当前位置:网站首页>Illustration of ONEFLOW's learning rate adjustment strategy
Illustration of ONEFLOW's learning rate adjustment strategy
2022-06-23 14:22:00 【InfoQ】
1、 background

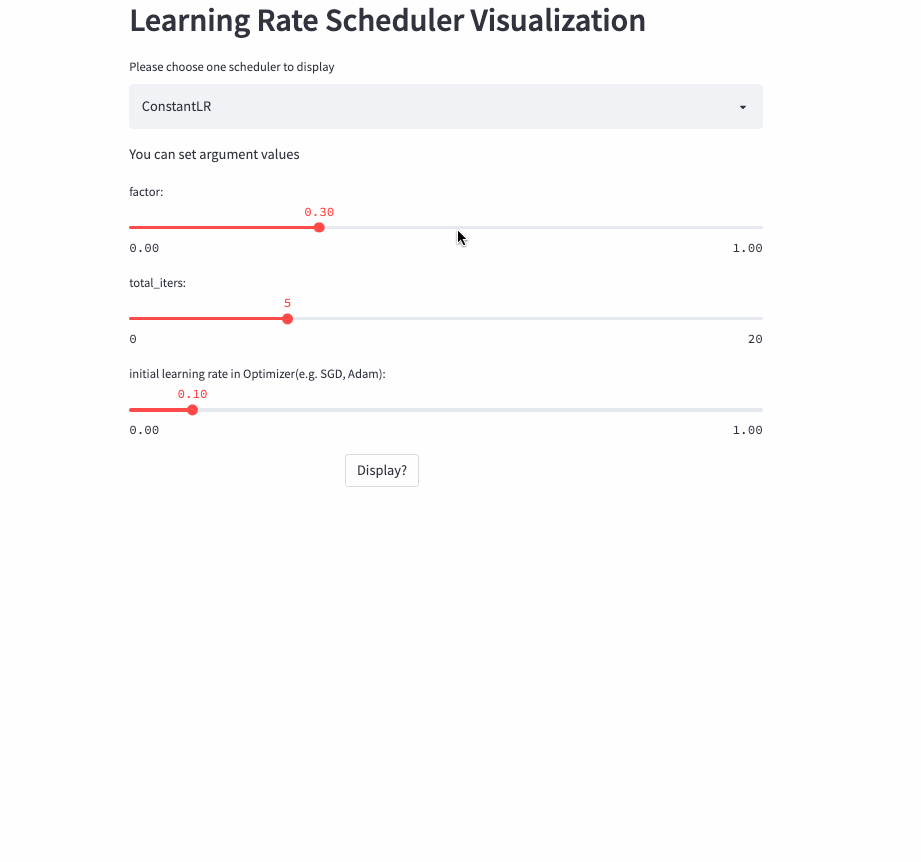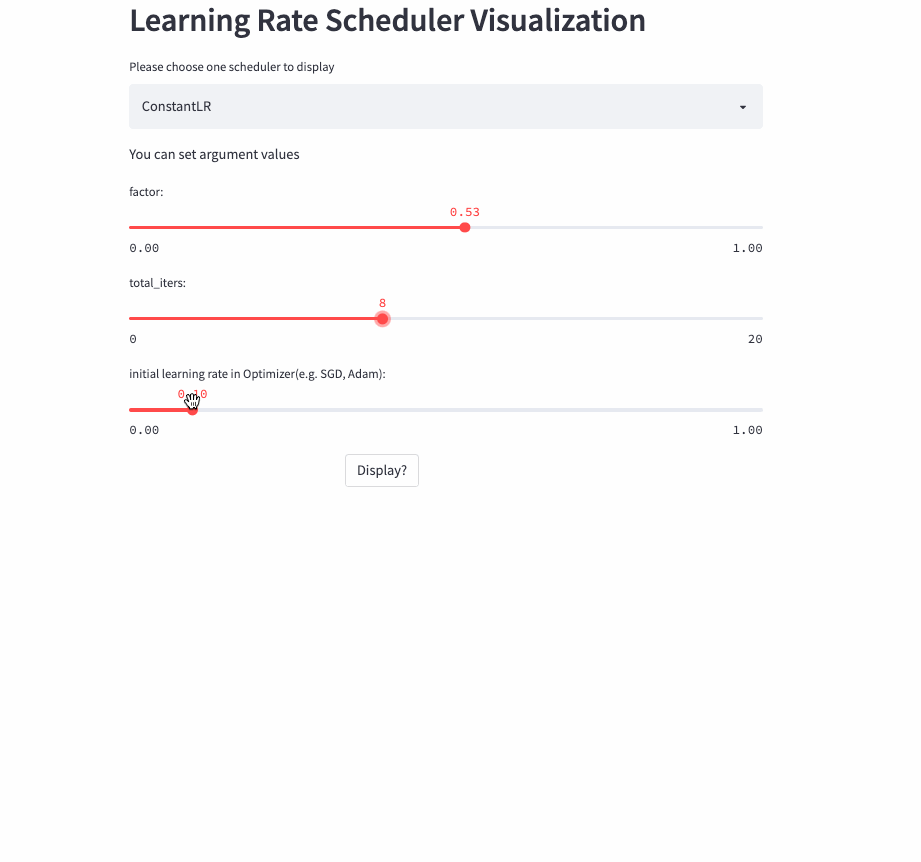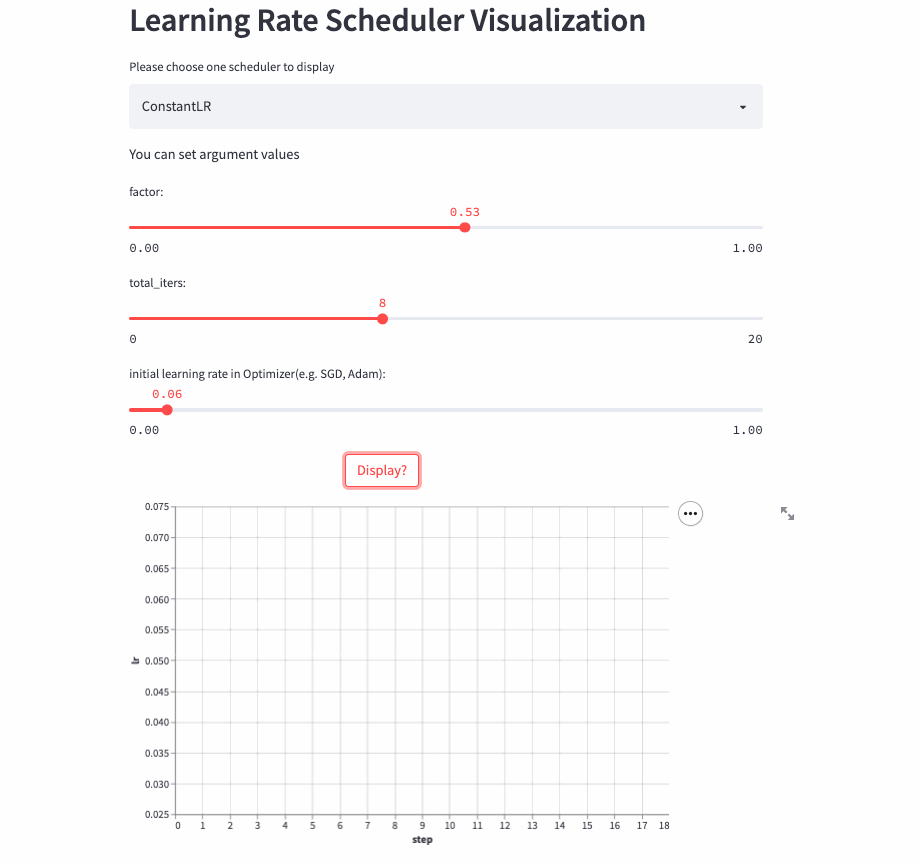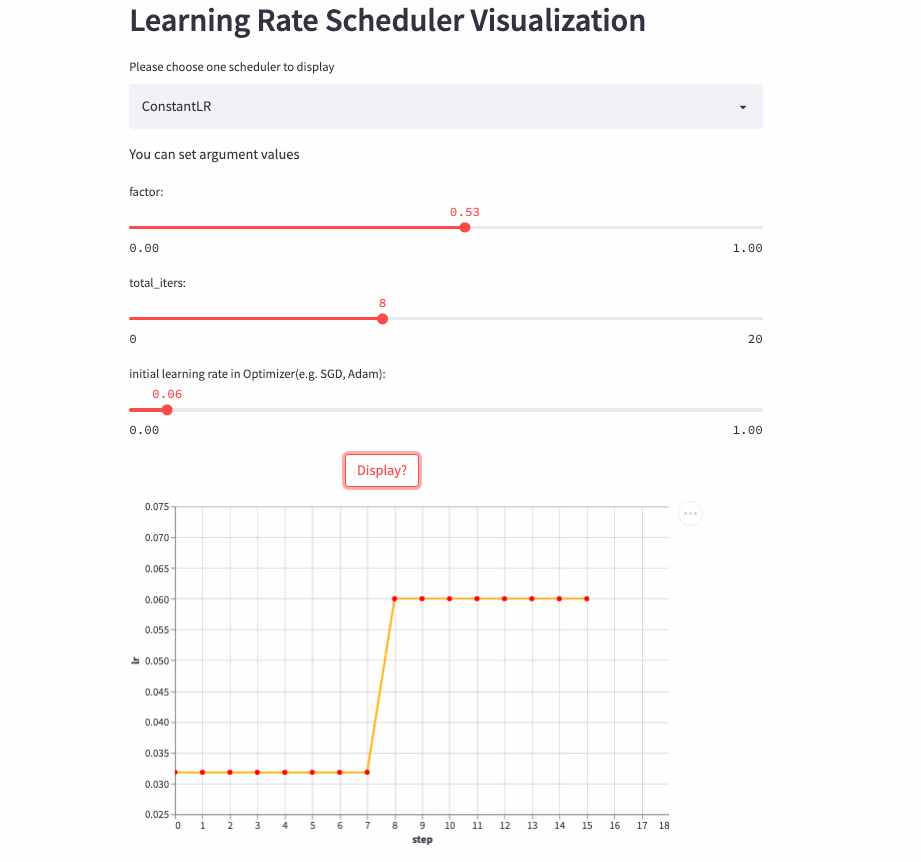
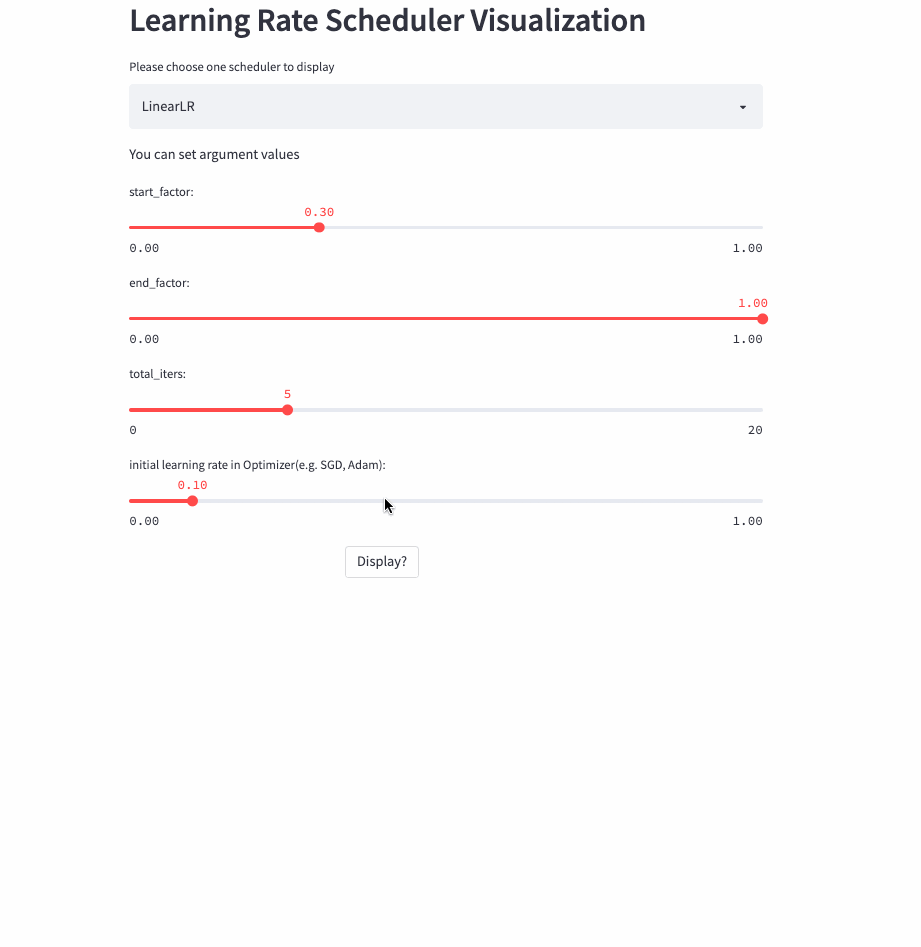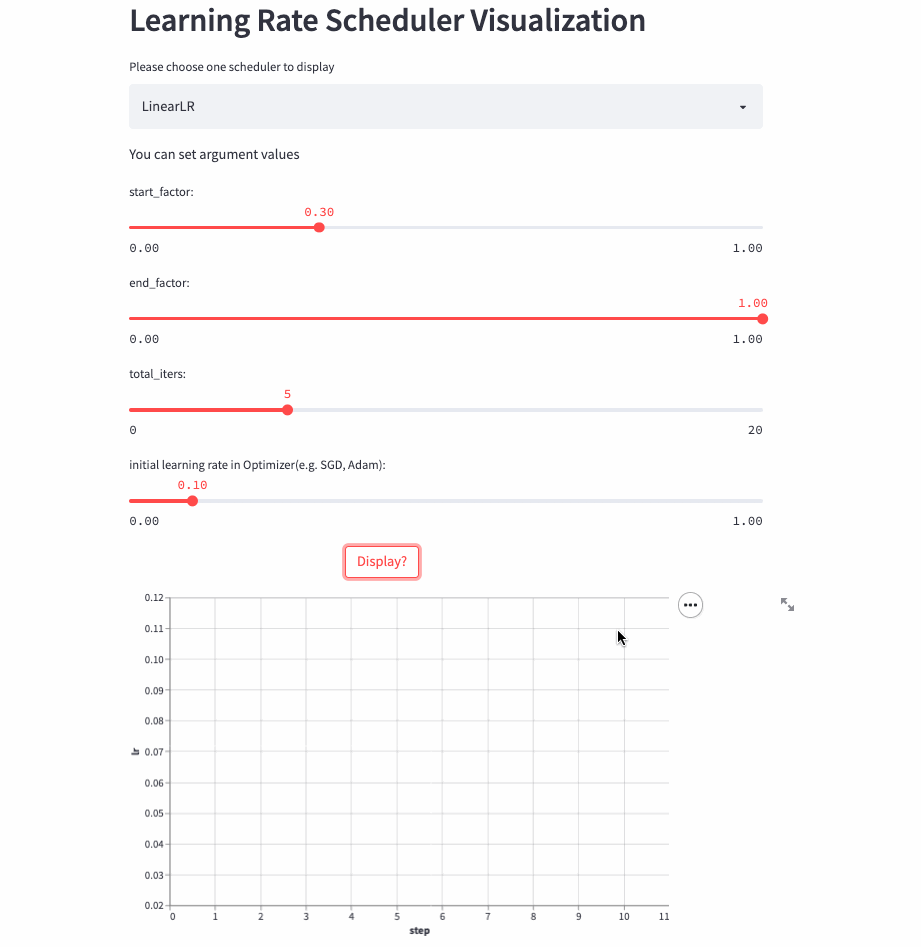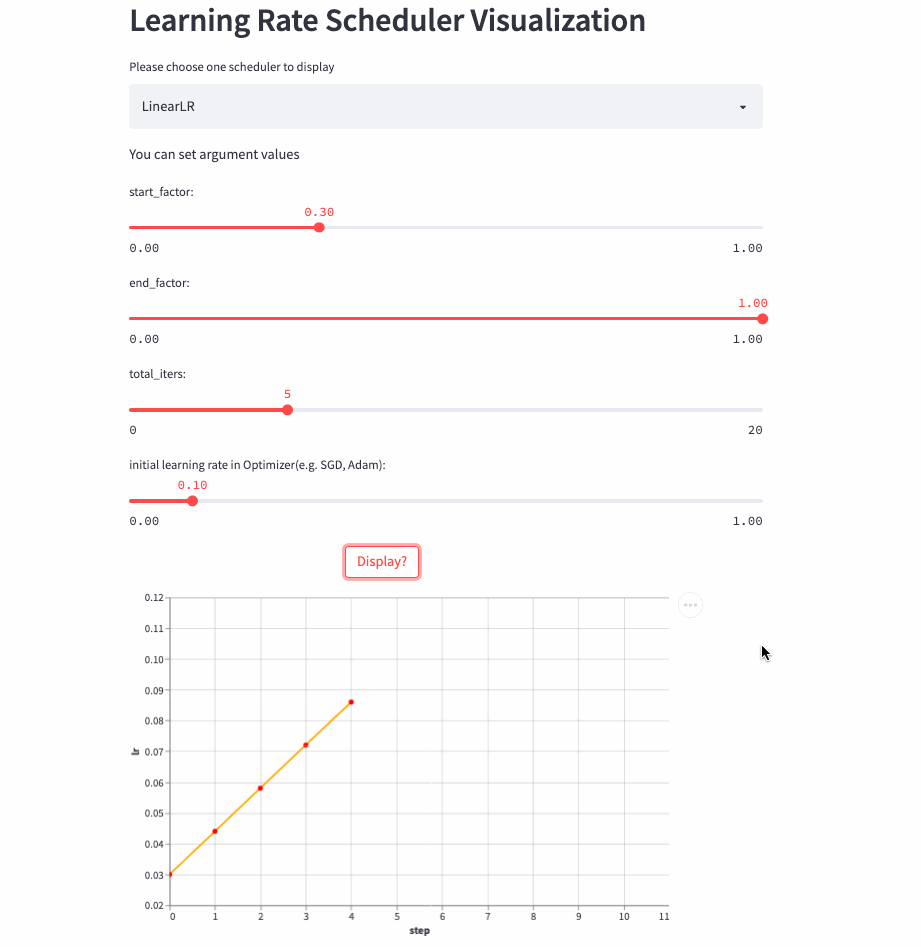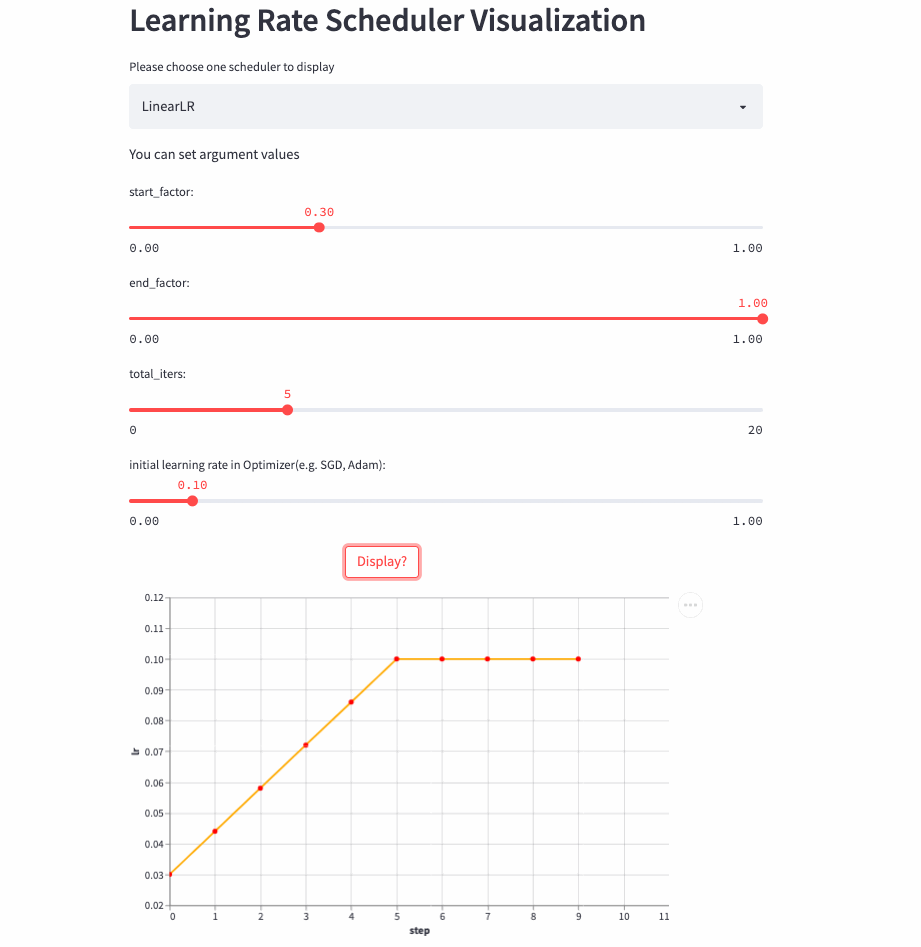
- https://huggingface.co/spaces/basicv8vc/learning-rate-scheduler-online
- https://share.streamlit.io/basicv8vc/scheduler-online
2、 Learning rate adjustment strategies
Base class LRScheduler
ConstantLR
oneflow.optim.lr_scheduler.ConstantLR(
optimizer: Optimizer,
factor: float = 1.0 / 3,
total_iters: int = 5,
last_step: int = -1,
verbose: bool = False,
)LinearLR
oneflow.optim.lr_scheduler.LinearLR(
optimizer: Optimizer,
start_factor: float = 1.0 / 3,
end_factor: float = 1.0,
total_iters: int = 5,
last_step: int = -1,
