当前位置:网站首页>Prediction of advertising investment and sales based on regression analysis -- K neighborhood, decision tree, random forest, linear regression, ridge regression
Prediction of advertising investment and sales based on regression analysis -- K neighborhood, decision tree, random forest, linear regression, ridge regression
2022-07-24 06:54:00 【I'm a college scum】
Prediction of advertising investment sales based on regression analysis ——K near , Decision tree , Random forests , Linear regression , Ridge return
List of articles
- Prediction of advertising investment sales based on regression analysis ——K near , Decision tree , Random forests , Linear regression , Ridge return
- 1. Project background
- 2. Project brief introduction
- 3. Algorithm principle
- 4. Analysis steps
- 5. Summary of the experiment
1. Project background
- With the quickening pace of people's life , Advertising plays an increasingly important role in commodity sales , Each company has attached great importance to the advertising investment mode of its own products , So as to maximize the role of advertising , To maximize revenue . The role of accurate advertising has the following aspects .
1、 Advertising is the biggest 、 The fastest 、 The most extensive information transmission medium . by advertising , Enterprises or companies can combine the characteristics of products and services 、 function 、 Use and supplier information are transmitted to consumers , Communicate the contact between production and demand , Attract the attention and interest of consumers , Promote the purchase of .
If some products are overstocked and unsalable in a certain place , But there is a lack of supply , You can also communicate through advertisements . In order to communicate the relationship between production and demand , Now not only production units and sales units publish advertisements , Looking for customers , And some units in urgent need of certain equipment or raw materials , Also advertise , Looking for the source of goods . therefore , The information transmission of advertising can quickly communicate the relationship between supply and demand , Accelerate commodity circulation and sales .
2、 Advertising can stimulate and induce consumption . Consumer demand for a product , It is often a potential demand , This potential need and real purchase action , Sometimes it's contradictory . Visual effects caused by advertisements 、 Sensory mapping and induction often arouse consumers' real desire to buy . Some are good and cheap 、 A marketable new product , Because it is unknown to consumers , So it's hard to open the market , Once the advertisement is carried out , Consumers are buying . in addition , Repeated rendering of advertisements 、 To stimulate repeatedly , It will also expand the popularity of products , It will even cause a certain sense of trust . It will also lead to an increase in purchases .
3、 Advertising can better introduce product knowledge 、 Guide consumption . Through advertising, we can comprehensively introduce the performance of the product 、 quality 、 purpose 、 Maintenance and installation , And dispel their doubts , Eliminate them due to maintenance 、 maintain 、 Installation and other problems , So as to generate the desire to buy .
4、 Advertising can promote new products 、 The development of new technology . A new product 、 The emergence of new technology , Promote by administrative means , It's troublesome and slow , It's very limited , And through advertising , Meet directly with consumers , Can make new products 、 New technology quickly gained a foothold in the market , successful .
If we can analyze the relationship between advertising media investment and sales , We can better allocate advertising expenses and maximize sales .
2. Project brief introduction
2.1 Project content
- This project will analyze the impact of different advertising investment methods on sales , And establish relevant models to predict the sales of different advertising investment methods . The main research contents are as follows :
- The relationship between different advertising investment methods and sales .
- Predict the sales volume brought by different advertising investment methods .
- Try to give reasonable suggestions on advertising investment
2.2 Data description
- The experiment uses from kaggle Obtain data of different advertising investment methods and sales . The data share 4 A field , common 202 Article content . Each content includes the investment and corresponding sales of different advertising methods .

