当前位置:网站首页>Understand the data consistency between MySQL and redis
Understand the data consistency between MySQL and redis
2022-06-23 22:32:00 【Star sink】
Main ideas of this paper :
1. Understanding consistency ; 2. Reverse the inconsistent situation ; 3. Explore inconsistencies in a single thread ; 4. Explore inconsistencies in multithreading ; 5. Develop a data consistency strategy ; 6. Add details
1. What is data consistency
“ The data is consistent ” It usually refers to : Data in cache , Cached data values = Values in the database .
But according to the data in the cache , be ” Agreement “ There can be two situations :
- Data in cache , Cached data values = Values in the database ( All values must be the latest , This article will “ Consistency of old values ” Classified as “ Inconsistent state ”)
- There is no data in the cache , Values in the database = Latest value ( When there is a request to query the database , The data is written to the cache , It becomes the above “ Agreement ” state )
” Data inconsistency “: Cached data values ≠ Values in the database ; There are old values in the cache or database , Cause other threads to read old data
2. Data inconsistency and countermeasures
Depending on whether a write request is received , The cache can be divided into read-write cache and read-only cache .
A read-only cache : Data lookup only in the cache , That is to use “ Update the database + Delete cache ” Strategy ;
Read write buffer : The data needs to be added, deleted, modified and queried in the cache , That is to use “ Update the database + Update cache ” Strategy .
2.1 For read-only cache ( Update the database + Delete cache )
A read-only cache : When adding data , Write directly to the database ; to update ( modify / Delete ) Data time , So let's delete the cache . follow-up , When accessing these added, deleted and modified data , There will be a cache miss , Then query the database , Update cache .
- When adding data , Write to database ; When accessing data , Cache missing , Database search , Update cache ( Always in ” The data is consistent “ The state of , Data inconsistency will not occur )
- to update ( modify / Delete ) Data time , There will be a timing problem : The order of updating the database and deleting the cache ( Data inconsistency will occur in this process )
In the process of updating data , There may be the following problems :
- No concurrent requests , One of the operations failed
- Concurrent requests , Other threads may read old values
therefore , To achieve data consistency , Two things need to be guaranteed :
- No concurrent requests , Guarantee A and B All steps can be successfully executed
- Concurrent requests , stay A and B In the interval of steps , Avoid or eliminate the impact of other threads
Next , We are aiming at / No concurrent scenarios , Analyze and use different strategies .
A. No concurrency
No concurrent requests , In the process of updating the database and deleting cached values , Because the operation is split into two steps , Then it is likely to exist “ step 1 success , step 2 Failure ” What happened ( Because steps in a single thread 1 And steps 2 It's serial , Unlikely to happen “ step 2 success , step 1 Failure ” The situation of ).
(1) So let's delete the cache , Update the database
(2) Update the database first , Delete the cache
Execution sequence | Potential problems | result | Is there a consistency problem |
|---|---|---|---|
So let's delete the cache , Update the database after | Delete cache succeeded , Database update failed | Request failed to hit cache , Read old database values | yes |
Update the database first , Delete cache after | Update database successful , Delete cache failed | Request hit cache , Read cached old values | yes |
Solutions :
a. Message queue + Asynchronous retry
No matter which execution timing is used , You can perform step 1 when , Will step 2 Write the request to the message queue , When step 2 When the failure , You can use the retry policy , The failed operation is corrected “ compensate ”.
The specific steps are as follows :
- Generate a message for the operation to delete the cache value or update the database value , Staging to message queue ( For example, using Kafka Message queue );
- When the operation of deleting the cache value or updating the database value is successful , Remove these messages from the message queue ( discarded ), So as not to repeat the operation ;
- When the operation of deleting the cache value or updating the database value fails , Execute failed policy , The retry service re reads from the message queue ( consumption ) The news , Then delete or update again ;
- When deletion or update fails , Need to retry again , Retry more than a certain number of times , Send error message to the business layer .
b. subscribe Binlog Change log
- Create update cache service , Receiving data changes MQ news , Then consume the news , to update / Delete Redis Cache data in ;
- Use Binlog Real time updates / Delete Redis cache . utilize Canal, The service responsible for updating the cache is disguised as MySQL The slave node , from MySQL receive Binlog, analysis Binlog after , Get real-time data change information , Then update according to the change information / Delete Redis cache ;
- MQ+Canal Strategy , take Canal Server The received Binlog The data is delivered directly to MQ Decoupling , Use MQ Asynchronous consumption Binlog journal , This is used for data synchronization ;
No use MQ/Canal perhaps MQ+Canal To update the cache asynchronously , The data reliability and real-time requirements of the whole update service are relatively high , If data loss or update delay occurs , Can cause MySQL and Redis The data in is inconsistent . therefore , When using this strategy , It is necessary to consider the degradation or compensation scheme in case of out of synchronization problems .