verbose: bool = False,
)
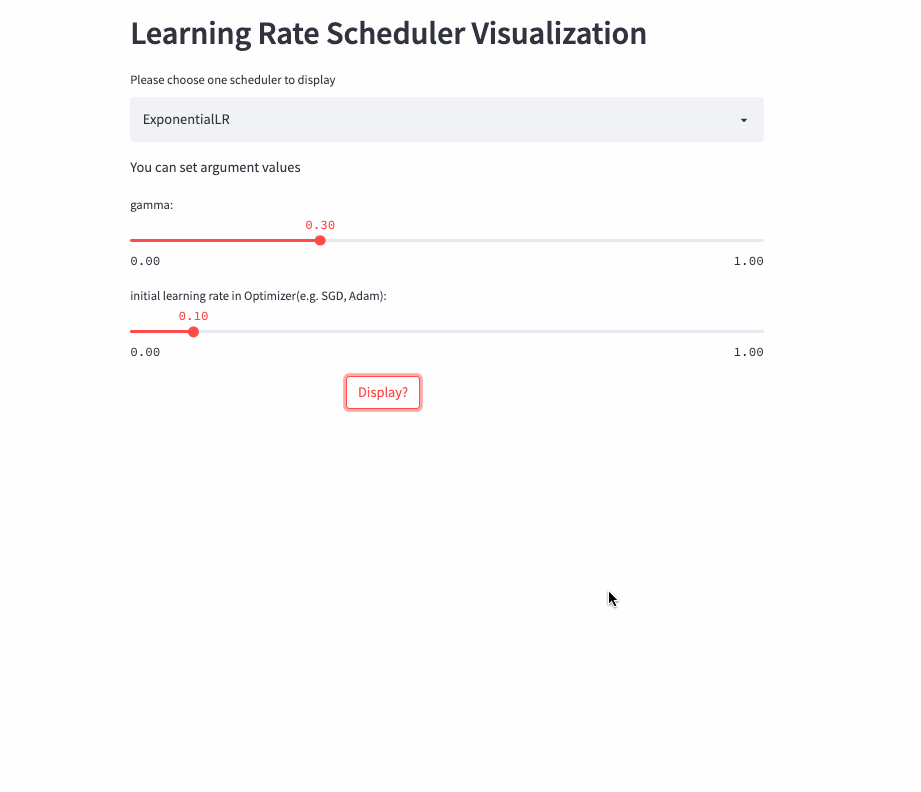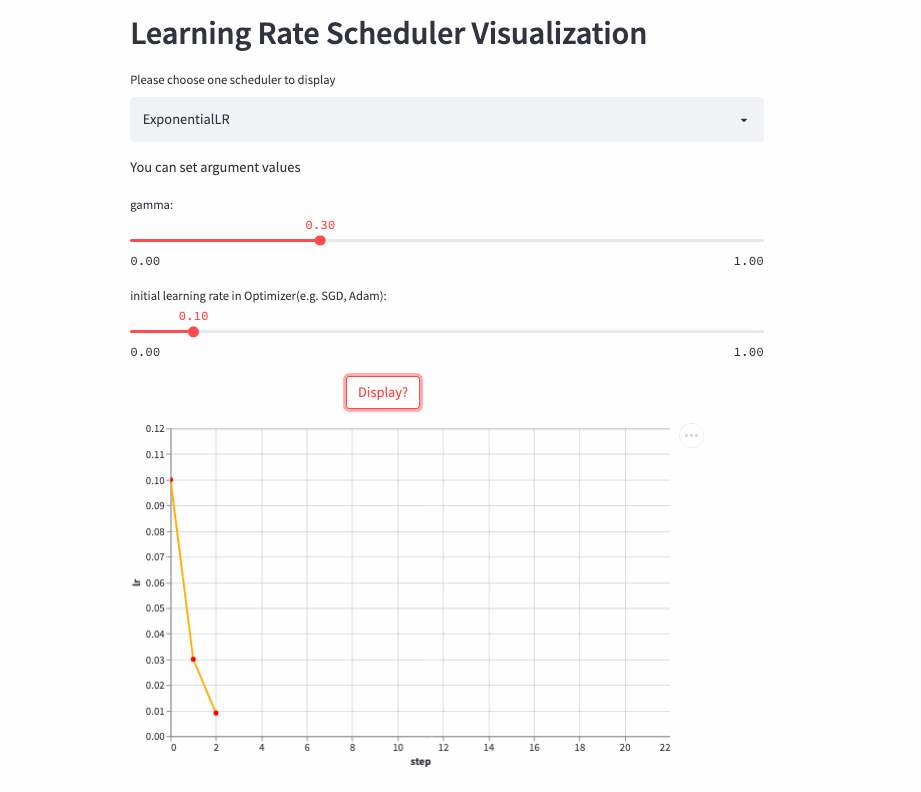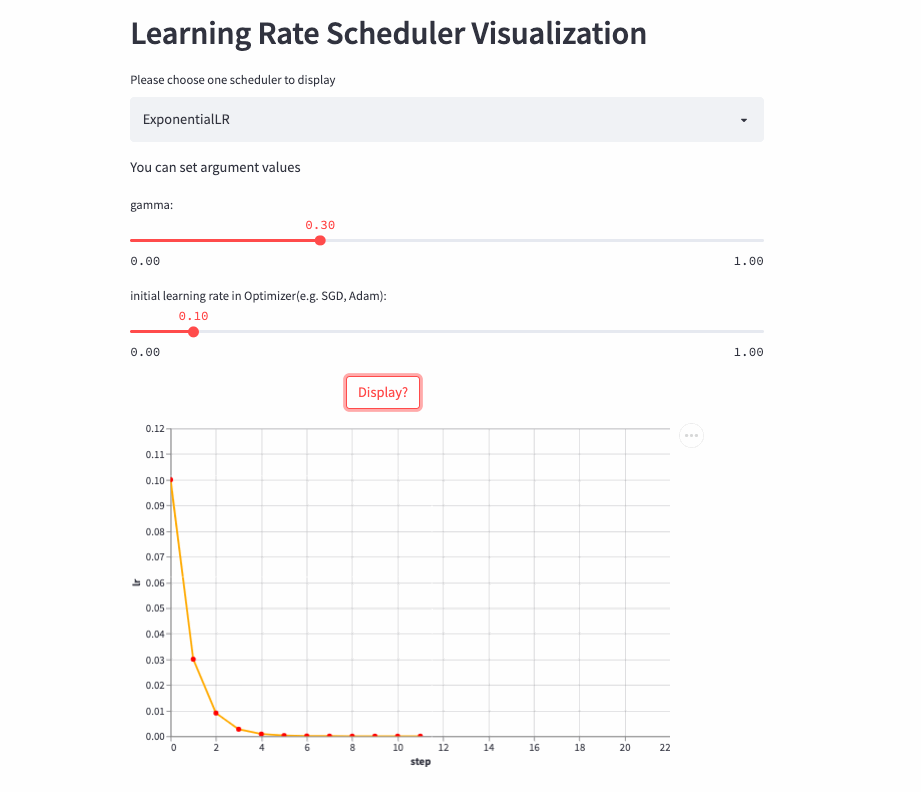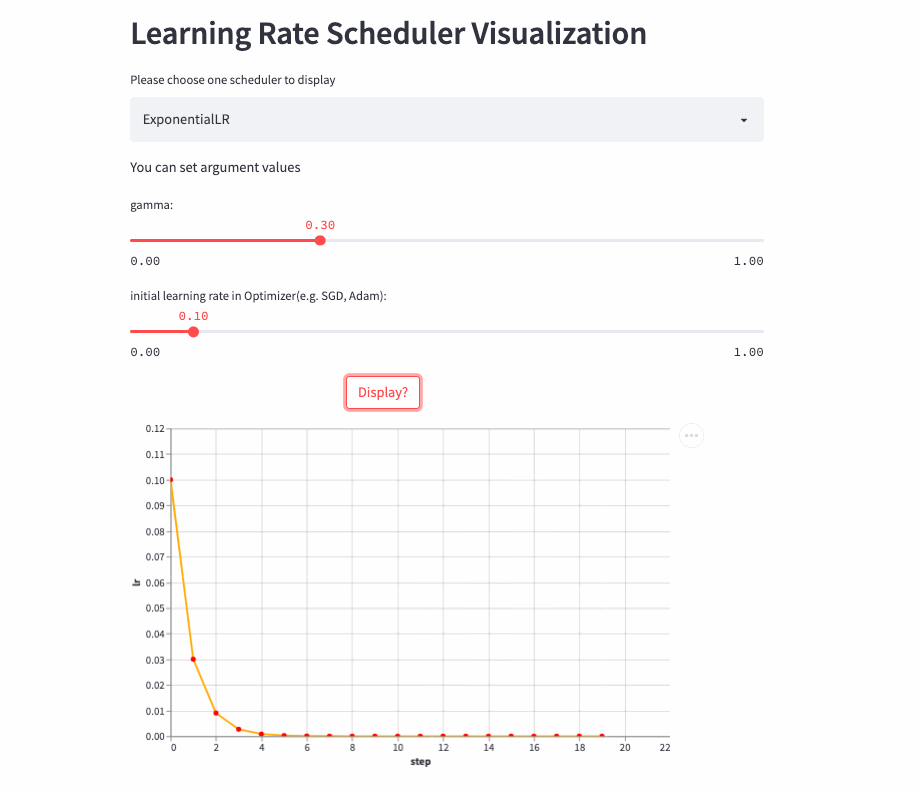
ExponentialLR
oneflow.optim.lr_scheduler.ExponentialLR(
optimizer: Optimizer,
gamma: float,
last_step: int = -1,
verbose: bool = False,
)
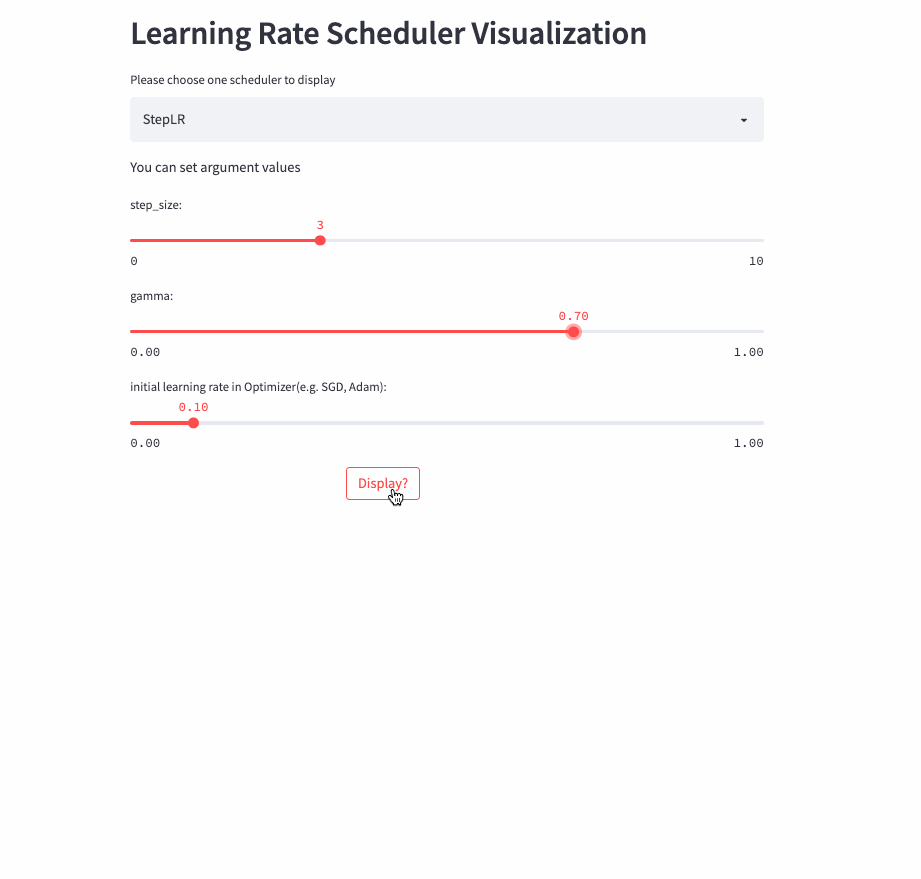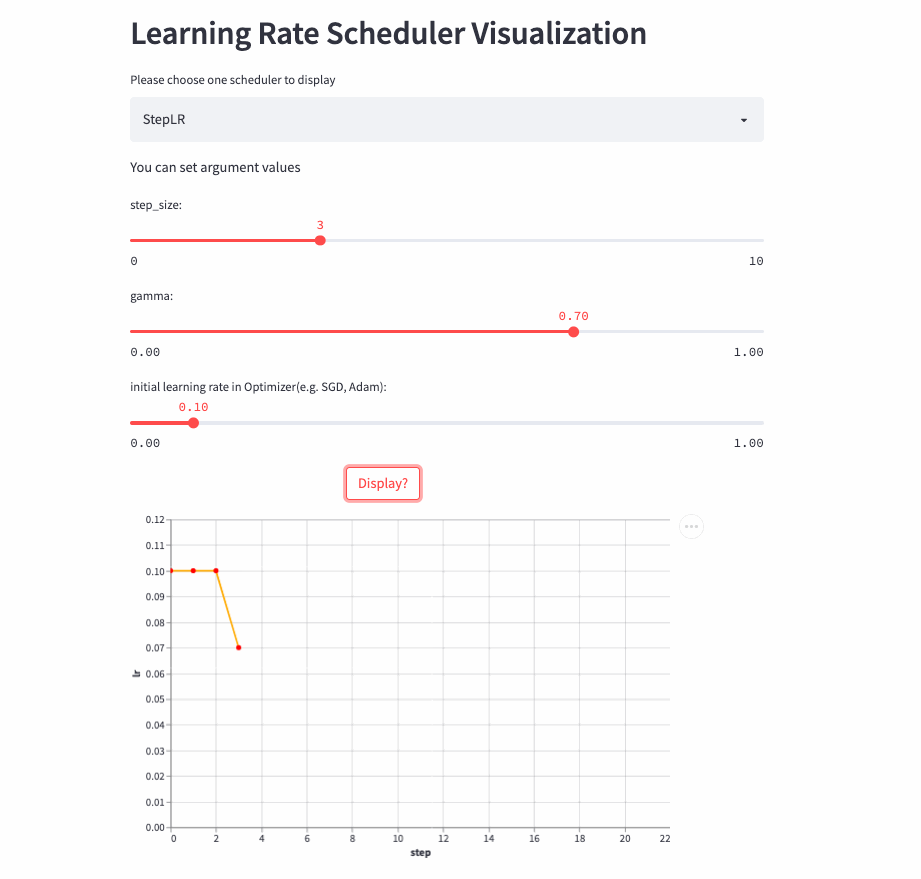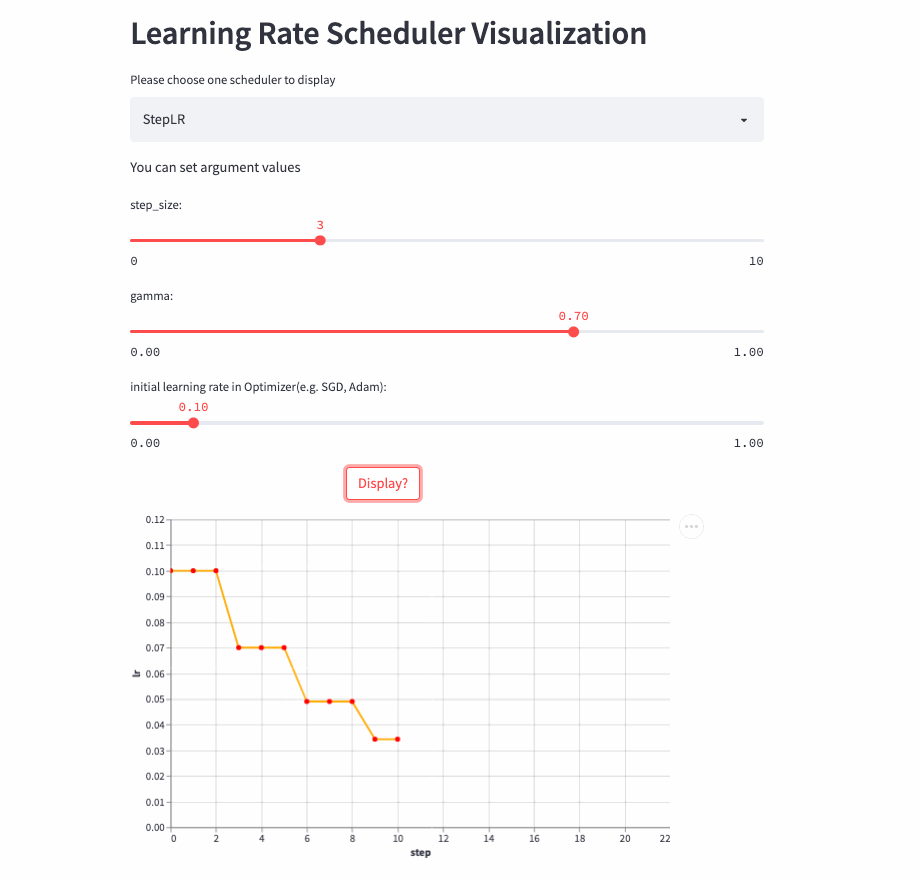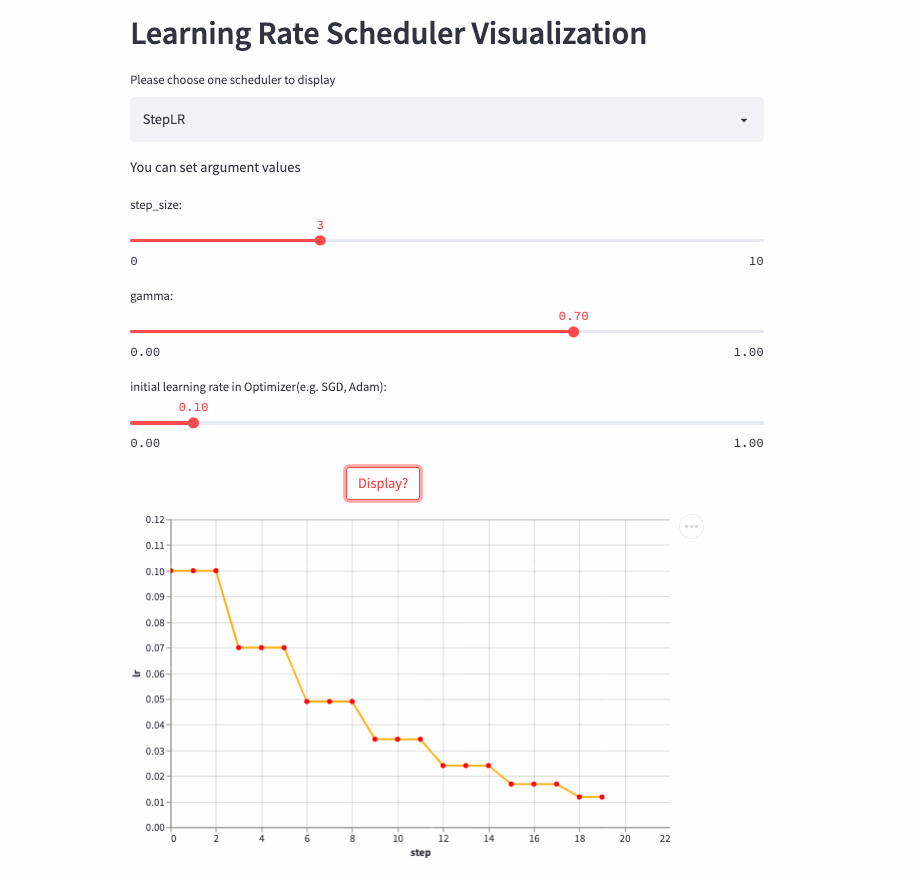
StepLR
oneflow.optim.lr_scheduler.StepLR(
optimizer: Optimizer,
step_size: int,
gamma: float = 0.1,
last_step: int = -1,
verbose: bool = False,
)
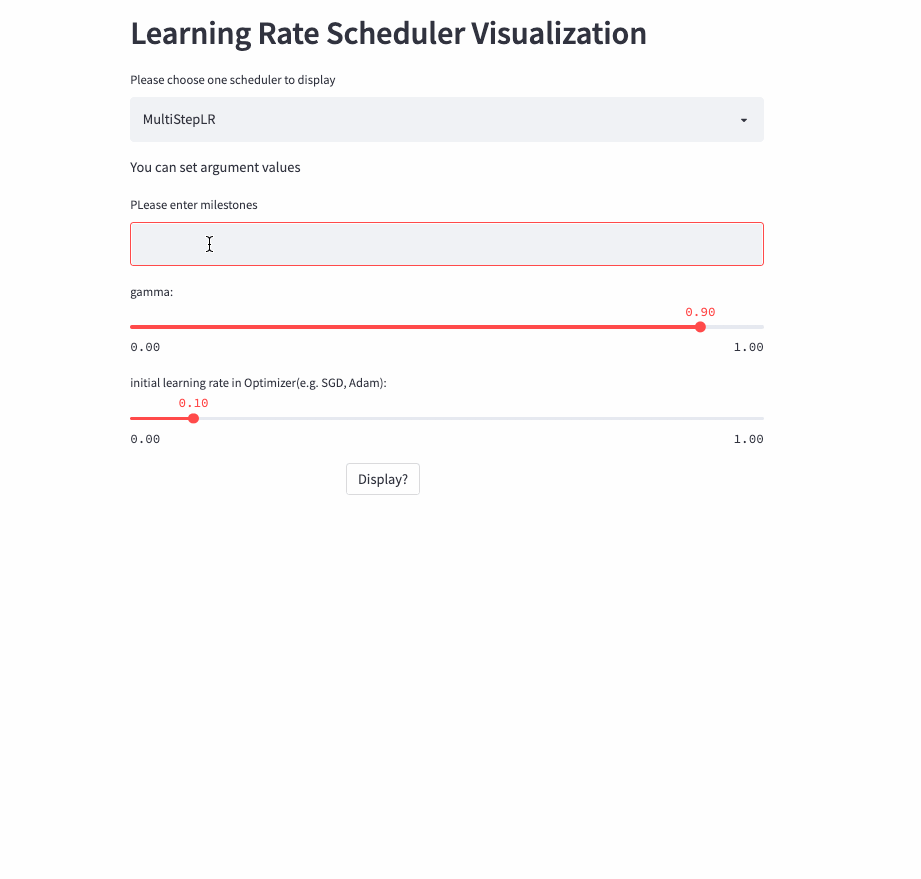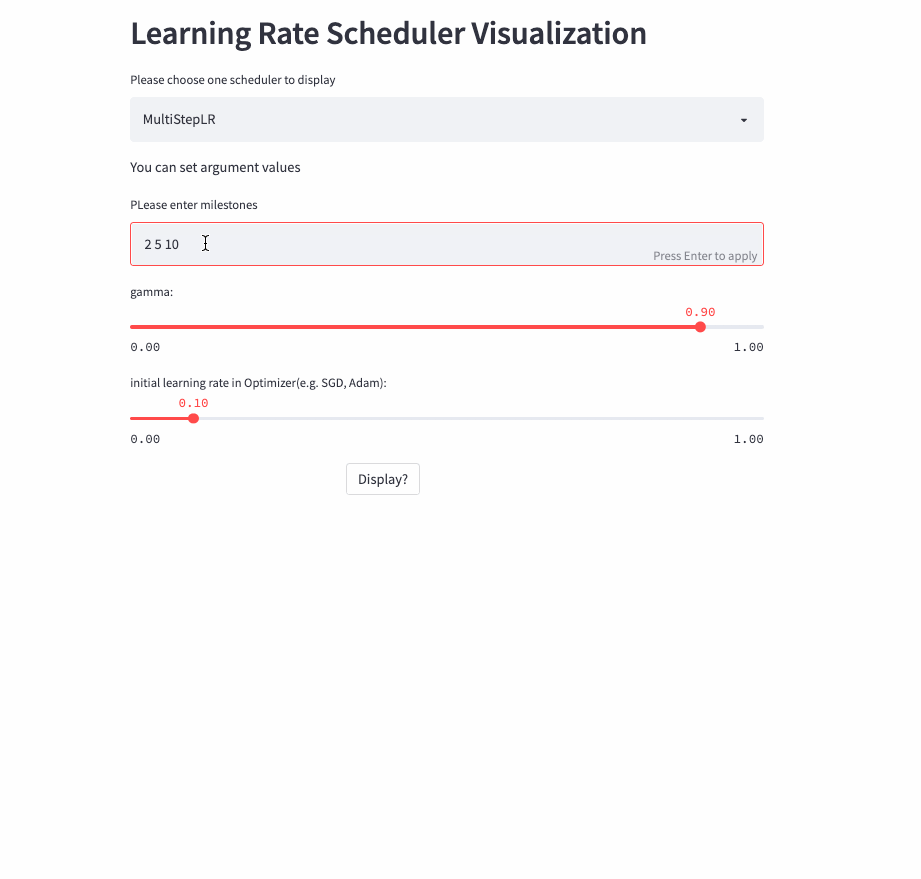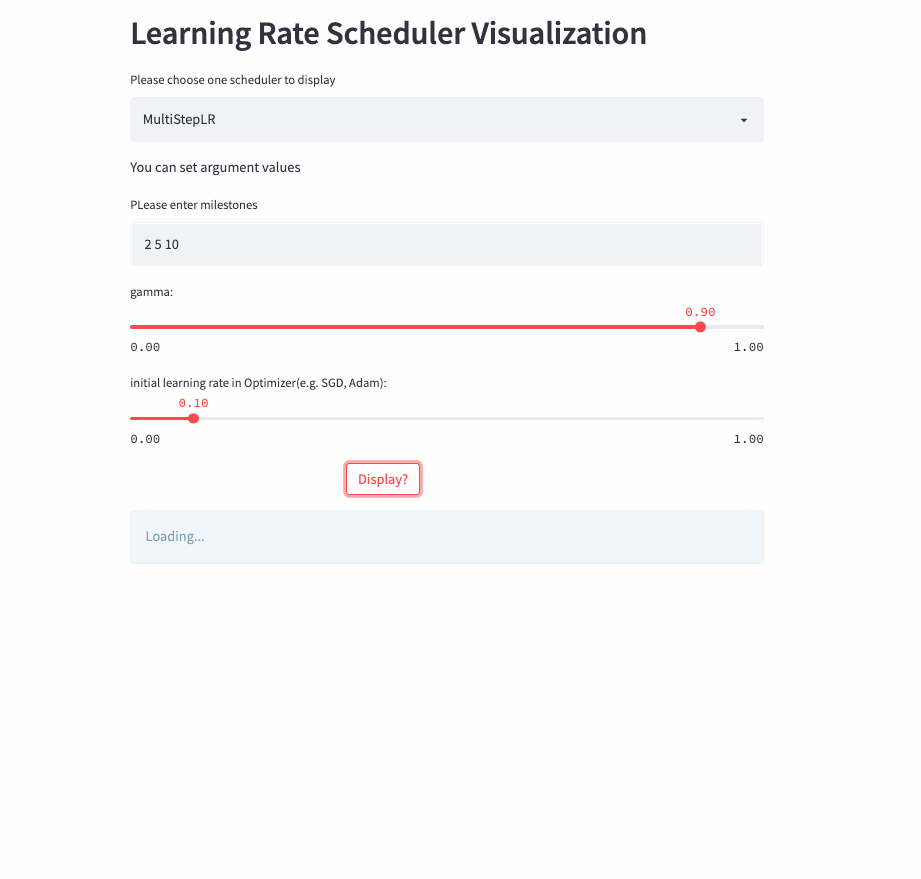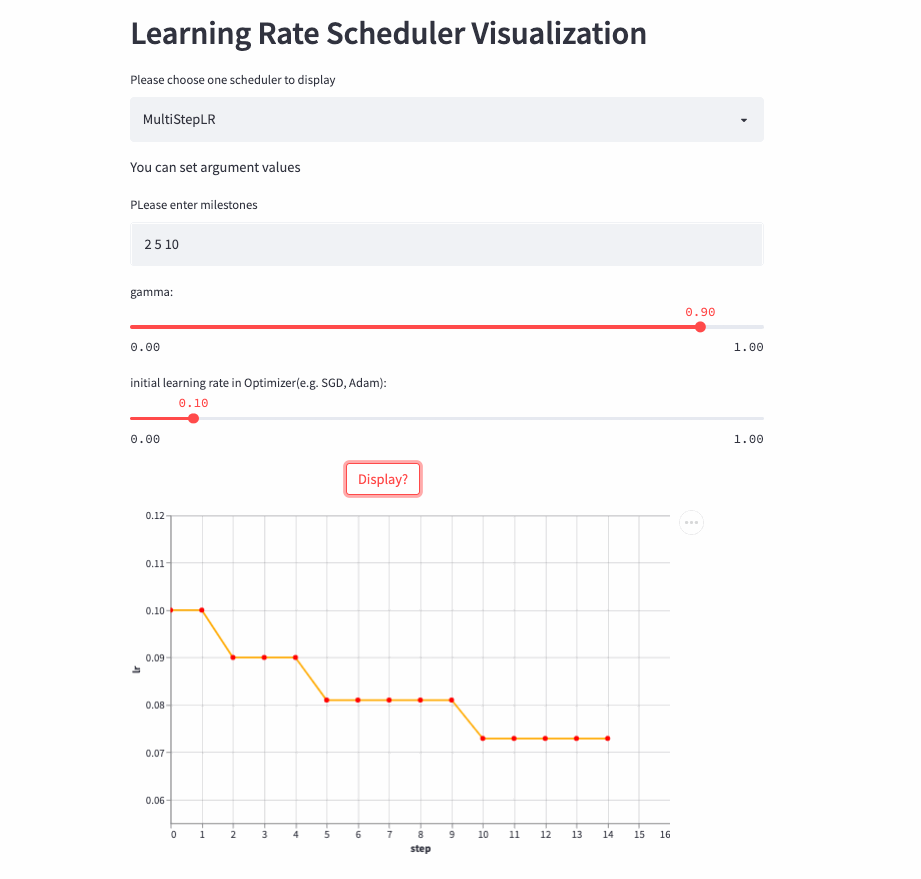
MultiStepLR
oneflow.optim.lr_scheduler.MultiStepLR(
optimizer: Optimizer,
milestones: list,
gamma: float = 0.1,
last_step: int = -1,
verbose: bool = False,
)
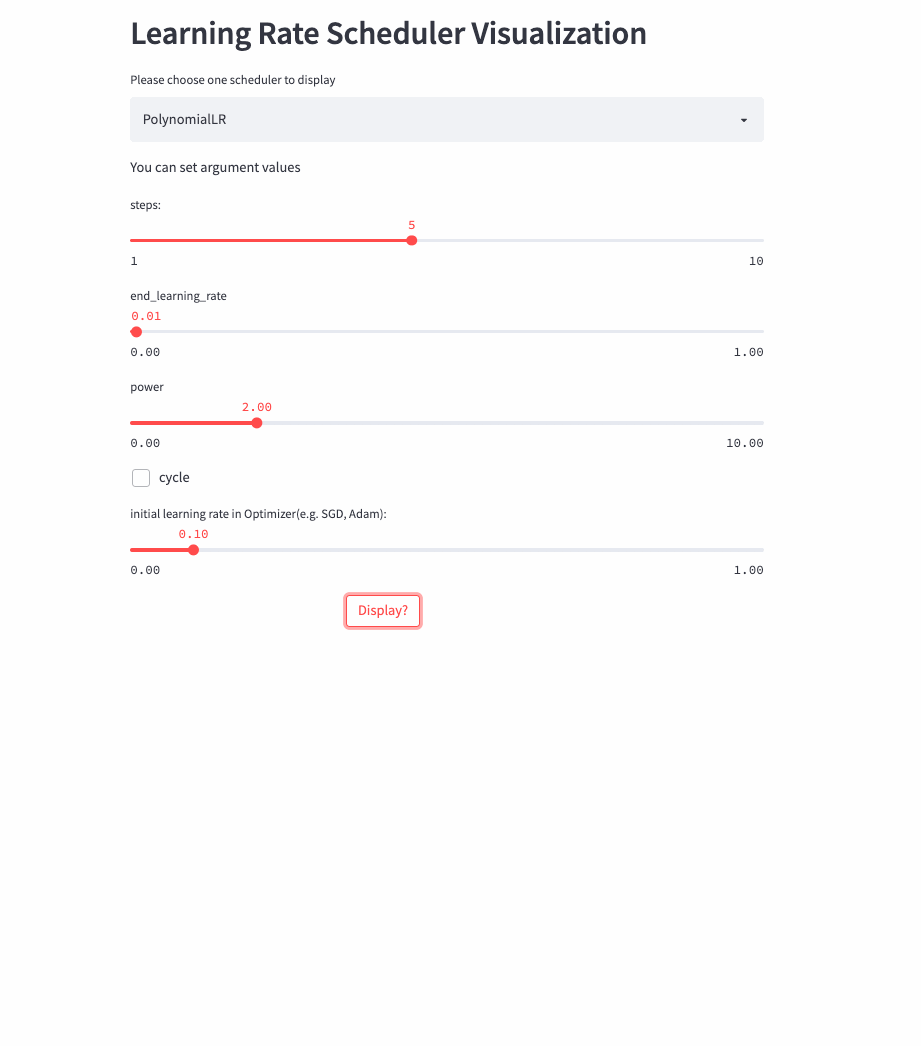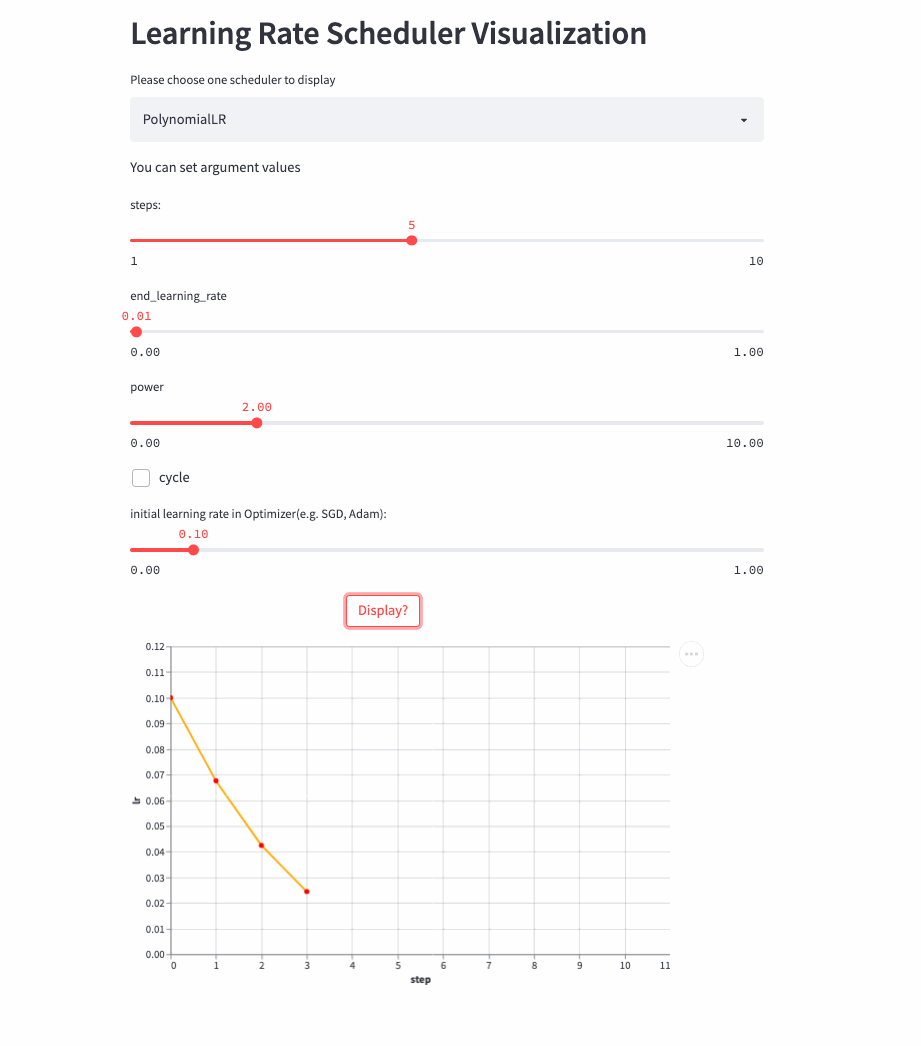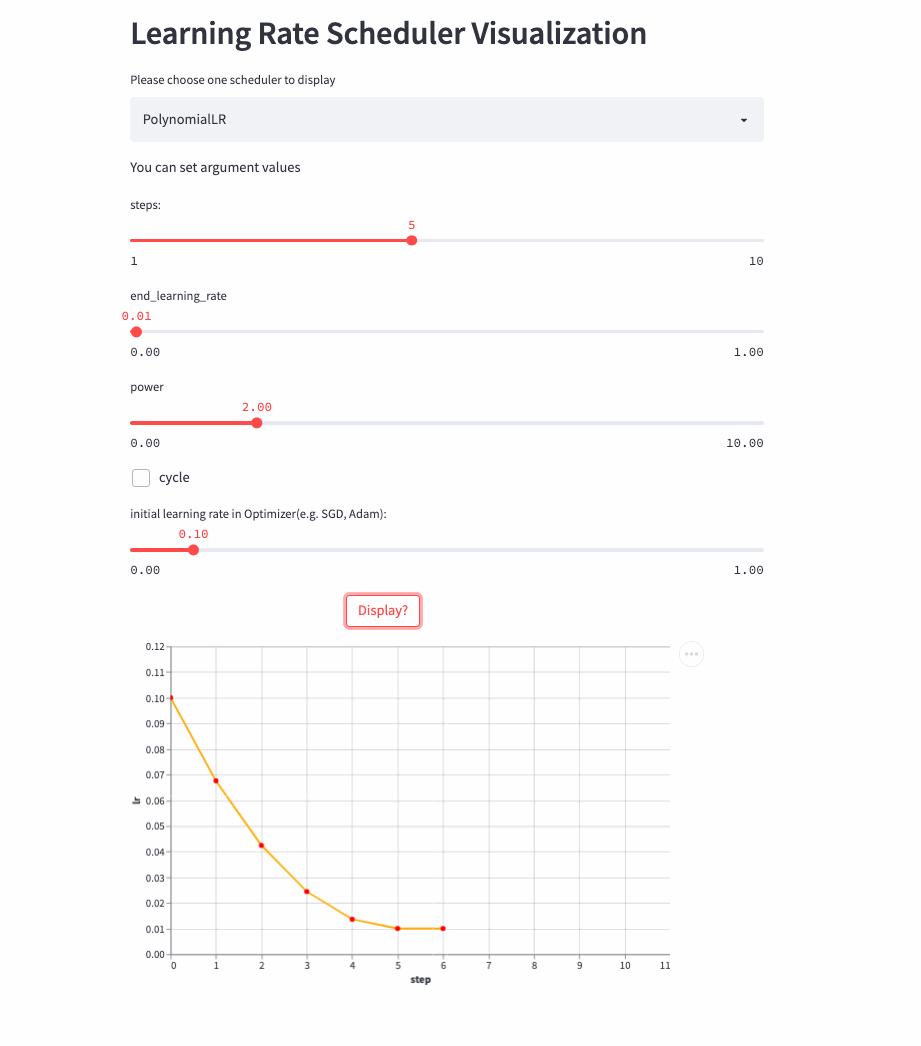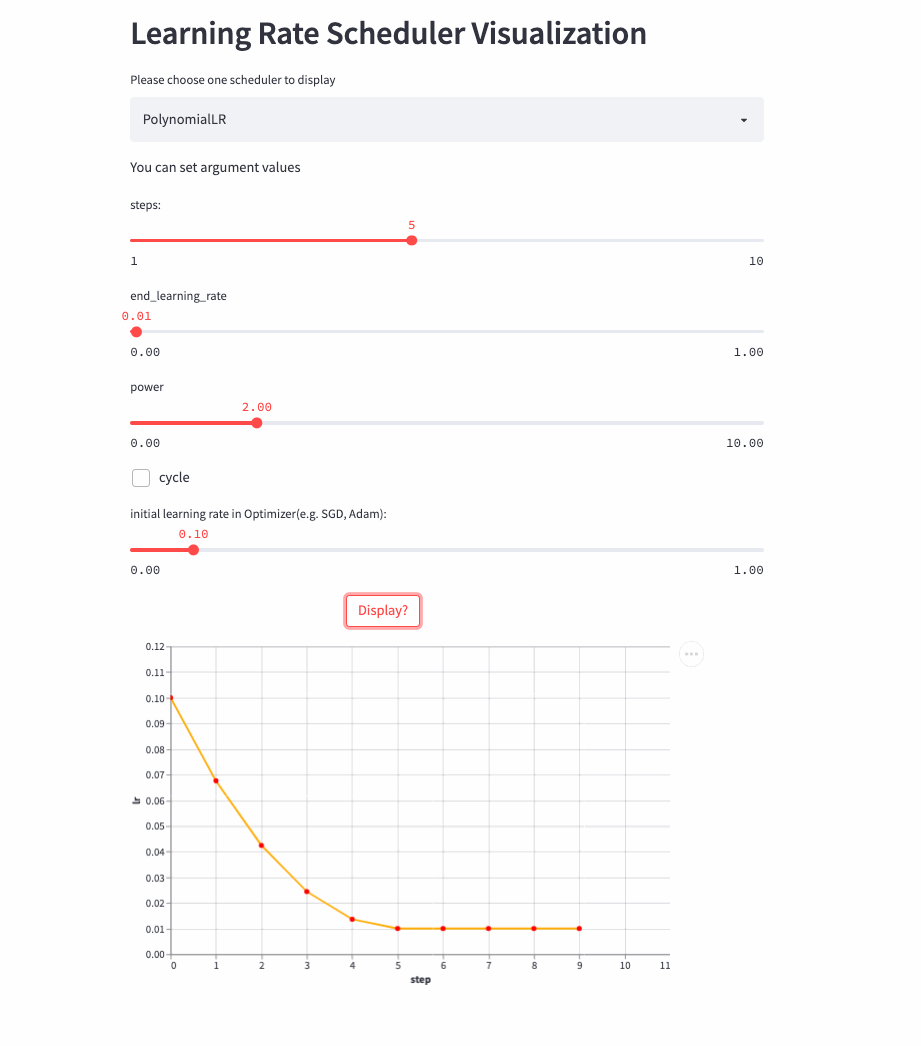