Index name Indicator meaning
TV TV advertising
radio Radio advertising
newspaper Newspaper advertising
sales sales
| Index name | Indicator meaning |
|---|---|
| TV | TV advertising |
| radio | Radio advertising |
| newspaper | Newspaper advertising |
| sales | sales |
2.3 Technical tools
- This project Pycharm For the platform , With Python Language is the foundation , use pandas Data collation and statistical analysis , use matplotlib、seaborn Visual presentation , Using decision tree 、 Random forests 、K— a near neighbor 、 Four linear regression models are used for customer churn early warning .
3. Algorithm principle
3.1 K— a near neighbor
- K a near neighbor , It means the nearest neighbor k Nearest neighbor , It means that each sample can be closest to k My neighbor said .
1、K- Nearest neighbor algorithm (KNN) The algorithm is simple to implement 、 Efficient . In the classification 、 Return to 、 Pattern recognition has a wide range of applications . take KNN When the algorithm is applied to solve problems , Attention should be paid to sample weight and feature weight . Based on SVM Feature weighting algorithm (FWKNN, featureweightedKNN), use SVM Method to determine the feature weight . Experiments show that , FWKNN It can greatly improve the classification accuracy under certain conditions .
2、 KNN The core idea of the algorithm is that if the sample is in the feature space k Most of the nearest samples belong to a certain class , Then the sample also belongs to this category , And it has the characteristics of this kind of samples . In classification decision , This method only determines the category of the samples to be divided according to the category of one or a few samples .kNN The method is only applicable to the classification decision of a few adjacent samples . stay kNN In the method , because kNN The method mainly depends on the surrounding limited neighborhood samples , Instead of relying on domain discrimination to determine the category , therefore , kNN Compared with other methods, this method is more suitable for the sample set to be divided with more overlapping or overlapping .
summary KNN The algorithm can be used for classification , It can also be used for regression . Use the sample k A close neighbor , And assign the average value of neighbor attribute in the sample , So as to obtain the attribute of the sample . For the influence of neighbors with different distances on these samples , Use different weights , This is more useful (weight) 1) advantage : High precision 、 Insensitive to outliers 、 No input data is assumed ;
shortcoming : High computational complexity 、 High spatial complexity ; Applicable data range : Numerical and nominal .
3.2 Decision tree
- The concept of decision tree is very simple . Even if you don't know it, you can understand its working principle through simple graphics , chart 3-1 The flowchart shown is a decision tree , The square represents the judgment module (decision
block), The ellipse represents the termination module (terminating
block), A conclusion has been reached , Can terminate operation . The left and right arrows from the judgment module are called branches (branch), It can reach another judgment module or termination module . chart 3-1
A hypothetical mail classification system is constructed ,
It first detects the sending mail domain address . If the address is myEmployer.com, Put it in the category “ Emails to read when bored ” in . If the email is not from this domain , Check the email for word hockey , If included, the message is categorized to “ Friends' emails that need to be handled in time ”, If not, categorize the message to “ Spam that doesn't need to be read ”.
We often use decision trees to deal with classification problems , Recent surveys show that decision tree is also the most commonly used data mining algorithm . Why it's so popular , A very important reason is that users basically do not need to understand machine learning algorithms , You don't have to delve into how it works .
