当前位置:网站首页>【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
2022-07-25 12:40:00 【chad_ lee】
《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
take BERT Apply to Bimodal data On : programing language (PL) And natural language (NL), After pre training CodeBERT The resulting generic representation , It can support various downstream tasks, such as natural language code search , Code document generation . The author also contributed a NL-PL Data set of .
Method
Model architecture
The model is BERT, Model architecture and RoBERTa-base Almost the same , Include 12 Layers , Each floor has 12 It's a self focusing head , The dimension of each self attention head is 64. The hidden dimension is 768,FF The dimension of the layer is 3072. The total amount of model parameters is 1.25 Billion .
Input and output
Input : The input of pre training is a sequence of natural language text and programming language text :[CLS], w1, w2, …wn, [SEP], c1, c2, …, cm, [EOS],w Is textual token,c It's code token.
Output : Every token stay CodeBERT There are outputs in , Text and code token The output of is their semantic vector representation in the current scene ,[CLS] The vector representation of is the aggregation of the whole sequence representation (aggregated sequence representation). Separator [SEP] And the ending [EOS] The output of is meaningless .
Pre training data
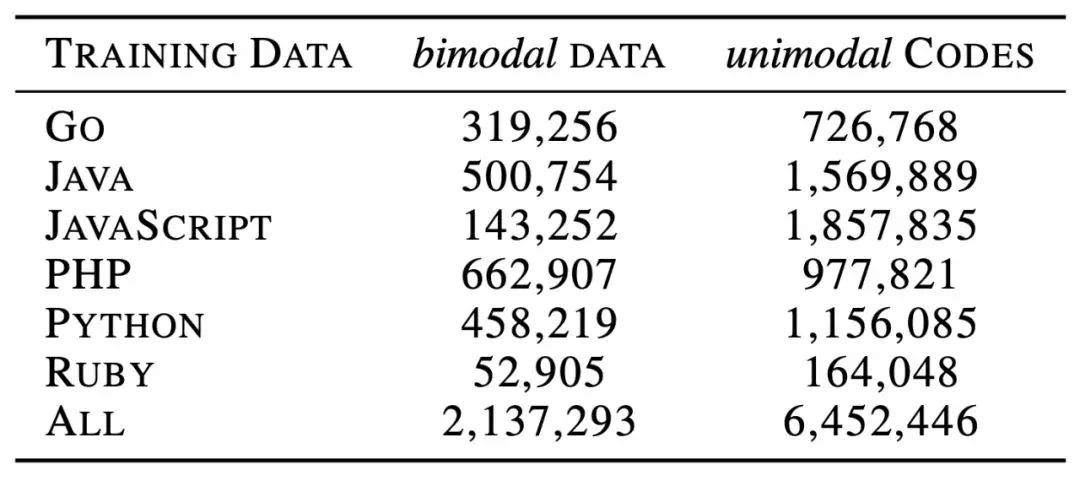
Yes Two types of training data , One is bimodal PL-NL Data pair , There is another kind Single mode The data of , namely “ Code without parallel corresponding natural language text ” and “ Natural language text without corresponding code ”.
NL-PL The examples are as follows , among NL It's a function document ( Black dashed box ) The first paragraph in ( Red box )

Pretraining task
MLM (Masked Language Modeling)
There are two objective functions , In bimodal data NL-PL use MLM Objective function , stay NL and PL Randomly select the location mask( The two positions are independent ), use token [MASK] Instead of :
m i w ∼ unif { 1 , ∣ w ∣ } for i = 1 to ∣ w ∣ m i c ∼ unif { 1 , ∣ c ∣ } for i = 1 to ∣ c ∣ w masked = REPLACE ( w , m w , [ M A S K ] ) c masked = REPLACE ( c , m c , [ M A S K ] ) x = w + c \begin{aligned} m_{i}^{w} & \sim \operatorname{unif}\{1,|\boldsymbol{w}|\} \text { for } i=1 \text { to }|\boldsymbol{w}| \\ m_{i}^{c} & \sim \operatorname{unif}\{1,|\boldsymbol{c}|\} \text { for } i=1 \text { to }|\boldsymbol{c}| \\ \boldsymbol{w}^{\text {masked }} &=\operatorname{REPLACE}\left(\boldsymbol{w}, \boldsymbol{m}^{\boldsymbol{w}},[M A S K]\right) \\ \boldsymbol{c}^{\text {masked }} &=\operatorname{REPLACE}\left(\boldsymbol{c}, \boldsymbol{m}^{c},[M A S K]\right) \\ \boldsymbol{x} &=\boldsymbol{w}+\boldsymbol{c} \end{aligned} miwmicwmasked cmasked x∼unif{ 1,∣w∣} for i=1 to ∣w∣∼unif{ 1,∣c∣} for i=1 to ∣c∣=REPLACE(w,mw,[MASK])=REPLACE(c,mc,[MASK])=w+c
MLM The goal is to predict being mask Of touken. Discriminator p D 1 p^{D_{1}} pD1 Forecast No i The first word is masked Of token Probability .
L M L M ( θ ) = ∑ i ∈ m w ∪ m c − log p D 1 ( x i ∣ w masked , c masked ) \mathcal{L}_{\mathrm{MLM}}(\theta)=\sum_{i \in \boldsymbol{m}^{\boldsymbol{w}} \cup \boldsymbol{m}^{c}}-\log p^{D_{1}}\left(x_{i} \mid \boldsymbol{w}^{\text {masked }}, \boldsymbol{c}^{\text {masked }}\right) LMLM(θ)=i∈mw∪mc∑−logpD1(xi∣wmasked ,cmasked )
RTD (replaced token detection)
stay MLM We only use NL-PL data , stay RTD Use unimodal data .

