当前位置:网站首页>Why does MySQL limit affect performance?
Why does MySQL limit affect performance?
2022-06-25 16:57:00 【androidstarjack】
Click on the top “ Terminal R & D department ”
Set to “ Star standard ”, Master more database knowledge with you One , Preface
Let's start with MySQL Version of :
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)Table structure :
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)id It is an auto increment primary key ,val Is a non unique index .
Pour in a lot of data , common 500 ten thousand :
mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)We know , When limit offset rows Medium offset When a large , There will be efficiency issues :
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)In order to achieve the same goal , We usually rewrite it as follows :
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)The time difference is obvious .
Why did the above result appear ? Let's see select * from test where val=4 limit 300000,5; Query process of :
Query the index leaf node data .
According to the primary key value of the leaf node, query all the required field values on the cluster index .
It's similar to the picture below :
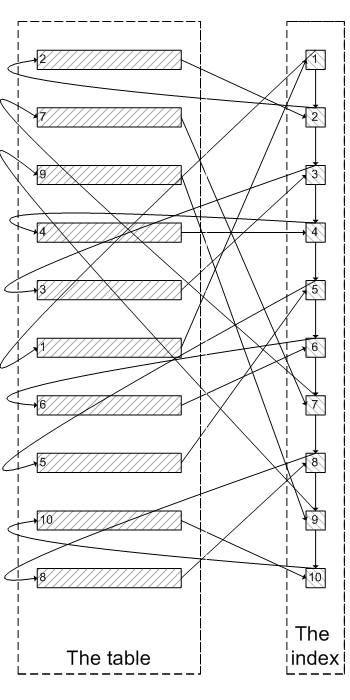
Like above , Need to check 300005 Secondary inode , Inquire about 300005 Data of secondary cluster index , Finally, filter out the results 300000 strip , Take out the last 5 strip .MySQL It takes a lot of randomness I/O On the query cluster index data , But there is 300000 Sub random I/O The query data will not appear in the result set .
Someone must have asked : Since it was indexed in the beginning , Why not follow the index leaf node to find the last needed 5 Nodes , Then query the actual data in the cluster index . It just needs 5 Sub random I/O, Similar to the process shown in the following picture :

