution gap between the target data itself ( Intra domain gap ). In this study , We propose a two-step self supervised domain adaptive method to minimize the gap between domains and within domains . First , We adapt the model between domains ; From this adaptation , We use the entropy based sorting function to segment the target domain into simple and difficult segments . Last , To reduce the intra domain gap , We propose a self supervised adaptive technique , From easy segmentation to difficult segmentation . The experimental results on a large number of benchmark data sets highlight the effectiveness of our method compared with the existing advanced methods .
1. summary
The purpose of semantic segmentation is to assign each pixel in an image to a semantic class . In recent years , Segmentation model based on convolutional neural network [14,34] Remarkable progress has been made , It has been applied in computer vision system , Such as autonomous driving [15,32,13]、 robot [16,24]、 Disease diagnosis [36,33]. Training such a segmented network requires a large amount of annotation data . However , It is difficult to use pixel level annotation to collect large-scale data sets for semantic segmentation , Because they are expensive and labor-intensive . lately , Realistic data with precise pixel level semantic annotation from simulators and game engines are used to train segmentation networks . However , because [11] Cross domain differences , Models trained from synthetic data are difficult to transform into real data . To solve this problem , Put forward Unsupervised domain adaptation (unsupervised domain adaptive, UDA) Technology to align the distribution offset between labeled source data and unlabeled target data . For specific semantic segmentation tasks , Based on confrontation learning UDA Method in the image [17,11] Or output [27,26] Horizontal display of efficient feature alignment . lately , from [29] The proposed pixel level output prediction entropy is also used for output level alignment . Other methods [39,38] Including generating pseudo tags for target data , And refine it through the iterative self-training process . Although many models consider a single source - Single objective adaptation settings , But recent research [19,35] The problem of solving multi-source domain is proposed ; This paper focuses on the multi-source single target adaptive environment . most important of all , Previous work mainly considered Adjust the model from the source data to the target data ( Inter domain gap ).
chart 1: We propose a two-step self supervised domain adaptation technique for semantic segmentation . The previous work only adjusted the segmentation model from the source domain to the target domain . Our work also considers the adaptation from the clean map to the noise map in the target domain .
However , The target data collected from the real world has different scene distributions ; These distributions are caused by various factors , For example, moving objects 、 Weather conditions , These factors lead to large gaps in the target ( Intra domain gap ). for example , chart 1 The noise map and the clean map in the target domain shown are predictions of different images by the same model . Although previous studies only focused on reducing the gap between domains , However, the problem of intra domain gap has not attracted enough attention .
In this paper , We put forward a kind of A two-step domain adaptive method is used to minimize the inter domain and intra domain gaps . Our model consists of In the third part of form , Pictured 2 Shown , namely :
chart 2: A self supervised domain adaptive model is proposed
- Inter domain adaptive module , Used to narrow the inter domain gap between tagged source data and unlabeled target data ;
- Entropy based ranking system , Used to divide the target data into simple and difficult parts
- Intra domain adaptation module , Used to close the intra domain gap between easy stripping and hard stripping ( Use pseudo tags from easy subdomains ).
In terms of semantic segmentation , The proposed method achieves good performance on benchmark data sets . Besides , In terms of digital classification , Our method is superior to the previous domain adaptive method
The contribution of our work : - First , Introduce inter domain differences in the target data , A sort function based on entropy is proposed , Divide the target domain into simple and difficult sub domains ;
- secondly , We propose a two-step self supervised domain adaptation method to minimize the gap between domains and within domains
2. Related work
2.1. Unsupervised fields adapt to
The goal of unsupervised domain adaptation is Align the distribution offset between the marked source data and the unlabeled target data . lately , Based on confrontation UDA The method shows great ability in learning the unchanging characteristics of the domain , Even for complex tasks , Such as semantic segmentation [29,4,27,26,22,11,18]. Based on antagonism UDA The semantic segmentation model usually contains two networks . One of the networks acts as a generator to predict the segmentation map of the input image , It can be a source image or a target image . Given the characteristics from the generator , The second network acts as a discriminator to predict domain labels . The generator tried to trick the discriminator , So that the feature distribution of the two domains can be offset and aligned . In addition to feature level alignment , Other methods try to align the field movement at the image level or the output level . On the image level ,[11] use CycleGAN[37] Build the generated image for field alignment . At the output level ,[26] An end-to-end model is proposed , The model involves the structure output alignment of distributed offset . lately ,[29] The pixel prediction entropy of the segmented output is used to solve the domain gap . Although all previous studies have specifically considered the gap between homogeneous domains , But our method further minimizes the gap in the domain . therefore , Our technology can be compared with most existing UDA Combination of methods , To get additional performance benefits .
