当前位置:网站首页>datasets Dataset类(2)
datasets Dataset类(2)
2022-06-26 13:27:00 【不负韶华ღ】
对象方法(重要)
1、map函数
map(
function: Optional[Callable] = None,
with_indices: bool = False,
with_rank: bool = False,
input_columns: Optional[Union[str, List[str]]] = None,
batched: bool = False,
batch_size: Optional[int] = 1000,
drop_last_batch: bool = False,
remove_columns: Optional[Union[str, List[str]]] = None,
keep_in_memory: bool = False,
load_from_cache_file: bool = True,
cache_file_names: Optional[Dict[str, Optional[str]]] = None,
writer_batch_size: Optional[int] = 1000,
features: Optional[Features] = None,
disable_nullable: bool = False,
fn_kwargs: Optional[dict] = None,
num_proc: Optional[int] = None,
desc: Optional[str] = None,
)
通过一个映射函数function,处理Dataset中的每一个元素。如果不指定function,则默认的函数为lambda x: x。参数batched表示是否进行批处理,参数batch_size表示批处理的大小,也就是每次处理多少个元素,默认为1000。参数drop_last_batch表示当最后一批的数量小于batch_size,是否处理最后一批。
>>> import transformers
>>> import datasets
>>> dataset = datasets.load_dataset("glue", "cola", split="train")
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551
})
>>> dataset = dataset.map(lambda data: tokenizer(data["sentence"],
padding="max_length",
truncation=True,
max_length=10),
batched=True,
batch_size=1000,
drop_last_batch=False)
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 8551
})
参数input_columns表示输入的列名,默认为Dataset中所有的列,以一个字典类型传入。参数remove_columns表示移除的列名。
>>> import transformers
>>> import datasets
>>> dataset = datasets.load_dataset("glue", "cola", split="train")
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551
})
>>> dataset = dataset.map(lambda data: tokenizer(data["sentence"],padding=True), batched=True)
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 8551
})
# 使用参数input_columns时,注意传入的lambda函数的形式
>>> dataset = dataset.map(lambda data: tokenizer(data,
padding="max_length",
truncation=True,
max_length=10),
batched=True,
batch_size=1000,
drop_last_batch=False,
input_columns=["sentence"])
>>> dataset
Dataset({
features: ['sentence', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 8551
})
# 使用参数remove_columns
>>> dataset = dataset.map(lambda data: tokenizer(data["sentence"],padding=True), batched=True, remove_columns=["sentence", "idx"])
>>> dataset
Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 8551
})
2、to_tf_dataset函数
to_tf_dataset(
columns: Union[str, List[str]],
batch_size: int,
shuffle: bool,
collate_fn: Callable,
drop_remainder: bool = None,
collate_fn_args: Dict[str, Any] = None,
label_cols: Union[str, List[str]] = None,
dummy_labels: bool = False,
prefetch: bool = True,
)
根据datasets.Dataset对象来创建一个tf.data.Dataset对象。如果设置batch_size的话,那么tf.data.Dataset将从datasets.Dataset中加载一批数据,其中每一批数据是一个字典,所有的键名都来自于设置的columns参数。
参数columns表示生成数据的键名,范围为datasets.Dataset的features中的一项或者多项。参数batch_size表示生成数据中每一批数据的大小。参数shuffle表示是否将数据进行打乱。collate_fn表示一个用于将多个数据变成一批数据的函数。
参数drop_remainder表示是否加载时删除最后一个不完整的批次,确保数据集产生的所有批次在批次维度上具有相同的长度。参数label_cols表示要作为标签加载的数据集列。参数prefetch表示是否在单独的线程中运行数据加载器并维护一个小的批次缓冲区用于训练。通过允许在模型训练时在后台加载数据来提高性能。
>>> import transformers
>>> import datasets
>>> dataset = datasets.load_dataset("glue", "cola", split="train")
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx'],
num_rows: 8551
})
>>> tokenizer = transformers.BertTokenizer.from_pretrained("bert-base-uncased")
>>> dataset = dataset.map(lambda data: tokenizer(data["sentence"],padding=True), batched=True)
>>> dataset
Dataset({
features: ['sentence', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 8551
})
>>> data_collator = transformers.DataCollatorWithPadding(tokenizer, return_tensors="tf")
>>> dataset = dataset.to_tf_dataset(columns=["label", "input_ids"], batch_size=16, shuffle=False, collate_fn=data_collator)
>>> dataset
<PrefetchDataset element_spec={'input_ids': TensorSpec(shape=(None, None), dtype=tf.int64, name=None), 'attention_mask': TensorSpec(shape=(None, None), dtype=tf.int64, name=None), 'labels': TensorSpec(shape=(None,), dtype=tf.int64, name=None)}>
边栏推荐
- Hard (magnetic) disk (I)
- Niuke challenge 48 e speed instant forwarding (tree over tree)
- Pychar remotely connects to the server to run code
- d的is表达式
- Build your own PE manually from winpe of ADK
- Correlation analysis related knowledge
- Relevant knowledge of information entropy
- VIM auto fill auto indent explanation
- "Scoi2016" delicious problem solution
- Introduction to granular computing
猜你喜欢