PolynomialLR
oneflow.optim.lr_scheduler.PolynomialLR(
optimizer,
steps: int,
end_learning_rate: float = 0.0001,
power: float = 1.0,
cycle: bool = False,
last_step: int = -1,
verbose: bool = False,
)



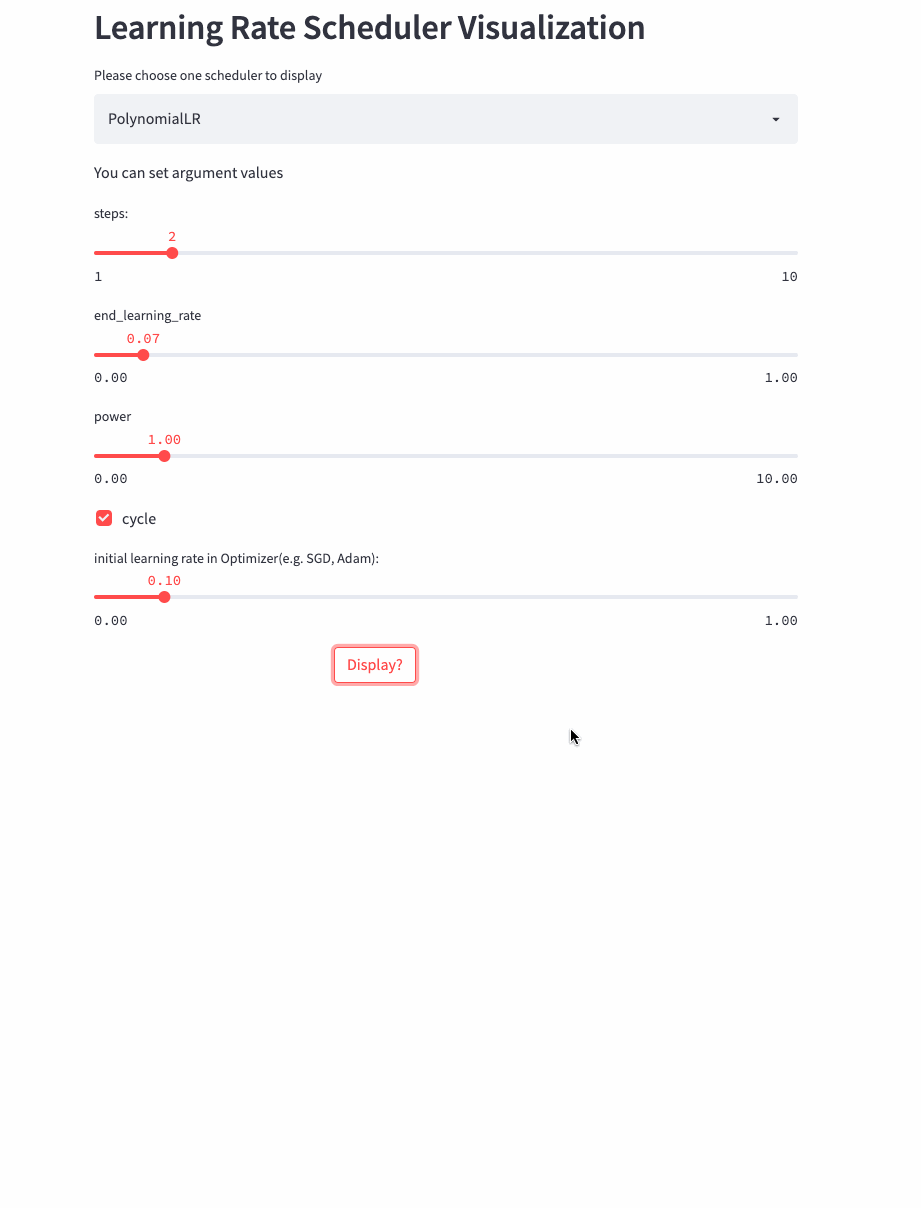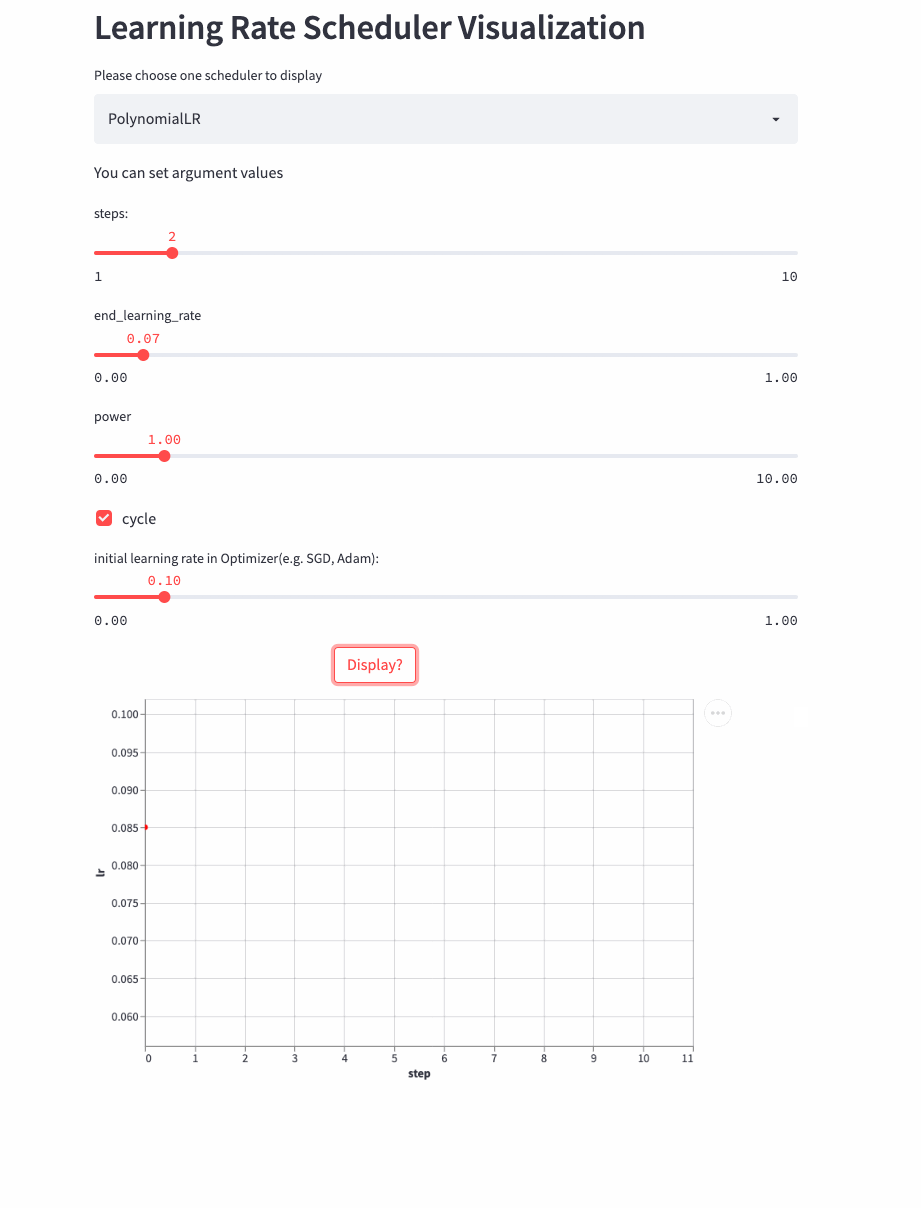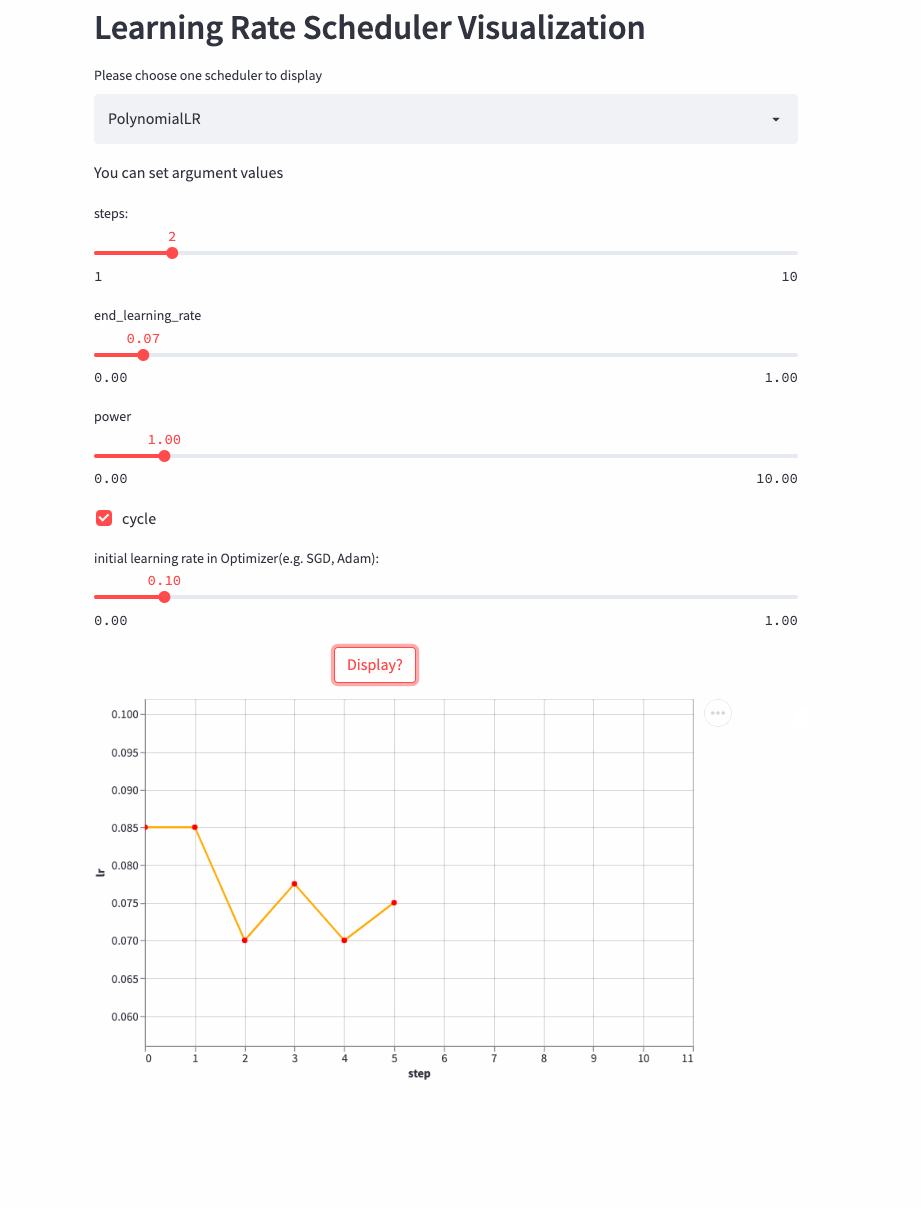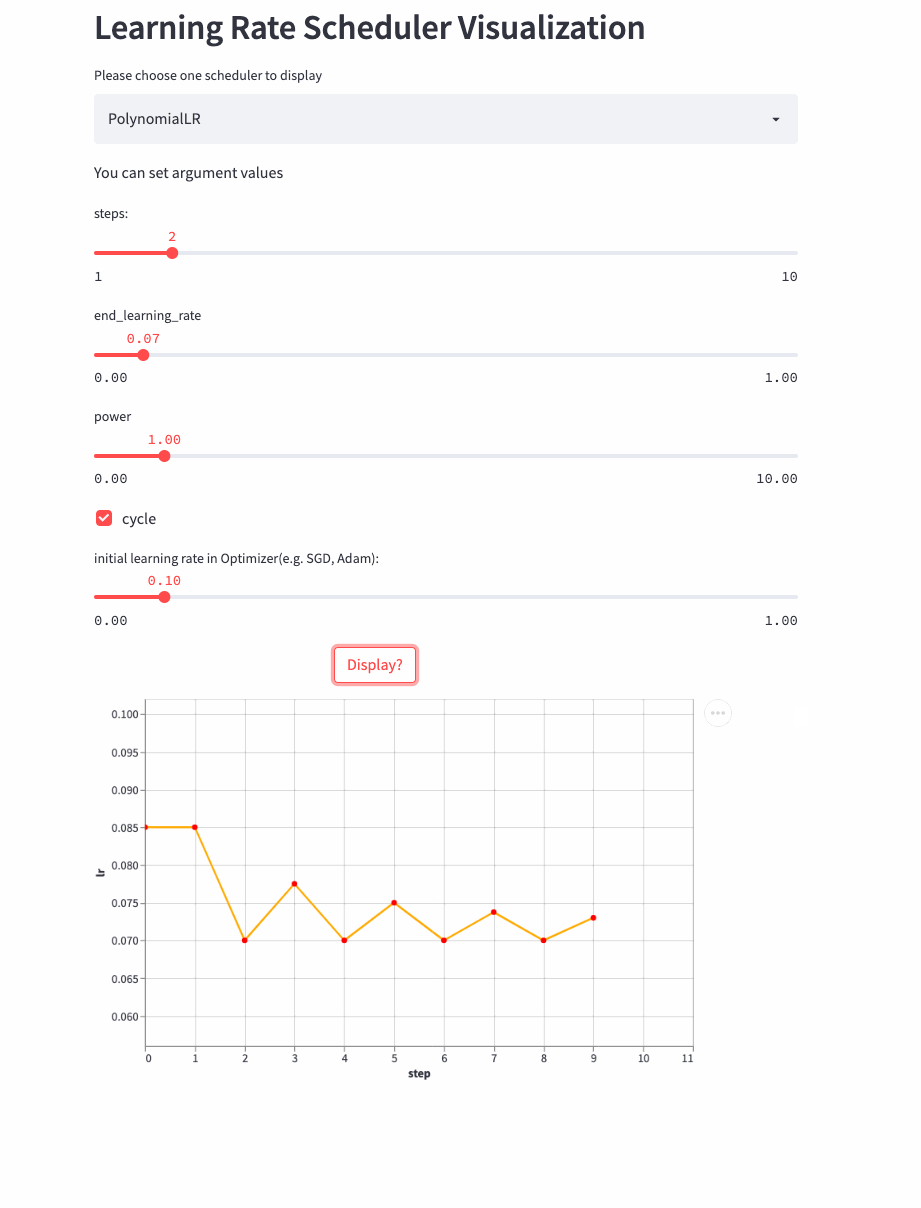
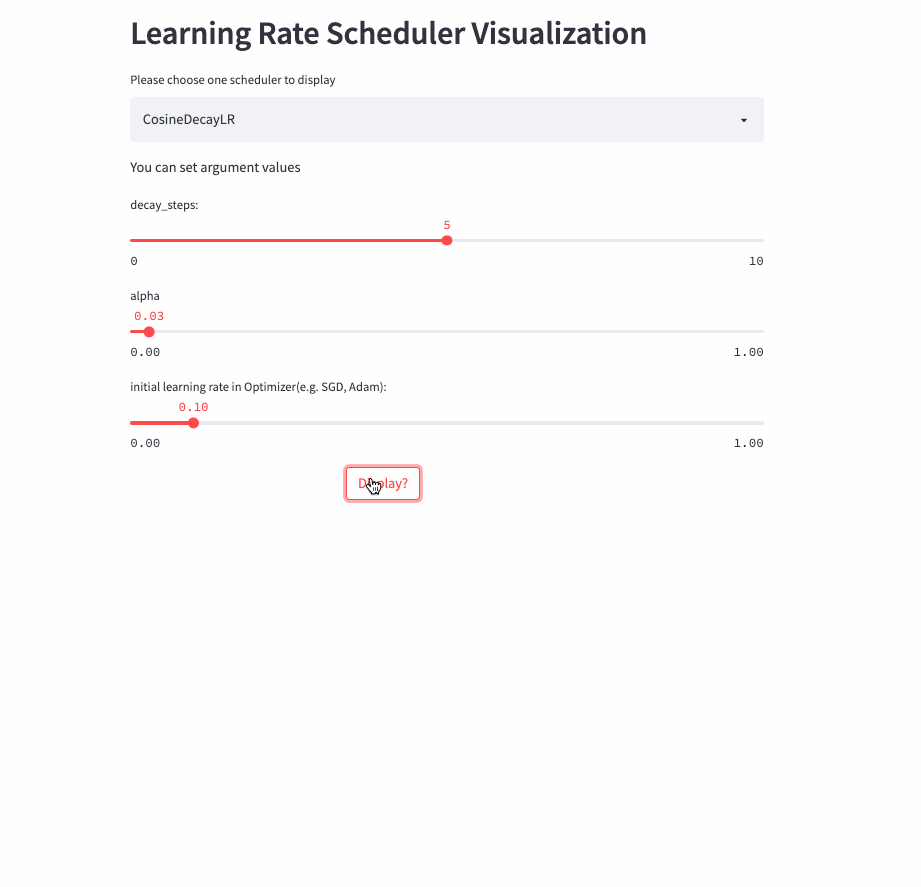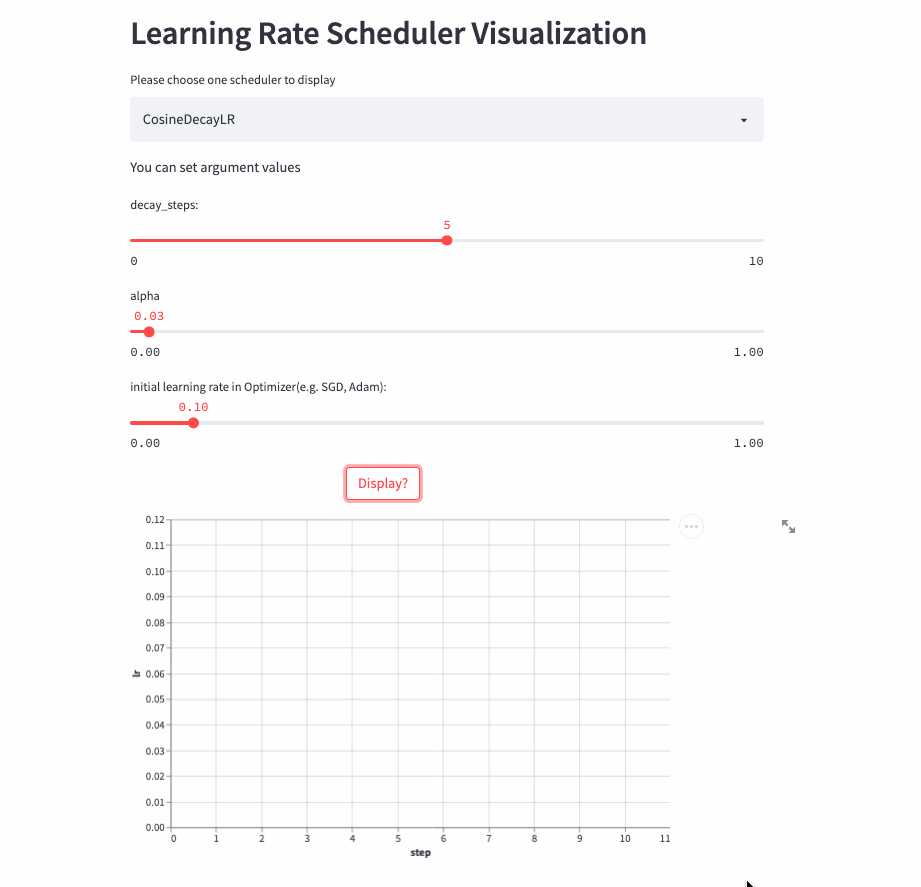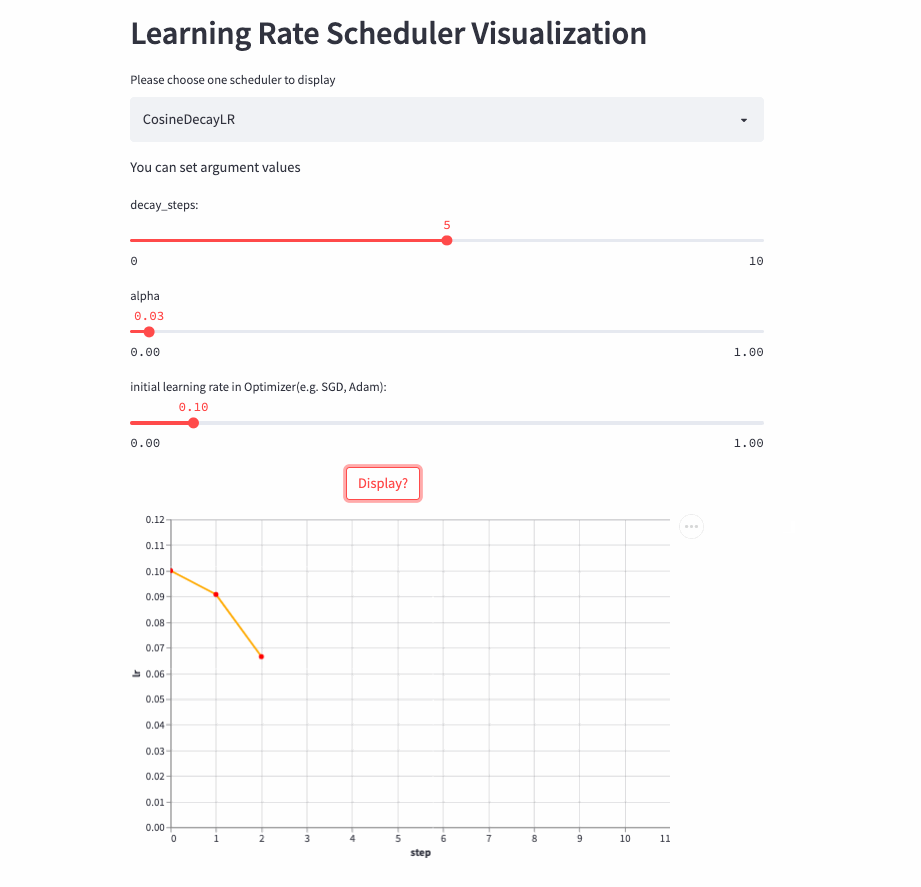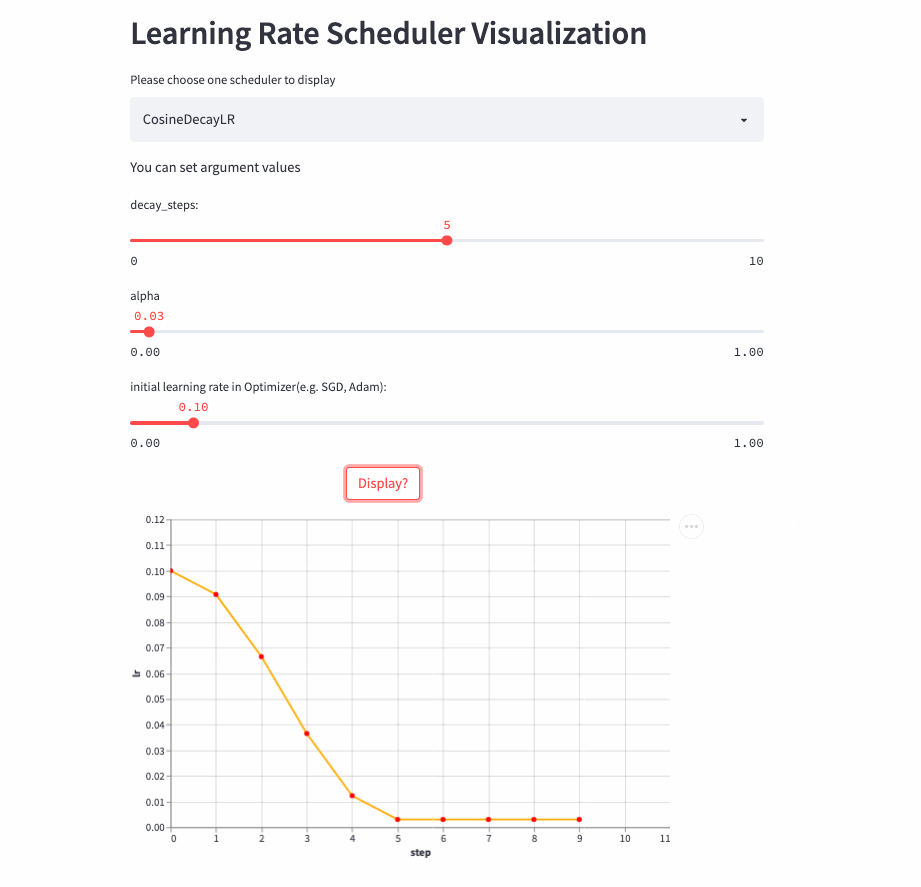
CosineDecayLR
oneflow.optim.lr_scheduler.CosineDecayLR(
optimizer: Optimizer,
decay_steps: int,
alpha: float = 0.0,
last_step: int = -1,
verbose: bool = False,
)
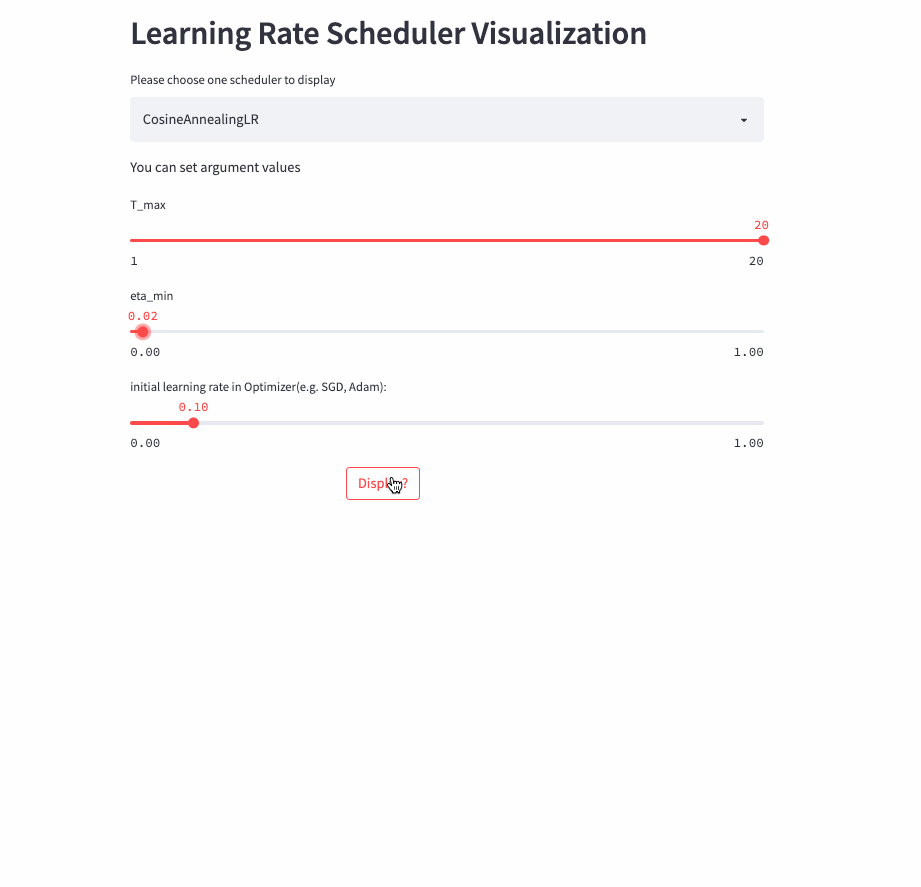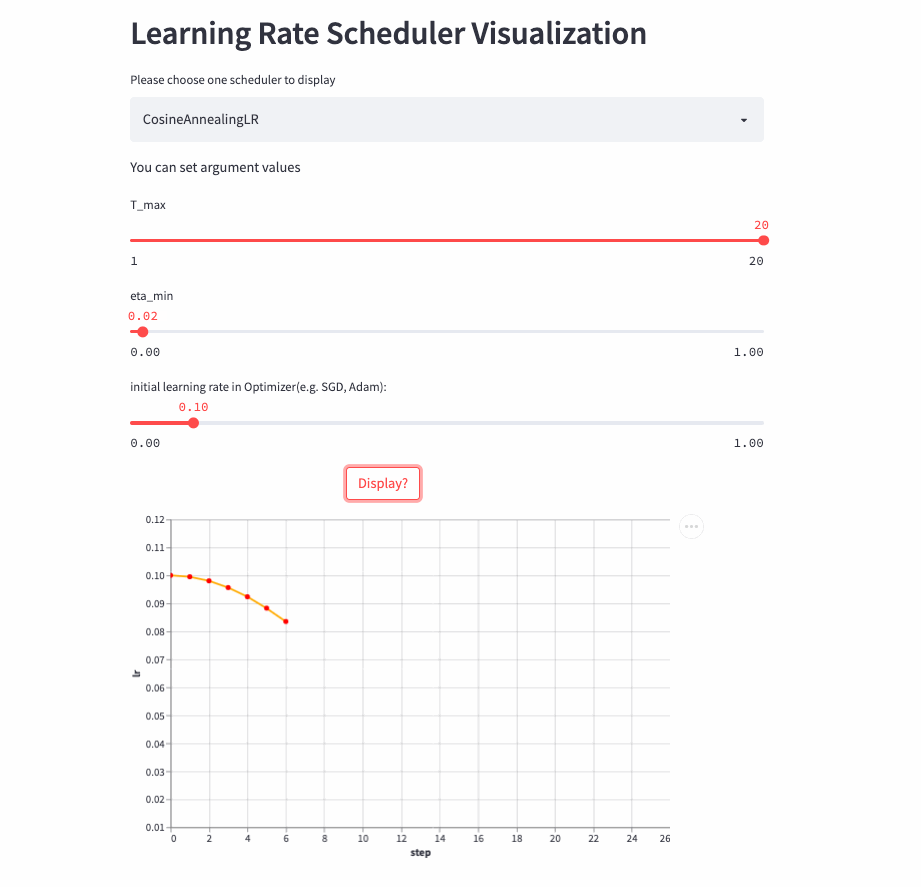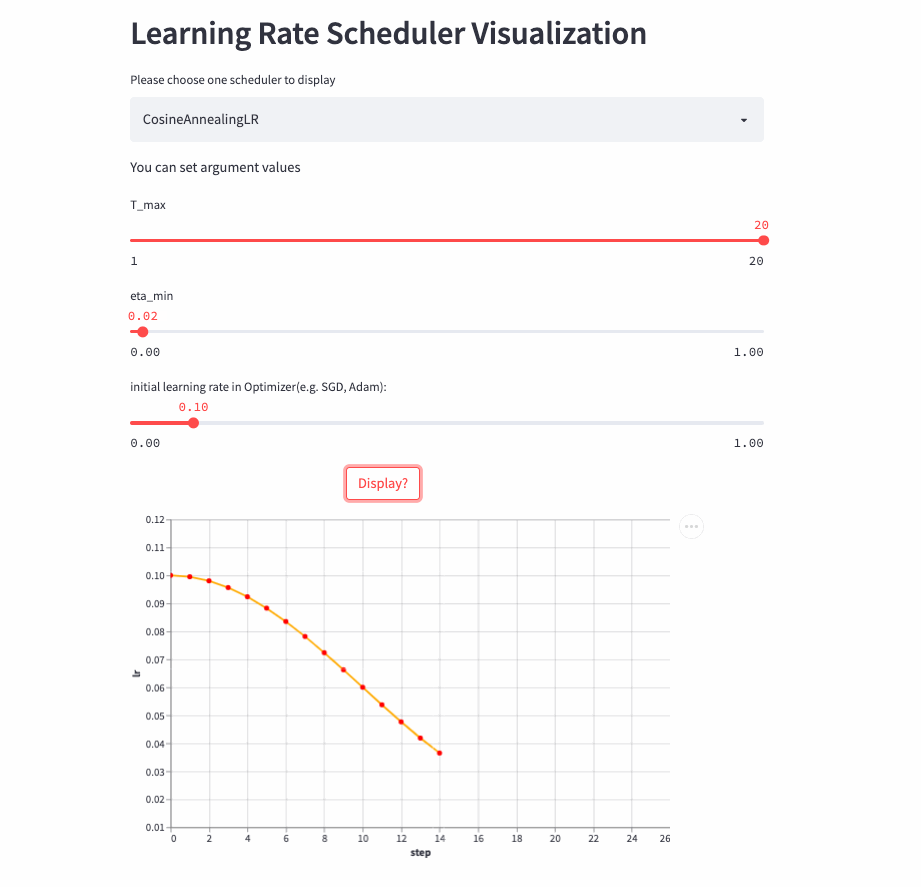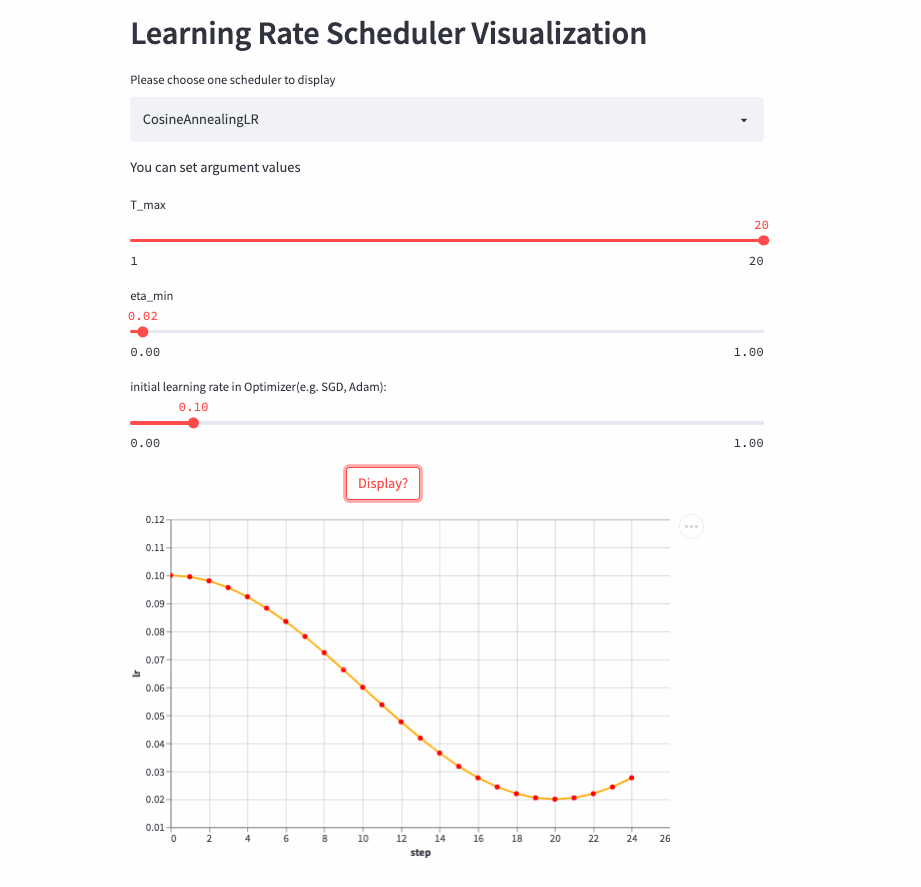
CosineAnnealingLR
oneflow.optim.lr_scheduler.CosineAnnealingLR(
optimizer: Optimizer,
T_max: int,