2.2. Calculate the uncertainty by entropy
There is a strong connection between uncertainty measurement and unsupervised domain adaptation . for example ,[29] It is proposed to directly minimize the target entropy of the model output or to use confrontation learning [26,11] To narrow the gap in semantic segmentation . Besides , Model output [30] The entropy of is used to transport samples across domains [25] Confidence measure of . We propose to use entropy to sort the target images , The target image is divided into two types , The separation of easy and difficult .
2.3. Curriculum based domain adaptation
Our work also involves adaptation to the curriculum field [23,32,7], This first deals with simple samples . Course domain adaptation for fog scene understanding ,[23] In this paper, a semantic segmentation model of non fog image is applied to synthetic light fog image , And then applied to the real heavy fog image . In order to popularize this concept ,[7] By introducing an unmarked intermediate domain , Decompose domain differences into smaller ones . However , These technologies Additional information is required to decompose the domain . To overcome this limitation ,[32] Learning the global and local label distribution of the image is the primary task of regularization model prediction in the target domain . On the contrary , We put forward a kind of A simpler data-driven method based on entropy sorting system To learn easy target samples .
3. Method

Figure 2 : The proposed self supervised domain adaptive model consists of an inter domain generator and a discriminator {Ginter, Dinter}, In domain generators and discriminators {Gintra, Dintra}. The model consists of three parts , namely (a) Inter domain adaptation ,(b) Entropy based ranking system , Intra domain adaptation . stay (a) in , Given source and unlabeled target data , Training Dinter Predict the domain name label of the sample , Training Ginter to fool Dinter.{Ginter, Dinter} By minimizing segmentation losses Lseg inter And confrontational losses Ladvinter To optimize . stay (b) in , Use an entropy based function R(It) Divide all target data into easy segmentation and difficult segmentation . Hyperparameters λ Is introduced as a ratio assigned to a target image that is easy to segment . In the middle , Use intra domain adaptation to narrow the gap between easy splitting and difficult splitting .Ginter The segmentation prediction of the easily segmented data in can be used as a pseudo label . For the easily segmented data and hard segmented data with pseudo labels ,Dintra It is used to predict whether the sample is easy to segment or hard to segment , and Gintra Is trained to confuse Dintra.{Gintra and Dintra} Use intra domain partition loss Lseg intra And counter losses Ladvintra To optimize
set up S Represents a set of images ∈RH×W×3 And related ground-truth C Class partition graph ∈(1,C)H×W The source domain ; Again , Give Way T Indicates that it contains a set of unlabeled images ⊂RH×W×3 Target domain for . In this section , We will introduce a two-step self supervised domain adaptive semantic segmentation method .
- The first step is inter domain adaptation , This is based on the common UDA Method [29,26]. then , Generate pseudo tags and predictive entropy maps for target data , So as to achieve the clustering of the target data , Divided into easy and difficult . say concretely , An entropy based ranking system is used to cluster the target data into easy and difficult segmentation .
- The second step is intra domain adaptation , This includes aligning easy and difficult segmentation using pseudo tags , Pictured 2 Shown . The network consists of an inter domain generator and an identifier {Ginter, Dinter} And domain generators and identifiers {Gintra, Dintra} form .