B. High concurrency
After using the above strategy , It can be guaranteed in a single thread / Data consistency without concurrency . however , In high concurrency scenarios , Due to the read-write concurrency at the database level , This will cause inconsistency between the database and the cached data ( The essence is that the subsequent read request returns first )
(1) So let's delete the cache , Update the database
Assuming that thread A After deleting the cached value , The database was not updated due to network delay , And then , Threads B When you start reading data, you will find that the cache is missing , Then query the database . And when threads B Finished reading data from the database 、 After updating the cache , Threads A Just started updating the database , here , It will cause the data in the cache to be old values , And in the database is the latest value , produce “ Data inconsistency ”. Its essence is , Should have happened after “B Threads - Read request ” Precede “A Threads - Write requests ” Execute and return .
Time | Threads A | Threads B | problem |
|---|---|---|---|
T1 | Delete data X The cache value of | ||
T2 | 1. Read cache data X, Cache missing , Reading data from a database X | Threads B Old value read | |
T3 | 2. Put the data X The value of is written to the cache | Cause other threads to read the old value | |
T4 | Update the data in the database X Value | Cache is old value , The database is old , Leading to data inconsistency |
perhaps
Time | Threads A | Threads B | problem |
|---|---|---|---|
T1 | Delete data X The cache value of | ||
T2 | 1. Read cache data X, Cache missing , Reading data from a database X | Threads B Old value read | |
T3 | Update the data in the database X Value | ||
T4 | 2. Put the data X The value of is written to the cache | Cache is old value , The database is old , Leading to data inconsistency |
Solutions :
a. Set cache expiration time + Delay double delete
By setting the cache expiration time , In case of the above-mentioned cache obsolescence failure , After the cache expires , Read requests can still be from DB Read the latest data and update the cache , It can reduce the influence range of data inconsistency . Although there are differences in data over a certain time range , But it can ensure the final consistency of the data .
Besides , It can also be guaranteed through delayed double deletion : In a thread A After updating the database values , Let it go first sleep For a short time , Ensure threads B Be able to read data from the database first , Then write the missing data to the cache , then , Threads A Then delete . follow-up , When other threads read data , Missing cache found , The latest value will be read from the database .
redis.delKey(X) db.update(X) Thread.sleep(N) redis.delKey(X)
sleep Time : When the business program is running , Count the operation time of thread reading data and writing cache , Estimate on this basis
Time | Threads A | Threads C | Threads D | problem |
|---|---|---|---|---|
T5 | sleep(N) | Read cached old value | Other threads may read old values during this period | |
T6 | Delete data X The cache value of | |||
T7 | Cache missing , Reading data from a database X The latest value of |
Be careful : If it's hard to accept sleep This kind of writing , Delay queues can be used instead .
Delete the cache value before updating the database , It may cause requests to access the database due to missing cache , Put pressure on the database , That is, cache penetration . For cache penetration , You can cache empty results 、 Bloom filter to solve .
(2) Update the database first , Delete the cache
If the thread A Updated the value in the database , But I haven't had time to delete the cache value , Threads B Start reading data , So at this time , Threads B When querying the cache , Find cache hits , The old value will be read directly from the cache . Its essence is also , Should have happened after “B Threads - Read request ” Precede “A Threads - Delete cache ” Execute and return .