here CodeBERT Incarnate as Fig2 Medium NL-Code Discriminator, The specific method is to input the text / The code sequence first randomly selects several positions as mask, Then use a Generator by mask Generate a Puzzling token, there Generator It can be understood as Word2Vec( Not at all , Easy to understand ), According to the context mask Predict a token, It may be true ( Such as w5), It may be wrong, but it is also confusing ( After all word2vec Predicted ).
The generated new sequence is sent into CodeBERT, by CodeBERT Output Every token Of embedding Make a dichotomy , Determine whether it has been replaced .
fine-tuning
For natural language search code tasks , Just use [CLS] The output representation of determines the similarity between the two modal languages .
For the code generation text task , use CodeBERT As encoder-decoder Of encoder Partial initialization .
experiment
The experimental results of the article will not be released , Did code search respectively 、NL-PL Probe 、 Given the experiment of code generating documents .
https://marketplace.visualstudio.com/items?itemName=graykode.ai-docstring&ssr=false
VS Code There are already based on CodeBERT Of Docstring Plug in :
边栏推荐
- Plus SBOM: assembly line BOM pbom
- 【九】坐标格网添加以及调整
- Alibaba cloud technology expert Qin long: reliability assurance is a must - how to carry out chaos engineering on the cloud?
- Synergetic process
- 搭建Vision Transformer系列实践,终于见面了,Timm库!
- 2022.07.24 (lc_6124_the first letter that appears twice)
- Fiddler packet capturing app
- Pytorch main module
- MySQL练习二
- R language ggplot2 visualization: visualize the scatter diagram, add text labels to some data points in the scatter diagram, and use geom of ggrep package_ text_ The repl function avoids overlapping l
猜你喜欢

交换机链路聚合详解【华为eNSP】

技术管理杂谈

Zuul gateway use
![[fluent -- example] case 1: comprehensive example of basic components and layout components](/img/d5/2392d9cb8550aa2692c8b41303d507.png)
[fluent -- example] case 1: comprehensive example of basic components and layout components

Microsoft azure and Analysys jointly released the report "Enterprise Cloud native platform driven digital transformation"

防范SYN洪泛攻击的方法 -- SYN cookie

Want to go whoring in vain, right? Enough for you this time!

Azure Devops (XIV) use azure's private nuget warehouse

PyTorch项目实战—FashionMNIST时装分类

Jenkins configuration pipeline
随机推荐
Pytorch visualization
我想问DMS有没有定时备份某一个数据库的功能?
Communication bus protocol I: UART
软件测试流程包括哪些内容?测试方法有哪些?
Maskgae: masked graph modeling meets graph autoencoders
【4】 Layout view and layout toolbar usage
Pytorch main module
Perf performance debugging
[rust] reference and borrowing, string slice type (& STR) - rust language foundation 12
Build a series of vision transformer practices, and finally meet, Timm library!
【2】 Grid data display stretch ribbon (take DEM data as an example)
flinkcdc可以一起导mongodb数据库中的多张表吗?
LeetCode 1184. 公交站间的距离
Use of hystrix
Jenkins配置流水线
深度学习MEMC插帧论文列表paper list
R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip chart, set the palette parameter to configure the color of data points at different levels,
阿里云技术专家秦隆:可靠性保障必备——云上如何进行混沌工程?
Synergetic process
【11】 Production and adjustment of vector and grid data Legends