当前位置:网站首页>Ultrafast transformers | redesign vit with res2net idea and dynamic kernel size, surpassing mobilevit
Ultrafast transformers | redesign vit with res2net idea and dynamic kernel size, surpassing mobilevit
2022-06-22 21:00:00 【Zhiyuan community】
In pursuit of continuously improving accuracy , Large scale network models are usually developed . Such models require a lot of computing resources , Therefore, it cannot be deployed on edge devices . Because edge devices are available in many application fields , Therefore, it is of great value to build a resource efficient general network .
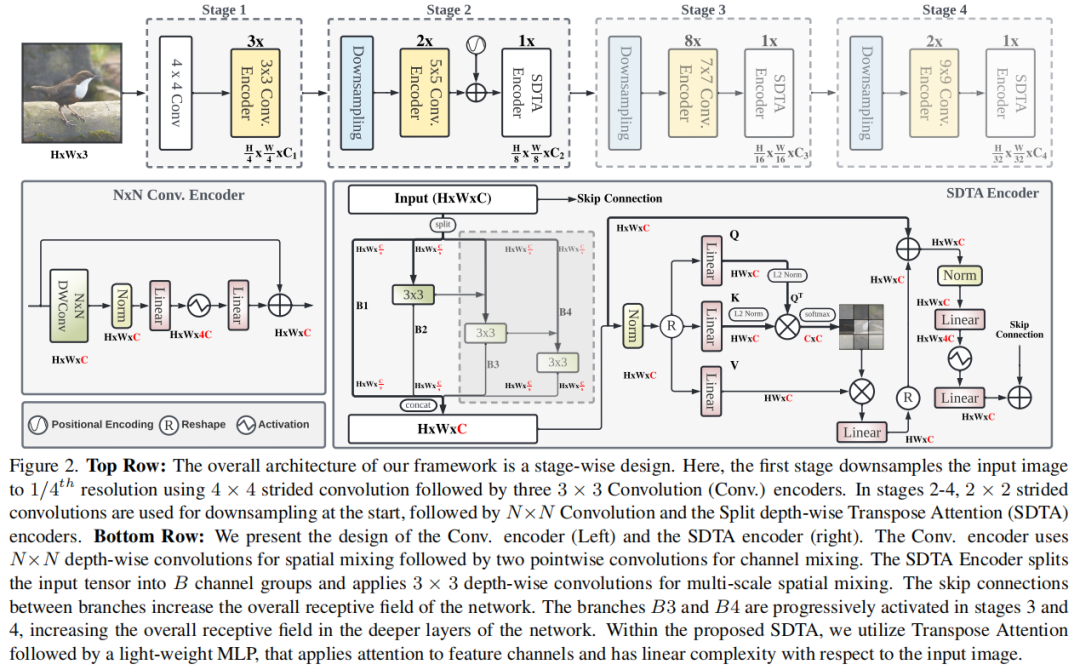
In this work CNN and Transformer The advantages of the model , A new efficient hybrid architecture is proposed EdgeNeXt. Especially in EdgeNeXt in , Introduced Split Depth-wise Transpose Attention(SDTA) Encoder ,SDTA Split the input tensor into multiple channel groups , And using depth convolution and cross channel dimension Self-Attention To implicitly expand receptive field and encode multi-scale features .
In the classification 、 Extensive experiments on detection and segmentation tasks reveal the advantages of the proposed method ,EdgeNeXt It is superior to the most advanced method when the calculation requirements are relatively low .1.3M Parametric EdgeNeXt Model in ImageNet-1K It has been realized. 71.2% Of top-1 Accuracy rate , With 2.2% Gain and 28% Of FLOP Reduced by more than MobileViT. Besides ,5.6M Parametric EdgeNeXt Model in ImageNet-1K It has been realized. 79.4% Of top-1 Accuracy rate .

Thesis link :
https://arxiv.org/abs/2206.10589
边栏推荐
- Raspberry pie environment settings
- Feign常见问题总结
- 【剑指Offer】面试题44.数字序列中的某一位数字
- [proteus simulation] H-bridge drive DC motor composed of triode + key forward and reverse control
- Visualization of wine datasets in R language
- Ribbon load balancing
- 访问成功但抛出异常:Could not find acceptable representation
- 扩展Ribbon支持Nacos权重的三种方式
- 农产品期货开户
- 支持在 Kubernetes 运行,添加多种连接器,SeaTunnel 2.1.2 版本正式发布!
猜你喜欢

采用网络远程访问树莓派。

Moke 6. Load balancing ribbon

R language Midwest dataset visualization

R 语言USArrests 数据集可视化
R语言midwest数据集可视化

How to realize @ person function in IM instant messaging

Ribbon load balancing

深度学习常用损失函数总览:基本形式、原理、特点
![[proteus simulation] 74LS138 decoder water lamp](/img/30/7dbdead9c18788cd946b5541e76443.png)
[proteus simulation] 74LS138 decoder water lamp

R language organdata dataset visualization
随机推荐
How to realize @ person function in IM instant messaging
The road to systematic construction of geek planet business monitoring and alarm system
MySQL Basics - functions
Easyclick update Gallery
智能计算之神经网络(BP)介绍
智能計算之神經網絡(BP)介紹
Golang學習筆記—結構體
UnityEditor 编辑器脚本执行菜单
Visualization of wine datasets in R language
华为云发布拉美互联网战略
MySQL基础——函数
启牛送的券商账户是安全的吗?启牛提供的券商账户是真的?
R 语言nutrient数据集的可视化
what? You can't be separated by wechat
Easyclick fixed status log window
山东大学科技文献期末复习(个人速成向)
78-生产系统不改代码解决SQL性能问题的几种方法
71-对2010年阿里一道Oracle DBA面试题目的分析
天,靠八股文逆袭了啊
软件测试——测试用例设计&测试分类详解