当前位置:网站首页>Examples of corpus data processing cases (part of speech encoding, part of speech restoration)
Examples of corpus data processing cases (part of speech encoding, part of speech restoration)
2022-06-23 04:42:00 【Triumph19】
7.2 part-of-speech tagging
7.2.1 The basic operation of part of speech coding
- Code the part of speech of the text (part-of-speech tagging or POS tagging) It is one of the most common text processing tasks in corpus linguistics .NLTK The library page provides a part of speech encoding module . Please see the following example .
import nltk
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
string_tokenized = nltk.word_tokenize(string)
string_postagged = nltk.pos_tag(string_tokenized)
string_postagged
- Before the part of speech coding, the sentence should be segmented , So first we need to use nltk.word_tokenize() Function pair string Do word segmentation . then , adopt nltk.pos_tage() Function to code the part of speech of the segmented list . The printing results of part of speech code assignment are as follows :
[('My', 'PRP$'),
('father', 'NN'),
("'s", 'POS'),
('name', 'NN'),
('being', 'VBG'),
('Pririp', 'NNP'),
(',', ','),
('and', 'CC'),
('my', 'PRP$'),
('Christian', 'JJ'),
('name', 'NN'),
('Philip', 'NNP'),
(',', ','),
('my', 'PRP$'),
('infant', 'JJ'),
('tongue', 'NN'),
('could', 'MD'),
('make', 'VB'),
('of', 'IN'),
('both', 'DT'),
('names', 'NNS'),
('nothing', 'NN'),
('longer', 'RB'),
('or', 'CC'),
('more', 'JJR'),
('explicit', 'NNS'),
('than', 'IN'),
('Pip', 'NNP'),
('.', '.'),
('So', 'NNP'),
(',', ','),
('I', 'PRP'),
('called', 'VBD'),
('myself', 'PRP'),
('Pip', 'NNP'),
(',', ','),
('and', 'CC'),
('came', 'VBD'),
('to', 'TO'),
('be', 'VB'),
('called', 'VBN'),
('Pip', 'NNP'),
('.', '.')]
- It can be seen from the results that ,nltk.word_tokenize() After the function part of speech is coded , Return a list , Each element of the list is a tuple , Each tuple has two more elements , They are the word and its part of speech code .
- If you print or output the above results directly , Poor readability . To improve the readability of the results , We can treat it as " word _ The part of speech " In the form of . therefore , You can use the following code to implement this function .
for i in string_postagged:
print(i[0] + '_' + i[1])
My_PRP$
father_NN
's_POS
name_NN
being_VBG
Pririp_NNP
,_,
and_CC
my_PRP$
Christian_JJ
name_NN
Philip_NNP
,_,
my_PRP$
infant_JJ
tongue_NN
could_MD
make_VB
of_IN
both_DT
names_NNS
nothing_NN
longer_RB
or_CC
more_JJR
explicit_NNS
than_IN
Pip_NNP
._.
So_NNP
,_,
I_PRP
called_VBD
myself_PRP
Pip_NNP
,_,
and_CC
came_VBD
to_TO
be_VB
called_VBN
Pip_NNP
7.2.2 Code the text sentence by sentence and part of speech
- In the example in this section , We want to process a certain text , Write it out to a text file in Clause form , And assign part of speech codes to each word of the sentence . The code is as follows :
import nltk
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
# Clause the string
sent_splitter = nltk.data.load('tokenizers/punkt/english.pickle')
sents_splitted = sent_splitter.tokenize(string)
file_out = open('D:\works\ Text analysis \sent_postagged.txt','a')
# Code the part of speech of the text after the clause
for sent in sents_splitted:
# posttag the sentence
sent_tokenized = nltk.word_tokenize(sent)
sent_postag = nltk.pos_tag(sent_tokenized)
# save the postagged sentence in sent_postagged
for i in sent_postag:
output = i[0] + '_' + i[1] + ' '
file_out.write(output)
file_out.write('\n')
file_out.close()
- give the result as follows :
My_PRP$ father_NN 's_POS name_NN being_VBG Pririp_NNP ,_, and_CC my_PRP$ Christian_JJ name_NN Philip_NNP ,_, my_PRP$ infant_JJ tongue_NN could_MD make_VB of_IN both_DT names_NNS nothing_NN longer_RB or_CC more_JJR explicit_NNS than_IN Pip_NNP ._.
So_RB ,_, I_PRP called_VBD myself_PRP Pip_NNP ,_, and_CC came_VBD to_TO be_VB called_VBN Pip_NNP ._.
- In fact, it means pressing "." Divide it into two sentences , Every word in every sentence is encoded by part of speech .
7.3 Part of speech reduction
- Part of speech reduction (lemmatization) It refers to the restoration of a word with twists and turns into its prototype (base form). such as desks Can be reduced to desk, Verb went or going restore go etc. .NLTK Built in library wordnet modular ,wordnet There is a word form restore tool in the module WordNetLemmatizer. So we can use WordNetLemmatizer To restore the part of speech . See the following code example .
import nltk
from nltk.stem.wordnet import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('books','n')) #book
print(lemmatizer.lemmatize('went','v')) #go
print(lemmatizer.lemmatize('better','a')) #good
print(lemmatizer.lemmatize('geese')) #goose
- The above demonstration is the most basic utilization wordnet Part of speech restoration tool to restore the part of speech of a single word . If we have a long text , Not a single word , utilize wordnet Part of speech reduction tools are more cumbersome . such as , We need to segment and code the text first , Then extract word and part of speech code one by one , You also need to convert the part of speech code into wordnet The acceptable magnetic code of part of speech restoration tool , Finally, it can pass wordnet Tool to restore part of speech .
- Of course , We can also use other tools to restore part of speech . such as ,Stanford CoreNLP The part of speech restore tool of the software package is used to restore the part of speech of the text . The specific method will be discussed in this chapter 7.12 Subsection discussion .
- The following error message appears , But the download failed .