although k- The nearest neighbor algorithm can accomplish a lot of classification tasks , But its biggest drawback is that it doesn't give the data its meaning , The main advantage of decision trees is that the data form is very easy to understand .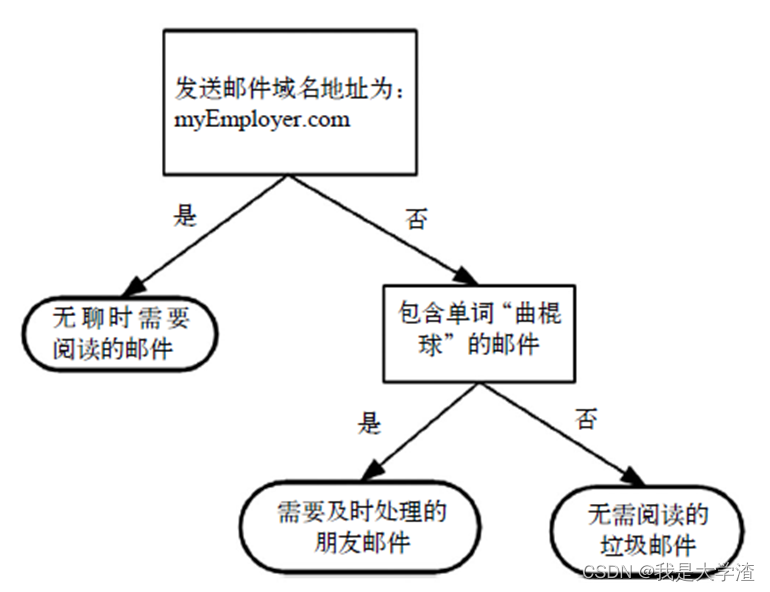
3.3 Random forests
- Random forest is a classifier that contains multiple decision trees . The algorithm of random forest is composed of Leo Breiman and Adele
Cutler Develop inferences . Random forests , As the name suggests, it is to build a forest in a random way , There are many decision trees in the forest , There is no correlation between these decision trees . Random forest is an algorithm that integrates multiple trees with the idea of ensemble learning , Its basic unit is the decision tree , And its essence belongs to a big branch of machine learning ------ Integrated learning (Ensemble
Learning) Method . Integrated learning is to use a series of learners to learn , And integrate various learning methods through certain specific rules , In order to obtain better learning effect than a single learner . Integrated learning builds several models , And combine them to solve the single prediction problem . Its working principle is mainly to generate multiple classifiers or models , Learn and make predictions independently . Random forest is composed of multiple decision trees . For every tree , The training set they use is sampled from the total training set by putting it back . When training the nodes of each tree , The features used are extracted from all features in a random way without putting back in a certain proportion . Advantages as follows : - Random forest can calculate the closeness in each case , In data mining 、 It plays a very important role in detecting deflectors and visualizing data .
- Good performance on big data sets .
- Be able to evaluate the importance of each feature on the classification problem .
3.4 Linear regression
- It is assumed that the functional relationship between the predicted value and the sample characteristics is linear , The task of regression analysis , It depends on the sample X and Y The observations , To estimate the function h, Looking for approximate functional relationships between variables . Definition :
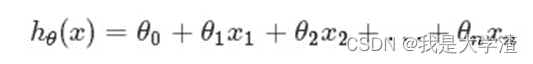
- among ,n = Number of features ;xj = Each training sample is j The value of a feature , It can be regarded as the... Of the eigenvectors j It's worth . For convenience , remember x0=
1, Then multivariable linear regression can be recorded as :(θ、x All means (n+1,1) Virial vector ) Note that pluralism and multiplicity are two different concepts ,“ multivariate ” It means that the equation has multiple parameters ,“ many times ” It refers to the highest power of the parameter in the equation . Multivariate linear equations are hypothetical predictions y It conforms to a multivariate linear equation with all eigenvalues of the sample .
3.5 Ridge return
- Ridge regression mainly solves two major problems in regression : Exclude multicollinearity and select variables . The idea is to add a small disturbance to the original least squares estimation , Also called the penalty term , It makes it possible to solve the generalized inverse when it was impossible to solve the generalized inverse , Yes, the problem is stable and solved . Ridge regression shrinks the sparsity by adding a penalty to the length square of the coefficient vector . When there are multiple related variables in the linear regression model , Their coefficients become uncertain and show high variance . for instance , A large positive coefficient on a variable may be offset by a similarly large negative coefficient on its related variable , Ridge regression is to avoid this phenomenon by imposing constraints on the coefficients . In addition, when the characteristic number p>> When the number of samples , matrix X^TX Irreversible , At this time, the least square method cannot be directly used , There is no such limitation for ridge regression .