Time | Threads A | Threads B | Potential problems |
|---|---|---|---|
T1 | Update the data in the database X | ||
T2 | Reading data X, Hit cache , Read from cache X, Read old values | Threads A Cached values have not been deleted , Cause threads B Old value read | |
T3 | Delete cached data X |
perhaps , stay ” Update the database first , Delete the cache ” Under the plan ,“ Read / write separation + Master slave delay ” It can also lead to inconsistencies :
Time | Threads A | Threads B | MySQL colony | Potential problems |
|---|---|---|---|---|
T1 | Update master library X = 2( Original value X = 1) | |||
T2 | Delete cache | |||
T3 | The query cache , missed , Query from library , Get old value ( Slave Library X = 1) | |||
T4 | Write the old value to the cache (X = 1) | |||
T5 | Synchronization from Library completed ( Master-slave library X = 2) | Final X The value of in the cache is 1( The old value ), In the master-slave library is 2( The new value ), Inconsistencies also occur |
Solution :
a. Delay message
Send... With experience 「 Delay message 」 Go to the queue , Delay delete cache , At the same time, it is also necessary to control the delay of the master-slave Library , Minimize the probability of inconsistency
b. subscribe binlog, Delete asynchronously
Through the database binlog To eliminate key, utilize an instrument (canal) take binlog Log collection sent to MQ in , And then through ACK Mechanism confirmation processing delete cache .
c. Delete message write to database
By comparing the data in the database , Confirm the deletion First update the database and then delete the cache , It may cause requests to access the database due to missing cache , Put pressure on the database , That is, cache penetration . For cache penetration , You can cache empty results 、 Bloom filter to solve .
d. Lock
When updating data , Add write lock ; When querying data , Add read lock Ensure the of two-step operation “ Atomicity ”, Enables operations to be performed serially .“ Atomicity ” What is the essence of ? Indivisibility is only an external manifestation , Its essence is the requirement of consistency among multiple resources , The intermediate state of the operation is not visible to the outside .
Suggest :
priority of use “ First update the database and then delete the cache ” Execution timing of , There are two main reasons :
- Delete the cache value before updating the database , It may cause requests to access the database due to missing cache , Put pressure on the database ;
- In business applications, it is sometimes difficult to estimate the time to read the database and write the cache , This leads to... In delayed double deletion sleep Time is not easy to set .
2.2 For read-write cache ( Update the database + Update cache )
Read write buffer : Additions, deletions and changes are made in the cache , And adopt the corresponding write back strategy , Synchronize data to the database
- Synchronous direct writing : With a transaction , Ensure the atomicity of cache and data update , And retry the failure ( If Redis It's not working , It will reduce the performance and availability of the service )
- Asynchronous write back : Write to the database is not synchronized when writing to the cache , Wait until the data is eliminated from the cache , Write back to the database ( Before writing back to the database , Cache failure , Can cause data loss ) This strategy has been seen in the second kill field , The business layer directly operates the second kill commodity inventory information in the cache , Write back to the database after a period of time .
Uniformity : Synchronous direct writing > Asynchronous write back therefore , For read-write caching , The main idea to maintain strong data consistency is : Using synchronous write through Synchronous write through also has two timing problems : Update database and update cache
A. No concurrency
Execution order | Potential problems | result | Is there a consistency problem | Solutions |
|---|---|---|---|---|
Update cache first , Update the database after | Update cache successful , Database update failed | Old value in database | yes | Message queue + Retry mechanism |
Update the database first , Update cache after | Update database successful , Failed to update cache | Request hit cache , Read cached old values | yes | Message queue + Retry mechanism ; subscribe Binlog journal |
B. High concurrency
There are four scenarios that cause data inconsistency :
sequential | Concurrency type | Potential problems | Influence degree |
|---|---|---|---|
Update the database first , Update the cache again | Write + Read concurrent | 1. Threads A Update the database first 2. Threads B Reading data , Hit cache , Old value read 3. Threads A Update cache successful , Subsequent read requests will hit the cache to get the latest value | In this case , Threads A Before updating the cache , During this period, the read request will briefly read the old value , Short term impact on business |
Update cache first , Update the database | Write + Read concurrent | 1. Threads A Update the cache first 2. Threads B Reading data , The thread B Hit cache , Read the latest value and return 3. Threads A Update database successful | In this case , Although threads A The database has not been updated yet , There will be a brief inconsistency between the database and the cache , But all incoming read requests can hit the cache directly , Getting the latest value has little impact on the business |
Update the database first , Update the cache again | Write + Write concurrent | 1. Threads A And thread B Update the same data at the same time 2. Update the database first A after B 3. When updating the cache, the order is first B after A | This will cause inconsistency between the database and the cache , Great impact on business |
Update cache first , Update the database | Write + Write concurrent | 1. Threads A And thread B Update the same data at the same time 2. The order of updating the cache is first A after B 3. Update the database first B after A | This will cause inconsistency between the database and the cache , Great impact on business |
Aimed at the scene 1 and 2 The solution is : Save the read record of the request to the cache , Delay message comparison , When inconsistencies are found , Do business compensation Aimed at the scene 3 and 4 The solution is : For write requests , It needs to be used with distributed locks . Write a request when you come in , Modify the same resource , Add a distributed lock first , Ensure that there is only one thread to update the database and cache at the same time ; The thread that does not get the lock puts the operation into the queue , Delay processing . In this way, the sequence of multiple threads operating the same resource is guaranteed , To ensure consistency .
