当前位置:网站首页>卷积神经网络模型之——AlexNet网络结构与代码实现
卷积神经网络模型之——AlexNet网络结构与代码实现
2022-07-25 12:43:00 【1 + 1=王】
文章目录
AlexNet简介
AlexNet原文地址:https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
AlexNet诞生于2012年,由2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。
AlexNet的贡献点:
首次使用GPU加速网络训练
使用ReLU激活函数,代替不是传统的Sigmoid和Tanh,解决了Sigmoid的梯度消失问题,使收敛更快。

训练时使用Dropout随机忽略一部分神经元,以减少模型过拟合。

使用了LRN局部响应归一化提高准确率。
在CNN中使用重叠的最大池化,提升了特征的丰富性。
AlexNet网络的原始输入图像大小为【3,224,224】,由5个卷积层、3个池化层和3个全连接层构成,并且在每一个卷积层和全连接层之后都进行一次ReLU激活。其中的3个池化层分别跟在第1、第2和第5个卷积层的激活之后。网络结构图如下: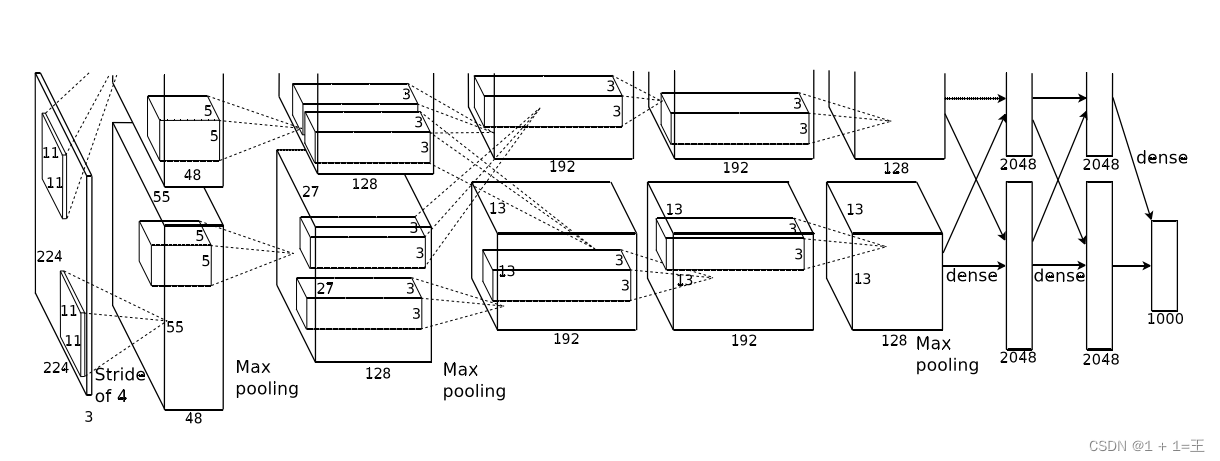
AlexNet网络结构解析
卷积层1(Conv + ReLU + MaxPool)

Conv1使用卷积核大小为11,步距为4,padding为2。
输入大小:【3,224,224】
输出大小:【48,55,55】
N = (W-F+2P)/ S + 1 = (224-11+2*2)/4+1=55。
卷积之后跟着一个ReLU激活,激活之后接着一个最大池化上采样,池化核大小为3,步距为2,池化后输出大小为【48,27,27】。
PyTorch表述本层为:
# input[3, 224, 224]
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
卷积层2(Conv + ReLU + MaxPool)

