当前位置:网站首页>scrapy——爬取漫画自定义存储路径下载到本地
scrapy——爬取漫画自定义存储路径下载到本地
2022-06-26 12:40:00 【浪里划船】
scrapy——爬取漫画网漫画自定义存储路径下载到本地
1.新建项目以及主爬虫文件
scrapy startproject comic
cd comic
scrapy genspider Comic manhua.sfacg.com
注意以上命令是在cmd界面操作的
2.在项目下新建main.py文件,编写代码如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl Comic".split())
项目结构如下图所示: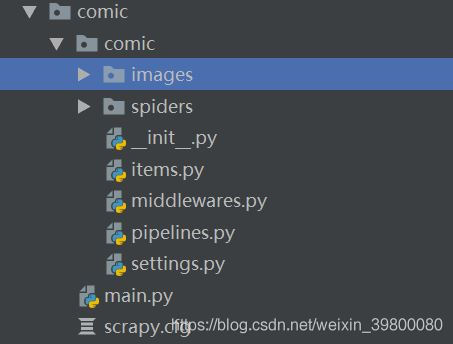
3.编写items.py文件里面的代码,如下:
import scrapy
class ComicItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
comic_name=scrapy.Field()#漫画名
chapter_name=scrapy.Field()#章节名
chapter_url=scrapy.Field()#章节url
img_urls=scrapy.Field()#漫画图片列表类型
chapter_js=scrapy.Field()#章节对应的js
4.编写pipelines.py文件里面的代码,如下
class MyImageDownloadPipeline(ImagesPipeline):
def get_media_requests(self,item,info):
meta={'comic_name':item['comic_name'],'chapter_name':item['chapter_name']}#图片文件夹命名名需要的参数
return [Request(url=x,meta=meta) for x in item.get('img_urls',[])]#这里一定要记得对应形参传值,否则报错
def file_path(self, request, response=None, info=None):
comic_name = request.meta.get('comic_name')#漫画名作为顶级目录
chapter_name = request.meta.get('chapter_name')#章节名作为次级目录
image_name=request.url.split('/')[-1]#选择链接最后可表示图片序号的后缀
#构造文件名
filename = '{0}/{1}/{2}'.format(comic_name,chapter_name,image_name)
return filename
上述代码完成继承ImagesPipeline类,并重写其中的两个函数,完成自定义存储路径。
5.编写Comic.py文件里面的代码,如下:
import scrapy
from ..items import ComicItem
class ComicSpider(scrapy.Spider):
name = 'Comic'
allowed_domains = ['manhua.sfacg.com','comic.sfacg.com']
start_urls = ['https://manhua.sfacg.com/mh/Gongsheng/']
img_host = 'http://coldpic.sfacg.com'#图片链接域名
host='https://manhua.sfacg.com'#章节域名
def parse(self,response):
chapter_urls=response.xpath('//div[@class="comic_Serial_list"]//a/@href').extract()#章节链接列表
for chapter_url in chapter_urls:#遍历章节url
chapter_url=self.host+chapter_url#加上域名
yield scrapy.Request(chapter_url,callback=self.parse_chapter)
def parse_chapter(self,response):#解析章节html
js_url='http:'+response.xpath('//head//script/@src').extract()[0]
chapter_name=response.xpath('//div[@id="AD_j1"]/span/text()').extract_first().strip()
yield scrapy.Request(url=js_url,meta={'chapter_name':chapter_name,'chapter_url':response.url},callback=self.parse_js)
def parse_js(self,response):#解析js里面返回的数据
texts=response.text.split(';')
comic_name=texts[0].split('=')[1].strip()[1:-1]#漫画名
img_urls = [self.img_host + text.split('=')[1].strip()[1:-1] for text in texts[7:-1]]#漫画章节图片列表
chapter_name=response.meta.get('chapter_name')#章节名
chapter_url=response.meta.get('chapter_url')#章节url
comic_item=ComicItem()
comic_item['comic_name']=comic_name
comic_item['chapter_name']=chapter_name
comic_item['chapter_js']=response.url
comic_item['img_urls']=img_urls
comic_item['chapter_url']=chapter_url
yield comic_item
由于漫画章节详情页图片是通过js动态加载的,直接获取到章节html是不包含漫画图片链接,经过观察,是通过每章节对应的js访问获取到对应图片链接的。而该js是可以在漫画章节源代码里面找到的,所有思路大致是先获取到所有章节链接,然后获取到章节详情页源码,解析出js的链接,然后访问js所咋url,获得章节所有图片。其中comic_item内容如下
{'chapter_js': 'http://comic.sfacg.com/Utility/1972/ZP/0083_6428.js',
'chapter_name': '共生symbiosis 19话(五)',
'chapter_url': 'https://manhua.sfacg.com/mh/Gongsheng/53379/',
'comic_name': '共生symbiosis',
'img_urls':
['http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/002_260.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/003_12.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/004_71.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/005_659.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/006_217.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/007_611.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/008_168.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/009_335.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/010_175.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/011_178.jpg',
'http://coldpic.sfacg.com/Pic/OnlineComic4/Gongsheng/ZP/0083_6428/012_790.jpg']}
6.编写settings.py文件里面的代码,如下:
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
ITEM_PIPELINES = {
'comic.pipelines.ComicPipeline': None,
'comic.pipelines.MyImageDownloadPipeline':300,
}
import os
project_dir=os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE=os.path.join(project_dir,'images')#漫画存储在项目根目录下的imags文件夹下
7.运行main.py文件,结果如下:
 最后下载完成可看到漫画已经下载到本地
最后下载完成可看到漫画已经下载到本地