among , The implementation of distributed locks can use the following strategies :
Distributed lock policy | Realization principle |
|---|---|
Optimism lock | Use version number 、updatetime; In cache , Only the higher version is allowed to overwrite the lower version |
Watch Realization Redis Optimism lock | watch monitor redisKey The state of the value , establish redis Business ,key+1, Perform transactions ,key If it is modified, it will be rolled back |
setnx | Get the lock :set/setnx; Release the lock :del command /lua Script |
Redisson Distributed lock | utilize Redis Of Hash Structure as a storage unit , Take the name specified by the business as key, Will be random UUID And thread ID As field, Finally, the number of locks is taken as value To store ; Thread safety |
2.3 Strong consistency strategy
The above strategy can only ensure the final consistency of data . To achieve strong consistency , The most common solution is 2PC、3PC、Paxos、Raft Such consistency protocols , But their performance is often poor , And these schemes are more complex , Also consider various fault tolerance issues . If the business layer requires strong consistency of data to be read , You can take the following strategies :
(1) Staging concurrent read requests
When updating the database , First in Redis Cache client staging concurrent read requests , When the database is updated 、 After the cache value is deleted , Read the data again , To ensure data consistency .
(2) Serialization
Read and write requests are queued , The worker thread takes tasks from the queue and executes them in turn
- Modify service Service Connection pool ,id Take the module and select the service connection , It can ensure that the reading and writing of the same data fall on the same back-end service
- modify the database DB Connection pool ,id Take the mold and select DB Connect , It can ensure that the reading and writing of the same data is serial at the database level
(3) Use Redis Distributed read and write locks
Put the obsolete cache and the update library table into the same write lock , Mutually exclusive with other read requests , Prevent the generation of old data . Reading and writing are mutually exclusive 、 Writing mutually exclusive 、 Read read share , It can meet the requirements of data consistency in scenarios with more reading and less writing , It also ensures concurrency . And according to the logical average running time 、 Response timeout to determine expiration time .
public void write() {
Lock writeLock = redis.getWriteLock(lockKey);
writeLock.lock();
try {
redis.delete(key);
db.update(record);
} finally {
writeLock.unlock();
}
}
public void read() {
if (caching) {
return;
}
// no cache
Lock readLock = redis.getReadLock(lockKey);
readLock.lock();
try {
record = db.get();
} finally {
readLock.unlock();
}
redis.set(key, record);
}2.4 Summary
Cache type | Consistency main strategy | advantage | shortcoming | Applicable scenario |
|---|---|---|---|---|
Read write buffer | Update the database + Update cache | There will always be data in the cache , If you visit again immediately after the update operation , You can hit the cache directly , It can reduce the pressure of read requests on the database | If the updated data , It is rarely visited again after , This will cause the cache to retain data that is not the hottest , Cache utilization is not high , Waste cache resources | Reading and writing are quite |
