当前位置:网站首页>基于回归分析的广告投入销售额预测——K邻近,决策树,随机森林,线性回归,岭回归
基于回归分析的广告投入销售额预测——K邻近,决策树,随机森林,线性回归,岭回归
2022-07-24 05:24:00 【我是大学渣】
基于回归分析的广告投入销售额预测——K邻近,决策树,随机森林,线性回归,岭回归
1. 项目背景
- 随着人们生活节奏的加快,广告在商品销售中起到的作用越来越大,各个公司都已经十分重视自身产品的广告投入方式,从而将广告的作用发挥到最大,来实现收益的最大化。精准投放广告的作用有以下几个方面。
1、广告是最大、最快、最广泛的信息传递媒介。通过广告,企业或公司能把产品与劳务的特性、功能、用途及供应厂家等信息传递给消费者,沟通产需双方的联系,引起消费者的注意与兴趣,促进购买。
如果出现某些产品在某地积压滞销,而彼地却缺少货源,也可通过广告沟通联系。为了沟通产需之间的联系,现在不仅生产单位和销售单位刊登广告,寻找顾客,而且一些急需某种设备或原材料的单位,也刊登广告,寻找货源。因此,广告的信息传递能迅速沟通供求关系,加速商品流通和销售。
2、广告能激发和诱导消费。消费者对某一产品的需求,往往是一种潜在的需求,这种潜在的需要与现实的购买行动,有时是矛盾的。广告造成的视觉、感觉映象以及诱导往往会勾起消费者的现实购买欲望。有些物美价廉、适销对路的新产品,由于不为消费者所知晓,所以很难打开市场,而一旦进行了广告宣传,消费者就纷纷购买。另外,广告的反复渲染、反复刺激,也会扩大产品的知名度,甚至会引起一定的信任感。也会导致购买量的增加。
3、广告能较好地介绍产品知识、指导消费。通过广告可以全面介绍产品的性能、质量、用途、维修安装等,并且消除他们的疑虑,消除他们由于维修、保养、安装等问题而产生的后顾之忧,从而产生购买欲望。
4、广告能促进新产品、新技术的发展。一新产品、新技术的出现,靠行政手段推广,既麻烦又缓慢,局限性很大,而通过广告,直接与广大的消费者见面,能使新产品、新技术迅速在市场上站稳脚跟,获得成功。
如果我们能分析出广告媒体投入与销售额之间的关系,我们就可以更好地分配广告开支并且使销售额最大化。
2. 项目简介
2.1 项目内容
- 本项目将分析广告的不同投入方式对销售额的影响,并建立相关模型对不同广告投入方式的销售额进行预测。主要研究以下内容:
- 不同广告投入方式与销售额之间的关系。
- 对不同广告投入方式所带来的销售额进行预测。
- 尝试给出合理化的广告投入建议
2.2 数据说明
- 实验使用从kaggle获取的不同广告投入方式和销售额的数据。该数据共有4个字段,共202条内容。每条内容包含了不同广告方式的投入额和相应的销售额。

