当前位置:网站首页>Interpretation of video generation paper of fed shot video to video (neurips 2019)
Interpretation of video generation paper of fed shot video to video (neurips 2019)
2022-07-25 01:37:00 【‘Atlas’】
List of articles
The paper : 《Few-shot Video-to-Video Synthesis
Ting-Chun》
github: https://github.com/NVlabs/few-shot-vid2vid
solve the problem
Even though vid2vid( See last article Video-to-Video Interpretation of the thesis ) Significant progress has been made , But there are two main limitations ;
1、 A lot of data is needed . Training requires a large amount of target human body or target scene data ;
2、 The generalization ability of the model is limited . Can only generate training concentrated in the human body , For people who have never seen human body, their generalization ability is poor ;
To solve the above problems , The author puts forward few-shot vid2vid, Several examples of target domain are used in reasoning , There is no target or scene video before learning and generating . By using attention The network weight generation module of the mechanism improves the generalization ability of the model ;
Algorithm
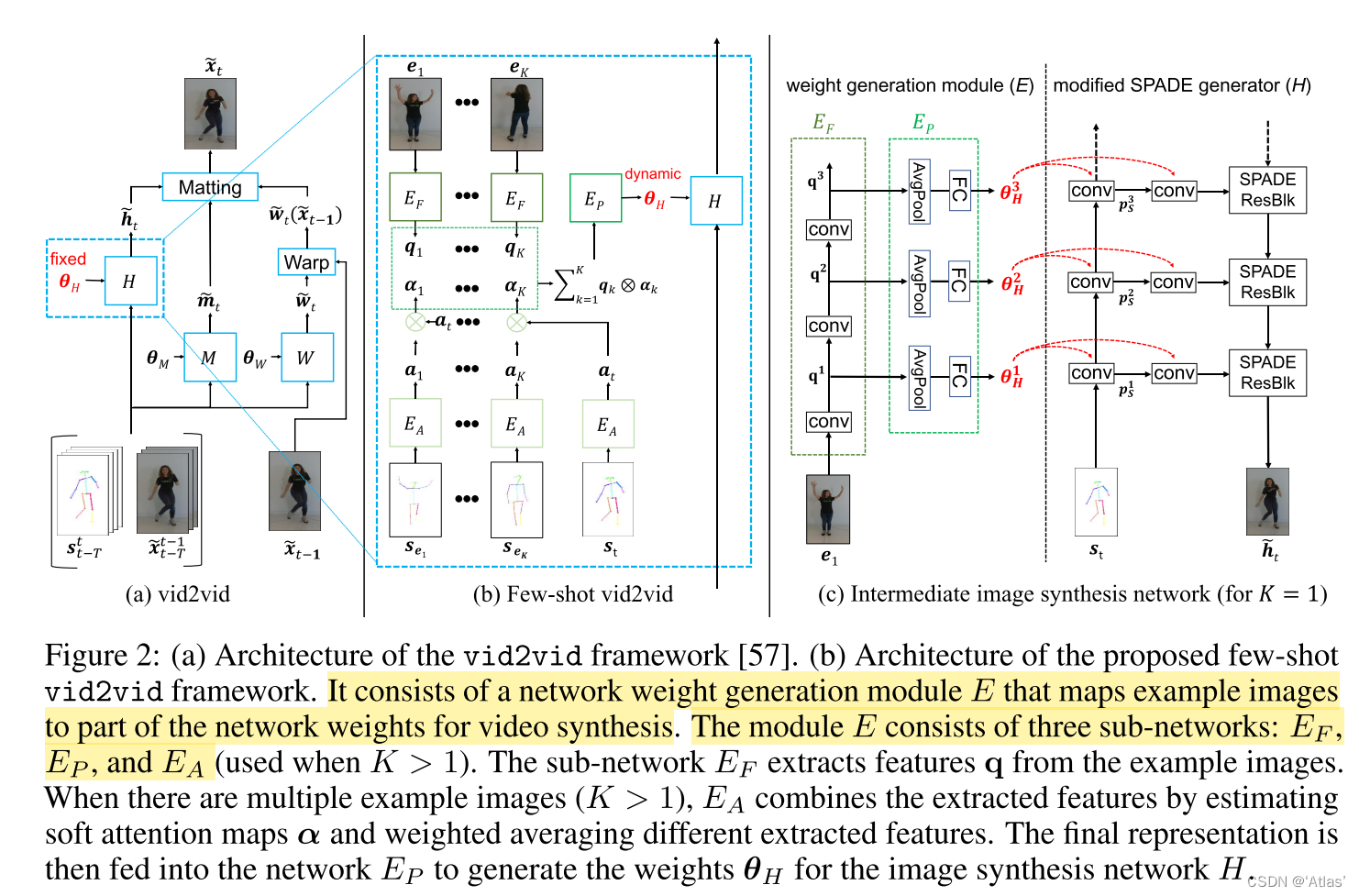
vid2vid programme
vid2vid Structure is shown in figure 2a, The formula is as follows 1,
Generate the image X ~ t \tilde X_t X~t, Based on the past τ + 1 \tau+1 τ+1 Split graph s t − τ t s^t_{t-\tau} st−τt And the past τ \tau τ A generation diagram X ~ t − τ t − 1 \tilde X^ {t-1}_{t-\tau} X~t−τt−1. The general design of the generator is as follows 2,
m ~ t , w ~ t − 1 , h ~ t \tilde m_t,\tilde w_{t-1},\tilde h_t m~t,w~t−1,h~t The learning process is like 3,4,5,
m ~ t \tilde m_t m~t For occluded areas , w ~ t − 1 \tilde w_{t-1} w~t−1 Is optical flow , h ~ t \tilde h_t h~t To generate an intermediate image ;
Few-shot vid2vid
however vid2vid Method cannot generate video without domain , For example, you can only generate people who appear in the training set . In order to make F F F Suitable for domains that have never been seen , Add additional input , therefore F F F There are two inputs :K Sample images of target domains e 1 , e 2 , . . . , e K e_1, e_2, ..., e_K e1,e2,...,eK, And the corresponding semantic map s e 1 , s e 2 , . . . , s e K s_{e_1} , s_{e_2} , ..., s_{e_K} se1,se2,...,seK, Such as the type 6 The model allows F F F Use the input sample mode to generate a video , Therefore, the author uses the network weight generation module E E E Extract the sample mode , Calculate network parameters by using sample modal information θ H \theta_H θH, Such as the type 7.
The model allows F F F Use the input sample mode to generate a video , Therefore, the author uses the network weight generation module E E E Extract the sample mode , Calculate network parameters by using sample modal information θ H \theta_H θH, Such as the type 7.
E E E Not used θ M \theta_M θM And θ W \theta_W θW, Because θ M \theta_M θM And θ W \theta_W θW Generate images based on the past , Itself has been shared across domains ;
E E E Generate weights only for spatially adjusted branches , The design has two advantages :
1、 Reduce E E E Generate parameter quantity , Avoid overfitting ;
2、 Avoid samples and output images shotcut, Because the generated parameters are only used for the space adjustment module
Network weight generation module
E E E Extract appearance mode by learning parameters , Introduce video generation branch ;
Consider entering only 1 A sample (k=1) And several sample cases (k>1);
When the input example is 1, namely k=1 when ,(image animation Mission ) E E E Decouple into two subnetworks : Feature extractor E F E_F EF And multi-layer perceptron E P E_P EP.