A read-only cache | Update the database + Delete cache | The read-only cache holds hot data , High cache utilization | The process of deleting a cache and causing the cache to be lost and reloaded ; When the cache is missing , Causes a large number of requests to fall to the database , Crush the database | Read more and write less |
For read-write caching : Synchronous direct writing , Update the database + Update cache
Sequence of operation | Whether there are concurrent requests | Potential problems | result | Response plan |
|---|---|---|---|---|
Update the database first , Update the cache again | nothing | Database update succeeded , But updating the cache failed | Request to read old data from cache | Retry cache update |
Write + read | Threads A Before updating the cache , Threads B The old value will be read briefly in the read request of | Request to read old data from the transient cache | Save read records , Make compensation | |
Write + Write | Update the database first A after B, But when updating the cache, the order is first B after A | The database and cache data are inconsistent | Distributed lock | |
Update cache first , Update the database | nothing | Cache update successful , But updating the database failed | Old values exist in the database | Retry database update |
Write + read | Threads A The database has not been updated yet , But all incoming read requests can hit the cache directly , Get the latest value | There is a temporary inconsistency between the database and the cache , But it does not affect the business | MQ Confirm that the database update is successful | |
Write + Write | The order of updating the cache is first A after B, But when updating the database, the order is first B after A | The database and cache data are inconsistent | Distributed lock |
For read-only cache : Update the database + Delete cache
Sequence of operation | Whether there are concurrent requests | Potential problems | The phenomenon | Response plan |
|---|---|---|---|---|
Delete the cache value first , Update the database | nothing | Cache delete succeeded , But database update failed | Request to read old data from the database | Retry database update |
Yes | After the cache is deleted , The database has not been updated , There are concurrent read requests | Concurrent requests read old values from the database , And update to the cache , Cause subsequent requests to read the old value | Delay double delete ; Lock | |
Update the database first , Delete the cache | nothing | Database update succeeded , But cache deletion failed | Request to read old data from cache | Retry cache deletion |
Yes | After the database is updated successfully , The cache has not been deleted , There are concurrent read requests | Concurrent requests read old values from the cache | Delay message ; Subscribe to change logs ; Lock |
A more general consistency strategy is proposed :
In a concurrent scenario , Use “ Update the database + Update cache ” Distributed locks are needed to ensure cache and data consistency , And there may be ” Cache resources are wasted “ and ” Machine performance waste “ The situation of ; Generally recommended “ Update the database + Delete cache ” The plan . If necessary , There are many hot data , have access to “ Update the database + Update cache ” Strategy .