3.1. Inter domain adaptation
sample Xs∈RH×W×3 From the source domain and its associated mapping Ys.Y Every object of Ys(h,w) =[Ys(h,w,c)]c Provides a pixel (h,w) As a unique hot code vector . The Internet Ginter With Xs For input , Generate “ Soft segmentation graph ”Ps = Ginter(Xs). Pixels (h,w) At every C Dimension vector [P(h,w,c)]c As c Discrete distributions on classes . Given Xs And its ground-truth Mark Ys, Ginter By minimizing cross entropy loss , Optimize in a supervised way :
To narrow the inter domain gap between the source domain and the target domain ,[29] Entropy mapping is proposed to align the distribution shift of features .[29] The assumption of , Trained models tend to be overconfident in the class source images ( Low entropy ) The forecast , Low confidence in class target images ( high-entropy ) The forecast . because [29] The simplicity and effectiveness of , We have adopted it in our work for cross domain adaptation . generator Ginter Take the target image Xt For input , Generate split mapping Pt= Ginter(Xt); Entropy characteristic graph It The expression of is :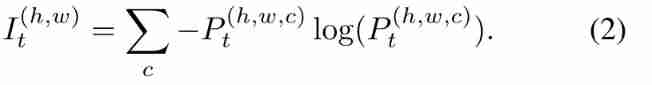
To align the clearance between domains , Training Dinter Predict the domain label of entropy graph , Training Ginter to fool Dinter;Ginter and Dinter Through the following loss Function implementation :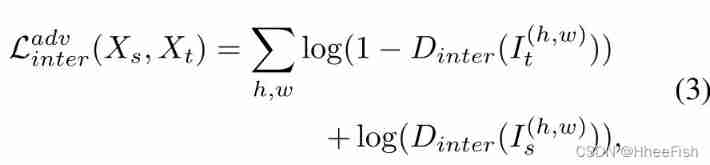
I: Entropy characteristic graph ;Dinter : Interdomain identifier
For the loss function Ladvinter and Lseginter To optimize , Make the distribution offset between source data and target data consistent . However , There is still a need for an effective method to minimize the gap within the domain . So , We suggest Divide the target domain into easy and difficult parts , And perform intra domain adaptation .
3.2. Entropy based ranking
Due to different weather conditions 、 Moving objects and shadows , The target images collected from the real world have different distributions . In the figure 2 in , Some target prediction charts are clean , Others are very noisy , Although they are generated from the same model . Because there is an intra domain gap between the target images , A simple solution is Decompose the target domain into small sub domains or small partition blocks . However , Due to the lack of target tags , This is still a challenging task . To build these partitions , We use entropy graph to determine the confidence level of target prediction . generator Ginter Take the target image Xt For input , Generate Pt And entropy graph It. On this basis , We adopt a simple and effective sorting method :
Entropy mapping It Of mean value . according to R(Xt) The score order of , Super parameter is introduced λ As a ratio , Divide the target image into easy and difficult parts . set up Xte and Xth Respectively represent the target images assigned to easy segmentation and difficult segmentation . For domain separation , We define λ = |Xte|/|Xt|, among |Xte| Is a cardinal number that can be easily divided ,|Xt| Is the cardinality of the entire target image set . In order to obtain λ Influence , We are on the table 2 How to optimize λ the Melting research . Be careful , We do not introduce a super parameter as the separation threshold , because The threshold depends on a particular data set . We chose a ratio superparameter , This has a strong generalization ability for other data sets
3.3. Intra domain adaptation
Because it is easy to split, it is not marked , It is not feasible to directly align the gap between easy segmentation and difficult segmentation . But we suggest using Ginter As Pseudo label . Given a set of images from which it is easy to segment Xte Image , We will Xte Forward to Ginter, Get a prediction chart Pte = Ginter(Xte). although Pte It's a “ Soft segmentation graph ”, But we will Pte Convert to in Pte , Each entry is a unique hot code vector . With the help of pseudo tags , Optimize by minimizing cross entropy loss Gintra:
In order to make up for the gap between easy segmentation and difficult segmentation Intra domain gap , We use the alignment method on entropy mapping for both segmentation . Take the image in the image set that is difficult to segment Xth As input to the generator G, Generate a split graph Pth= G(Xth) And entropy graph Ith. In order to narrow the gap within the domain , Training domain discriminator Dintra To predict the Ite and Ith Split label for :Ite From easy segmentation ,Ith From hard to separate .G Trained to fool Dintra. Optimize Gintra and Dintra The formula of antagonistic learning loss is 
Last , Our complete loss function L It consists of all the following loss functions :
Our goal is to learn the goal model G, according to :
Because our model is a two-step self-monitoring method , So it's hard to minimize in a training phase L. therefore , We chose to minimize it in three stages . First , We train the inter domain adaptability of the model to optimize Ginter and Dinter. secondly , utilize Ginter Generate target pseudo tags , And based on S(Xt) Sort all target images . Last , We train in domain adaptive optimization Gintra and Dintra.
4. experiment
In this section , We introduce the experimental details of inter domain adaptation and intra domain adaptation of semantic segmentation .
