当前位置:网站首页>Redis (13) -- on master-slave replication of redis
Redis (13) -- on master-slave replication of redis
2022-07-24 13:00:00 【cb414】
1, Preface
stay Redis in , The user can go through SLAVEOF Command or set slaveof Options , Let one server copy another server , Our replication server is called master , The server that replicates the primary server is called the secondary server
Suppose there are two servers
- The server A, The address is
127.0.0.1:6379- The server B, The address is
127.0.0.1:12345
- The server B, The address is
- On the server A Send the following command :
SLAVEOF 127.0.0.1:12345
Then the server A Will become a server B From the server , The server B It's the server A The primary server of
The databases of the master and slave servers that replicate will store the same data , Conceptually, this phenomenon is called :” Database state is consistent “, Or for short ” Agreement “
The master-slave copy function takes Redis2.8 Version is the dividing line ,2.8 The replication function of the previous version is inefficient in dealing with the secondary server reconnected after disconnection ; and Redis2.8 Later, the copy function of the new version solves the inefficiency of the copy function of the old version through partial resynchronization
2, Implementation of the old copy function
Redis The copy function of is divided into :
- Sync (
sync): Synchronization is used to update the database state of the slave server to the current database state of the master server - Command propagation (
command propagate): Command propagation operations are used to modify the database state of the master server , When the database state of the master-slave server is inconsistent , Returns the master slave server's database to a consistent state
2.1, Sync
When the client sends SLAVEOF command , When it is required to replicate the primary server from the server , The slave server needs to perform synchronization first , That is to say : Update the database status from the server to the current database state of the master server
The slave server sends SYNC Command complete synchronization , Here are SYNC The execution of the order :
- Sent from the slave server to the master server
SYNCcommand - received
SYNCThe main server of the command executesBGSAVEcommand , Generate a... In the backgroundRDBfile , And use a buffer to record all write commands executed from now on - When the main server
BGSAVEAt the end of the command , The master server willBGSAVECommand generatedRDBFile sent to server , Receive and load this... From the serverRDBfile , Update your own database state to the master server for executionBGSAVEDatabase state at command time - The master sends all write commands recorded in the buffer to the slave , Execute these write commands from the server , Update your database status to the current status of the master server database

The following table shows an example of master-slave server synchronization :
| Time | master server | From the server |
|---|---|---|
| T0 | Server startup | Server startup |
| T1 | perform SET k1 v1 | |
| T2 | perform SET k2 v2 | |
| T3 | perform SET k3 v3 | |
| T4 | Send to primary server SYNC command | |
| T5 | Received from the server SYNC command , perform BGSAVE command , Create include key k1、k2、k3 Of RDB file , And use the buffer to record all subsequent write commands | |
| T6 | perform SET k4 v4, And record this command into the buffer | |
| T7 | perform SET k5 v5, And record this command into the buffer | |
| T8 | BGSAVE Order executed , To the slave server RDB file | |
| T9 | Receive and load the data sent by the master server RDB file , get k1、k2、k3 The three key | |
| T10 | Send write command saved in buffer to server SET k4 v4 and SET k5 v5 | |
| T11 | Receive and execute two messages from the master server SET command , obtain k4 and k5 Two keys | |
| T12 | Synchronization complete , Now the databases of both master and slave servers contain keys k1、k2、k3、k4 and k5 | Synchronization complete , Now the databases of both master and slave servers contain keys k1、k2、k3、k4 and k5 |
2.2, Command propagation
After the synchronization operation is completed , The databases of both master and slave servers will reach a consistent state , But this consensus is not static . After the master server executes the write command , The database state between master and slave servers may no longer be consistent , At this time, the master server needs to pass the write command just executed to the slave server , Let the server execute this write command , Thus, the database state of the master-slave server is consistent again .