stay “ Update the database + Delete cache ” The scheme , It is recommended to use “ Update the database first , Delete the cache ” Strategy , Because deleting the cache first may cause a large number of requests to fall into the database , And the delay time of double deletion is difficult to evaluate . stay “ Update the database first , Delete the cache ” Strategy , have access to “ Message queue + Retry mechanism ” The scheme guarantees the deletion of the cache . And pass “ subscribe binlog” Cache comparison , Add a layer of protection .
Besides , You need to initialize the cache 、 Multiple data sources trigger 、 Delayed messages are assisted and compensated more than peer-to-peer policies . 【 Multiple data update trigger sources : Scheduled task scan , Business system MQ、binlog change MQ, They complement each other to ensure that the data will not be updated 】
3. What other issues need to be paid attention to in data consistency ?
3.1 k-v Reasonable setting of size
Redis key Size design : Due to a transmission of the network MTU The maximum is 1500 byte , So in order to ensure efficient performance , Suggest a single k-v Not larger than 1KB, One network transmission can complete , Avoid multiple network interactions ;k-v The smaller the, the better the performance Redis heat key:(1) When the business encounters a single read hot key, Improve reading ability by adding copies or use hashtag hold key Save multiple copies in multiple slices ;(2) When a business encounters a single write hot key, The business needs to be split key The function of , The design is unreasonable - When business encounters hot fragmentation , That is, multiple heat key A single slice is caused on the same slice cpu high , It can be done by hashtag Break up
3.2 Avoid other problems that cause the cache server to crash , In turn, it almost leads to the failure of data consistency strategy
Such as cache penetration 、 Cache breakdown 、 Cache avalanche 、 Problems such as machine failure
problem | describe | Solution |
|---|---|---|
Cache penetration | Query a nonexistent data , Cannot hit cache , Cause every request to arrive DB Go to query , May cause the database to crash | 1. The data returned by the query is empty , Still cache this empty result , But the expiration time will be shorter ; 2. The bloon filter : Hash all possible data to a large enough bitmap in , A certain nonexistent data will be bitmap Intercept , So as to avoid to DB Query for |
Cache breakdown | For key, When the cache expires at a certain point in time , There happens to be a lot of people on this key Concurrent requests for , It may cause a large number of concurrent requests to overwhelm the database in an instant | 1. Use mutexes : When the cache fails , First use the Redis Of setnx To set a mutex , When the operation returns successfully, perform the database operation and reset the cache , Otherwise try again get Caching method ; 2. Never expire : Physics doesn't expire , But the logic is out of date ( Background asynchronous thread to refresh ) |
Cache avalanche | The cache is set with the same expiration time , The cache fails at the same time at a certain time , Results in a large number of requests to access the database . The difference from cache breakdown : Avalanches are many key, The breakdown is single key cache | 1. Decentralized cache expiration time : A random value is added to the original failure time ; 2. Use mutexes , When cached data fails , Ensure that only one request can access the database , And update the cache , Other threads wait and try again |
3.3 The idea of scheme selection
- Determine the cache type ( Reading and writing / read-only )
- Determine the consistency level
- Confirm synchronization / Asynchronous way