eta_min: float = 0.0,
last_step: int = -1,
verbose: bool = False,
)
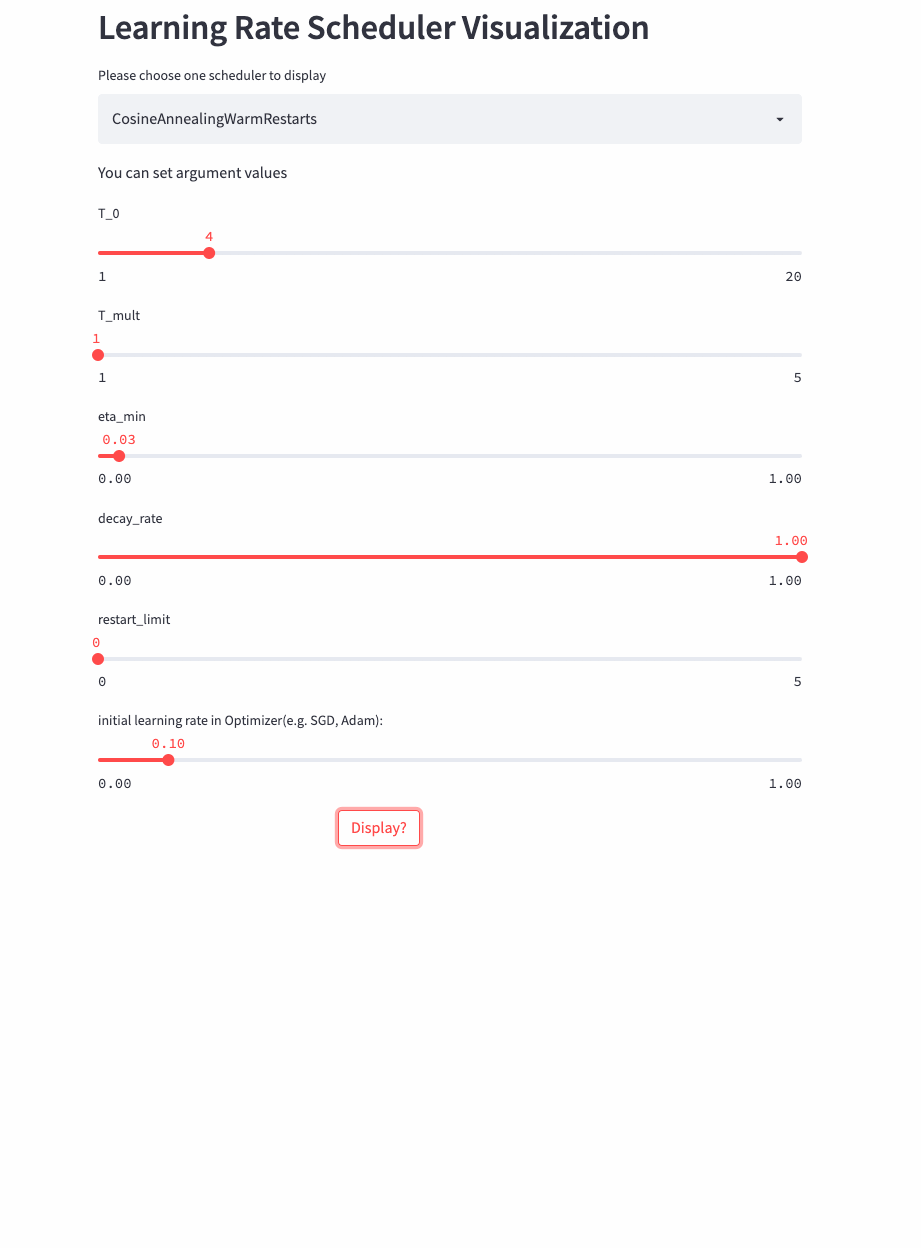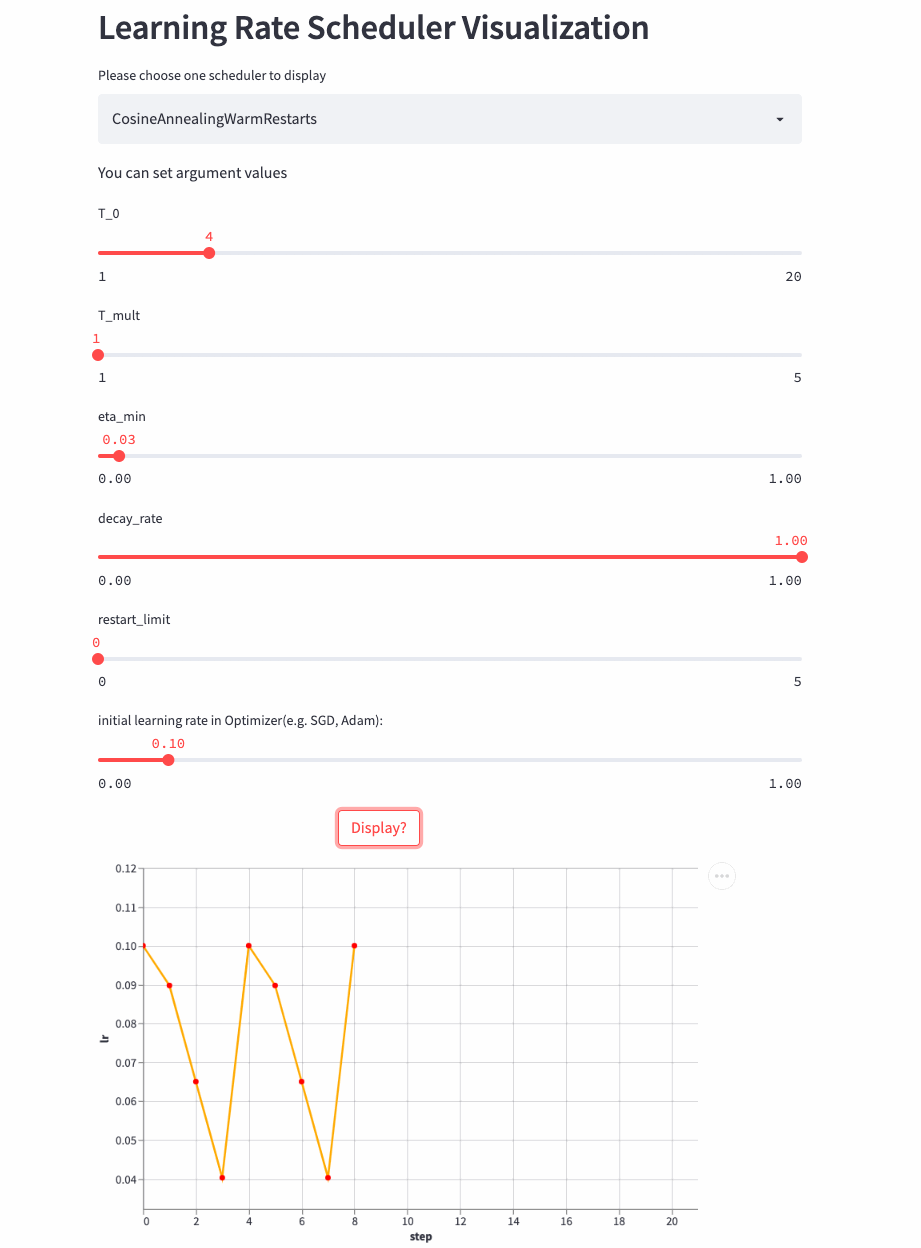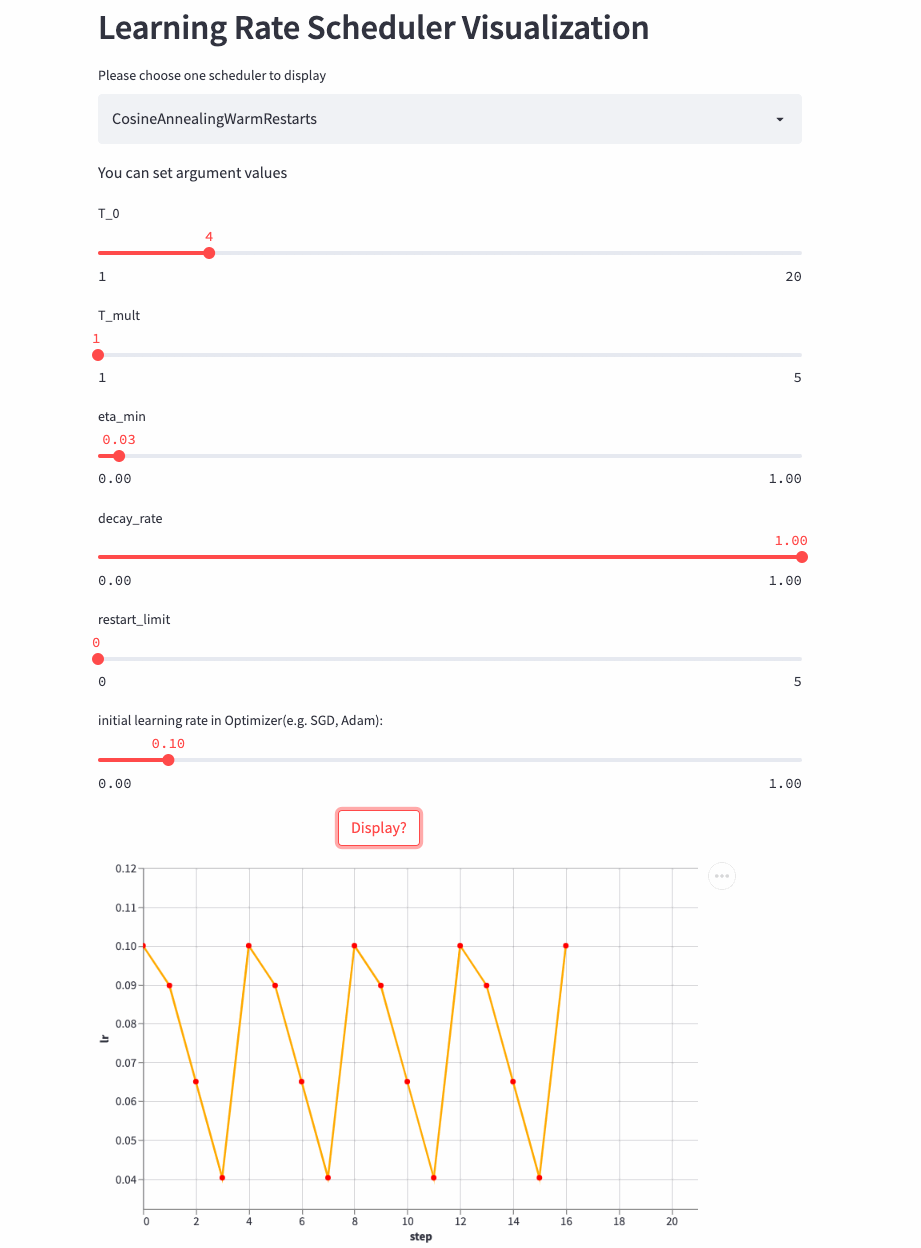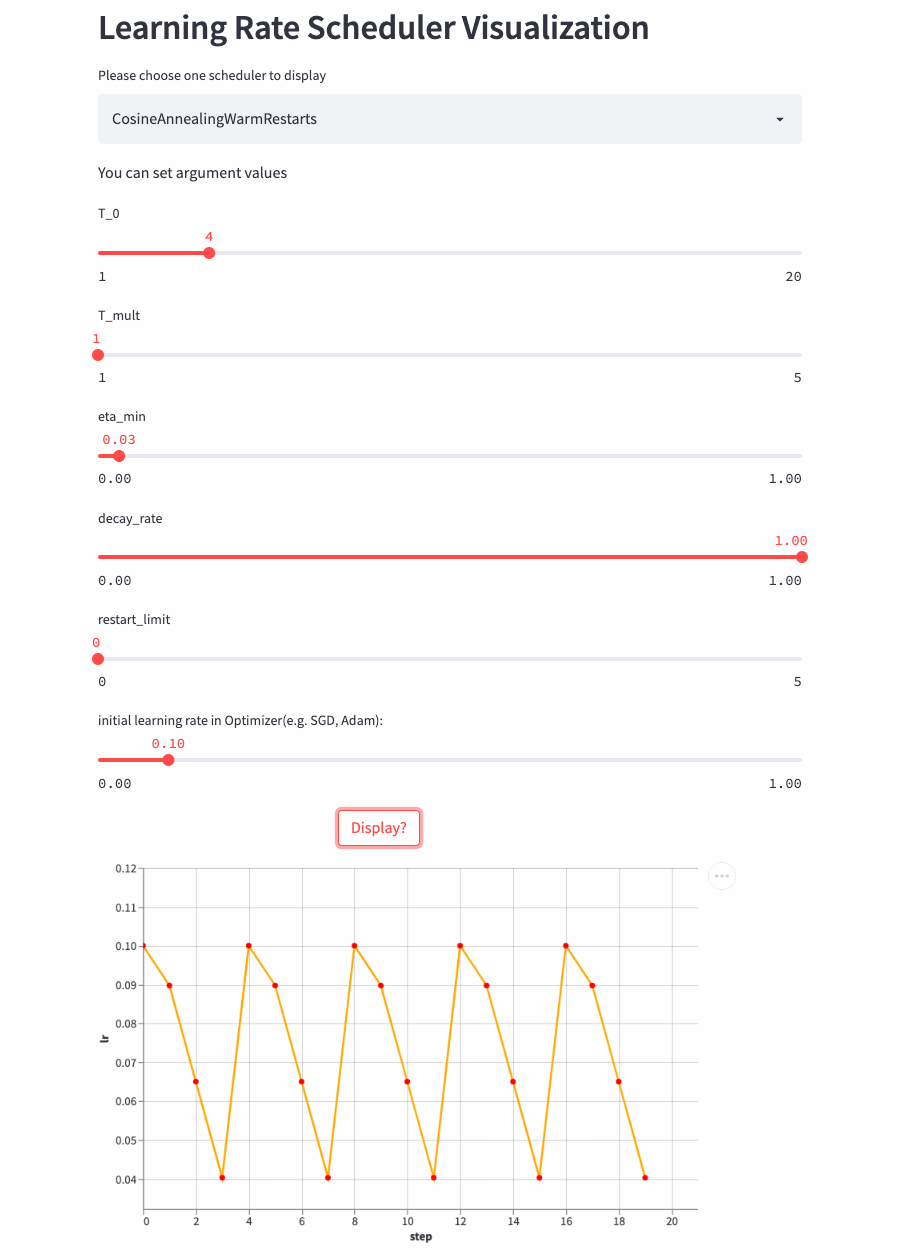
CosineAnnealingWarmRestarts
oneflow.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer: Optimizer,
T_0: int,
T_mult: int = 1,
eta_min: float = 0.0,
decay_rate: float = 1.0,
restart_limit: int = 0,
last_step: int = -1,
verbose: bool = False,
)
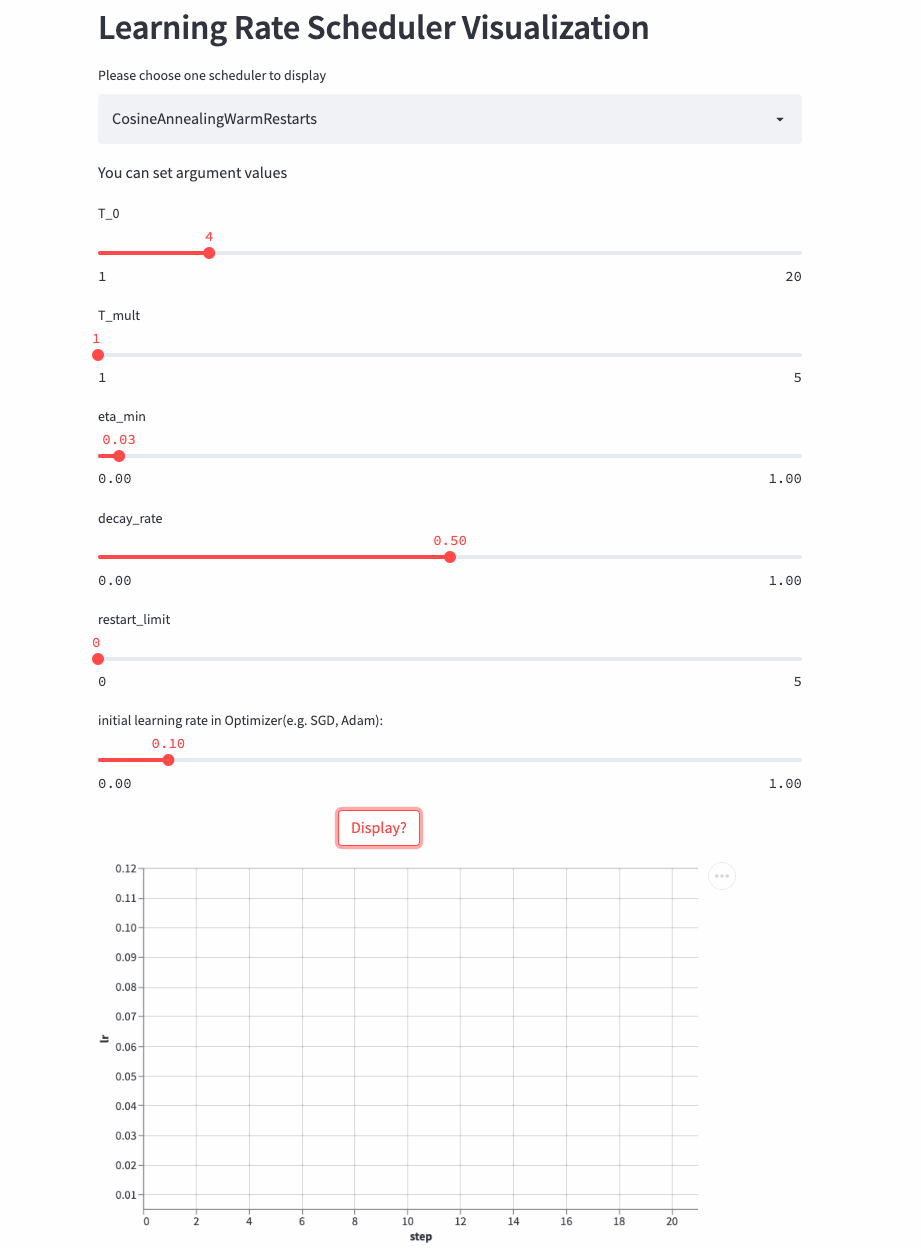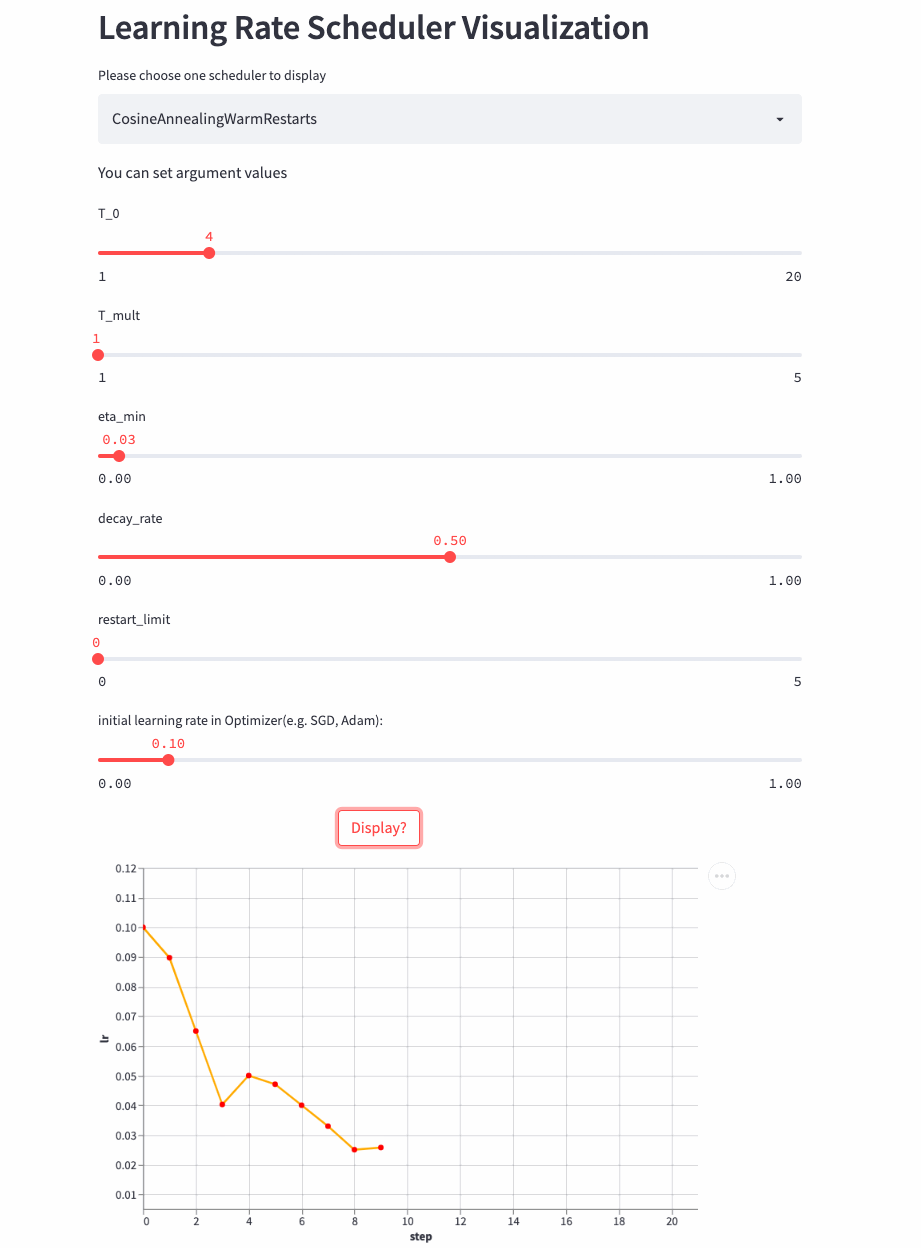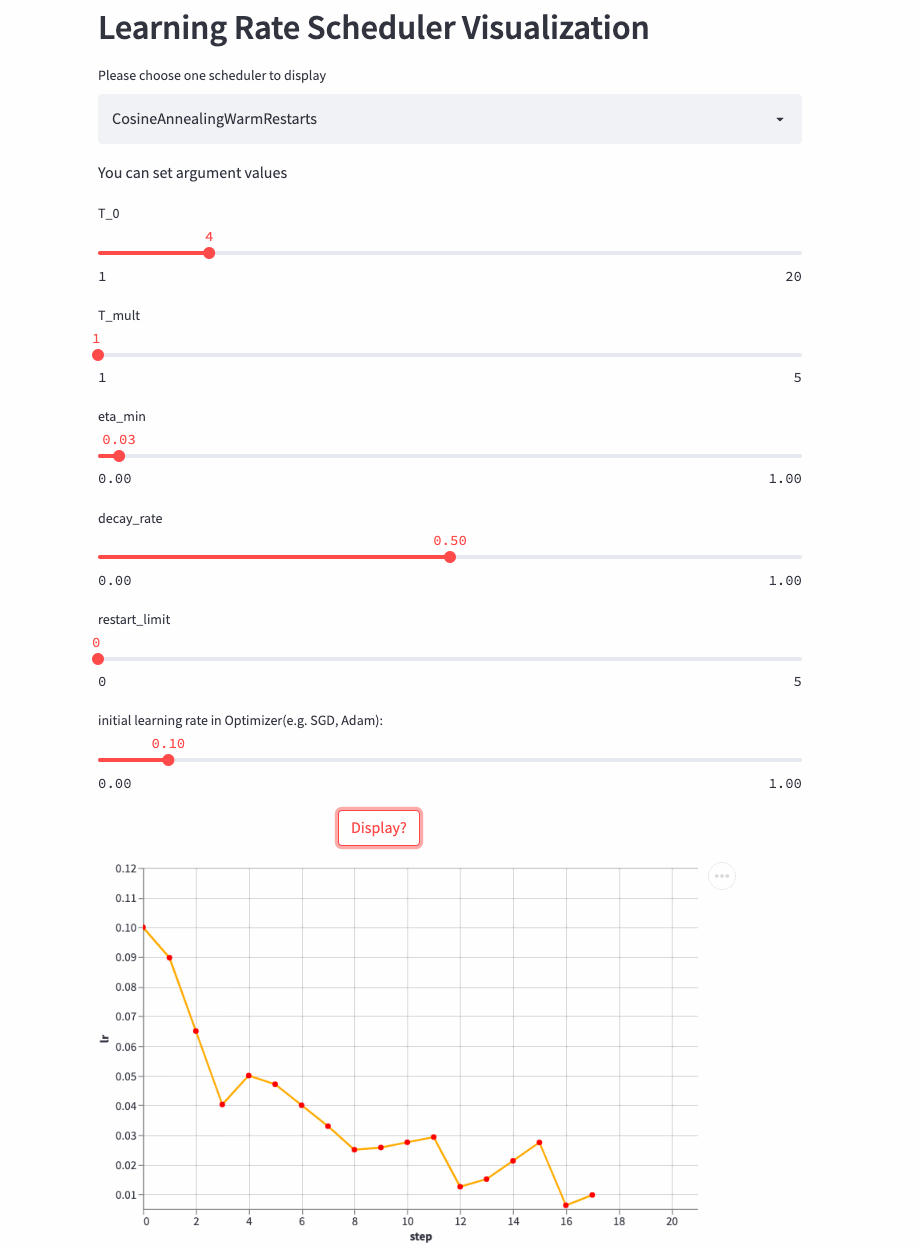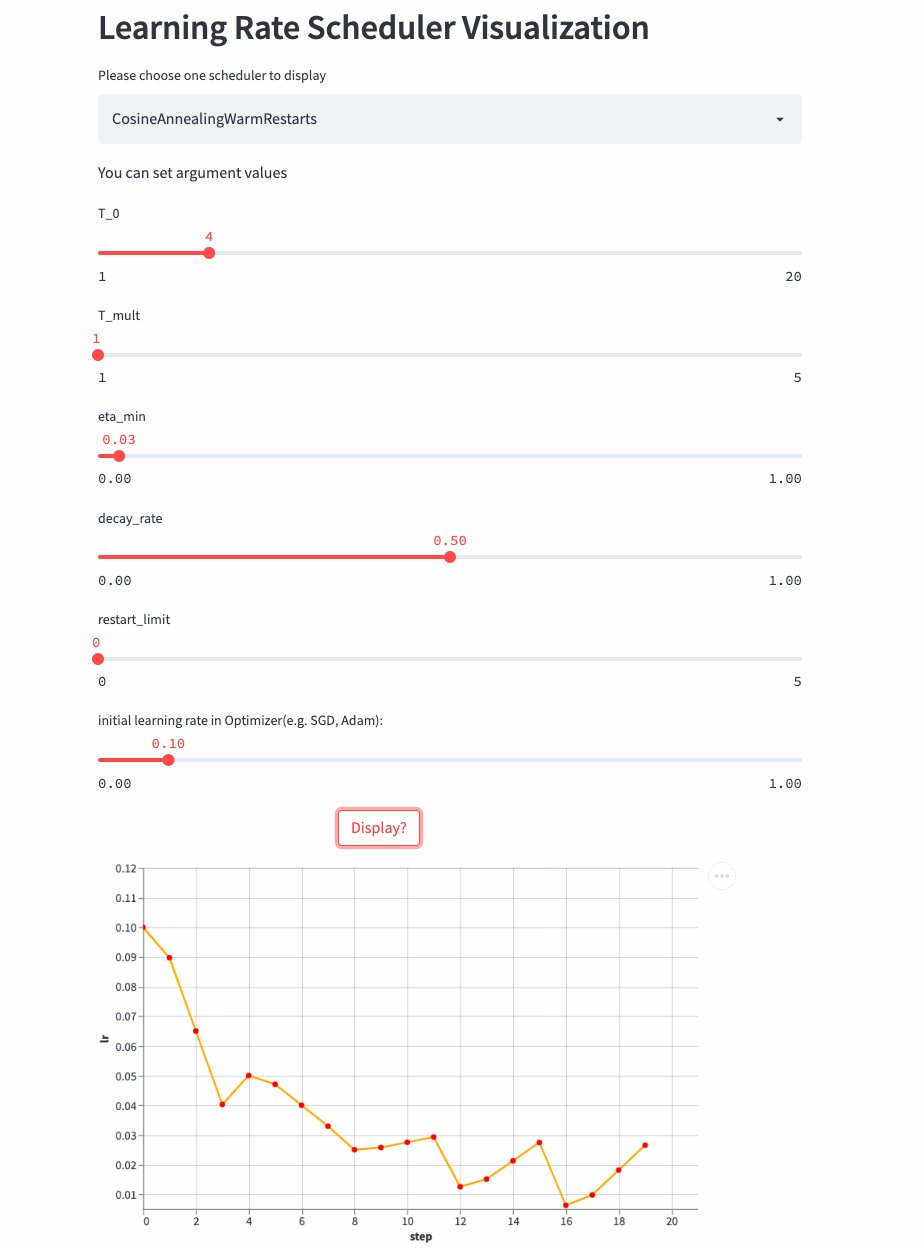

3、 Combined scheduling strategy
LambdaLR
oneflow.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_step=-1, verbose=False)def rate(step, model_size, factor, warmup):
"""
we have to default the step to 1 for LambdaLR function
to avoid zero raising to negative power.
"""
if step == 0:
step = 1
return factor * (
model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)
model = CustomTransformer(...)