Setup instance of layout manager login interface

Usage of unique function

Sword finger offer 15.65.56 I 56Ⅱ. Bit operation (simple - medium)

Global variable vs local variable

Pychar remotely connects to the server to run code

Sword finger offer 05.58 Ⅱ string

array

From Celsius to the three arrows: encrypting the domino of the ten billion giants, and drying up the epic liquidity
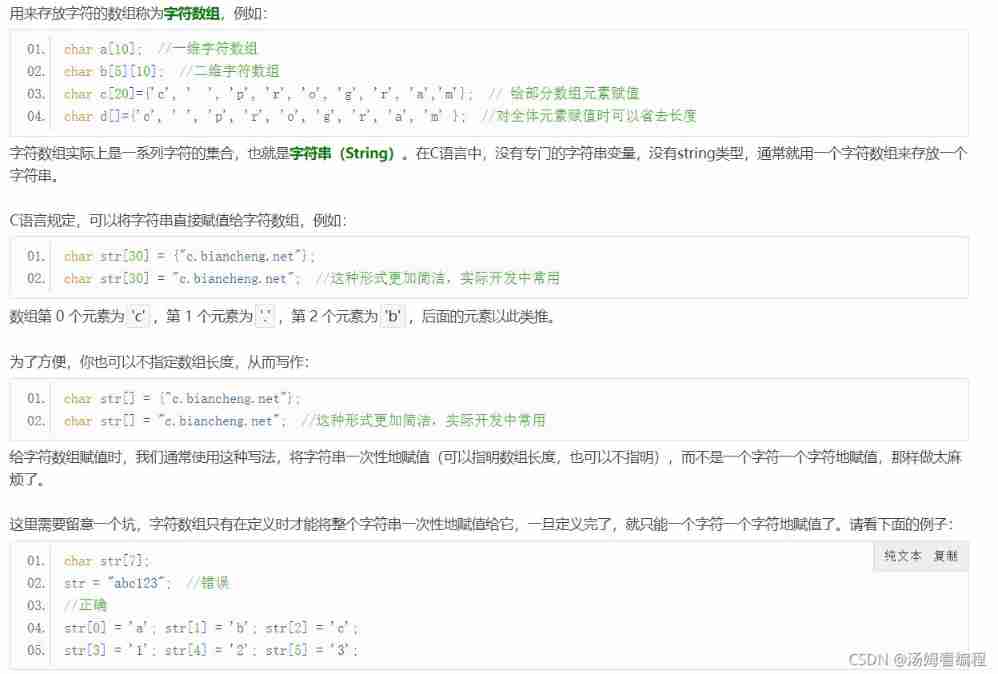
2021-10-18 character array

AGCO AI frontier promotion (6.26)
随机推荐
量化框架backtrader之一文读懂observer观测器
Sword finger offer 09.30 Stack
常用控件及自定义控件
RISC-V 芯片架构新规范
CVPR 2022文档图像分析与识别相关论文26篇汇集简介
Pointer
Logical operation
Intellij IDEA--格式化SQL文件的方法
虫子 运算符重载的一个好玩的
Sword finger offer 21.57.58 I Double pointer (simple)
Global variable vs local variable
Sword finger offer 06.24.35 Linked list
【HCSD应用开发实训营】一行代码秒上云评测文章—实验过程心得
虫子 类和对象 中
C language | file operation and error prone points
9項規定6個嚴禁!教育部、應急管理部聯合印發《校外培訓機構消防安全管理九項規定》
在线牛人博主
It is better and safer to choose which securities company to open an account for flush stock
On insect classes and objects
Sword finger offer 18.22.25.52 Double pointer (simple)