2.3, defects
stay Redis in , The replication from the slave server to the master server can be divided into the following two cases :
- First reproduction : The slave server has not previously replicated any master servers , Or the current master server to be replicated from the server is different from the last master server 【 No master server has been copied or the master server has been copied 】
- Duplicate after disconnection , The master-slave server in the command propagation stage interrupts replication due to network reasons , But the slave server reconnects to the master server through automatic reconnection , And continue to replicate the primary server 【 Even good , Suddenly disconnect , Then reconnect , As a result, the database state of the master and slave servers may be inconsistent 】
For initial replication , The copy function of the old version can complete the task well , But for copying after disconnection , Although the replication function of the old version can return the master and slave servers to a consistent state , But it's inefficient
The specific situation is shown in the following example :
| Time | master server | From the server |
|---|---|---|
| T0 | Master slave server completes synchronization | Master slave server completes synchronization |
| T1 | Execute and disseminate SET k1 v1 | Execute the SET k1 v1 |
| T2 | Execute and disseminate SET k2 v2 | Execute the SET k2 v2 |
| …… | …… | …… |
| T10085 | Execute and disseminate SET k10085 v10085 | Execute the SET k10085 v10085 |
| T10086 | Execute and disseminate SET k10086 v10086 | Execute the SET k10086 v10086 |
| T10087 | The master-slave server is disconnected | The master-slave server is disconnected |
| T10088 | Execute and disseminate SET k10087 v10087 | Broken line , Try reconnecting to the primary server |
| T10089 | Execute and disseminate SET k10088 v10088 | Broken line , Try reconnecting to the primary server |
| T10090 | Execute and disseminate SET k10089 v10089 | Broken line , Try reconnecting to the primary server |
| T10091 | Reconnect the master and slave servers | Reconnect the master and slave servers |
| T10092 | Send to primary server SYNC command | |
| T10093 | Received from the server SYNC command , perform BGSAVE command , Create include key k1 To key 10089 Of RDB file , And use the buffer to record all subsequent write commands | |
| T10094 | BGSAVE Order executed , To the slave server RDB file | |
| T10095 | Receive and load the data sent by the master server RDB file , Get key k1 to k10089 | |
| T10096 | Because in BGSAVE During the execution of the order , The master server did not execute any write commands , So skip the write command contained in the send buffer | |
| T10097 | The master and slave servers complete the synchronization again | The master and slave servers complete the synchronization again |
In time T10091, Reconnected from the server to the master server , Because at this time, the status of the master and slave servers has been inconsistent , So the slave server will send to the master server SYNC command , The main server will contain keys k1 To key k10089 Of RDB File sent to slave , Receive and load this from the server RDB File to update your database to the current state of the main server database
although SYNC The command can return the master and slave servers to the consistent state , But study this broken line duplication process carefully , Transmission can be found RDB Documentation is not a necessary step :
- The difference in database status between master and slave servers lies in the key k10087 To key k10089, And the key k1 To key k10086 These keys are the same , You only need to add keys from the server k10087 To key k10089 You can reach that the database state of the master-slave server is consistent
- It is a pity , The old version replication function does not propose a solution based on the above situation , Instead, let the master server generate and send the include key to the slave server k1 To key k10089 Of RDB file , But actually
RDBThe key contained in the file k1 To key k10086 It is unnecessary for the server
The above situation may be a little idealized : During the disconnection of the master and slave servers , The main server may execute hundreds of write commands , Not just twoorthree orders , And the amount of data generated by the write command executed during the disconnection is much less than that in the database . under these circumstances , In order to make up a small part of the missing data from the server , But let the master and slave server execute again SYNC command , Reload the RDB file , This approach is undoubtedly very inefficient
SYNC Command is a very resource intensive operation
Every time you execute SYNC command , Both master and slave servers need to perform the following actions :
- The master server needs to perform
BGSAVECommand to generateRDBfile , This build operation will cost the master server a lot ofCPU、 Memory and diskI/Oresources - The main server needs to be generated by itself
RDBFile sent to slave , This sending operation will consume a lot of network resources from the master and slave servers ( Bandwidth and traffic ), It also affects the response time of the master server to the command request - Received
RDBFiles from the server need to be loaded from the serverRDBfile , And during loading , The slave server will be unable to process command requests due to blocking
because SYNC Command is a resource consuming operation , therefore Redis It must be used with caution SYNC command , Only when it is really necessary
3, New version copy function
In order to solve the inefficient problem of the old version replication function in the case of broken line replication ,Redis from 2.8 Start , Use PSYNC Command instead of SYNC Command to perform replication synchronization
PSYNC The command has two modes: full resynchronization and partial resynchronization :
- Complete resynchronization : Complete resynchronization steps and
SYNCThe execution steps of the command are basically the same , Are created through the master serverRDBfile , And timely push the write command saved in the buffer of the main server for synchronization - Partial resynchronization : Partial resynchronization is used to deal with the situation of duplication after disconnection , When the slave server is disconnected, reconnect to the master server . If conditions permit , The master server can send the commands executed during the disconnection to the slave server , The slave server only needs to accept and execute these write commands , In this way, the database can be updated to the current state of the primary server
Look at the following example :
| Time | master server | From the server |
|---|---|---|
| T0 | Master slave server completes synchronization | Master slave server completes synchronization |
| T1 | Execute and disseminate SET k1 v1 | Execute the SET k1 v1 |
| T2 | Execute and disseminate SET k2 v2 | Execute the SET k2 v2 |
| …… | …… | …… |
| T10085 | Execute and disseminate SET k10085 v10085 | Execute the SET k10085 v10085 |
| T10086 | Execute and disseminate SET k10086 v10086 | Execute the SET k10086 v10086 |
| T10087 | The master-slave server is disconnected | The master-slave server is disconnected |
| T10088 | Execute and disseminate SET k10087 v10087 | Broken line , Try reconnecting to the primary server |
| T10089 | Execute and disseminate SET k10088 v10088 | Broken line , Try reconnecting to the primary server |
| T10090 | Execute and disseminate SET k10089 v10089 | Broken line , Try reconnecting to the primary server |
| T10091 | Reconnect the master and slave servers | Reconnect the master and slave servers |
| T10092 | Send to primary server PSYNC command | |
| T10093 | Return to the slave server +CONTINUE reply , Represents a partial resynchronization | |
| T10094 | receive +CONTINUE reply , Ready to perform partial resynchronization | |
| T10095 | To the slave server SET k10087 v10087、SET k10088 v10088、SET k10089 v10089 | |
| T10096 | Accept and execute the three SET command | |
| T10097 | The master and slave servers complete the synchronization again | The master and slave servers complete the synchronization again |
Compared with SYNC command ,PSYNC The execution of the command only needs to send the command missing from the slave server to the slave server for execution .
So the next question is , How does the master server determine which commands are missing from the slave server ?
Implementation of partial resynchronization
The partial resynchronization function consists of three parts :
- Replication offset of the primary server (
replication offset) And the replication offset from the server - Replication backlog buffer for primary server (
replication backlog) - Running the server
ID(run ID)
3.1, Copy offset
Both parties performing the replication maintain a replication offset
- Each time the master server propagates to the slave server N Bytes of data , Add the value of your copy offset to N
- Every time the master server propagates from the server N Bytes of data , Add the value of your copy offset to N
If there are so many servers :