指标名称 指标含义
TV 电视广告投放
radio 电台广告投放
newspaper 报纸广告投放
sales 销售额
| 指标名称 | 指标含义 |
|---|---|
| TV | 电视广告投放 |
| radio | 电台广告投放 |
| newspaper | 报纸广告投放 |
| sales | 销售额 |
2.3 技术工具
- 本项目以Pycharm为平台,以Python语言为基础,采用pandas进行数据整理和统计分析,用matplotlib、seaborn进行可视化呈现,采用决策树、随机森林、K—近邻、线性回归四个模型进行客户流失预警。
3.算法原理
3.1 K—近邻
- K近邻,是表示最近邻居 k的近邻,表示每一个样本都能以其最接近 k的邻居表示。
1、K-近邻算法(KNN)算法实现简单、高效。在分类、回归、模式识别等方面有着广泛的应用。将 KNN算法应用于求解问题时,应注意样本权重和特征权重两个方面。提出了基于 SVM的特征加权算法(FWKNN, featureweightedKNN),用 SVM方法确定特征权重。试验表明, FWKNN可以在一定条件下大大提高分类精度。
2、 KNN算法的核心思想是如果样本在特征空间的 k个最相邻的样本中大部分属于某一类,那么该样本也属于这一类,并且具有这类样本的特征。在分类决策中,该方法仅根据样本的一个或少数几个样本的类别确定待分样本所属的类别。kNN方法仅适用于极少数相邻样本的分类决策。在 kNN方法中,由于 kNN方法主要依赖于周围有限的邻域样本,而不是依赖域判别法来确定类别,因此, kNN方法比其他方法更适合于交叉或重叠较多的待分样本集。
总结 KNN算法既可用于分类,也可用于回归。利用样本中 k个近邻,并对样本中邻居属性的平均值进行赋值,从而获得样本的属性属性。对于不同距离的邻居对这些样本的影响,采用不同的权值,这更有用(weight) 1)优点:精度高、对异常值不敏感、无数据输入假定;
缺点:计算复杂度高、空间复杂度高;适用数据范围:数值型和标称型。
3.2 决策树
- 决策树的概念非常简单。即使不知道它也可以通过简单的图形了解其工作原理,图3-1所示的流程图就是一个决策树,正方形代表判断模块(decision
block),椭圆形代表终止模块(terminating
block),表示已经得出结论,可以终止运行。从判断模块引出的左右箭头称作分支(branch),它可以到达另一个判断模块或者终止模块。图3-1
构造了一个假想的邮件分类系统,
它首先检测发送邮件域名地址。如果地址为myEmployer.com,则将其放在分类“无聊时需要阅读的邮件”中。如果邮件不是来自这个域名,则检查邮件内容里是否包含单词曲棍球,如果包含则将邮件归类到“需要及时处理的朋友邮件”,如果不包含则将邮件归类到“无需阅读的垃圾邮件”。
我们经常使用决策树处理分类问题,近来的调查表明决策树也是最经常使用的数据挖掘算法。它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。
虽然k-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势就在于数据形式非常容易理解。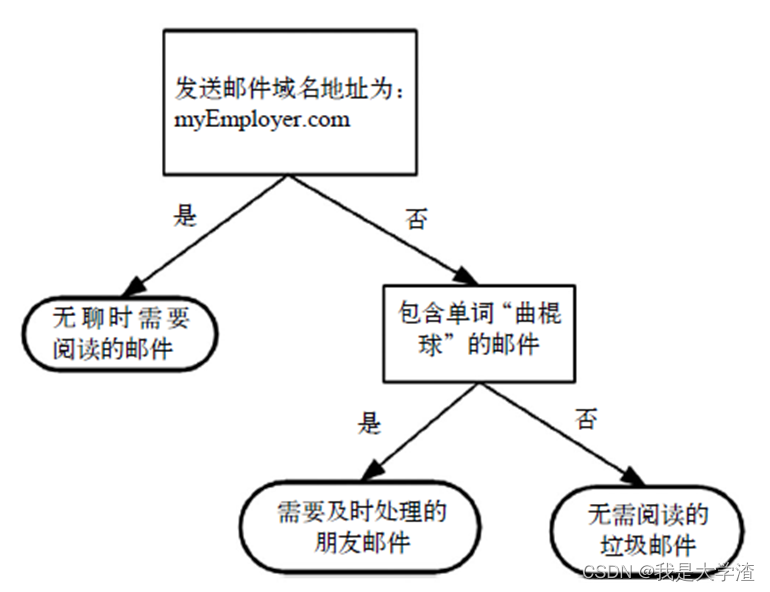
3.3随机森林
- 随机森林是一种包含多个决策树的分类器。随机森林的算法是由Leo Breiman和Adele
Cutler发展推论出的。随机森林,顾名思义就是用随机的方式建立一个森林,森林里面由很多的决策树组成,而这些决策树之间没有关联。随机森林就是用过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支------集成学习(Ensemble
Learning)方法。集成学习就是使用一系列学习器进行学习,并将各个学习方法通过某种特定的规则进行整合,以获得比单个学习器更好的学习效果。集成学习通过建立几个模型,并将它们组合起来来解决单一预测问题。它的工作原理主要是生成多个分类器或者模型,各自独立地学习和作出预测。随机森林是由多棵决策树构成的。对于每棵树,他们使用的训练集是采用放回的方式从总的训练集中采样出来的。而在训练每棵树的结点时,使用的特征是从所有特征中采用按照一定比例随机地无放回的方式抽取的。优点如下: - 随机森林可以计算出各例中的亲近度,在数据挖掘、侦测偏离者及将资料视觉化方面有着非常重要的作用。
- 在大数据集上表现良好。
- 能够评估在分类问题上的各个特征的重要程度。
3.4 线性回归
- 假定预测值与样本特征间的函数关系是线性的,回归分析的任务,就在于根据样本X和Y的观察值,去估计函数h,寻求变量之间近似的函数关系。定义:
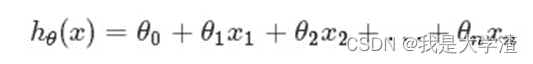
- 其中,n = 特征数目;xj = 每个训练样本第j个特征的值,可以认为是特征向量中的第j个值。为了方便,记x0=
1,则多变量线性回归可以记为:(θ、x都表示(n+1,1)维列向量)注意多元和多次是两个不同的概念,“多元”指方程有多个参数,“多次”指的是方程中参数的最高次幂。多元线性方程是假设预测值y与样本所有特征值符合一个多元一次线性方程。
3.5 岭回归
- 岭回归主要解决回归中的两大问题:排除多重共线性和进行变量的选择。思想是在原先的最小二乘估计中加入一个小扰动,也叫惩罚项,使得原先无法求广义逆的情况下变为可以求广义逆,是的问题稳定并得以求解。岭回归通过对系数向量的长度平方添加处罚来收缩稀疏。当线性回归模型中存在多个相关变量时,它们的系数确定性变差并呈现高方差。比如说,在一个变量上的一个很大的正系数可能被在其相关变量上的类似大小的负系数抵消,岭回归就是通过在系数上施加约束来避免这种现象的发生。此外当特征数p>>样本数量时,矩阵X^TX不可逆,此时不可以直接使用最小二乘法,而岭回归没有这个限制。

