当前位置:网站首页>Optimizing for vectorization
Optimizing for vectorization
2022-06-26 14:38:00 【maray】
本文是 ARM 开发者文档,原文地址:https://developer.arm.com/documentation/den0018/a/Compiling-NEON-Instructions/Vectorization/Optimizing-for-vectorization
The C and C++ languages do not provide syntax that specifies concurrent behavior, so compilers cannot safely generate parallel code. However, the developer can provide additional information to let the compiler know where it is safe to vectorize.
Unlike intrinsics, these modifications are not architecture dependent, and are likely to improve vectorization on any target platform. These modifications usually do not have negative impact on performance on targets where vectorization is not possible.
The following describe the main rules:
- Short, simple loops work best (even if it means multiple loops in your code).
- Avoid using a break statement to exit a loop.
- Try to make the number of iterations a power of two.
- Try to make sure the number of iterations is known to the compiler.
- Functions called inside a loop should be inlined.
- Using arrays with indexing vectorizes better than using pointers.
- Indirect addressing (multiple indexing or dereferencing) does not vectorize.
- Use the
restrictkeyword to tell the compiler that pointers do not reference overlapping areas of memory.
Indicate knowledge of number of loop iterations
If a loop has a fixed iteration count, or if you know that the iteration count is always a power of 2, making this obvious to the compiler enables the compiler to perform optimizations that would otherwise be unsafe or difficult.
Example 2.1 shows a function accumulating a number (len) of int-sized elements. If you know that the value passed as len is always a multiple of four, you can indicate this to the compiler by masking off the bottom two bits when comparing the loop counter to len. This ensures that the loop always executes a multiple of four times. Therefore the compiler can safely vectorize and:
does not need to add code for runtime checks on len
does not need to add code to deal with over-hanging iterations.
int accumulate(int * c, int len)
{
int i, retval;
for(i = 0, retval = 0; i < (len & ~3) ; i++)
{
retval = retval + c[i]
}
return retval;
}
Avoid loop-carried dependencies
If your code contains a loop where the result of one iteration is affected by the result of a previous iteration, the compiler cannot vectorize it. If possible, restructure the code to remove any loop-carried dependencies.
Use the restrict keyword
C pointer aliasing
A major challenge in optimizing Standard C (ISO C90) is because you can de-reference pointers which might (according to the standard) point to the same or overlapping datasets.
As the C standard evolved, this issue was addressed by adding the keyword restrict to C99 and C++. Adding restrict to a pointer declaration is a promise that only this pointer will access the address it is pointing to. This enables the compiler to do the work in setup and exit restrictions, preload data with plenty of advance notice, and cache the intermediate results.
C99 introduced the restrict keyword, that you can use to inform the compiler that the location accessed through a specific pointer is not accessed through any other pointer within the current scope.
Example 2.2 shows a situation where using restrict on a pointer to a location being updated makes vectorization safe when it otherwise would not be.
int accumulate2(char * c, char * d, char * restrict e, int len)
{
int i;
for(i=0 ; i < (len & ~3) ; i++)
{
e[i] = d[i] + c[i];
}
return i;
}
Without the restrict keyword, the compiler must assume that e[i] can refer to the same location as d[i + 1], meaning that the possibility of a loop-carried dependency prevents it from vectorizing this sequence. With restrict, the programmer informs the compiler that any location accessed through e is only accessed through pointer e in this function. This means the compiler can ignore the possibility of aliasing and vectorize the sequence.
Using the restrict keyword does not enable the compiler to perform additional checks on the function call. Hence, if the function is passed values for c or d that overlap with the value for e, the vectorized code might not execute correctly.
Both GCC and ARM Compiler toolchain support the alternative forms restrict and __restrict when not compiling for C99. ARM Compiler toolchain also supports using the restrict keyword with C90 and C++ when --restrict is specified on the command line.
Avoid conditions inside loops
Normally, the compiler cannot vectorize loops containing conditional statements. In the best case, it duplicates the loop, but in many cases it cannot vectorize it at all.
Use suitable data types
When optimizing some algorithms operating on 16-bit or 8-bit data without SIMD, sometimes you get better performance if you treat them as 32-bit variables. When producing software targeting automatic vectorization, for best performance always use the smallest data type that can hold the required values. This means a NEON register can hold more data elements and execute more operations in parallel. In a given period, the NEON unit can process twice as many 8-bit values as 16-bit values.
Also, NEON technology does not support some data types, and some are only supported for certain operations. For example, it does not support double-precision floating-point, so using a double-precision double where a single-precision float is sufficient can prevent the compiler from vectorizing code. NEON technology supports 64-bit integers only for certain operations, so avoid using long long variables where possible.
Note
NEON technology includes a group of instructions that can perform structured load and store operations. These instructions can only be used for vectorized access to data structures where all members are of the same size.
Floating-point vectorization
Floating-point operations can result in loss of precision. The order of the operations or floating-point inputs can be arranged to reduce the loss in precision. Changing the order of the operations or inputs can result in further loss in precision. Hence some floating-point operations are not vectorized by default because vectorizing can change the order of the operations. If the algorithm does not require this level of precision, you can specify --fpmode=fast, for armcc, or -ffast-math, for GCC, on the command line to enable these optimizations.
Example 2.3 shows a sequence that can only be vectorized with one of these parameters specified. In this case, it performs parallel accumulation, potentially reducing the precision of the result.
float g(float const *a)
{
float r = 0;
int i;
for (i = 0 ; i < 32 ; ++i)
r += a[i];
return r;
}
The NEON unit always operates in Flush-to-Zero mode (see Flush-to-zero mode), making it non-compliant with IEEE 754. By default, armcc uses --fpmode=std, permitting the deviations from the standard. However, if the command line parameters specify a mode option requiring IEEE 754 compliance, for example --fpmode=ieee_full, most floating-point operations cannot be vectorized.
边栏推荐
- ArcGIS batch render layer script
- View touch analysis
- Oracle ASMM和AMM
- wptx64能卸载吗_win10自带的软件哪些可以卸载
- Leaflet load day map
- R语言glm函数逻辑回归模型、使用epiDisplay包logistic.display函数获取模型汇总统计信息(自变量初始和调整后的优势比及置信区间,回归系数的Wald检验的p值)、结果保存到csv
- Practical website recommendations worth collecting for College Students
- 文献1
- Solution to the upper limit of TeamViewer display devices
- Unity 利用Skybox Panoramic着色器制作全景图预览有条缝隙问题解决办法
猜你喜欢