Conv2使用卷积核大小为5,步距为1,padding为2。
输入大小:【48,27,27】
输出大小:【128,27,27】
N = (W-F+2P)/ S + 1 = (27-5+2*2)/1+1=27。
卷积之后跟着一个ReLU激活,激活之后接着一个最大池化上采样,池化核大小为3,步距为2,池化后输出大小为【128,13,13】。
PyTorch表述本层为:
# input[48,27,27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
卷积层3(Conv + ReLU )
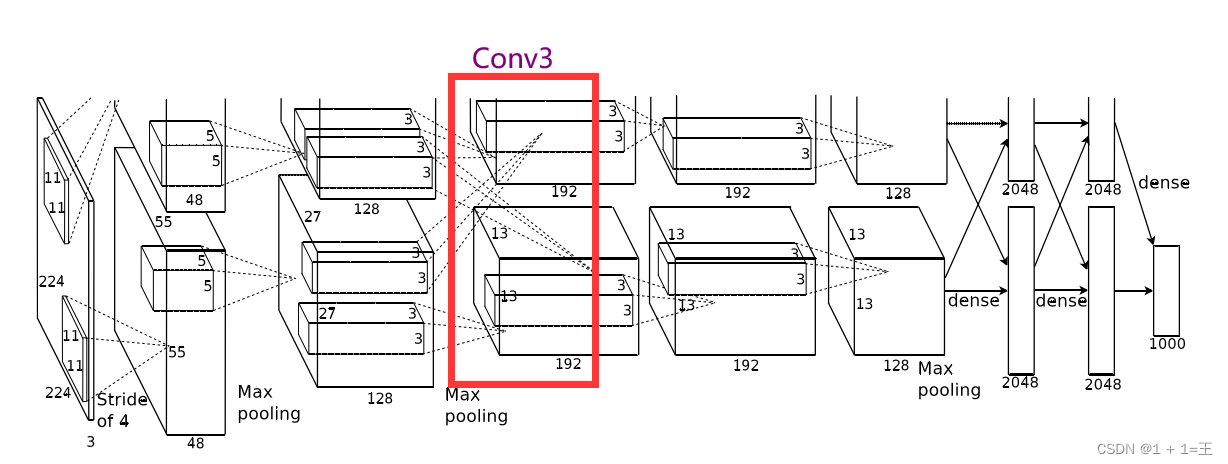
Conv3使用卷积核大小为3,步距为1,padding为1。
输入大小:【128, 13, 13】
输出大小:【192,13,13】
N = (W-F+2P)/ S + 1 = (13-3+1*2)/1+1=13。
卷积之后跟着一个ReLU激活,没有池化。
PyTorch表述本层为:
# input[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
卷积层4(Conv + ReLU )

Conv4使用卷积核大小为3,步距为1,padding为1。
输入大小:【192, 13, 13】
输出大小:【192,13,13】
N = (W-F+2P)/ S + 1 = (13-3+1*2)/1+1=13。
卷积之后跟着一个ReLU激活,没有池化。
PyTorch表述本层为:
# input[192, 13, 13]
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
卷积层5(Conv + ReLU + MaxPool)
Conv5使用卷积核大小为3,步距为1,padding为1。
输入大小:【192, 13, 13】
输出大小:【128,13,13】
N = (W-F+2P)/ S + 1 = (13-3+1*2)/1+1=13。
卷积之后跟着一个ReLU激活,激活之后接着一个最大池化上采样,池化核大小为3,步距为2,池化后输出大小为【128,6,6】。
PyTorch表述本层为:
# input[192, 13, 13]
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
第5个卷积层之后,就是三个全连接层。
FC1
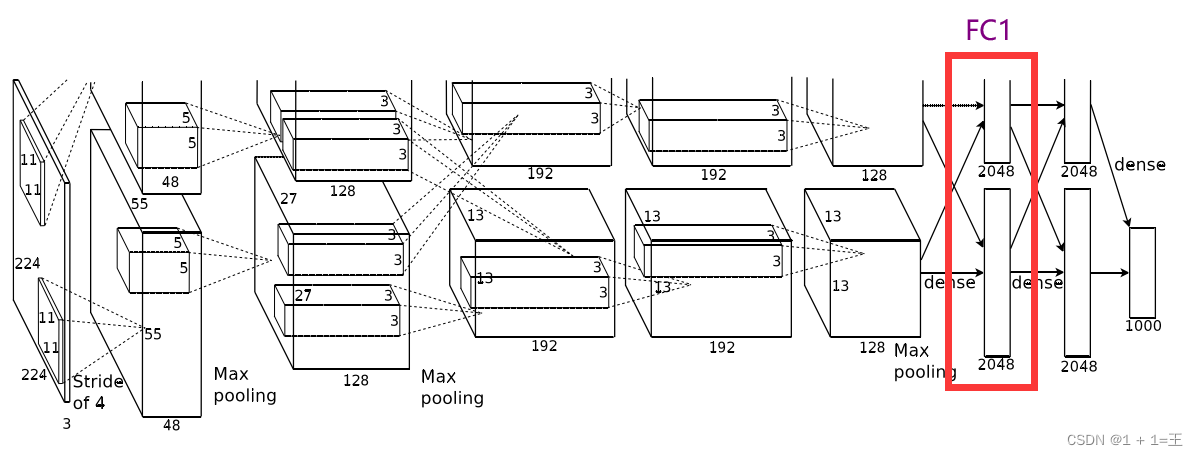
全连接FC1之前先进行一次Dropout。
FC1使用4096个神经元,对128个大小为66的特征图,进行一个全连接。
输入大小:【12866】
输出大小:【2048】
FC1之后进行一次ReLU激活。
PyTorch表述本层为:
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
FC2