optimizer = flow.optim.Adam(
model.parameters(), lr=1.0, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(step, d_model, factor=1, warmup=3000),
)SequentialLR
oneflow.optim.lr_scheduler.SequentialLR(
optimizer: Optimizer,
schedulers: Sequence[LRScheduler],
milestones: Sequence[int],
interval_rescaling: Union[Sequence[bool], bool] = False,
last_step: int = -1,
verbose: bool = False,
)WarmupLR
oneflow.optim.lr_scheduler.WarmupLR(
scheduler_or_optimizer: Union[LRScheduler, Optimizer],
warmup_factor: float = 1.0 / 3,
warmup_iters: int = 5,
warmup_method: str = "linear",
warmup_prefix: bool = False,
last_step=-1,
verbose=False,
)ChainedScheduler
oneflow.optim.lr_scheduler.ChainedScheduler(schedulers)lr ==> LRScheduler_1 ==> LRScheduler_2 ==> ... ==> LRScheduler_NReduceLROnPlateau
oneflow.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode="min",
factor=0.1,
patience=10,
threshold=1e-4,
threshold_mode="rel",
cooldown=0,
min_lr=0,
eps=1e-8,
verbose=False,
)optimizer = flow.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = flow.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Be careful , This step should be done at validate() Then call .
scheduler.step(val_loss)4、 practice
- https://github.com/basicv8vc/oneflow-cifar100-lr-scheduler
- Overview of deep learning
- The journey of an operator in the framework of deep learning
- The optimal parallel strategy of distributed matrix multiplication is derived by hand
- Train a large model with hundreds of billions of parameters , Four parallel strategies are indispensable
- Reading Pathways( Two ): The next step forward is OneFlow
- About concurrency and parallelism ,Go and Erlang My father is mistaken ?
- OneFlow v0.7.0 Release :New distributed interface ,LiBai、Serving Everything
边栏推荐
- Use xtradiagram Diagramcontrol for drawing and controlling process graphics
- Shell process control - 39. Special process control statements
- Ks007 realizes personal blog system based on JSP
- Tinder security cooperates with Intel vPro platform to build a new pattern of software and hardware collaborative security