4.1. Data sets
In the experiment of semantic segmentation , We have adopted an adaptive setting from synthesis to real domain . To perform this series of tests , Will include GTA5[20]、SYNTHIA[21] and Synscapes[31] Inside The composite dataset is used as the source domain , At the same time Real data sets cityscapes[6] Use as target domain . Given marked source data and unlabeled target data , Train the model . Our model is in cityscapes Evaluated on the validation set .
- GTA5: Composite datasets GTA5[20] contain 24,966 Zhang composite image , A resolution of 1,914×1,052, And corresponding ground-truth notes . These composite images were collected from a video game based on the urban landscape of Los Angeles . Automatically generated ground-truth The comment contains 33 Categories . For training , We only consider the relationship with cityscape Data sets [6] Compatible 19 Categories , This is similar to the previous work .
- SYNTHIA: SYNTHIA- rand - cityscape[21] As another composite data set . It contains 9,400 A completely annotated RGB Images . During training , We use cityscape Data sets consider 16 Common categories . In the process of evaluation , Use 16 and 13 A subset of classes to evaluate performance .
- Synscapes: Synscapes[31] Is a realistic composite dataset , from 25,000 A completely annotated RGB Image composition , A resolution of 1,440×720. Just like the urban landscape , The ground truth notes contain 19 Categories
- Cityscapes: Cityscapes[6] Is a data set collected from the real world , It provides 3975 Image with fine segmentation annotation .2975 This picture was taken from the urban landscape of the training set , Used for training . From the urban landscape evaluation set 500 Images were used to evaluate the performance of our model .
The evaluation index : Occurring simultaneously than IoU(intersection-over-union metric)
Implementation details :
stay GTA5→ Urban landscape and SYNTHIA→ In the experiment of urban landscape , We make use of AdvEnt[29] Frame pair Ginter and Dinter Perform inter domain adaptation training ;Ginter The backbone of ResNet-101 framework [10], The parameters come from ImageNet [8]; The input data is marked as a source image and an unmarked target image . Inter domain adaptation Ginter The model of has gone through 70000 Training in the next iteration . After training ,Ginter Used for all 2975 Zhang Ziyuan cityscape Image generation of training set Segmentation and entropy graph . then , utilize R(Xt) Sort all target images , And according to λ The target image is divided into easy segmentation and difficult segmentation . We are on the table 2 in Yes λ Ablation studies were conducted to optimize . For intra domain adaptation ,Gintra Have and Ginter The same architecture ,Dintra Have and Dinter The same architecture ; The input data is 2975 A training image of urban landscape with pseudo labels that are easy to segment .Gintra Yes, it is ImageNet and Dintra The pre training parameters of start training from zero , Be similar to AdvEnt. In addition to the experiments mentioned above , We also did synscape→cityscape The experiment of . In order to AdaptSegNet[26] Compare , We will AdaptSegNet The framework is applied to the experiments of inter domain adaptation and intra domain adaptation .
And [29] and [26] similar , We utilize conv4 and conv5 The multi-level feature output is used for inter domain adaptation and intra domain adaptation . For training Ginter and Gintra, We applied SGD Optimizer [2], Its learning rate is 2.5 × 10−4, Momentum is 0.9, Training Ginter and Gintra The weight attenuation of is 10−4. The learning rate is 10−4 Of Adam Optimizer [12] Used for training Dinter and Dintra.
4.2. result


surface 3:GTA5→ Cityscapes Self training and intra domain adaptation gain .
GTA5: In the table 1 (a) in , We compared our method with other most advanced methods [26,5,29] stay cityscapes Verify the split performance on the set . For a fair comparison , The baseline model uses data from DeepLabv2[3] Of ResNet-101 The backbone . in general , Our proposed method achieves 46.3% The average of IoU. And AdvEnt comparison , The intra domain adaptation of our method results in an average of IoU Improved 2.5%.
In order to highlight the relevance of the proposed intra domain adaptation , We are on the table 3 Medium split loss Lseg And against the loss of adaptation Ladvintra Made a comparison . The baseline AdvEnt[29] achieve mIoU Of 43.8%. By using AdvEnt + Intra domain adaptation , namely Lsegintra = 0, We got 45.1%, It shows that the antagonism learning is effective for intra domain alignment . By applying the AdvEnt + self-training, λ = 1.0( All for self-training Fake tags for ), namely Ladvintra = 0, We did mIoU Of 45.5%, This shows the importance of pseudo tags . Last , Our proposed model achieves 46.3% Of mIOU( Self training + Intra domain alignment ).
