当前位置:网站首页>MapReduce elementary programming practice
MapReduce elementary programming practice
2022-06-28 01:31:00 【wr456wr】
List of articles
Experimental environment
- ubuntu18.04 Virtual machines and a win10 Physical host
- Programming environment IDEA
- virtual machine ip:192.168.1.108
- JDK:1.8
Experimental content
Use Java Program a WordCount Program , And package the program into Jar The package executes in the virtual machine
use first IDEA Create a Maven project
stay pom.xml Import dependencies into the file and package them as Jar Package plug-ins :
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.4.11</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.11</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.4.11</version>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.MyProgramDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
Write the corresponding program :
MyProgramDriver Class is used to execute program entries :
import org.apache.hadoop.util.ProgramDriver;
public class MyProgramDriver {
public static void main(String[] args) {
int exitCode = -1;
ProgramDriver programDriver = new ProgramDriver();
try {
programDriver.addClass("com.WordCount", WordCount.class, "com.WordCount Program");
exitCode = programDriver.run(args);
} catch (Throwable e) {
throw new RuntimeException(e);
}
System.exit(exitCode);
}
}
;
WordCount Program :
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator var5 = values.iterator(); var5.hasNext(); sum += val.get()) {
val = (IntWritable)var5.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
;
Screenshot of project structure :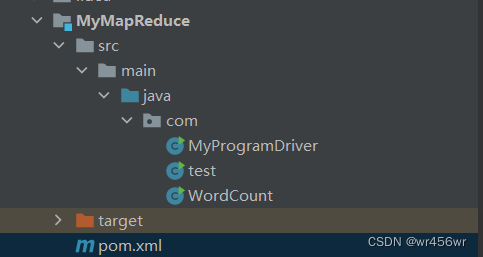
Click on the right maven Of package Package the project as Jar file 
The package file after the package is completed is in target Under the table of contents 
And then we'll pack it up Jar Packets are sent to the virtual machine , I am in /root/hadoop/a_dir Under the table of contents , Put it anywhere , But I need to know where it is 
;
Then write the input file input1 and input2, The contents are :
Then upload the two files to hadoop The system path of , I put it here hadoop Of /root/input Under the table of contents , Note that it is not a physical path , yes Hadoop Network path after startup 
;
Then execute the program :
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar com.WordCount /root/input/* /root/out
among a_dir/MyMapReduce-1.0-SNAPSHOT.jar It needs to be carried out Jar The path of the package ,com.WordCount It needs to be carried out WordCount Program name , The name is in the MyProgramDriver Name indicated in