4. 分析步骤
4.1 理解数据
在Pycharm中输入下面程序,导入数据和工具包,并查看数据集的信息、大小,并初步观察头部信息。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor #决策树
from sklearn.linear_model import LinearRegression #线性回归
from sklearn.linear_model import Ridge #岭回归
from sklearn.ensemble import RandomForestRegressor #随机森林
from sklearn.neighbors import KNeighborsRegressor #K邻近
from sklearn import metrics
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号无法显示
data = pd.read_csv("azd1.csv")
# 查看数据集大小
print(data.shape)
# 设置查看前15条数据
print(data.head(15))

头部信息数据集有4个字段,与上述表 2 1所展示的信息一致,即说明信息加载成功。
4.2 数据预处理
- 在真实世界中,数据通常是不完整的(缺少某些感兴趣的指标值)、不一致的(包含代码或者名称的差异)、极易受到噪声(错误或异常值)的侵扰的。因为数据库太大,而且数据集经常来自多个异种数据源,低质量的数据将导致低质量的挖掘结果。就像一个大厨现在要做美味的蒸鱼,如果不将鱼进行去鳞等处理,一定做不成我们口中美味的鱼。数据预处理就是解决上述所提到的数据问题的可靠方法,因此,在进行数据分析之前我们需要进行数据预处理。
数据预处理一般要遵循以下规则:
1)完整性:单条数据是否存在空值,统计的字段是否完善。
2)全面性:观察某一列的全部数值,通过常识来判断该列是否有问题,比如:数据定义、单位标识、数据本身。
3)合法性:数据的类型、内容、大小的合法性。比如数据中是否存在非ASCII字符,性别存在了未知,年龄超过了150等。
4)唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的。
本项目对数据进行数据类型转换和缺失值处理两种预处理方法,以确保其完整性、全面性与合法性。
4.2.1 数据类型转换
首先,通过Dataframe中的info()函数查看各数据字段数据类型和缺失值情况