全连接FC2之前先进行一次Dropout。
FC1使用2048个神经元,对2048特征图,进行一个全连接。
输入大小:【2048】
输出大小:【2048】
FC1之后进行一次ReLU激活。
PyTorch表述本层为:
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
FC3

FC3是AlexNet的输出层,输出大小为1000,对应1000个类别。
PyTorch表述本层为:
nn.Linear(2048, 1000),
使用PyTorch搭建AlexNet网络结构
前面在网络结构解析的时候,都已经给出了每一层的代码表述。
init
这里我们使用nn.Sequential将5个卷积层放在一起,定义为features(义为提取特征);将3个全连接层放在一起,定义为classifier(义为分类)。
def __init__(self):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
forward
然后定义正向传播过程
def forward(self, x):
x = self.features(x) # 5个卷积层
x = torch.flatten(x, start_dim=1) # 将3维展平成一维,进行全连接
x = self.classifier(x) # 3个全连接层
return x
完整代码
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, 1000),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
model = AlexNet();
print(model)
打印结构:
边栏推荐
- Zero basic learning canoe panel (16) -- clock control/panel control/start stop control/tab control
- 【AI4Code】《Contrastive Code Representation Learning》 (EMNLP 2021)
- Atcoder beginer contest 261 f / / tree array
- 使用vsftpd服务传输文件(匿名用户认证、本地用户认证、虚拟用户认证)
- [machine learning] experimental notes - emotion recognition
- Zero basic learning canoe panel (13) -- trackbar
- go : gin 自定义日志输出格式
- 【历史上的今天】7 月 25 日:IBM 获得了第一项专利;Verizon 收购雅虎;亚马逊发布 Fire Phone
- Zero basic learning canoe panel (12) -- progress bar
- Memory layout of program
猜你喜欢
![[shutter -- layout] stacked layout (stack and positioned)](/img/01/c588f75313580063cf32cc01677600.jpg)
[shutter -- layout] stacked layout (stack and positioned)

深度学习的训练、预测过程详解【以LeNet模型和CIFAR10数据集为例】
LeetCode 1184. 公交站间的距离

【重温SSM框架系列】15 - SSM系列博文总结【SSM杀青篇】

跌荡的人生

Docekr学习 - MySQL8主从复制搭建部署
【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020

Memory layout of program

【OpenCV 例程 300篇】239. Harris 角点检测之精确定位(cornerSubPix)

Common operations for Yum and VIM
随机推荐
程序的内存布局
如何用因果推断和实验驱动用户增长? | 7月28日TF67
The world is exploding, and the Google server has collapsed
深度学习的训练、预测过程详解【以LeNet模型和CIFAR10数据集为例】
If you want to do a good job in software testing, you can first understand ast, SCA and penetration testing
“蔚来杯“2022牛客暑期多校训练营2 补题题解(G、J、K、L)
Atcoder beginer contest 261e / / bitwise thinking + DP
[shutter -- layout] stacked layout (stack and positioned)
AtCoder Beginner Contest 261 F // 树状数组
word样式和多级列表设置技巧(二)
零基础学习CANoe Panel(13)—— 滑条(TrackBar )
卷积神经网络模型之——VGG-16网络结构与代码实现
Want to go whoring in vain, right? Enough for you this time!
Shell常用脚本:检测某域名、IP地址是否通
Perf performance debugging
程序员奶爸自制AI喂奶检测仪,预判宝宝饿点,不让哭声影响老婆睡眠
Zero basic learning canoe panel (15) -- CAPL output view
【C语言进阶】动态内存管理
Leetcode 1184. distance between bus stops
Business visualization - make your flowchart'run'(3. Branch selection & cross language distributed operation node)