- vulnhub靶机Os-hackNos-1
- WPF (c) new open source control library: newbeecoder UI waiting animation
- Simplify deployment with openvino model server and tensorflow serving
- IEEE transaction journal revision process record
- AI reference kit
- leetcode:42.接雨水
猜你喜欢

Simplify deployment with openvino model server and tensorflow serving

【课程预告】基于飞桨和OpenVINO 的AI表计产业解决方案 | 工业读表与字符检测
![[deeply understand tcapulusdb technology] tcapulusdb import data](/img/c5/fe0c9333b46c25be15ed4ba42f7bf8.png)
[deeply understand tcapulusdb technology] tcapulusdb import data

AI 参考套件
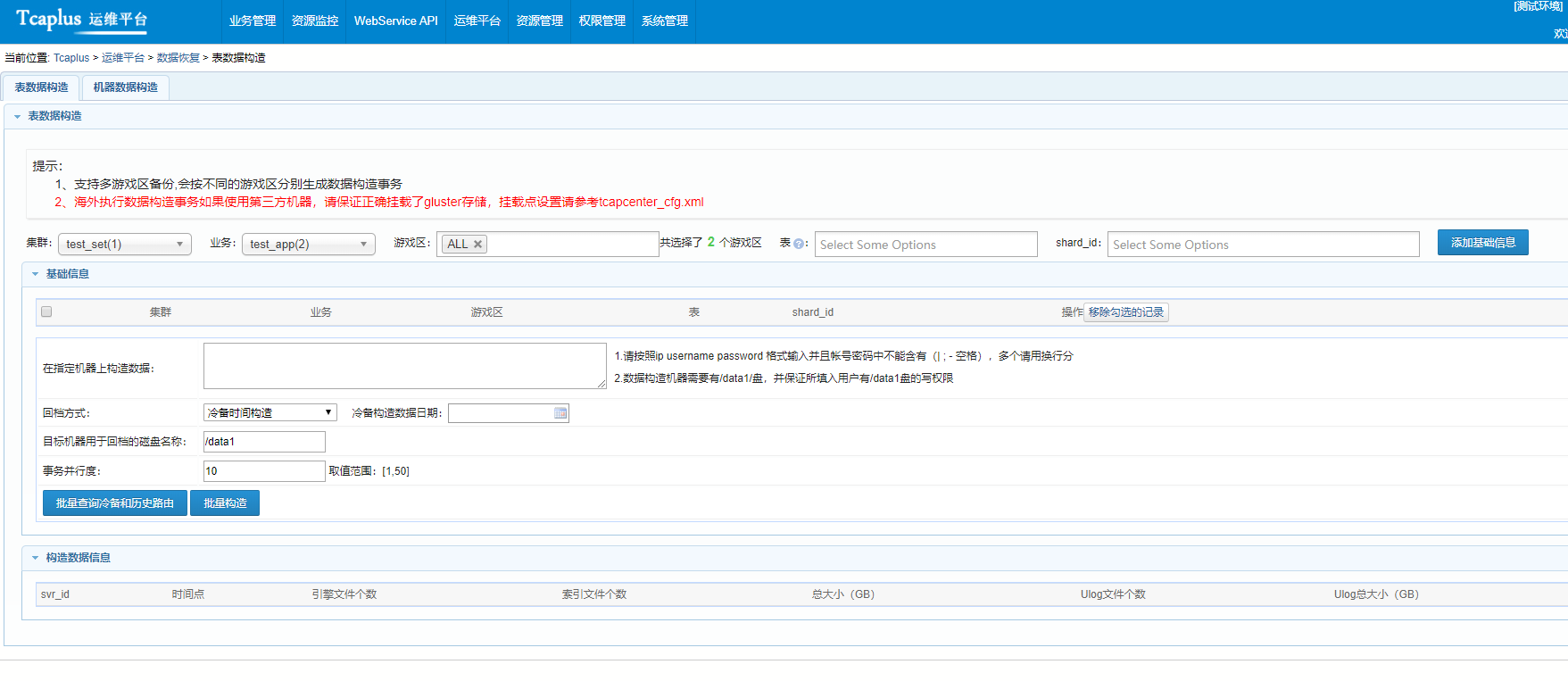
【深入理解TcaplusDB技术】TcaplusDB构造数据

leetcode:42. Rain water connection

Basic use of stacks and queues

3 interview salary negotiation skills, easily win 2K higher than expected salary to apply for a job

微信小程序之input前加图标

分布式数据库使用逻辑卷管理存储之扩容
随机推荐
[untitled]
Quartus II 13.1 detailed installation steps
[digital signal processing] linear time invariant system LTI (judge whether a system is a "non time varying" system | case 1 | transform before shift | shift before transform)
Thinking and Practice on Quality Standardization (suitable for product, development, testing and management post learning)
【深入理解TcaplusDB技术】TcaplusDB构造数据
Crmeb second open SMS function tutorial
Best practices for auto plug-ins and automatic batch processing in openvinotm 2022.1
Tinder security cooperates with Intel vPro platform to build a new pattern of software and hardware collaborative security
[deeply understand tcapulusdb technology] tmonitor system upgrade
今年英语高考,CMU用重构预训练交出134高分,大幅超越GPT3
【深入理解TcaplusDB技术】一键安装Tmonitor后台
Ks007 realizes personal blog system based on JSP
Win10 64位系统如何安装SQL server2008r2的DTS组件?
如何使用笔记软件 FlowUs、Notion 进行间隔重复?基于公式模版
微信小程序之input调整
SQLserver2008r2安装dts组件不成功
Understand ADT and OOP
What is the charm of Guizhou? Why do Alibaba, Huawei and Tencent build data centers in Guizhou?
Problems during MySQL uninstallation
Multi-Camera Detection of Social Distancing Reference Implementation