经过观察,发现所有数据类型都为浮点型数据,所以不需要进行数据类型的转换。
4.2.2 缺失值处理
- 在上述数据类型转换过程中,发现radio和newspaper列存在数值缺失,需要对该缺失数据进行处理。缺失值指的是现有数据集中某个或某些指标的值是不完全的。其一般处理主要有以下方法:
1)删除指标或者删除样本:如果大部分样本该指标都缺失,这个指标能提供的信息有限,可以选择放弃使用该维指标。
2)统计填充:对于缺失值的指标,尤其是数值类型的指标,根据所有样本关于这维指标的统计值对其进行填充,如使用平均数、中位数、众数、最大值、最小值等,具体选择哪种统计值需要具体问具体分析。
3)统一填充:常用的统一填充值有“空”、“0”、“正无穷”、“负无穷”等;
4)预测/模型填充:可以通过预测模型利用不存在缺失值的指标来预测缺失值,如统计、学习等。这种虽然方法复杂,但是最后得到的结果比较好。
本项目通过dropna方法删除该样本的缺失值来进行缺失值处理

结果显示,缺失值处理已经完成,下面可以进行数据可视化分析。
4.3 探索性数据分析
- 探索性数据分析(Exploratory Data
Analysis,EDA)是对数据进行分析并得出规律的一种数据分析方法,是一种利用各种工具和图形技术(如柱状图、直方图等)分析数据的方法。它是一个开放式的过程,在这个过程中,我们可以绘制图表并计算统计数据以便探索我们的数据。
EDA的目标是确定我们的数据可以告诉我们什么。与目标相关的变量对模型很有用,因为他们是用于预测目标。简单说就是画图来理解数据,EDA探索性数据分析本质上就是用图画图的方式来理解数据。所有代码见附录1。
首先,
通过散点图分析每一种广告投放方式的销售额分布情况:

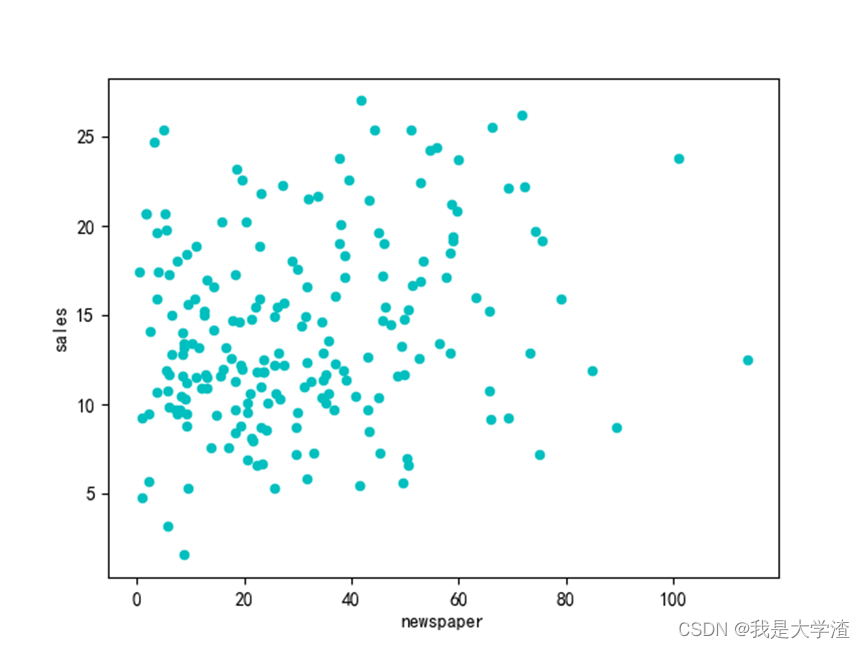
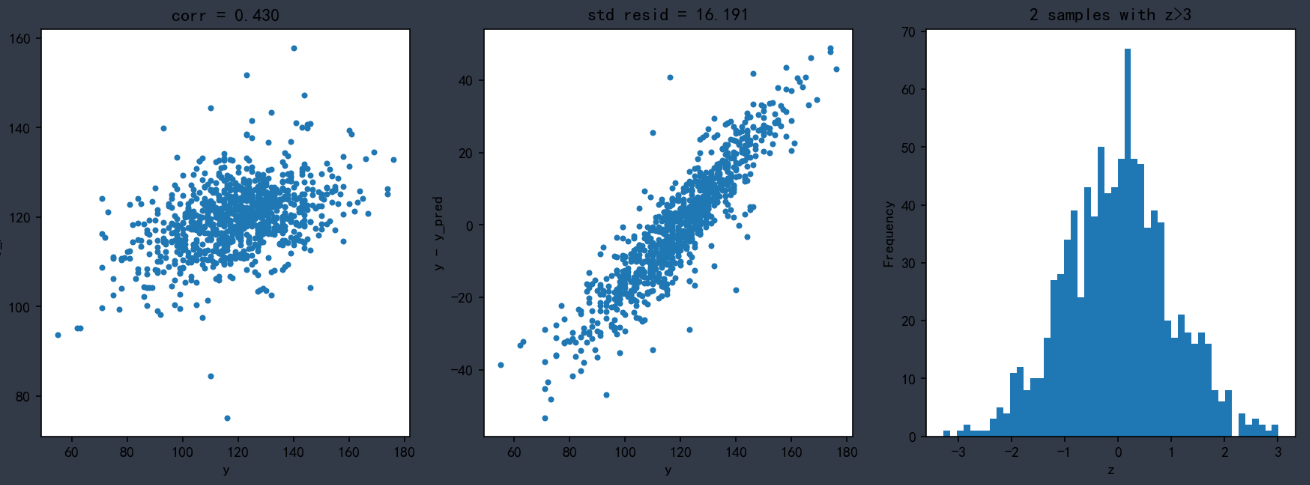
通过绘制每一个维度特征与销售额的散点图,可以大概看出,各种广告投入与销售额成正比。
然后我们在画出各个投放方式金额的平均数和销售额的条形图来更加直观的证明这个结论。
从下图我们也可以清晰的看出电视这种广告投放方式的平均值最高,这和我们上面得到的散点图基本一致,电视广告投放散点图分布有明显的集中趋势。
但是我们要清楚散点图分布只能看出一个模糊的大概,具体量化的关联性,可以通过关联矩阵和热力图进行展示,首先就是corr()方法输出关系矩阵。
然后可以将输出的数据进行图形可视化,较为常用的就是热力图,直接利用上面的结果进行输出。
绘制热力图的代码如下
def load_data():
data = pd.read_csv(r'azd1.csv', sep=',')
# 计算相关系数矩阵
corr = data.corr()
print(corr)
cor = corr
plt.figure() # 绘制热力图
sns.heatmap(cor, vmin=-1, cmap="plasma_r", annot=True)
plt.savefig("5")
plt.show()
# 找出对y相关系数大于0.5的因素
a = corr['sales']
a = a[abs(a) > 0.5].sort_values(ascending=False)
a_colums = np.array(a.index).tolist()
return data, a_colums
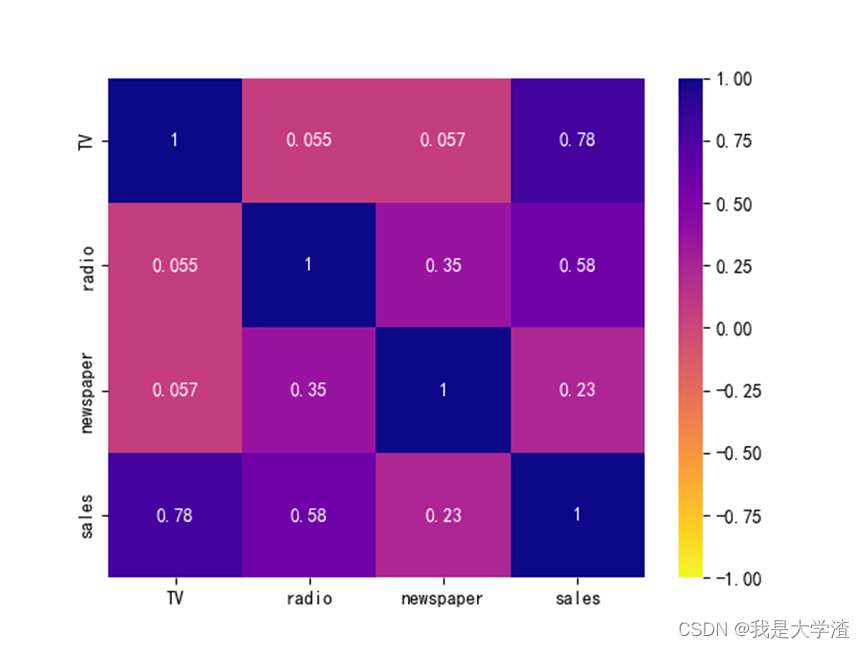
查看关联矩阵和热力图都只需要查看主对角线(左上角到右下角对角线)的一侧即可,由于这里探究的是利润与其它三个影响因素之间的关系,因此只需要看最后一行的数据即可。数值在(0.45,1)或者(-1,-0,45)之间,都可以认为两者具有相关性。比如上面的输出结果,利润和电视投放以及广播投放都是有关联,而与新闻报纸的投放没有关联。
4.4 销售额预测
4.4.1 建模及模型预测
1)导入相应的工具包
2)本项目采用决策树、随机森林、K近邻、线性回归、岭回归四种算法,分别对广告投入进行学习和预测,并根据结果(见图 4 24至图 4 27所示)的均方误差,平均绝对误差,R值进行分析。
4.4.1.1使用线性回归模型:
def model_fit1(data, a_colums):
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
# 加载模型
linreg = LinearRegression()
# 拟合数据
linreg.fit(train_X, train_Y)
return linreg, test_X, test_Y