indeed , Complex scenes ( Contains many objects ) May be classified as “ difficult ”. To provide a more representative “ Sort ”, We use a new normalization method , Divide the average entropy by the number of predicted rare classes in the target image . For urban landscape datasets , We define these rare classes as “ wall 、 fence 、 Pole 、 traffic lights 、 traffic sign 、 terrain 、 Rider 、 truck 、 The bus 、 train 、 automobile ”. Entropy normalization helps to move an image with multiple objects to a location that is easy to segment . After normalization , Our proposed model achieves 47.0% Of mIoU, As shown in the table 3 Shown . Our method also has limitations for some classes .
chart 3:GTA5→Cityscapes Evaluation example results of .(a) and (d) For coming from cityscape Verify the image of the set and the corresponding ground-truth notes .(b) For inter domain adaptation [29] Prediction segmentation graph of . It's a prediction chart of our technology .
In the figure 3 in , We provide some visual segmentation mapping from our technology . adopt Inter domain comparison and intra domain comparison The model segmentation graph obtained by training , Compared with the baseline model that only performs inter domain comparison training AdvEnt More accurate . chart 4 A group belonging to “ hard ” Representative images of segmentation . After field alignment , We generate (d) Column . Compared to columns , Our model can be transferred to more difficult target images .
stay GTA5→Cityscapes In the experiment of , We're talking about hyperparameters λ The appropriate value of . In the table 2 in , Different δ Value is used to establish the decision boundary of domain separation . When λ = 0.67, namely |Xte| And |Xt| The ratio of is about 2/3 when , The model is in citylandscape The best performance on the verification set has reached 46.3 mIoU.
surface 2: Hyperparameters λ Ablation research in target domain segmentation .
SYNTHIA: We use SYNTHIA As the source domain , And on the table 1 The method of this paper and the most advanced method are given on the verification set of urban landscape [26,29] The results of the evaluation of . For comparison , We also use the same method as ResNet-101 The same architecture DeepLab-v2. Our approach is 16 Classes and 13 Class baseline . According to the table 1 (b) Result , The method we put forward is 16 Level and 13 ... were obtained on the level 1 baseline 41.7% and 48.9% The average of IoU. As shown in the table 1 Shown , Our model is more accurate than the existing technology in automobile and motorcycle . The reason is that we apply intra domain adaptation to further narrow the gap between domains 
Synscapes: We currently use Syncapes The only job of dataset discovery is [26]. therefore , We use AdaptSegNet[26] As a baseline model . To provide a fair comparison , We only consider using vanilla-GAN In our experiment . In the case of inter domain adaptation and intra domain adaptation , Our model achieves 54.2% Of mIoU, Above table 1 Shown AdaptSegNet.
4.3. Discuss
The theoretical analysis :
Comparison table 1 Medium (a)、(b),GTA5→cityscapes Than SYNTHIA→cityscape More effective . We think this is because compared with other synthetic data sets ,GTA5 Have more and cityscapes Similar street view images . This paper also makes a theoretical analysis . set up H Represents a hypothetical class ,S and T Is the source domain and the target domain . from [1] The expected error on the target definition domain is proposed theoretically T (h) The demarcation of the law :∀h∈h, T (h)≤εS(h) + 1/2 dH(S, T) +Λ, among ,εS(h) Define the expected error on the domain for the source ;dH(S, T) = 2sup|PrS(h)−PrT(h)|, Is the domain divergence distance ;Λ In general, it is considered a constant . therefore ,T (h) yes εS(h) and dH(S, T) The upper bound of . Our proposed model uses inter domain alignment and intra domain alignment to minimize dH(S, T). If dH(S, T) High value , The larger the upper bound of the first stage of inter domain adaptation , Affect our entropy ranking system , Influence the adaptation process within the domain . therefore , When there is a big gap in the field , Our model is inefficient . Because of its limitations , Our model performance is affected by dH(S, T) and εS(h) Influence . First , The greater the divergence between the source domain and the target domain ,dH(S, T) The bigger the value is. . Because the upper bound of the error is high , So the effectiveness of our model is low . secondly , When the model uses a smaller neural network ,εS(h) It will be very high . under these circumstances , Our model will also be less effective .
