当前位置:网站首页>stable_ Baselines quick start
stable_ Baselines quick start
2022-07-25 13:20:00 【Hurry up and don't let it rot】
0 brief introduction
baselines yes OpenAI Launched a set of reinforcement learning algorithm components , Used to quickly configure reinforcement learning algorithm , It is friendly to beginners
1 install
pip install stable-baselines
2 Parameter Introduction
Base RL Class
common interface for all the RL algorithms
class stable_baselines.common.base_class.BaseRLModel(policy,env,verbos=0,*,requires_vec_env,policy_base,policy_kwargs=None,seed=None,n_cpu_tf_sess=None)
The base RL model
Parameters:
policy - ( BasePolicy )Policy object
policy: Strategy model selection , Used to establish status / state - The connection between action pairs and strategies , The bottom layer is multilayer perceptron or convolutional network .
env: [Gym environment] The environment to learn from [if registered in Gym, can be str. Can be None for loading trained models]
env:
The necessary methods :step(action)、reset()、render()
Necessary elements :action_space、observation_space
step(action): Simulation step , How to accept a action Then carry out one-step simulation
reset(): Reset
render(): Show
action_space: Successive / discrete . For example, discrete , East, West, North and south . Like continuous , Select an interval to produce a number , As one of his motion steps .
observation_space It's the same , For example, robot right 6 A joint , His state is based on his 6 Positions and 6 A speed to express . This speed and position have an upper and lower range . This range can be used as his observation_space
Meet the above 5 If there are three elements , This environment can be transmitted to stable-baselines It's time for the next training
application
adopt stable_baselines establish DQN frame , Train and run the inverted pendulum (CartPole-v0)
from stable_baselines import DQN
from stable_baselines.common.evaluation import evaluate_policy
import gym
import time
env = gym.make('CartPole-v0') # Incoming inverted pendulum
TRAIN = 0
if TRAIN: # The training part
model = DQN('MlpPolicy', env, learning_rate=1e-3, prioritized_replay=True, verbose=1) # It belongs to such a network that can be discrete
# MlpPolicy, A strategy of multilayer perceptron or neural network
# env, Incoming environment
# Some other parameters , Look under this folder , I don't want to elaborate , Each one has a detailed explanation
model.learn(total_timesteps=int(1e5)) # Start training , Direct use model.learn That's all right. , This learn Some parameters will also be involved in
model.save("dqn_cartpole") # After training , You can save such a model
del model # After training , This model is useless , You can delete it
else: # Part of the presentation
model = DQN.load("dqn_cartpole", env) # Call the trained model , Call from neural network
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
obs = env.reset() # Status reset
for i in range(1000):
action, _states = model.predict(obs) # Pass the current status into , Tell us what actions we will make .
obs, rewards, done, info = env.step(action)# Return to a new state
env.render() # Make a display
time.sleep(2) # for showing render()
边栏推荐
- Friends let me see this code
- 安装mujoco报错:distutils.errors.DistutilsExecError: command ‘gcc‘ failed with exit status 1
- Programmer growth chapter 27: how to evaluate requirements priorities?
- 领域驱动模型设计与微服务架构落地-模型设计
- 深度学习的训练、预测过程详解【以LeNet模型和CIFAR10数据集为例】
- 并发编程 — 内存模型 JMM
- 卷积神经网络模型之——LeNet网络结构与代码实现
- Pytorch creates its own dataset and loads the dataset
- Generate SQL script file by initializing the latest warehousing time of vehicle attributes
- [ai4code final chapter] alphacode: competition level code generation with alphacode (deepmind)
猜你喜欢

Generate SQL script file by initializing the latest warehousing time of vehicle attributes