In fact, I also want to ask this question .
confirmed
Now let's take a practical operation to confirm the above inference :
To confirm select * from test where val=4 limit 300000,5 It's a scan 300005 Index nodes and 300005 Data nodes on clustered indexes , We need to know MySQL Is there any way to count in a sql The number of times a data node is queried through an index node in . I tried first Handler_read_* series , Unfortunately, none of the variables can satisfy the condition .
I can only prove it indirectly :
InnoDB There is buffer pool. It contains recently accessed data pages , Including data pages and index pages . So we need to run two sql, To compare buffer pool Number of data pages in . The prediction is to run select * from test a inner join (select id from test where val=4 limit 300000,5) b> after ,buffer pool The number of data pages in is far less than select * from test where val=4 limit 300000,5;
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)It can be seen that , at present buffer pool There's nothing about test Table data page .
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)It can be seen that , here buffer pool About China test Table has 4098 Data pages ,208 Index pages .
select * from test a inner join (select id from test where val=4 limit 300000,5) b> To prevent the effect of the last test , We need to empty buffer pool, restart mysql.
mysqladmin shutdown /usr/local/bin/mysqld_safe &mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name; Empty set (0.03 sec) function sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id; +---------+-----+--------+---------+ | id | val | source | id | +---------+-----+--------+---------+ | 3327622 | 4 | 4 | 3327622 | | 3327632 | 4 | 4 | 3327632 | | 3327642 | 4 | 4 | 3327642 | | 3327652 | 4 | 4 | 3327652 | | 3327662 | 4 | 4 | 3327662 | +---------+-----+--------+---------+ 5 rows in set (0.09 sec) mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name; +------------+----------+ | index_name | count(*) | +------------+----------+ | PRIMARY | 5 | | val | 390 | +------------+----------+ 2 rows in set (0.03 sec)We can see clearly the difference between the two : first sql To load the 4098 Data pages to buffer pool, And the second one. sql Only loaded 5 Data pages to buffer pool. In line with our prediction . It also confirms why the first sql Will be slow : Read a lot of useless data rows (300000), Finally, he abandoned .
And it creates a problem : Loaded a lot of hot, not very high data pages to buffer pool, Can cause buffer pool Pollution of , Occupy buffer pool Space .
Problems encountered
To make sure it's cleared every time you restart buffer pool, We need to close innodb_buffer_pool_dump_at_shutdown and innodb_buffer_pool_load_at_startup, These two options control when the database is shut down dump Out buffer pool The data in the database and when the database is opened is loaded on the disk for backup buffer pool The data of .
Reference material :
1.https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
2.https://dev.mysql.com/doc/refman/5.7/en/innodb-information-schema-buffer-pool-tables.html
author :zhangyachen
source :https://dwz.cn/K1Q1cePW
Write it at the end
You can leave a message below to discuss what you don't understand , You can also ask me by private message. I will reply after seeing it . Finally, if the article is helpful to you, please remember to give me a like , Pay attention and don't get lost
@ Terminal R & D department
Fresh dry goods are shared every day !
reply 【idea Activate 】 You can get idea How to activate
reply 【Java】 obtain java Relevant video tutorials and materials
reply 【SpringCloud】 obtain SpringCloud Many relevant learning materials
reply 【python】 Get the full set 0 Basics Python Knowledge Manual
reply 【2020】 obtain 2020java Related interview questions tutorial
reply 【 Add group 】 You can join the technical exchange group related to the terminal R & D department
Read more
use Spring Of BeanUtils front , I suggest you understand these pits first !
lazy-mock , A lazy tool for generating backend simulation data
In Huawei Hongmeng OS Try some fresh food , My first one “hello world”, take off !
The byte is bouncing :i++ Is it thread safe ?
One SQL Accidents caused by , Colleagues are fired directly !!
Too much ! Check Alibaba cloud ECS Of CPU Incredibly reach 100%
a vue Write powerful swagger-ui, A little show ( Open source address attached )
Believe in yourself , Nothing is impossible , Only unexpected, not only technology is obtained here !
If you like, just give me “ Looking at ”边栏推荐
- 【機器學習】基於多元時間序列對高考預測分析案例
- The art of code annotation. Does excellent code really need no annotation?
- 【无标题】
- Unity技术手册 - 干扰/噪音/杂波(Noise)子模块
- [untitled]
- Kalman Filter 遇到 Deep Learning : 卡尔曼滤波和深度学习有关的论文
- 使用hbuilder X创建uniapp项目
- About: encryption and decryption of rsa+aes data transmission [chapter], project practice (special summary)
- 2022-06-17 网工进阶(十)IS-IS-通用报头、邻接关系的建立、IIH报文、DIS与伪节点
- _ 19_ IO stream summary
猜你喜欢

这些老系统代码,是猪写的么?

2022-06-17 advanced network engineering (IX) is-is- principle, NSAP, net, area division, network type, and overhead value

Day_ fifteen

Generate post order traversal according to pre order traversal and mid order traversal

Day_ eleven

这项最新的调查研究,揭开多云发展的两大秘密

使用PyWebIO测试,刚入门的测试员也能做出自己的测试工具

App测试工具大全,收藏这篇就够了
【 apprentissage automatique】 cas de prévision et d'analyse de l'examen d'entrée à l'Université basé sur des séries chronologiques multiples

Mac PHP multi version management and swoole extension installation
随机推荐
这项最新的调查研究,揭开多云发展的两大秘密
2022-06-17 网工进阶(九)IS-IS-原理、NSAP、NET、区域划分、网络类型、开销值
AD域登录验证
SDN系统方法 | 10. SDN的未来
Problems encountered in using MySQL
Perfect shuffle problem
1-8file sharing in VMWare
IO stream
The problem of missing precision of kettle table input components
Day_ fifteen
【机器学习】基于多元时间序列对高考预测分析案例
从TiDB上线阿里云的背后,如何看待云数据库的变革趋势
Generate post order traversal according to pre order traversal and mid order traversal
【精通高并发】深入理解汇编语言基础
JVM內存結構
3. conditional probability and independence
深入浅出对话系统——自己实现Transformer
Wireshark网卡无法找到或没有显示的问题
mysql使用过程中遇到的问题
批量--07---断点重提