当前位置:网站首页>【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
【AI4Code】《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
2022-07-25 11:11:00 【chad_lee】
《CodeBERT: A Pre-Trained Model for Programming and Natural Languages》 EMNLP 2020
将BERT应用在 双模态数据 上:编程语言(PL)和自然语言(NL),预训练完的CodeBERT得到的通用表示,可以支持下游各种任务比如自然语言代码搜索,代码文档生成等。作者还贡献了一个NL-PL的数据集。
方法
模型架构
模型就是BERT,模型架构和RoBERTa-base 基本一致,包括 12 个层,每一层有 12 个自注意力头,每个自注意力头的维度为 64。隐藏维度为 768,FF层的维度为 3072。模型参数总量为 1.25 亿。
输入输出
输入:预训练的输入是自然语言文本和编程语言文本拼接成的序列:[CLS], w1, w2, …wn, [SEP], c1, c2, …, cm, [EOS],w是文本的token,c是代码的token。
输出:每个token在CodeBERT里都有输出,文本和代码的token的输出就是当前场景下他们的语义向量表示,[CLS]的向量表示作为整个序列表示的聚合(aggregated sequence representation)。 分隔符 [SEP] 和结束符 [EOS]的输出没有意义。
预训练数据
有两类训练数据,一类是双模态的PL-NL对数据,此外还有一类单模态的数据,即“不具备平行对应自然语言文本的代码” 和 “不具备对应代码的自然语言文本”。
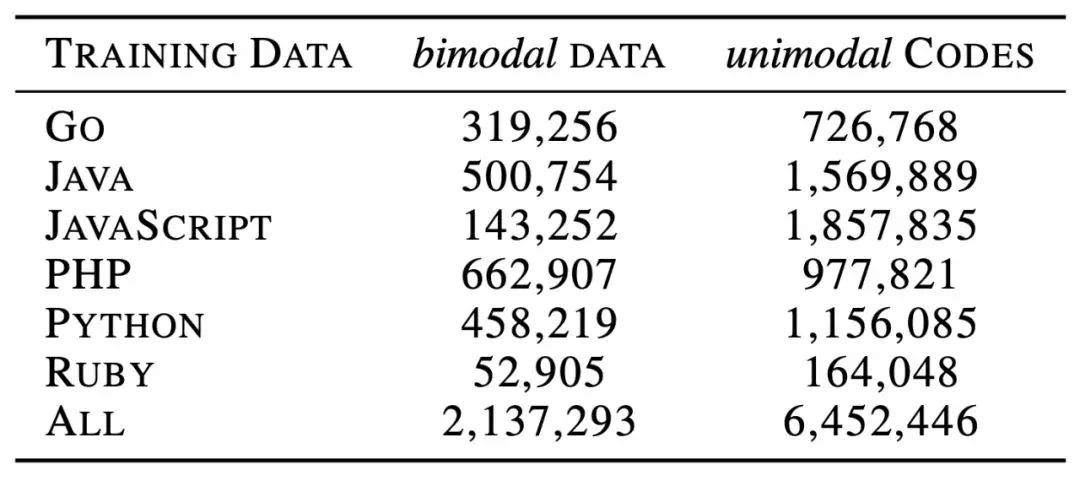
NL-PL 对示例如下所示,其中 NL 是函数文档(黑色虚线框)中的第一段(红色框)

预训练任务
MLM (Masked Language Modeling)
有两个目标函数,在双模态数据NL-PL用MLM目标函数,在NL和PL随机选择位置mask(两种位置无关),用token [MASK]代替:
m i w ∼ unif { 1 , ∣ w ∣ } for i = 1 to ∣ w ∣ m i c ∼ unif { 1 , ∣ c ∣ } for i = 1 to ∣ c ∣ w masked = REPLACE ( w , m w , [ M A S K ] ) c masked = REPLACE ( c , m c , [ M A S K ] ) x = w + c \begin{aligned} m_{i}^{w} & \sim \operatorname{unif}\{1,|\boldsymbol{w}|\} \text { for } i=1 \text { to }|\boldsymbol{w}| \\ m_{i}^{c} & \sim \operatorname{unif}\{1,|\boldsymbol{c}|\} \text { for } i=1 \text { to }|\boldsymbol{c}| \\ \boldsymbol{w}^{\text {masked }} &=\operatorname{REPLACE}\left(\boldsymbol{w}, \boldsymbol{m}^{\boldsymbol{w}},[M A S K]\right) \\ \boldsymbol{c}^{\text {masked }} &=\operatorname{REPLACE}\left(\boldsymbol{c}, \boldsymbol{m}^{c},[M A S K]\right) \\ \boldsymbol{x} &=\boldsymbol{w}+\boldsymbol{c} \end{aligned} miwmicwmasked cmasked x∼unif{ 1,∣w∣} for i=1 to ∣w∣∼unif{ 1,∣c∣} for i=1 to ∣c∣=REPLACE(w,mw,[MASK])=REPLACE(c,mc,[MASK])=w+c
MLM的目标就是预测被mask的touken。鉴别器 p D 1 p^{D_{1}} pD1预测第 i 个单词是masked的token的概率。
L M L M ( θ ) = ∑ i ∈ m w ∪ m c − log p D 1 ( x i ∣ w masked , c masked ) \mathcal{L}_{\mathrm{MLM}}(\theta)=\sum_{i \in \boldsymbol{m}^{\boldsymbol{w}} \cup \boldsymbol{m}^{c}}-\log p^{D_{1}}\left(x_{i} \mid \boldsymbol{w}^{\text {masked }}, \boldsymbol{c}^{\text {masked }}\right) LMLM(θ)=i∈mw∪mc∑−logpD1(xi∣wmasked ,cmasked )
RTD (replaced token detection)
在MLM中只用了NL-PL数据,在RTD用单模态数据。