4. Analysis steps
4.1 Understand the data
stay Pycharm Enter the following program , Import data and Toolkit , And view the information of the dataset 、 size , And preliminarily observe the head information .
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor # Decision tree
from sklearn.linear_model import LinearRegression # Linear regression
from sklearn.linear_model import Ridge # Ridge return
from sklearn.ensemble import RandomForestRegressor # Random forests
from sklearn.neighbors import KNeighborsRegressor #K near
from sklearn import metrics
plt.rcParams['font.sans-serif'] = ['SimHei'] # Solve Chinese display
plt.rcParams['axes.unicode_minus'] = False # Resolution symbol cannot be displayed
data = pd.read_csv("azd1.csv")
# Look at the dataset size
print(data.shape)
# Set before viewing 15 Data
print(data.head(15))

The header information data set has 4 A field , And the above table 2 1 The information displayed is consistent , That means the information is loaded successfully .
4.2 Data preprocessing
- In the real world , Data is often incomplete ( Some interesting index values are missing )、 inconsistent ( Contains code or name differences )、 Be susceptible to noise ( Error or outlier ) The intrusion of the . Because the database is too big , And data sets often come from multiple heterogeneous sources , Low quality data leads to low quality mining results . It's like a chef trying to make a delicious steamed fish right now , If you do not scale the fish, etc , You can't make the delicious fish we eat . Data preprocessing is a reliable method to solve the data problems mentioned above , therefore , Before data analysis, we need data preprocessing .
Data preprocessing generally follows the following rules :
1) integrity : Whether a single piece of data has a null value , Whether the statistical fields are perfect .
2) overall : Observe all values in a column , Use common sense to judge whether there is a problem with this column , such as : Data definition 、 Unit identification 、 Data itself .
3) Legitimacy : Type of data 、 Content 、 The legitimacy of size . For example, whether there are non ASCII character , Gender is unknown , Older than 150 etc. .
4) Uniqueness : Whether there are duplicate records in the data , Because the data usually comes from the summary of different channels , Repetition is common . Row data 、 Column data needs to be unique .
In this project, data type conversion and missing value processing are two preprocessing methods for data , To ensure its integrity 、 Comprehensiveness and legitimacy .
4.2.1 Data type conversion
First , adopt Dataframe Medium info() Function to check the data type and missing value of each data field 

After observation , It is found that all data types are floating-point data , Therefore, there is no need to convert data types .
4.2.2 Missing value processing
- During the above data type conversion , Find out radio and newspaper Column has missing values , The missing data needs to be processed . Missing value means that the value of one or some indicators in the existing data set is incomplete . Its general treatment mainly includes the following methods :
1) Delete indicators or delete samples : If most samples are missing , This indicator can provide limited information , You can choose to give up using this dimension .
2) Statistical fill : For indicators with missing values , Especially for numerical indicators , Fill it according to the statistical values of all samples about this dimension , Such as using the average 、 Median 、 The number of 、 Maximum 、 Minimum, etc , The specific choice of statistical value requires specific questions and analysis .
3) Uniform fill : Commonly used unified filling values include “ empty ”、“0”、“ It's just infinite ”、“ Negative infinity ” etc. ;
4) forecast / Model filling : The missing value can be predicted by using the index without missing value through the prediction model , Such as statistics 、 Learning, etc. . Although this method is complex , But the final result is better .
The project passed dropna Methods delete the missing value of the sample to process the missing value

Results show , Missing value processing has been completed , The following can be used for data visual analysis .
4.3 Exploratory data analysis
- Exploratory data analysis (Exploratory Data
Analysis,EDA) It is a data analysis method that analyzes data and obtains rules , It is a kind of using various tools and graphic technology ( Like a bar chart 、 Histogram, etc ) The way to analyze data . It is an open process , In the process , We can draw charts and calculate statistics to explore our data .
EDA The goal is to determine what our data can tell us . Variables related to goals are useful for models , Because they are used to predict goals . Simply put, it means drawing pictures to understand data ,EDA The essence of exploratory data analysis is to understand data by drawing pictures . See Appendix for all codes 1.
First ,
Analyze the sales distribution of each advertising method through the scatter diagram :