Combat readiness mathematical modeling 32 correlation analysis 2

PostGIS create spatial database

Mark: unity3d cannot select resources in the inspector, that is, project locking

Deploy the flask environment using the pagoda panel

重磅白皮书发布,华为持续引领未来智慧园区建设新模式

TCP拥塞控制详解 | 1. 概述
Detailed explanation of C language programming problem: can any three sides form a triangle, output the area of the triangle and judge its type

'教练,我想打篮球!' —— 给做系统的同学们准备的 AI 学习系列小册
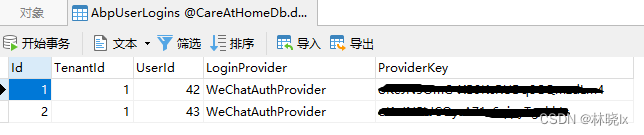
Use abp Zero builds a third-party login module (II): server development

Correlation of XOR / and
随机推荐
Stream常用操作以及原理探索
Excel-VBA 快速上手(二、条件判断和循环)
Deploy the flask environment using the pagoda panel
Authoritative announcement on the recruitment of teachers in Yan'an University in 2022
C语言刷题随记 —— 乒乓球比赛
Understand the difference and use between jsonarray and jsonobject
R语言使用epiDisplay包的aggregate函数将数值变量基于因子变量拆分为不同的子集,计算每个子集的汇总统计信息、使用aggregate.data.frame函数计算分组汇总统计信息
Two point answer, 01 score planning (mean / median conversion), DP
手机股票注册开户安全吗,有没有什么风险?
房东拿租金去还房贷是天经地义的嘛
NAACL2022:(代码实践)好的视觉引导促进更好的特征提取,多模态命名实体识别(附源代码下载)...
Mark: unity3d cannot select resources in the inspector, that is, project locking
MHA高可用配合及故障切换
GDAL multiband synthesis tool
使用 Abp.Zero 搭建第三方登录模块(二):服务端开发
启动Redis报错:Could not create Server TCP listening socket *:6379: bind: Address already in use–解决办法
Informatics Olympiad all in one 1400: count the number of words (string matching)
Introduction to basic knowledge of C language (Daquan) [suggestions collection]
(improved) bubble sorting and (improved) cocktail sorting
R语言dplyr包summarise_at函数计算dataframe数据中多个数据列(通过向量指定)的均值和中位数、指定na.rm参数配置删除缺失值