0716RHCSA
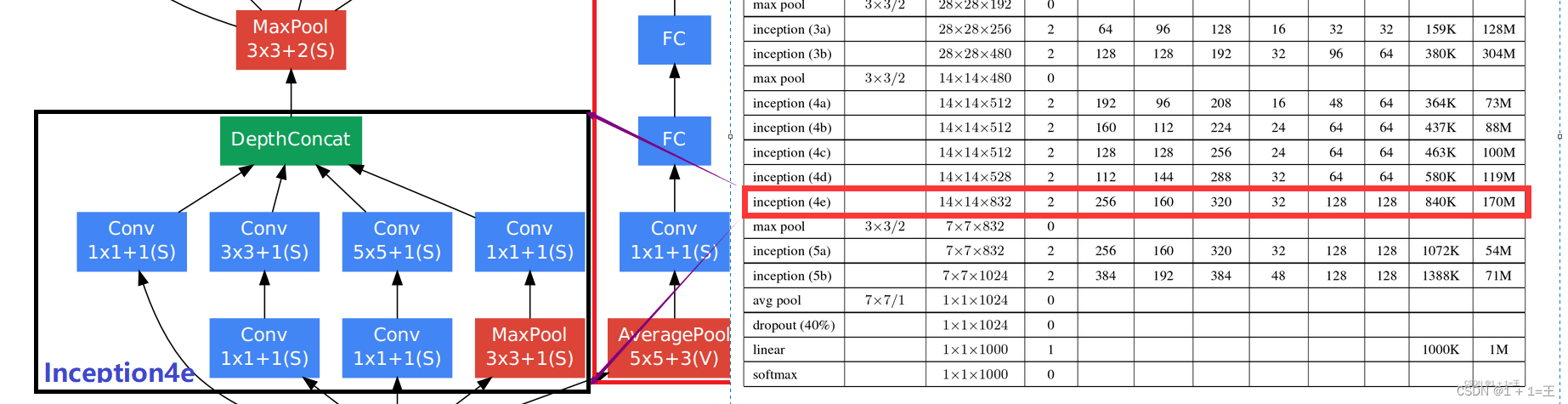
Convolutional neural network model -- googlenet network structure and code implementation
![[CSDN year-end summary] end and start, always on the way -](/img/51/a3fc5eba0eeb22b600260ee81ff9e6.png)
[CSDN year-end summary] end and start, always on the way - "2021 summary of" 1+1= Wang "

【服务器数据恢复】HP EVA服务器存储RAID信息断电丢失的数据恢复

Docker学习 - Redis集群-3主3从-扩容-缩容搭建

Redis visualizer RDM installation package sharing
Masscode is an excellent open source code fragment manager

Excel添加按键运行宏

为提高效率使用ParallelStream竟出现各种问题
随机推荐
The programmer's father made his own AI breast feeding detector to predict that the baby is hungry and not let the crying affect his wife's sleep
0716RHCSA
0710RHCSA
6W+字记录实验全过程 | 探索Alluxio经济化数据存储策略
Vim技巧:永远显示行号
G027-OP-INS-RHEL-04 RedHat OpenStack 创建自定义的QCOW2格式镜像
Programmer growth chapter 27: how to evaluate requirements priorities?
机器学习强基计划0-4:通俗理解奥卡姆剃刀与没有免费午餐定理
Pytorch creates its own dataset and loads the dataset
Generate SQL script file by initializing the latest warehousing time of vehicle attributes
Convolutional neural network model -- alexnet network structure and code implementation
并发编程 — 内存模型 JMM
【AI4Code】《IntelliCode Compose: Code Generation using Transformer》 ESEC/FSE 2020
卷积神经网络模型之——AlexNet网络结构与代码实现
OAuth, JWT, oidc, you mess me up
mujoco+spinningup进行强化学习训练快速入门
【服务器数据恢复】HP EVA服务器存储RAID信息断电丢失的数据恢复
牛客论坛项目部署总结
R语言GLM广义线性模型:逻辑回归、泊松回归拟合小鼠临床试验数据(剂量和反应)示例和自测题
0713RHCSA