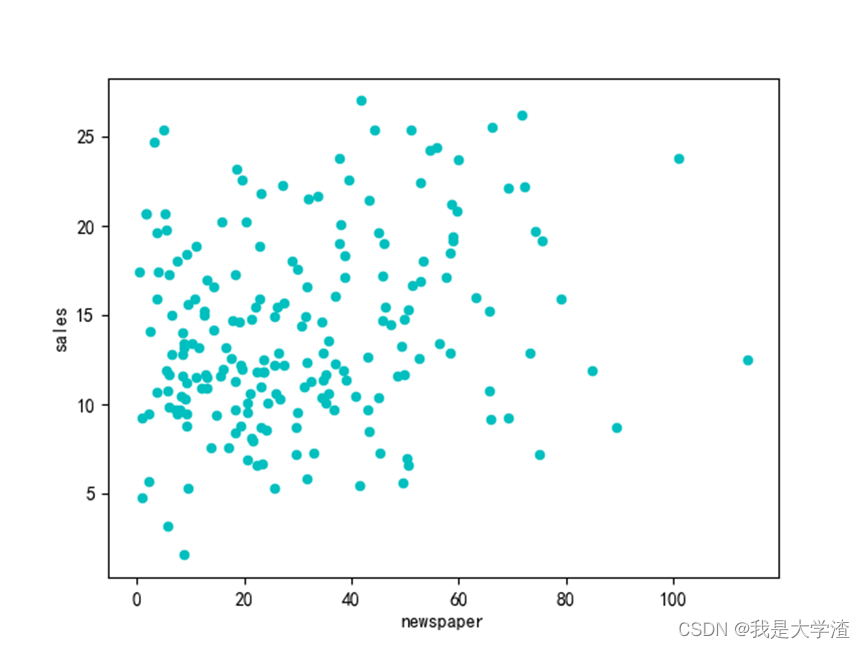
By drawing the scatter diagram of each dimension feature and sales , It can be seen that , All kinds of advertising investment is in direct proportion to sales .
Then we draw a bar graph of the average amount of each delivery method and sales to more intuitively prove this conclusion .
From the figure below, we can also clearly see that the average value of TV advertising is the highest , This is basically consistent with the scatter diagram we obtained above , The distribution of scatter diagram of TV advertising has an obvious trend of concentration .
But we should be clear that the distribution of the scatter diagram can only see a vague outline , Specific quantitative relevance , It can be displayed through incidence matrix and thermal diagram , The first is corr() Method output relation matrix .
Then the output data can be visually visualized , The more commonly used is the thermal diagram , Directly use the above results for output .
The code for drawing the heat map is as follows
def load_data():
data = pd.read_csv(r'azd1.csv', sep=',')
# Calculate the correlation coefficient matrix
corr = data.corr()
print(corr)
cor = corr
plt.figure() # Draw a heat map
sns.heatmap(cor, vmin=-1, cmap="plasma_r", annot=True)
plt.savefig("5")
plt.show()
# Find out about y The correlation coefficient is greater than 0.5 Factors
a = corr['sales']
a = a[abs(a) > 0.5].sort_values(ascending=False)
a_colums = np.array(a.index).tolist()
return data, a_colums
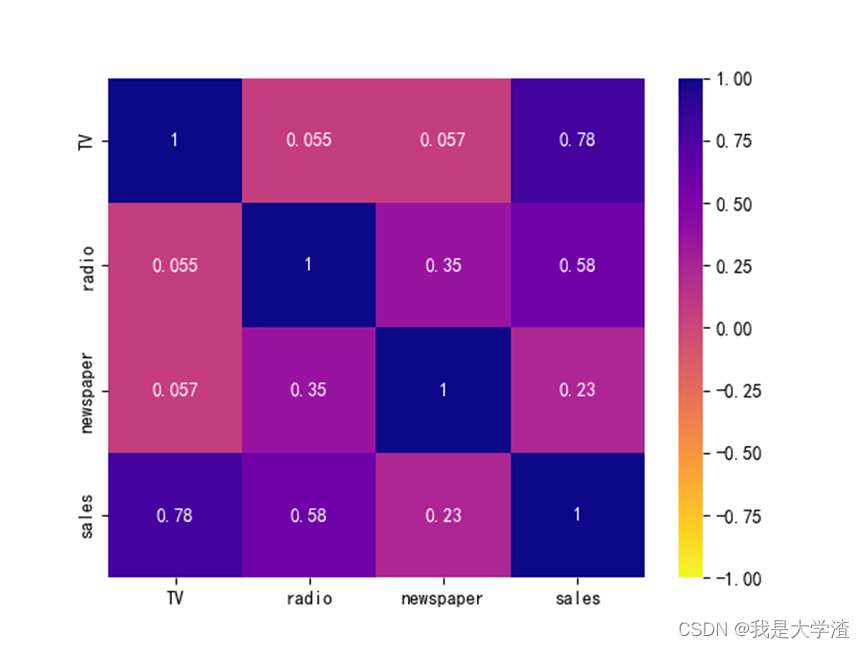
To view the incidence matrix and thermal diagram, you only need to view the main diagonal ( Diagonal from top left to bottom right ) Just one side of the , Because what is explored here is the relationship between profit and the other three influencing factors , So just look at the data in the last row . Values in (0.45,1) perhaps (-1,-0,45) Between , Both can be considered to be related . For example, the output above , Profits are related to TV and radio delivery , It has nothing to do with the delivery of news newspapers .
4.4 Sales forecast
4.4.1 Modeling and model prediction
1) Import the corresponding toolkit
2) This project adopts decision tree 、 Random forests 、K a near neighbor 、 Linear regression 、 Four algorithms of ridge regression , Study and predict advertising investment respectively , And according to the results ( See the picture 4 24 To 4 27 Shown ) The mean square error of , Mean absolute error ,R Value to analyze .
4.4.1.1 Use linear regression model :
def model_fit1(data, a_colums):
# Make the data of training set and test set
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# Split training set and test set
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
# Load model
linreg = LinearRegression()
# Fitting data
linreg.fit(train_X, train_Y)
return linreg, test_X, test_Y

