当前位置:网站首页>Paper reading [quovadis, action recognition? A new model and the dynamics dataset]
Paper reading [quovadis, action recognition? A new model and the dynamics dataset]
2022-06-23 08:27:00 【hei_ hei_ hei_】
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
- publish :2017 CVPR
- Main contributions :(1) A large video data set is disclosed , It can be used for transfer learning and network training .(2) A new video action classification model is proposed I3D.
The previous model
a. ConvNet+LSTM
First use CNN Extract the spatial features of the image , Then input in sequence LSTM To extract temporal features from , The last hidden layer is used for action classification .
ps: But the effect is not very good , Therefore, it is not popular
b. 3D-ConvNet
Input a video into , use 3D Convolution directly learns the spatiotemporal features of video . Two dimensional Conv and Pooling All for 3D Of 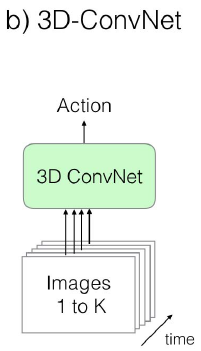
ps: The number of parameters is huge , It is difficult to train for small data sets , But the effect is OK
c. Two-Strean
Use optical flow information ( The flow of light , That is, the motion track of the target in the video ) Time series feature modeling . The input of the convolution network on the left is one or more frames of images , Scene information for learning images ; The convolution network input on the right is the optical flow diagram of the video , It is used to learn the motion information of objects 
ps: The model is simpler , And easy to train , Just extract the optical flow graph of the video and learn the mapping of classification actions , It is widely used
d. 3D-Fused Two-Stream
b and c Combined version of , take c The weighted average in is replaced by 3D ConvNet
summary : With sufficient data ,3DConv Than 2DConv Is much better , But there are still some things that you can't learn well ( Additional information such as optical flow diagram may be required to supplement )
Model framework

(1)inflating
take 2D Network of “ inflation ” become 3D, Keep the architecture unchanged . The network architecture remains unchanged , Just will 2D Conv Switch to 3D Conv,2D Pooling Switch to 3D Pooling. In this way, you can directly use the previous 2D The Internet
(2)Bootstrapping
How to train good 2D The parameters of the model are right 3D The model is initialized . The basic idea is for the same input , The output of the two models should be consistent . Specifically, copy an image n One video at a time ,2D Parameters of are copied in time latitude n Time , Then the parameter is divided by n(rescaling, It is used to ensure the consistency of input and output )
(3) Model details

ps: But now we basically use Resnet
边栏推荐
- Which one is better for rendering renderings? 2022 latest measured data (IV)
- Derivation and loading of the trained random forest model
- 5-旋转的小菊-旋转画布和定时器
- C restart application
- 6-shining laser application of calayer
- How to solve the problem that flv video stream cannot be played and TS file generation fails due to packet loss?
- 渲染效果图哪家好?2022最新实测(四)
- “方脸老师”董宇辉再回应热度下降:把农产品直播做好让农民受益 考虑去支教
- Go 数据类型篇(三)之整型及运算符
- 复选框的基本使用与实现全选和反选功能
猜你喜欢

Deep learning ----- different methods to realize vgg16
Monitor the cache update of Eureka client

船长阿布的灵魂拷问

Keng dad's "dedication blessing": red packet technology explosion in Alipay Spring Festival Gala

给你的win10装一个wget
开源软件、自由软件、Copyleft、CC都是啥,傻傻分不清楚?

Why do we say that the data service API is the standard configuration of the data midrange?
![[paper notes] catching both gray and black swans: open set supervised analog detection*](/img/52/787b25a9818cfc6a1897af81d41ab2.png)
[paper notes] catching both gray and black swans: open set supervised analog detection*

jmeter压测结果分析

81 sentences worth repeating
随机推荐
Vulnhub | DC: 3 |【实战】
Focus! Ten minutes to master Newton convex optimization
训练后的随机森林模型导出和加载
Do not put files with garbled names into the CFS of NFS protocol
C RichTextBox controls the maximum number of rows
3-progressbar and secondary cropping
ThreadPoolExecutor线程池实现原理与源码解析
Idea true permanent activation method and permanent activation code tutorial
Third party payment in the second half: scuffle to symbiosis
Openvino series 18 Real time object recognition through openvino and opencv (RTSP, USB video reading and video file reading)
Huawei ECS EIP cannot be pinged
Analysis of JMeter pressure measurement results
Crawler frame
给你的win10装一个wget
Install a WGet for your win10
Structure and usage of transform
Arclayoutview: implementation of an arc layout
Set interface and set sub implementation classes
看了5本书,我总结出财富自由的这些理论
9 ways in which network security may change in 2022