Digital classification :
The model is also applicable to digital classification tasks . We have considered MNIST→USPS、USPS→MNIST and SVHN→MNIST Adapt to change . Our model is trained using training sets :MNIST Yes 60000 Zhang image ,USPS Yes 7291 Zhang image , standard SVHN Yes 73257 Zhang image . The proposed model is evaluated on a standard test set :MNIST(10,000 Images ) and USPS(2,007 Images ). In the digital classification task ,Ginter and Gintra As a classifier with the same architecture , The architecture is based on LeNet A variant of the architecture . In terms of inter domain adaptation , We make use of CyCADA[11] Frame pair Ginter and Dinter Training . In the ranking stage , We make use of Ginter Generate forecasts for all target data , And use R(Xt) Calculate their ranking score . about λ, We used in all our experiments λ = 0.8. Our intra domain adaptation network is also based on CyCADA[11]. In the table 4 in , The model we proposed is in MNIST→USPS The accuracy rate of 95.8±0.1%, stay USPS→MNIST The accuracy rate of 97.8±0.1%, stay SVHN→MNIST The accuracy rate of 95.1±0.3%. Our model outperforms the baseline model CyCADA[11].
5. Conclusion
In this paper , We propose a self supervised domain adaptive method , To minimize both inter domain and intra domain gaps . We first use the existing inter domain adaptive training model . secondly , Generate the entropy map of the target image , The entropy based sorting function is used to segment the target region ; Last , We do intra domain adaptation , To further narrow the gap in the field . We have conducted extensive experiments on synthetic real images in traffic scenes . Our model can be combined with existing domain adaptation methods . Experimental results show that , The performance of this model is better than the existing adaptive algorithms .
6. The method part is a concise summary

reference
[1] Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation. In NeurIPS, pages 137–144, 2007. 7
[2] Léon Bottou. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010, pages 177–186. Springer, 2010. 6
[3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. PAMI, 40(4):834–848, 2017. 6
[4] Minghao Chen, Hongyang Xue, and Deng Cai. Domain adaptation for semantic segmentation with maximum squares loss. In ICCV, pages 2090–2099, 2019. 2
[5] Yuhua Chen, Wen Li, and Luc Van Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In CVPR, pages 7892–7901, 2018. 5, 6
[6] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 5
[7] Shuyang Dai, Kihyuk Sohn, Yi-Hsuan Tsai, Lawrence Carin, and Manmohan Chandraker. Adaptation across extreme variations using unlabeled domain bridges. arXiv preprint arXiv:1906.02238, 2019. 2
[8] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009. 6
[9] Mark Everingham, SM Ali Eslami, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. IJCV, 111(1):98–136, 2015. 5
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016. 6
[11] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. CyCADA: Cycle-consistent adversarial domain adaptation. In ICML, pages 1989–1998, 2018. 1, 2, 8
[12] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014. 6
[13] Seokju Lee, Junsik Kim, Tae-Hyun Oh, Yongseop Jeong, Donggeun Yoo, Stephen Lin, and In So Kweon. Visuomotor understanding for representation learning of driving scenes. In BMVC, 2019. 1
[14] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015. 1
[15] Pauline Luc, Natalia Neverova, Camille Couprie, Jakob Verbeek, and Yann LeCun. Predicting deeper into the future of semantic segmentation. In ICCV, pages 648–657, 2017. 1
[16] Andres Milioto, Philipp Lottes, and Cyrill Stachniss. Realtime semantic segmentation of crop and weed for precision agriculture robots leveraging background knowledge in cnns. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 2229–2235. IEEE, 2018. 1
[17] Zak Murez, Soheil Kolouri, David Kriegman, Ravi Ramamoorthi, and Kyungnam Kim. Image to image translation for domain adaptation. In CVPR, pages 4500–4509, 2018. 1
[18] Kwanyong Park, Sanghyun Woo, Dahun Kim, Donghyeon Cho, and In So Kweon. Preserving semantic and temporal consistency for unpaired video-to-video translation. In Proceedings of the 27th ACM International Conference on Multimedia, pages 1248–1257, 2019. 2
[19] Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. In ICCV, pages 1406–1415, 2019. 2
[20] Stephan R. Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, editors, ECCV, volume 9906 of LNCS, pages 102– 118. Springer International Publishing, 2016. 1, 5