4.4.1.2 Use ridge regression :
def model_fit2(data,a_colums):
# Build data set Training models
# Make the data of training set and test set
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# Split training set and test set
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
ridge=Ridge()
ridge.fit(train_X,train_Y)
return ridge, test_X, test_Y

4.4.1.3 Using the random forest model :
def model_fit3(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# Split training set and test set
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
randomForestRegressor=RandomForestRegressor(n_estimators=200, random_state=0)
randomForestRegressor.fit(train_X,train_Y)
return randomForestRegressor, test_X, test_Y

4.4.1.4 Use k Proximity model analysis :
def model_fit4(data,a_colums):
# Build data set Training models
# Make the data of training set and test set
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# Split training set and test set
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
k=5
kNeighborsRegressor=KNeighborsRegressor(k)
kNeighborsRegressor.fit(train_X,train_Y)
return kNeighborsRegressor, test_X, test_Y

4.4.1.5 Use the decision tree model to analyze :
def model_fit5(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# Split training set and test set
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
decisionTreeRegressor=DecisionTreeRegressor()
decisionTreeRegressor.fit(train_X,train_Y)
return decisionTreeRegressor, test_X, test_Y

Results show , Random forest and decision tree models R2( Goodness of fit ) Higher , More than 90% .
3) Next, draw the learning curve of the model , Observe the fitting of the model .
- Linear regression model results