这里CodeBERT化身为Fig2中的NL-Code Discriminator,具体做法是输入的文本/代码序列先随机选取几个位置作为mask,然后使用一个Generator为mask生成一个 迷惑性的token,这里的Generator可以理解为Word2Vec(并不是,方便理解),根据上下文为mask预测一个token,可能是正确的(如w5),可能是错误的但也是有迷惑性的(毕竟word2vec预测的)。
生成的新序列送入CodeBERT,为CodeBERT输出的每个token的embedding进行二分类,判断是否被替换掉了。
微调
对于自然语言搜索代码任务,就用 [CLS] 的输出表征判断两个模态语言的相似关系。
对于代码生成文本任务,用CodeBERT作为encoder-decoder的encoder部分的初始化。
实验
文章的实验结果就不放了,分别做了代码搜索、NL-PL探测、给定代码生成文档的实验。
https://marketplace.visualstudio.com/items?itemName=graykode.ai-docstring&ssr=false
VS Code里已经有基于CodeBERT的Docstring插件了:
边栏推荐
- W5500 is in TCP_ In server mode, you cannot Ping or communicate in the switch / router network.
- [multimodal] transferrec: learning transferable recommendation from texture of modality feedback arXiv '22
- 【多模态】《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》ICCV 2021
- Teach you how to configure S2E as the working mode of TCP server through MCU
- Power Bi -- these skills make the report more "compelling"“
- Review in the middle of 2022 | understand the latest progress of pre training model
- 【MySQL 17】安装异常:Could not open file ‘/var/log/mysql/mysqld.log‘ for error logging: Permission denied
- 程序员送给女孩子的精美礼物,H5立方体,唯美,精致,高清
- Varest blueprint settings JSON
- What is the global event bus?
猜你喜欢

PHP curl post x-www-form-urlencoded

【AI4Code】CodeX:《Evaluating Large Language Models Trained on Code》(OpenAI)

微星主板前面板耳机插孔无声音输出问题【已解决】

toString()与new String()用法区别

任何时间,任何地点,超级侦探,认真办案!

Onenet platform control w5500 development board LED light

【GCN多模态RS】《Pre-training Representations of Multi-modal Multi-query E-commerce Search》 KDD 2022
MySQL historical data supplement new data

OSPF综合实验

【AI4Code】《CoSQA: 20,000+ Web Queries for Code Search and Question Answering》 ACL 2021
随机推荐
【GCN-RS】Learning Explicit User Interest Boundary for Recommendation (WWW‘22)
【AI4Code】CodeX:《Evaluating Large Language Models Trained on Code》(OpenAI)
Onenet platform control w5500 development board LED light
php curl post Length Required 错误设置header头
Functions in JS
return 和 finally的执行顺序 ?各位大佬请看过来,
软件测试阶段的风险
Learning to Pre-train Graph Neural Networks(图预训练与微调差异)
JS data types and mutual conversion
The applet image cannot display Base64 pictures. The solution is valid
JaveScript循环
【GCN】《Adaptive Propagation Graph Convolutional Network》(TNNLS 2020)
dirReader. Readentries compatibility issues. Exception error domexception
What is the difference between session and cookie?? Xiaobai came to tell you
擎创科技加入龙蜥社区,共建智能运维平台新生态
JS interview question: handwriting throttle function
【多模态】《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》ICCV 2021
Power Bi -- these skills make the report more "compelling"“
【CTR】《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)
[GCN multimodal RS] pre training representations of multi modal multi query e-commerce search KDD 2022