If the master server propagates to three slave servers, the length is 33 Bytes of data , Then the replication offset of the primary server will be updated to 10119, After the three slave servers receive the data transmitted by the master server , The copy offset is also updated to 10119:
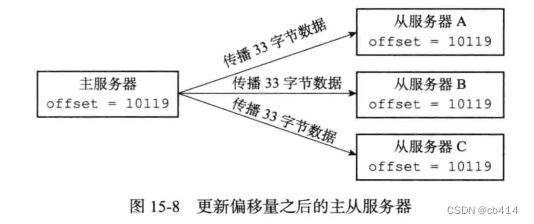
Suppose from the server A After disconnecting and reconnecting to the primary server , The slave will send... To the master PSYNC command , Report from server A The current copy offset is 10086, Then, does the master server perform full resynchronization or partial resynchronization on the slave server ? In case of partial resynchronization , And how to compensate for the actual data from the server ? The answer is related to the replication backlog buffer
3.2, Copy backlog buffer
The replication backlog buffer is a fixed length first in, first out queue maintained by the primary server , The default size is 1MB
The entry and exit rules of fixed length FIFO queues are the same as those of ordinary FIFO queues , The difference is : Ordinary FIFO queues will dynamically adjust their length with the increase and decrease of elements , The length of the fixed length FIFO queue is fixed , When the number of queued elements is greater than the queue length , The first element to join the team will be ejected , And new elements are put into the queue
For example, a length of 3 Fixed length FIFO queue , Now it's time to ‘h’、’e’、‘l’、‘l’、‘o’ Put five characters in the queue
- Put in first
‘h’、’e’、‘l’, At this point the queue is full - Then put
‘l’, Will ‘h’ Pop up the queue , The queue becomes :‘e’、’l’、‘l’ - Then put it in
‘o’
Determination of the size of the replication backlog buffer
【 It is worth mentioning that : If the size of the copy backlog buffer is set unreasonably , that PSYNC The replication resynchronization mode of does not work properly , Therefore, it is very important to correctly estimate and set the size of the replication backlog buffer . The minimum size of the copy backlog buffer can be determined according to the formula ( The average time it takes to reconnect to the primary server after disconnecting from the server )* ( The average amount of write command data generated by the master server per second ( The total length of write commands in protocol format ))】
When the master server propagates commands , It not only sends write commands to all slave servers , The write command is also queued into the copy backlog buffer :