[21] German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, pages 3234–3243, 2016. 1, 5
[22] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In CVPR, pages 3723–3732, 2018. 2
[23] Christos Sakaridis, Dengxin Dai, Simon Hecker, and Luc Van Gool. Model adaptation with synthetic and real data for semantic dense foggy scene understanding. In ECCV, pages 687–704, 2018. 2
[24] Alexey A Shvets, Alexander Rakhlin, Alexandr A Kalinin, and Vladimir I Iglovikov. Automatic instrument segmentation in robot-assisted surgery using deep learning. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 624–628. IEEE, 2018. 1
[25] Jong-Chyi Su, Yi-Hsuan Tsai, Kihyuk Sohn, Buyu Liu, Subhransu Maji, and Manmohan Chandraker. Active adversarial domain adaptation. In WACV, pages 739–748, 2020. 2
[26] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, pages 7472–7481, 2018. 1, 2, 3, 5, 6, 7
[27] Yi-Hsuan Tsai, Kihyuk Sohn, Samuel Schulter, and Manmohan Chandraker. Domain adaptation for structured output via discriminative patch representations. In ICCV, pages 1456– 1465, 2019. 1, 2
[28] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, pages 7167–7176, 2017. 8
[29] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In CVPR, pages 2517–2526, 2019. 2, 3, 5, 6, 7, 8
[30] Keze Wang, Dongyu Zhang, Ya Li, Ruimao Zhang, and Liang Lin. Cost-effective active learning for deep image classification. IEEE Transactions on Circuits and Systems for Video Technology, 27(12):2591–2600, 2016. 2
[31] Magnus Wrenninge and Jonas Unger. Synscapes: A photorealistic synthetic dataset for street scene parsing. arXiv preprint arXiv:1810.08705, 2018. 5
[32] Yang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, page 6, Oct 2017. 1, 2
[33] Amy Zhao, Guha Balakrishnan, Fredo Durand, John V Guttag, and Adrian V Dalca. Data augmentation using learned transformations for one-shot medical image segmentation. In CVPR, pages 8543–8553, 2019. 1
[34] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In CVPR, 2017. 1
[35] Han Zhao, Shanghang Zhang, Guanhang Wu, José MF Moura, Joao P Costeira, and Geoffrey J Gordon. Adversarial multiple source domain adaptation. In NIPS, pages 8559– 8570, 2018. 2
[36] Yi Zhou, Xiaodong He, Lei Huang, Li Liu, Fan Zhu, Shanshan Cui, and Ling Shao. Collaborative learning of semisupervised segmentation and classification for medical images. In CVPR, pages 2079–2088, 2019. 1
[37] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In ICCV, 2017. 2
[38] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In ECCV, pages 289–305, 2018. 2
[39] Yang Zou, Zhiding Yu, Xiaofeng Liu, B.V.K. Vijaya Kumar, and Jinsong Wang. Confidence regularized self-training. In ICCV, October 2019. 2
边栏推荐
- Handwritten promise all
- Dynamic programming Backpack - 01 Backpack
- XSS (cross site script attack) summary (II)
- Vue uses keep alive to cache page optimization projects
- Deep analysis of recursion in quick sorting
- C language -- Sanzi chess
- Array and simple function encapsulation cases
- A summary of the experiment of continue and break in C language
- Svg code snippet of loading animation
- Japanese fifty tone diagram
猜你喜欢

Eyeshot 2022 Released
![Bind simulation, key points of interpreting bind handwritten code [details]](/img/03/6aa300bb8b8342199aed5a819f3634.jpg)
Bind simulation, key points of interpreting bind handwritten code [details]

A review of small sample learning

Go deep into the working principle of browser and JS engine (V8 engine as an example)

Detailed summary of float

Flex flexible layout for mobile terminal page production
渗透测试-提权专题

Dynamic programming example 2 leetcode62 unique paths

Uva1103 ancient pictograph recognition

3.2.3 use tcpdump to observe TCP header information (supplement common knowledge of TCP protocol)
随机推荐
Baidu ueeditor set toolbar initial value
A review of small sample learning
H5 native player [learn video]
Using JS to realize the sidebar of life information network
Two dimensional array and function call cases of C language
Detailed summary of float
Mysql interactive_ Timeout and wait_ Timeout differences
Creation and use of MySQL index
The k-th node of the binary search tree [sword finger offer]
JS function to realize simple calculator
Bind simulation, key points of interpreting bind handwritten code [details]
Charles and iPhone capture
2022.1.23 diary
[keil] GPIO output macro definition of aducm4050 official library
For in JS Of and for in
2.20 learning content
Makefile Foundation
Handwritten promise all
How micro engine uploads remote attachments
Attack and defense world web baby Web