4.4.1.2 使用岭回归:
def model_fit2(data,a_colums):
# 构建数据集 训练模型
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
ridge=Ridge()
ridge.fit(train_X,train_Y)
return ridge, test_X, test_Y

4.4.1.3 使用随机森林模型:
def model_fit3(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
randomForestRegressor=RandomForestRegressor(n_estimators=200, random_state=0)
randomForestRegressor.fit(train_X,train_Y)
return randomForestRegressor, test_X, test_Y

4.4.1.4 使用 k邻近模型分析:
def model_fit4(data,a_colums):
# 构建数据集 训练模型
# 制作训练集和测试集的数据
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
k=5
kNeighborsRegressor=KNeighborsRegressor(k)
kNeighborsRegressor.fit(train_X,train_Y)
return kNeighborsRegressor, test_X, test_Y

4.4.1.5 使用决策树模型分析:
def model_fit5(data,a_colums):
data_01 = data[a_colums]
Y = np.array(data_01['sales'])
data_02 = np.array(data_01.drop('sales', axis=1))
# 分割训练集和测试集
train_X, test_X, train_Y, test_Y = train_test_split(data_02, Y, test_size=0.2)
decisionTreeRegressor=DecisionTreeRegressor()
decisionTreeRegressor.fit(train_X,train_Y)
return decisionTreeRegressor, test_X, test_Y