Therefore, the replication backlog buffer of the master server will store some recently propagated write commands , And the copy backlog buffer records the copy offset for each byte in the queue , Such as :

When the slave server reconnects to the master server , The slave server will go through PSYNC Command to copy its own offset offset Send to the main server , The master server will decide whether to perform full resynchronization or partial resynchronization on the slave server according to this replication offset :
- If
offsetData after offset ( That is, the offsetoffset+1Starting data ) It still exists in the replication backlog buffer , Then the master server will partially resynchronize the slave server - contrary , If
offsetThe data after the offset no longer exists in the copy backlog buffer , Then the master server will perform a full resynchronization operation on the slave server
Combined with the previous example , The new copy function handles the example of disconnection and reconnection :
- When the slave server A After disconnection , It immediately reconnects to the primary server , And send... To the main server
PSYNCcommand , Report your copy offset as 10086 - The master server received a message from the server
PSYNCCommand and offset 10086, The master server will check the offset 10086 Whether the subsequent data exists in the copy backlog buffer , It turns out that these data still exist , Then the master server will send+CONTINUEreply , Indicates that the data synchronization will be carried out by partial resynchronization - Then the master server will copy the backlog buffer 10086 All data after the offset is sent to the slave server
- You only need to receive this from the server 33 Missing data of bytes , It can be consistent with the database state of the primary server !

3.3, Server running ID
In addition to copy offsets and copy backlog buffers , Some resynchronization also requires the server to run ID(run ID)
- Every
RedisThe server , Both the master server and the slave server have their own operationID - function
IDAutomatically generated when the server starts , from 40 Random hexadecimal characters
When the primary server is replicated from the secondary server for the first time , The main server will run its own ID Deliver to slave , And the slave server will run this ID Save up . When the slave is disconnected and reconnected to a primary server , The slave server will send the previously saved run... To the currently connected master server ID:
- If the sent run
IDAnd the operation of the current main serverIDidentical , Then it means that the master server is connected before disconnecting from the server , The master server will try to perform some resynchronization - If it's not the same , Then it means that the current master server is not connected before disconnecting from the server , The master server will fully resynchronize the slave server
4,PSYNC Implementation of commands
PSYNC There are two ways to call commands :
- If the slave server has not replicated any master server before , Or did it before
SLAVEOF no onecommand , Then the slave server will send... To the master server when starting a new replicationPSYNC ? -1command , Actively request the master server for complete resynchronization - contrary , If the slave server has replicated a master server , Then the slave server will send... To the master server when starting a new replication
PSYNC <runid> <offset>command , amongrunidIs the operation of the last replicated primary serverID, andoffsetThe current copy offset from the server , The master server that receives this command will determine which synchronization operation should be performed on the server through these two parameters
According to the circumstances , Received PSYNC The master server of will return one of the following three replies to the slave server :
- If the master server returns
+FULLREYSNC <runid> <offset>reply , Indicates that the master server will perform a complete resynchronization with the slave serverrunid: Operation of the main serverID, The slave server will send thisIDSave up , Send nextPSYNCUseoffset: The current replication offset of the primary server , The slave server will use this value as its initialization offset
- If the master server returns
+CONTINUEreply , Then it means that the master server will perform partial resynchronization with the slave server , The slave server just needs to wait for the master server to send the missing data - If the master server returns
-ERRreply , Indicates that the version of the primary server is lower thanRedis2.8, It doesn't recognizePSYNCcommand , The slave will send... To the masterSYNCcommand , And perform complete resynchronization with the main server
The relevant schematic diagram is as follows :