- Select cache process
- Add details
Reference resources
https://xie.infoq.cn/article/1322475e05c11bd2aacd8bc73https://www.infoq.cn/article/Hh4IOuIiJHWB4X46vxeOhttps://time.geekbang.org/column/article/217593https://xie.infoq.cn/article/ab2599366009928a17fe498fbhttps://mp.weixin.qq.com/s?spm=a2c6h.12873639.0.0.2020fe8dDvjfTJ&__biz=MjM5ODYxMDA5OQ==&mid=404202261&idx=1&sn=1b8254ba5013952923bdc21e0579108e&scene=21#wechat_redirecthttps://time.geekbang.org/column/article/295812https://blog.csdn.net/chengh1993/article/details/112685774https://juejin.cn/post/6850418120201666568
边栏推荐
- [tcapulusdb knowledge base] update data example (TDR table)
- PHP laravel 8.70.1 - cross site scripting (XSS) to cross Site Request Forgery (CSRF)
- How to configure Nessus vulnerability scanning policy?
- How to lossless publish API gateway why do you need API gateway?
- How to build a website after registering a domain name
- What is stock online account opening? Is it safe to open a mobile account?
- How does H5 communicate with native apps?
- Start learning simple JS
- Why is the server fortress machine error code 110? How to solve error code 110?
- Low code technology
猜你喜欢

Opengauss Developer Day 2022 was officially launched to build an open source database root community with developers

The latest research progress of domain generalization from CVPR 2022
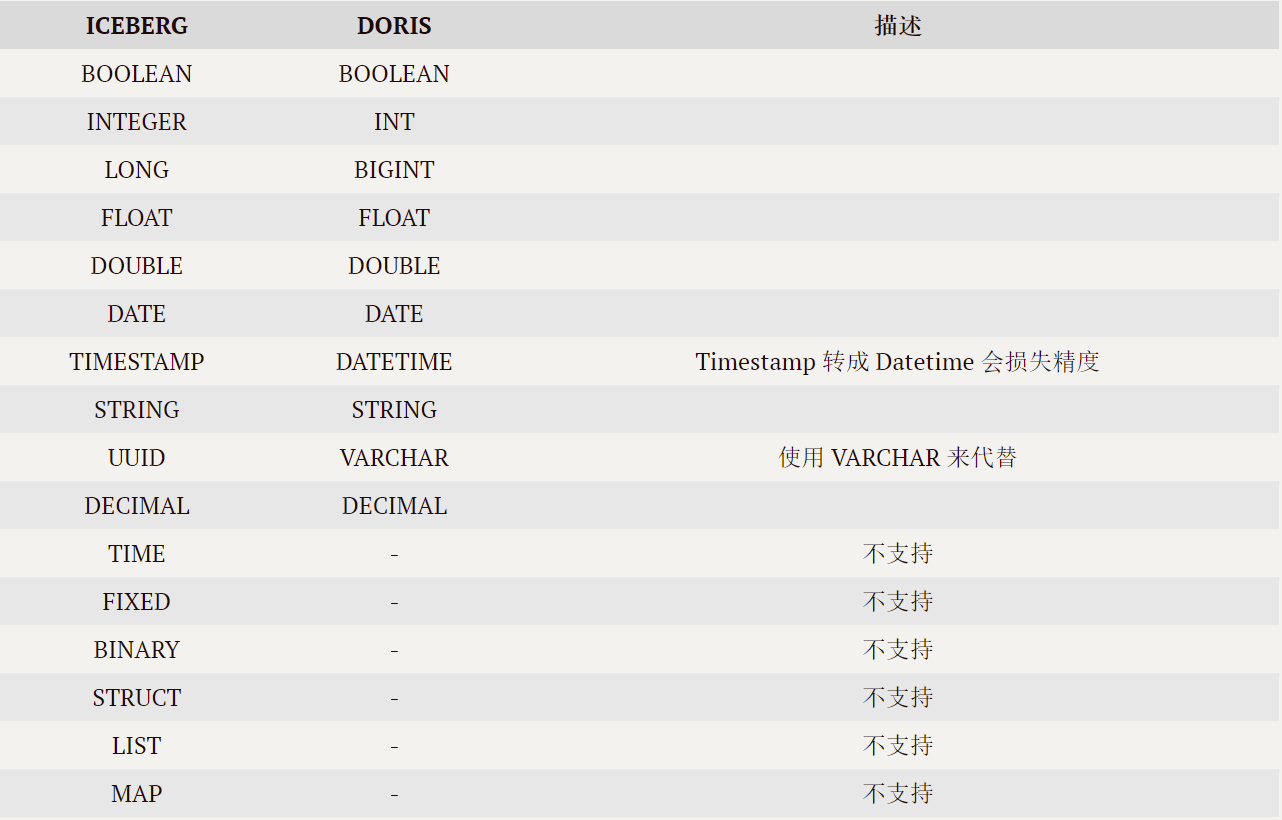
Application practice | Apache Doris integrates iceberg + Flink CDC to build a real-time federated query and analysis architecture integrating lake and warehouse

Why is only one value displayed on your data graph?

Slsa: accelerator for successful SBOM
应用实践 | Apache Doris 整合 Iceberg + Flink CDC 构建实时湖仓一体的联邦查询分析架构

在宇宙的眼眸下,如何正确地关心东数西算?
openGauss Developer Day 2022正式开启,与开发者共建开源数据库根社区

游戏安全丨喊话CALL分析-写代码
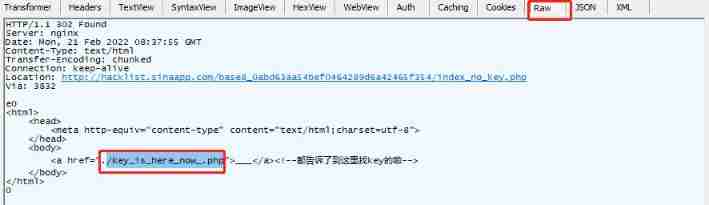
Hackinglab penetration test question 8:key can't find it again
随机推荐
2008R2 CFS with NFS protocol
How to set secondary title in website construction what is the function of secondary title
Redis source code analysis -- QuickList of redis list implementation principle
Micro build low code tutorial - variable definition
What should I do if the RDP fortress server connection times out? Why should enterprises use fortress machines?
What are the steps required for TFTP to log in to the server through the fortress machine? Operation guide for novice
2021-12-18: find all letter ectopic words in the string. Given two characters
Icml2022 | robust task representation for off-line meta reinforcement learning based on contrastive learning
应用实践 | Apache Doris 整合 Iceberg + Flink CDC 构建实时湖仓一体的联邦查询分析架构
In the new easygbs kernel version, the intranet mapping to the public network cannot be played. How to troubleshoot?
What should be done when the encryptor fails to authenticate in the new version of easycvr?
Judge whether the target class conforms to the section rule
In the "Internet +" era, how can the traditional wholesale industry restructure its business model?
How do fortress computers log in to the server? What is the role of the fortress machine?
The article "essence" introduces you to VMware vSphere network, vswitch and port group!
What is the was fortress server restart was command? What are the reasons why was could not be restarted?
VNC multi gear resolution adjustment, 2008R2 setting 1280 × 1024 resolution
Activiti practice
How to set up external links in website construction
[vulnerability recurrence]log4j vulnerability rce (cve-2021-44228)