Feature extractor E F E_F EF Including several convolution layers , Extract the appearance representation q q q, Applied to multi-layer perceptron E P E_P EP Generate weights θ H \theta_H θH, For intermediate image generation network H H H, H H H Yes L L L layer , E E E There are also L L L layer , Pictured 2c Shown ;
When the input samples are more than 1 when , namely K>1, to want to E E E The appearance mode of any number of samples can be extracted , Because different input samples have different angle correlations , So the author designed attention Mechanism E A E_A EA, Aggregate the extracted appearance modes ;
E A E_A EA Apply to each sample semantic diagram s e k s_{e_k} sek, Get the key vector α k ∈ R C × N \alpha_k \in R^{C \times N} αk∈RC×N, And the current input semantic map s t s_t st, Get the key vector α t ∈ R C × N \alpha_t \in R^{C \times N} αt∈RC×N, And then pass α k = ( α k ) T ⨂ α t \alpha_k = (\alpha_k)^T \bigotimes \alpha_t αk=(αk)T⨂αt, obtain attention The weight α k ∈ R N × N \alpha_k \in R^{N \times N} αk∈RN×N, Applied to appearance characterization q q q. Pictured 2b, In the generation phase attention map Help capture relevant body parts , Pictured 7c.
To reduce the burden of image generation network , Sure wrap Examples , And generate an intermediate image h ~ t ′ \tilde h'_t h~t′ combination , Such as the type 11,
Estimate additional optical flow w ~ e t \tilde w_{e_t} w~et And mask m ~ e t \tilde m_{e_t} m~et, When entering multiple samples , e 1 e_1 e1 by attention weight α k \alpha_k αk The sample with the greatest similarity with the current frame in ; It was found that , When the background area remains unchanged , To generate pose To be helpful to ;
experiment
The author compares different methods to achieve the generalization ability of the target domain , As shown in the table 1;
Encoder Indicates that the coding sample is a sub style vector ;
ConcatStyle Indicates that the coding sample is a sub style vector , Compare it with the input segmentation graph concat, Generate enhanced split input ;
AdaIN stay H After each spatial modulation module, add AdaIN Normalized layer .
The implementation details are shown in the figure 9 Shown ,
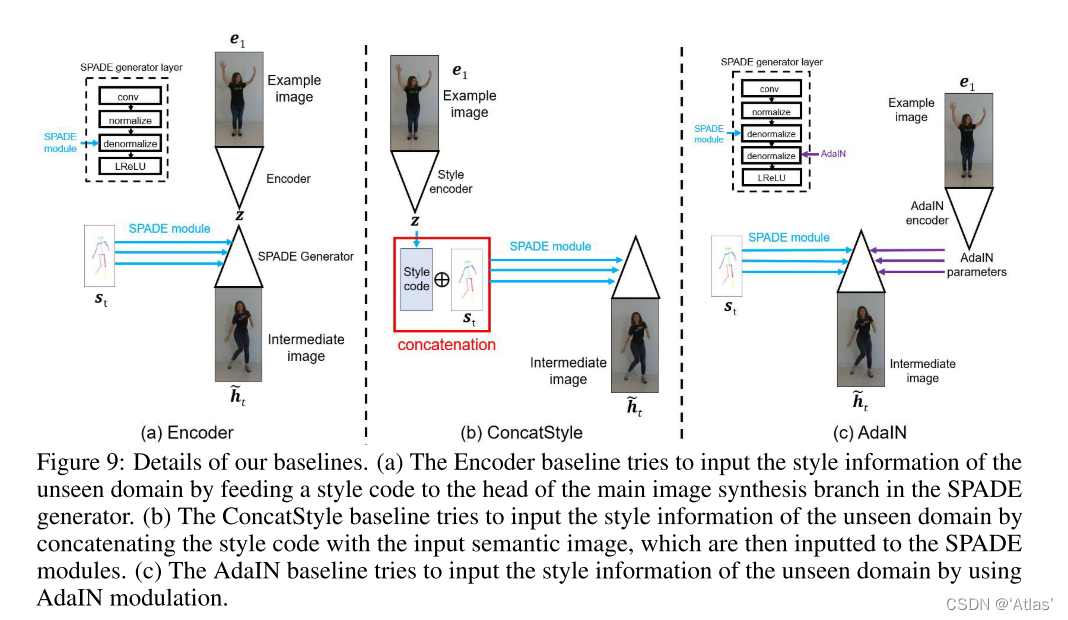
chart 3 Produce different results for the human body 
chart 4 Compare for various methods 
chart 5 Generate results for street scenes 
chart 6 Generate results for the face 
chart 7a Compare the influence of different training sample numbers on the results , chart 7b Compare the impact of different sample numbers on the results , chart 7c visualization attention map result ;
Conclusion
few-shot vid2vid It can generate videos that have never been seen before , Due to the dynamic weight generation mechanism based on the sample image .
But there are still two limitations :
1、 When there is a great difference between the test domain and the training domain , The generation effect is relatively poor ;
2、 When segmentation and key point estimation are inaccurate , The generation effect is relatively poor ;
边栏推荐
- Top priority of dry goods: common indicators and terms in data analysis!
- 1260. Two dimensional grid migration: simple construction simulation problem
- The current situation of the industry is disappointing. After working, I returned to UC Berkeley to study for a doctoral degree
- Pursue and kill "wallet Assassin" all over the network
- Point to point copy and paste of web pages
- Rightmost × Microframe, high quality heif image coding and compression technology
- Login and payment arrangement in uniapp
- [26. String hash]
- Open source demo | release of open source example of arcall applet
- [28. Maximum XOR pair]
猜你喜欢