/root/input/* Is the input file , /root/out Is the output path
;
Look at the output :
Programming to achieve file merging and de duplication operation
sample input :
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
The main idea : Use map Use regular to split each line of the file into key,value , Such as the 20150101 x After the split key by 20150101,value by x, The type is Text type , take map Treated by shuffle Process to reduce To deal with , stay reduce Internal use HashSet The de duplication characteristic of ( stay HashSet The elements in the do not repeat ) De duplicate the entered value .
;
Merge Program code :
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
public class Merge {
public Merge() {
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: merge <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "merge");
job.setJarByClass(Merge.class);
job.setMapperClass(Merge.MyMapper.class);
job.setCombinerClass(Merge.MyReduce.class);
job.setReducerClass(Merge.MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class MyMapper extends Mapper<Object, Text, Text, Text> {
public MyMapper() {
}
@Override
public void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line = value.toString();
// Match blanks
String[] split = line.split("\\s+");
if (split.length <= 1) {
return;
}
context.write(new Text(split[0]), new Text(split[1]));
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
public MyReduce() {
}
@Override
public void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
// Use HashSet Carry out de duplication operation
HashSet<String> hashSet = new HashSet<>();
Iterator<Text> iterator = values.iterator();
while (iterator.hasNext()) {
hashSet.add(iterator.next().toString());
}
Iterator<String> hashIt = hashSet.iterator();
while (hashIt.hasNext()) {
Text val = new Text(hashIt.next());
context.write(key, val);
}
}
}
}
take Merge Program write MyProgramDriver class :
import org.apache.hadoop.util.ProgramDriver;
public class MyProgramDriver {
public static void main(String[] args) {
int exitCode = -1;
ProgramDriver programDriver = new ProgramDriver();
try {
programDriver.addClass("com.WordCount", WordCount.class, "com.WordCount Program");
programDriver.addClass("Merge", Merge.class, "xll");
exitCode = programDriver.run(args);
} catch (Throwable e) {
throw new RuntimeException(e);
}
System.exit(exitCode);
}
}
Package the program and send it to the virtual machine , Run the program :
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar Merge /root/input/* /root/out
Running results :
Program to sort the input files
Ideas : stay Map The end separates the values to form <key,1> Such key value pairs , Because the sort is MapReduce Default action for , So in Reduce The end only needs to Map Output the value separated from the terminal , take Map Terminal key Value is set to Reduce Terminal value value .
MyConf Class code :
Here, I have extracted the general configuration required , Reduce code duplication in the future
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class MyConf {
public static void setConf(Class mainClass,Class outKeyClass, Class outValueClass, String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("otherArgs length error, length < 2");
System.exit(2);
}
Job job = Job.getInstance(conf, mainClass.getName());
Class[] innerClass = mainClass.getClasses();
for (Class c : innerClass) {
if (c.getSimpleName().equals("MyReduce")) {
job.setReducerClass(c);
// job.setCombinerClass(c);
} else if (c.getSimpleName().equals("MyMapper")) {
job.setMapperClass(c);
}
}
job.setJarByClass(mainClass);
job.setOutputKeyClass(outKeyClass);
job.setOutputValueClass(outValueClass);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
;
Sort class :
import com.utils.MyConf;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class Sort {
public Sort() {
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
MyConf.setConf(Sort.class, IntWritable.class, IntWritable.class, args);
}
public static class MyMapper extends Mapper<Object, org.apache.hadoop.io.Text, IntWritable, IntWritable> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
String var = value.toString();
context.write(new IntWritable(Integer.parseInt(var.trim())), new IntWritable(1));
}
}
public static class MyReduce extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> {
static int sort = 1;
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for (IntWritable va : values) {
context.write(new IntWritable(sort), key);
sort++;
}
}
}
}
And then Sort Class injection MyProgramDriver Class is OK 
Program input :
After packaging, put it into the virtual machine to run
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar Sort /root/input* /root/out5
Running results :
Information mining for a given table
Ideas :( Reference resources ), for instance :
steven lucy
lucy mary
This input goes through map(map Refer to the following code for the specific logic of ) Get output after coming out :
<steven,old#lucy>,<lucy,young#steven>,<lucy,old#mary>,<mary,young#lucy>,
After that shuffle After processing, you get input :
<steven,old#lucy>,<lucy,<young#steven,old#mary>>,<mary,young#lucy>,
Then each key value pair is treated as Reduce End input
<lucy,<young#steven,old#mary>> Key value pairs pass through reduce A valid output is obtained after the logic processing of :
<steven, mary>
InfoFind class :
package com;
import com.utils.MyConf;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
public class InfoFind {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, InstantiationException, IllegalAccessException {
MyConf.setConf(InfoFind.class, Text.class, Text.class, args);
}
public static class MyMapper extends Mapper<Object, Text, Text, Text> {
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] splStr = value.toString().split("\\s+");
String child = splStr[0];
String parent = splStr[1];
if (child.equals("child") && parent.equals("parent"))
return;
context.write(new Text(child), new Text("old#" + parent));
context.write(new Text(parent), new Text("young#" + child));
}
}
public static class MyReduce extends Reducer<Text, Text, Text, Text> {
private static boolean head = true ;
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException
{
if(head)
{
context.write(new Text("grandchild"), new Text("grandparent"));
head = false;
}
ArrayList<String> grandchild = new ArrayList<>();
ArrayList<String> grandparent = new ArrayList<>();
String[] temp;
for(Text val:values)
{
temp = val.toString().split("#");
if(temp[0].equals("young"))
grandchild.add(temp[1]);
else
grandparent.add(temp[1]);
}
for(String gc:grandchild)
for(String gp:grandparent)
context.write(new Text(gc), new Text(gp));
}
}
}
Input :
function :
bin/hadoop jar a_dir/MyMapReduce-1.0-SNAPSHOT.jar InfoFind /root/input/* /root/out6
Output :
Reference material
https://blog.csdn.net/u013384984/article/details/80229459 ( One a key Content )
https://blog.csdn.net/qq_43310845/article/details/123298811
https://blog.csdn.net/zhangwenbingbingyu/article/details/52210348
https://www.cnblogs.com/ginkgo-/p/13273671.html
边栏推荐
- plot_ Model error: pydot and graphviz are not installed
- What are the requirements for customizing the slip ring for UAV
- Introduction to memory model of JVM
- From small to large, why do you always frown when talking about learning
- [description] solution to JMeter garbled code
- 现在炒股网上开户安全吗?新手刚上路,求答案
- Overview and construction of redis master-slave replication, sentinel mode and cluster
- Which securities speculation account opening commission is the cheapest and safest
- Meituan dynamic thread pool practice idea has been open source
- Set集合用法
猜你喜欢