边栏推荐
- Analysis and protection of heart blood dripping vulnerability (cve-2014-0160)
- Machine learning notes - seasonality of time series
- 解中小企业之困,百度智能云打个样
- HDU 3555 Bomb
- openlayers 绘制动态迁徙线、曲线
- Deeply analyze the differences between dangbei box B3, Tencent Aurora 5S and Xiaomi box 4S
- Is it safe for the head teacher to open a stock account and open an account for financial management?
- Software testing - Fundamentals
- [esp32-c3][rt-thread] run RT-Thread BSP minimum system based on esp32c3
- processing 随机生成线动画
猜你喜欢

First knowledge - Software Testing

倍福EtherCAT Xml描述文件更新和下载

倍福CX5130换卡对已有的授权文件转移操作
Biff TwinCAT can quickly detect the physical connection and EtherCAT network through emergency scan

机器学习笔记 - 时间序列的季节性

processing 随机生成线动画

软件测试测试常见分类有哪些?

【网络是怎么连接的】第二章(中):一个网络包的发出

倍福将EtherCAT模块分到多个同步单元运行--Sync Units的使用

国标GB28181协议EasyGBS级联宇视平台,保活消息出现403该如何处理?
随机推荐
PostGIS geographic function
mariadb学习笔记
倍福PLC通过MC_ReadParameter读取NC轴的配置参数
Openlayers drawing dynamic migration lines and curves
第十章 设置结构化日志记录(二)
首批通过!百度智能云曦灵平台获信通院数字人能力评测权威认证
Electron official docs series: Examples
心脏滴血漏洞(CVE-2014-0160)分析与防护
EasyGBS如何解决对讲功能使用异常?
Don't mess with full_ Case and parallel_ CASE
面试题积累
软件测试 - 概念篇
Explain C language 10 in detail (C language series)
软件测试报告应该包含的内容?面试必问
Verilog中的系统任务(显示/打印类)--$display, $write,$strobe,$monitor
C# const详解:C#常量的定义和使用
National standard gb28181 protocol easygbs video platform TCP active mode streaming exception repair
黑马笔记---常用API
KVM video card transparent transmission -- the road of building a dream
[esp32-C3][RT-THREAD] 基于ESP32C3运行RT-THREAD bsp最小系统