Here is a complete copy -》 Network interruption - Example of repetition :
- First, there is the master server A:
127.0.0.1:6379And from the server :127.0.0.1:12345 - The client sends commands to the slave server
SLAVEOF 127.0.0.1 6379, Suppose that the slave server performs the replication operation for the first time , Then the slave server will send... To the master serverPSYNC ?-1command , Request the master server to perform a full resynchronization operation - After the master server receives the complete resynchronization request , Execute in the background
BGSAVEcommand , And return to the slave server+FULLRESYNC The main server is running ID 10086, Among them 10086 Is the master server replication offset - Assuming that the full resynchronization is successfully performed , And the master and slave servers keep the database state consistent for a period of time . But when copying to an offset of 20000 When , The network connection between the master and slave servers is interrupted , After a while , Reconnect from the server to the master server , And replicate the primary server again
- Because the primary server has been replicated before , So the slave server will send commands to the master server
PSYNC The main server is running ID 20000, Request partial resynchronization - The master server received from the slave server
PSYNCAfter the command , First, compare the running data from the serverID, And with its own operationIDCompare . The results show the same , So the master server continues to read the offset from the server 20000, Check that the offset is 20000 Whether the subsequent data exists in the replication backlog buffer , It turns out that it still exists - Confirm operation
IDAfter the same data exists , The master server will return to the server+CONTINUEreply , Indicates that partial resynchronization will be performed from the server , After that, the master server will receive all the data required by the slave server ( Data after offset ) Send to slave , The master-slave server database status returns to consistent again
5, Implementation of replication
Here are Redis2.8 And the detailed implementation steps of the replication function of the above version :
- Set the address and port of the master server
- Establish a socket connection
- send out
PINGcommand - Authentication
- Send port information
- Sync
- Command propagation
5.1, Set the address and port of the master server
When the client executes the following command to the slave server :
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
The first thing to do from the server is to give the client to the master server IP The address and port are saved to the server state masterhost Properties and masterport Attributes inside :
struct redisServer{
//...
// Primary server address
char *masterhost;
// Primary server port
int masterport;
//...
};
After executing the order , From the service status of the server :

5.2, Establish a socket connection
perform SLAVEOF After the command , The slave server will set the address and port according to the command , Create a socket connection to the primary server . If the socket created from the server can successfully connect to the primary server , Then the slave server will associate this socket with a file event handler specially used to handle replication , This processor will be responsible for the subsequent replication . Like receiving RDB file 、 Receive the write command from the master server .
After the master server receives the socket connection from the slave server , The corresponding client state will be created for the socket , And treat the slave server as a client connected to the master server .【 At this time, the slave server will have two identities of server and client 】
Because the next few steps of replication work will be carried out in the form of sending command requests from the server to the master server , So understand “ The slave server is the client of the master server ” This is very important
5.3, send out PING command
When the slave server becomes the client of the master server , The first thing is to send a PING command

Here PING Commands have two functions :
- Although the master-slave server successfully established a socket connection , However, the two parties have not used the socket for any communication , By sending
PINGThe command can check whether the socket read-write state is normal - By sending
PINGCommand to check whether the main server can normally process command requests
Sending from server PING The command is followed by one of three situations :
- The master server sent a command reply to the slave server , However, the network connection between master and slave servers is unstable , Subsequent steps of replication cannot continue . When that happens , Disconnect from the server and recreate the socket to the master server
- If the master server returns an error to the slave server , Then it means that the master server cannot handle the command request of the server for the time being , Subsequent steps of replication cannot continue . When that happens , Disconnect from the server and recreate the socket to the master server
- If you read from the server
PONGreply , It indicates that the network connection between the master and slave servers is normal and the master server can normally process the command requests of the slave server . In this case , From the server, you can proceed to the next step of replication
5.4, Authentication
Received from the master server PONG reply , The next step is to decide whether to authenticate :
- If the slave server is set
masterauthOptions , Then authenticate - If none is set from the server
masterauthOptions , So no authentication
When authentication is required , The slave server will send a message to the master server AUTH command , The parameter of the command is server ,masterauth The value of the option .
Suppose from the server masterauth The value of is 10086, Then the slave server will send... To the master server AUTH 10086
What the slave server may encounter during the authentication phase :
- The master server is not set
requirepassOptions , The slave server is not set up eithermasterauthOptions , Then nothing happens , The replication continues - The master server is set to
requirepassOptions , The slave server is not setmasterauthOptions , Then the primary server will return oneNOAUTHerror ; If the primary server is not setrequirepassOptions , Set up... From the servermasterauthOptions , Then the primary server will return oneno password is seterror - If passed from the server
AUTHCommand to send password and master serverrequirepassThe values of options are consistent , Then the master server will continue to execute the command sent from the server , The replication continues ; If it's not the same , Then the primary server will return oneinvalid passworderror
All errors will stop the current replication work from the server , And re execute the copy from the socket creation , Until authentication passes , Or abandon the replication from the server