7.5 Extract lexical chunks
- A hot issue in corpus linguistics is the study of lexical chunks (Ngrams or chunks) The study of . According to the length of the extracted word block , A lexical chunk can be divided into a lexical chunk ( word )、 Two word chunks 、 Three word chunks 、 Four word chunks, etc . For example, from string "To be or not to be" Five two word chunks can be extracted from the "To be"、"be or " 、"or not "、"not to "、“to be”.
- NLTK In the library ngrams modular , The ngrams() Function to extract chunks from a string . Its basic usage is ngrams(string,n), namely ngrams() There are two parameters , The first parameter is the string , The second parameter is the length of the word block . Look at the code below .
#%%
import nltk
from nltk.util import ngrams
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
string_tokenized = nltk.word_tokenize(string.lower())
n = 4
n_grams = ngrams(string_tokenized,n)
for grams in n_grams:
print(grams)
- We first pass import nltk and from nltk.util import ngrams Two statements introduce nltk and ngrams modular . then , adopt nltk.word_tokenize(string.lower()) The statement of string Lowercase and participle processing , And define the length of the extracted word block (n = 4). Next , adopt ngrams(string_tokenized,n) To extract string The middle length is 4 Lexical chunks . Last , adopt for…in Loop to print the extracted chunks . give the result as follows :
('my', 'father', "'s", 'name')
('father', "'s", 'name', 'being')
("'s", 'name', 'being', 'pririp')
('name', 'being', 'pririp', ',')
('being', 'pririp', ',', 'and')
('pririp', ',', 'and', 'my')
(',', 'and', 'my', 'christian')
('and', 'my', 'christian', 'name')
('my', 'christian', 'name', 'philip')
('christian', 'name', 'philip', ',')
('name', 'philip', ',', 'my')
('philip', ',', 'my', 'infant')
(',', 'my', 'infant', 'tongue')
('my', 'infant', 'tongue', 'could')
('infant', 'tongue', 'could', 'make')
('tongue', 'could', 'make', 'of')
('could', 'make', 'of', 'both')
('make', 'of', 'both', 'names')
('of', 'both', 'names', 'nothing')
('both', 'names', 'nothing', 'longer')
('names', 'nothing', 'longer', 'or')
('nothing', 'longer', 'or', 'more')
('longer', 'or', 'more', 'explicit')
('or', 'more', 'explicit', 'than')
('more', 'explicit', 'than', 'pip')
('explicit', 'than', 'pip', '.')
('than', 'pip', '.', 'so')
('pip', '.', 'so', ',')
('.', 'so', ',', 'i')
('so', ',', 'i', 'called')
(',', 'i', 'called', 'myself')
('i', 'called', 'myself', 'pip')
('called', 'myself', 'pip', ',')
('myself', 'pip', ',', 'and')
('pip', ',', 'and', 'came')
(',', 'and', 'came', 'to')
('and', 'came', 'to', 'be')
('came', 'to', 'be', 'called')
('to', 'be', 'called', 'pip')
('be', 'called', 'pip', '.')
- Of course , We can further process the above results according to the research needs , For example, delete tuples like the last word block containing punctuation elements ( Lexical chunks ). The following code finds and deletes the n_grams Tuples containing non alphanumeric character elements in the list ( Lexical chunks ), And print only other chunks .
import re
import nltk
from nltk.util import ngrams
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
string_tokenized = nltk.word_tokenize(string.lower())
n = 4
n_grams = ngrams(string_tokenized,n)
n_grams_AlphaNum = []
for gram in n_grams:
# to test if there is any non-alphanumeric character in the ngrams
# Filter out non English characters gram
for i in range(4):
if re.search(r'^\W+$',gram[i]): # \W Match any non word character . Equivalent to “[^A-Za-z0-9_]”
break
else:
n_grams_AlphaNum.append(gram)
for j in n_grams_AlphaNum:
print(j)