EasyX realizes button effect

Several schemes of traffic exposure in kubernetes cluster
![[hero planet July training leetcode problem solving daily] 20th BST](/img/25/2d2a05374b0cf85cf123f408c48fe2.png)
[hero planet July training leetcode problem solving daily] 20th BST
Custom type

Web Security Foundation - file upload

How to empty localstorage before closing a page

Worthington carboxyl transfer carbonic anhydrase application and literature reference

Green low-carbon Tianyi cloud, a new engine of digital economy!

Wireshark packet capturing and rapid packet location skills
![[28. Maximum XOR pair]](/img/31/20498377b812116d63fa9999eeb4a8.png)
[28. Maximum XOR pair]
随机推荐
The difference between sigsuspend and sigwait
JS convert pseudo array to array
Password input box and coupon and custom soft keyboard
Some of my understanding about anti shake and throttling
Yolov7:oserror: [winerror 1455] the page file is too small to complete the final solution of the operation
Opengauss kernel analysis: query rewriting
The cloud ecology conference comes with the "peak"!
[programmer interview classic] 01.09 string rotation
Three modes of executing programs, memory and cache
2022/7/18-7/19
Visual studio code installation package download slow & Installation & environment configuration & new one-stop explanation
Example analysis of recombinant monoclonal antibody prosci CD154 antibody
[summer daily question] output of Luogu p1157 combination
[hero planet July training leetcode problem solving daily] 20th BST
Open source demo | release of open source example of arcall applet
Latex notes
How to implement the server anti blackmail virus system is a problem we have to consider
Breederdao's first proposal was released: the constitution of the Dao organization
The solution of displaying garbled code in SecureCRT
Data governance notes