药物发现综述-01-药物发现概述

How to add live chat in your Shopify store?

【说明】Jmeter乱码的解决方法
Leetcode 720. The longest word in the dictionary

Taro---day1---搭建项目

JVM的内存模型简介
SQL Server 2016 detailed installation tutorial (with registration code and resources)

Why stainless steel swivel
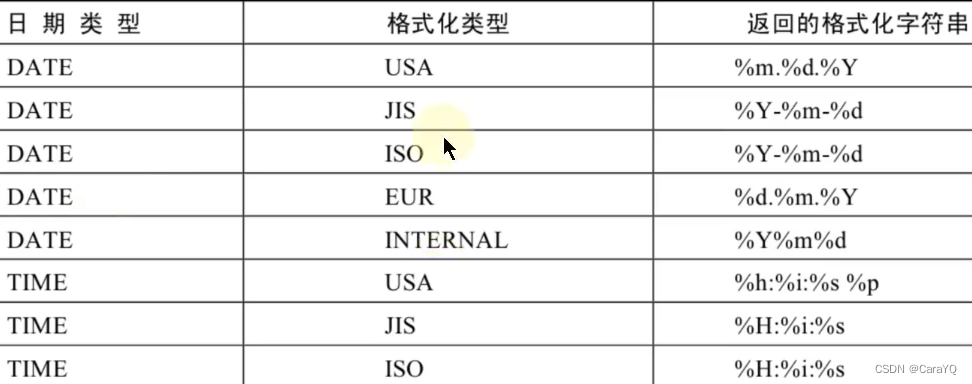
【MySQL】-【函数】

Overview and construction of redis master-slave replication, sentinel mode and cluster
随机推荐
Efficient supplier management in supply chain
What is the application scope and function of the conductive slip ring of single crystal furnace
Is it reliable to invest in exchange traded ETF funds? Is it safe to invest in exchange traded ETF funds
How to build dual channel memory for Lenovo Savior r720
【开源】开源系统整理-考试问卷等
大尺寸导电滑环市场应用强度如何
Want to open an account to buy stock, is it safe to open an account on the Internet?
Taro---day1---搭建项目
打新债注册账户安全吗,会有风险吗?
Class文件结构和字节码指令集
Summary of attack methods of attack team
Is it safe to open a stock account online now? Select a listed securities firm, and the fastest time to open an account is 8 minutes
PostgreSQL设置自增字段
完全二叉树的节点个数[非O(n)求法 -> 抽象二分]
lefse分析本地实现方法带全部安装文件和所有细节,保证成功。
如何阅读一篇论文
The contents of the latex table are left, middle and right
有监督、无监督与半监督学习
Esxi based black Qunhui DSM 7.0.1 installation of VMware Tools
Ai+ clinical trial patient recruitment | massive bio completed round a financing of $9million