结果显示,随机森林和决策树模型的R2(拟合优度)较高,均大于百分之九十。
3)接下来画出模型的学习曲线,观察模型的拟合情况。
- 线性回归模型结果

- 岭回归模型结果

- 随机森林模型结果

- K邻近模型结果

- 决策树模型结果

从结果来看,随机森林模型预测的准确性最高,基本与实际曲线拟合,这也更加直观的说明了此数据集用随机森林模型更加准确。
5.实验总结
5.1 结果分析
根据以上分析,可以得到如下结果:
要想增加商品的销售额,我们应该首先考虑增加电视广告和电台广告的投入量,因为商品的销售额与这两种广告投放方式的关系最大
我们要严格控制在报纸上的广告投入量,因为经过我们分析,报纸广告投入这种方式与销售额并没有什么明显关系,换句话说,加大报纸广告投入量并不能提高销售额,所以我们也就没有必要增加报纸的广告投入。
5.2 改善建议
- 1)现代化企业的广告宣传并不能只着眼于传统宣传方式,随着互联网平台的崛起,在新媒体营销时代背景下,企业产品的销售模式也随之发生改变。当前企业转变生产产品营销可以借助新媒体中的互联网平台来开展,可以此有效的降低企业的销售成本和运输费用,以此实现企业的经济效益增长,为生产企业的健康发展提供保障。
- 2)企业不能只关心自身广告的效益,最根本的是要提升自身产品的质量,无论是什么广告投放方式,最重要的还是回归到商品本身,如果商品足够优秀,这已经是最好的广告了,我认为广告就是将那些发光发亮的产品或商品推荐给更多人。
5.3 实验心得
其实很早之前我就听说过python这门编程语言,它在各大编程排行网站上位居榜首,我也萌生出来想系统的学习它的想法,可是我总是给自己找借口,一拖再拖,始终没有开始学习。直到知道这学期我的专业课有python后,在选课时我特意选择了与之相关的这节选修课。在寒假时我也自行阅读了python的相关经典书籍和在专业课上的学习,掌握了基本语法和相关库的使用。可是我一直停留在看的阶段,并没有亲自去编写过较大的程序,也没有自己做过数据分析。经过这次项目的实战,我对python这门语言有了更深的理解,同时也了解了大数据分析的基本方法,也有了以下的总结。
1) python中的第三方库非常多,有很多程序不需要我们自己去编写,可以直接使用库里面的相关函数,这也是为什么python应用十分广泛的原因。
2) 伴随着大数据、云平台、物联网、人工智能技术的快速发展,大数据分析必然会发挥更大的作用。大数据的意义归根到底就四个字:辅助决策。利用大数据分析,能够分析现状、分析原因、发现规律、总结经验、和预测趋势,这些都可以为辅助决策服务。我们掌握的数据信息越多,我们的决策才能更加科学、精确、合理。从这个方面看,也可以说数据本身不产生价值,大数据必须和其他具体的领域、行业相结合,能够给决策者提供帮助之后,才具有价值。政府或企业都可以借助大数据,提升管理、决策水平,提升经济效益。
3) 只有实战才能真正提高自己的编程水平,和对相关知识的理解,单纯的听课和看书只能增加理论知识,编程需要实战,不然只会眼高手低,看着很简单的问题自己就是解决不了。
4) 课程虽然结束了,但是我不能停止学习,在后期的学习中,我应该注重自己在语言的应用上层面上,不能只会纸上谈兵,在编程的过程中难买会遇到问题,保持独立思考的习惯,查询相关资料去解决,而不能就此放弃。
原 创 不 易 , 还 希 望 各 位 大 佬 支 持 一 下
点 赞 , 你 的 认 可 是 我 创 作 的 动 力 !
️ 收 藏 , 你 的 青 睐 是 我 努 力 的 方 向 !
️ 评 论 , 你 的 意 见 是 我 进 步 的 财 富 !
边栏推荐
猜你喜欢






随机推荐
这些坑你不掌握,你还真不敢用BigDecimal
LVM and disk quota
【LVGL(3)】设置对象大小、位置、盒子模型、状态
Quick start of go language
Combination of grep and regular
Modeling of XML
Flex layout
Talk about browser cache again
Secondary processing of template data
awk的使用
Yiwen node installation, download and configuration
RESTful API介绍
使用自定义zabbix包(4.0.5版本)安装agent和proxy
MySQL forgot to exit and close the window directly. How to delete the entire folder now
FTP服务与实验
XML parsing
Customize MVC 3.0
Restful API introduction
Crud of MySQL
Flink state use