- Ridge regression model results

- Random forest model results

- K Adjacent model results

- Decision tree model results

From the results , The accuracy of random forest model prediction is the highest , Basically fit with the actual curve , This also more intuitively shows that this data set is more accurate with random forest model .
5. Summary of the experiment
5.1 Result analysis
Based on the above analysis , You can get the following results :
To increase the sales of goods , We should first consider increasing the investment in TV advertising and radio advertising , Because the sales of goods have the greatest relationship with these two advertising methods
We should strictly control the amount of advertising investment in newspapers , Because after our analysis , This way of newspaper advertising investment has no obvious relationship with sales , let me put it another way , Increasing the amount of newspaper advertising investment does not improve sales , Therefore, there is no need to increase the advertising investment of newspapers .
5.2 Suggestions for improvement
- 1) The advertising of modern enterprises cannot only focus on the traditional way of publicity , With the rise of Internet platforms , In the era of new media marketing , The sales mode of enterprise products has also changed . At present, the transformation of production and product marketing of enterprises can be carried out with the help of the Internet platform in new media , This can effectively reduce the sales cost and transportation expenses of enterprises , So as to realize the economic benefit growth of the enterprise , Provide guarantee for the healthy development of production enterprises .
- 2) Enterprises cannot only care about the benefits of their own advertising , The most fundamental thing is to improve the quality of our products , No matter what kind of advertising , The most important thing is to return to the commodity itself , If the product is good enough , This is already the best advertisement , I think advertising is to recommend those shiny products or commodities to more people .
5.3 Experimental experience
In fact, I've heard of it a long time ago python This programming language , It ranks first on major programming ranking websites , I also came up with the idea of learning it systematically , But I always make excuses for myself , delayed , Never started learning . Until I knew that my major courses this semester had python after , In the elective class, I specially chose this elective course related to it . I also read by myself during the winter vacation python Related classic books and learning in professional courses , Master the basic grammar and the use of related libraries . But I have been stuck in the stage of watching , I haven't written a big program myself , I haven't done data analysis myself . After the actual combat of this project , I am right. python There is a deeper understanding of the language , At the same time, I also understand the basic methods of big data analysis , I also have the following summary .
1) python There are many third-party libraries in , There are many programs that we don't need to write ourselves , You can directly use the related functions in the Library , That's why python The reason why it is widely used .
2) With big data 、 Cloud platform 、 The Internet of things 、 The rapid development of artificial intelligence technology , Big data analysis is bound to play a greater role . The meaning of big data comes down to four words : Aid decision making . Use big data to analyze , Be able to analyze the current situation 、 The analysis reason 、 Found that regular 、 To sum up your experience 、 And predict trends , All of these can be used to assist decision making . The more data we have , Our decision-making can be more scientific 、 accurate 、 reasonable . In this respect , It can also be said that data itself does not produce value , Big data must and other specific areas 、 Industry combination , After being able to help decision makers , It's worth it . Governments or enterprises can use big data , Improve management 、 Decision making level , Improve economic efficiency .
3) Only in practice can we really improve our programming level , And understanding of relevant knowledge , Simply listening to classes and reading books can only increase theoretical knowledge , Programming requires practice , Otherwise, you will only have high hopes and low hands , Looking at a very simple problem, I just can't solve it by myself .
4) Although the course is over , But I can't stop learning , In later study , I should pay attention to my application of language , You can't just talk on paper , Difficult to buy in the process of programming will encounter problems , Keep the habit of thinking independently , Inquire relevant information to solve , Instead of giving up .
primary gen No easy , also Greek at various position Big Guy the a One Next
spot Fabulous , you Of recognize can yes I gen do Of dynamic force !
️ closed hidden , you Of green look at yes I No force Of Fang towards !
️ review On , you Of It means see yes I Into the Step Of goods rich !
边栏推荐
- 歹徒逃亡3
- [learning notes] possible reasons and optimization methods for white screen on Web pages
- Today, let's talk about the underlying architecture design of MySQL database. How much do you know?
- Jsonobject is sorted in A-Z order of key
- 华为专家自述:如何成为优秀的工程师
- Detailed analysis of the process (life cycle) of class loading
- metaRTC5.0实现君正的纯C的webrtc版IPC
- 安装snownlp包过程出现Requirement already satisfied:及Read timed out.问题解决方法
- Identification of Chinese medicinal materials
- 10分钟就能写出来的——25~30K的国外企业招聘面试考题,这不是轻轻松松吗~
猜你喜欢

Detailed explanation of class loader and parental delegation mechanism

【LVGL(1)】LVGL的简单介绍

kubernetes 的Deployment(部署),Service概念,动态扩缩容

kubernetes急速安装

Metaltc5.0 realizes webrtc version IPC of Junzheng pure C
![[lvgl (important)] style attribute API function and its parameters](/img/55/f25a510cf04caff7ee15e72360c3a1.png)
[lvgl (important)] style attribute API function and its parameters

You don't know these pits. You really don't dare to use BigDecimal
Machine learning case: smoking in pregnant women and fetal health

MapReduce(一)

MGR_ mysqlsh_ Keepalive high availability architecture deployment document
随机推荐
Sealos 打包部署 KubeSphere 容器平台
Kubernetes' deployment, service concept, dynamic capacity expansion
[lvgl layout] grid layout
[audio decoding chip] Application of vs1503 audio decoding chip
Today, let's talk about the underlying architecture design of MySQL database. How much do you know?
【音频解码芯片】VS1503音频解码芯片的应用
Special effects - starry cosmic background effects
Random forest, lgbm parameter adjustment based on Bayesian Optimization
xavier_normal_ 初始化测试
分组后返回每组中的最后一条记录 GROUP_CONCAT用法
Sealos packages and deploys kubesphere container platform
[lvgl layout] flexible layout
Metaltc5.0 realizes webrtc version IPC of Junzheng pure C
济南人社已签1W+电子劳动合同,法大大助力HR数字化
[esp8266 spot welder] Based on esp8266 for Arduino
三级分类/菜单的查询——树形结构
Introduction, architecture and principle of kubernetes
Geek planet ByteDance one stop data governance solution and platform architecture
Detailed explanation of class loader and parental delegation mechanism
Take you to understand the inventory deduction principle of MySQL database