5.5, Send port information
After the authentication step , The slave server will execute the command REPLCONF listening-port <port-number> Sends the listening port number of the slave to the master server
After the master server receives this command , Record the port number in the corresponding client state of the slave server slave_listening_port Properties of the
5.6, Sync
In this step , The slave will send... To the master PSYNC command , Perform synchronous operation , of PSYNC The information of has been described above , So I won't go into details
5.7, Command propagation
When synchronization is complete , The master slave server enters the command propagation phase , As long as the master server keeps sending its own write commands to the slave server , The slave server only needs to execute these commands , It can ensure that the database state of the master-slave server is consistent
6, The heartbeat detection
Command propagation stage , The slave server defaults to once per second , Send commands to the main server REPLCONF ACK <replication_offset>, among replication_offset Is the current replication offset from the server .
REPLCONF ACK The command has three functions for the master and slave servers :
- Detect the network connection status of the master-slave server
- The master and slave servers send and receive
REPLCONF ACKCommand to check whether the network connection between the two is normal : If the master server does not receive the message from the server for more than one secondREPLCONF ACKcommand , Then the master server knows that there is a problem with the connection between the master and slave servers
- The master and slave servers send and receive
- Aided implementation
min-slavesOptionsRedisOfmin-slaves-to-writeandmin-slaves-max-lagOption can prevent the master server from executing commands under unsafe conditions- hypothesis
min-slaves-to-wirteThe value of is 3,min-slaves-max-lagThe value of is 10. So the number of slave servers is less than 3 individual , Or three slave server delays (lag) All values are greater than or equal to 10 seconds , The master server will refuse to execute the write command
- Detection command lost
- If it's due to a network failure , As a result, the write command sent by the master server to the slave server is not received by the slave server , So when the slave server sends to the master server
REPLCONF ACKOn command , Bring the copy offset from the server , The master server accepts the command and compares it with its own copy offset , We can know whether the command is lost . Then the master server will use the replication offset submitted by the server , Send the missing data found in the replication backlog buffer to the slave server
- If it's due to a network failure , As a result, the write command sent by the master server to the slave server is not received by the slave server , So when the slave server sends to the master server
【 It is worth mentioning that :REPLCONF ACK yes Redis2.8 New version of ,Redis2.8 Previous versions , Even if the command is lost , The master and slave servers will not notice , The master server will not reissue the missing data to the slave server , So in order to ensure data consistency during replication , Best use Redis2.8 And above 】
边栏推荐
- How to mount NFS shares using autofs
- Is it safe to contact the account manager online to open a fund account?
- Industry insight | how to better build a data center? It and business should "go together"
- 1.9. touch pad test
- 树莓派自建 NAS 云盘之——树莓派搭建网络存储盘
- 手把手教你用 Power BI 实现 4 种可视化图表
- C language course design -- hotel management system
- Nacos deployment
- Make a fake! Science has exposed the academic misconduct of nature's heavy papers, which may mislead the world for 16 years
- 【C语言】动态内存管理
猜你喜欢

Wang Ping, co-founder of Denglin Technology: Innovation + self research "dual core" drive, gpu+ enabling AI takes root | quantum bit · viewpoint sharing review

SSM online examination system including documents

No routines, no traps, no advertisements | are you sure you don't need this free instant messaging software?

26. Reverse linked list II

开山之作造假!Science大曝Nature重磅论文学术不端,恐误导全球16年

Custom scroll bar
Say no to blackmail virus, it's time to reshape data protection strategy

SSM在线校园相册管理平台

ESP32ADC

【C语言】详细的文件操作相关知识

随机推荐
How to mount NFS shares using autofs
基于matlab的语音处理
About thread (3) thread synchronization
Is it safe to open an account on Oriental Fortune online? Is there a threshold for opening an account?
Step of product switching to domestic chips, stm32f4 switching to gd32
Use typeface to set the text font of textview
七月集训(第24天) —— 线段树
24. Merge K ascending linked lists
Nearly 65billion pieces of personal information were illegally handled in seven years, and the investigation of didi network security review case was announced
Why does 2.tostring() report an error
Raspberry pie self built NAS cloud disk -- automatic data backup
QT based software framework design
English grammar_ Indefinite pronouns - Overview
The price of domestic flagship mobile phones is nearly 6000, but they can't even beat iphone12. It's clear who users choose
猿人学第五题
Compatibility problems of call, apply, bind and bind
setAttribute、getAttribute、removeAttribute
Why has API strategy become a magic weapon for enterprises' digital transformation?
nacos部署
Arduino框架下ESP32 EEPROM库函数实现对各数据类型保存示例