边栏推荐
猜你喜欢

Background ribbon animation plug-in ribbon js

win10查看my.ini路径

在Pycharm中对字典的键值作更新时提示“This dictionary creation could be rewritten as a dictionary literal ”的解决方法

win10下安装、运行MongoDB
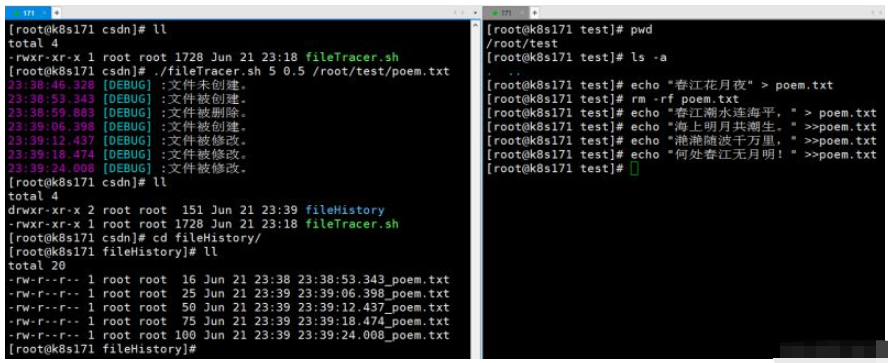
How to use shell script to monitor file changes

大一学生课设c——服装管理系统

JVM调优简要思想及简单案例-为什么需要JVM调优?

论文阅读_关系抽取_CASREL

How to make the page number start from the specified page in word
2020:VL-BERT: Pre-training of generic visual-linguistic representation
随机推荐
大一学生课设c——服装管理系统
[binary tree] completeness test of binary tree
Particle animation background login page particles js
Can MySQL be used in Linux
2022金属非金属矿山(露天矿山)安全管理人员考试题模拟考试题库及答案
Halcon知识:binocular_disparity 知识
Leetcode 1208. Try to make the strings equal as much as possible (finally solved, good night)
win10下安装、运行MongoDB
free( )的一个理解(《C Primer Plus》的一个错误)
What are the characteristics of SRM supplier management system developed by manufacturing enterprises
Halcon knowledge: binocular_ Discrimination knowledge
语料库数据处理个案实例(分词和分句、词频统计、排序)
Cocos学习日记1——节点
智能语音时代到来,谁在定义新时代AI?
Pta:6-30 time addition
Please use the NLTK Downloader to obtain the resource
在Pycharm中使用append()方法对列表添加元素时提示“This list creation could be rewritten as a list literal“的解决方法
一篇文章学会er图绘制
PTA:7-31 期刊收费
Photoshop PS viewing pixel coordinates, pixel colors, pixel HSB colors