当前位置:网站首页>Structured machine learning project (I) - machine learning strategy
Structured machine learning project (I) - machine learning strategy
2022-06-27 22:29:00 【997and】
This study note mainly records various records during in-depth study , Including teacher Wu Enda's video learning 、 Flower Book . The author's ability is limited , If there are errors, etc , Please contact us for modification , Thank you very much !
Structured machine learning project ( One )- Machine learning strategies
- One 、 Why ML Strategy (Why ML Strategy)
- Two 、 Orthogonalization (Orthogonalization)
- 3、 ... and 、 A single number measures (Single number evaluation metric)
- Four 、 Meet and optimize indicators (Satisficing and optimizing metrics)
- 5、 ... and 、 Training / Development / Test set partitioning (Train/dev/test distributions)
- 6、 ... and 、 The size of the development set and the test set (Size of dev and test sets)
- 7、 ... and 、 When to change development / Test sets and metrics ?(When to change dev/testt sets and metrics)
- 8、 ... and 、 Why is it human performance (Why human-level performance)
- Nine 、 Deviation can be avoided (Avoidable bias)
- Ten 、 Understand human performance (Understanding human-level performance)
- 11、 ... and 、 Super performance (Surpassing human-level performance)
- Twelve 、 Improve your model performance (Improving model performance)
The first edition 2022-05-31 first draft
One 、 Why ML Strategy (Why ML Strategy)

1. Collect more data
2. Training set diversity
3. Gradient descent training algorithm
4. Use larger or smaller Neural Networks
5.Adam optimization algorithm
6. Larger or smaller neural networks
7.dropout or L2 Regularization
8. Modify the network architecture : Modify activation function 、 Change the number of hidden units
Two 、 Orthogonalization (Orthogonalization)

Orthogonalization is the design of such buttons by TV designers , Each button adjusts only one property .
Cars are the same .
1. The training set cannot be well fitted in the cost function
2. It is found that the fitting of the algorithm to the development set is very poor
3. The development set is well done , But it's not done well in the test set
4. Unable to provide a good experience for users of cat image application , Need to change development set and cost function .
Generally do not use early stopping, But at the same time improve the performance of the development set
3、 ... and 、 A single number measures (Single number evaluation metric)

Precision rate ( How many of the classifiers are really cats )、 Recall rate ( For a real cat , The percentage of correct recognition by the classifier )、F1 Score( combination P and R)
The development team is generally , There is a well-defined development set to measure precision and recall , Plus a single numerical evaluation index .
C It looks good
Four 、 Meet and optimize indicators (Satisficing and optimizing metrics)

Accuracy and running time can be combined into an overall evaluation index .
Or choose a classifier , Maximize accuracy , But it must meet the time requirement .
Or consider N Indicators , Sometimes one of them is reasonable as an optimization index , be left over N-1 One is to meet the target .
5、 ... and 、 Training / Development / Test set partitioning (Train/dev/test distributions)
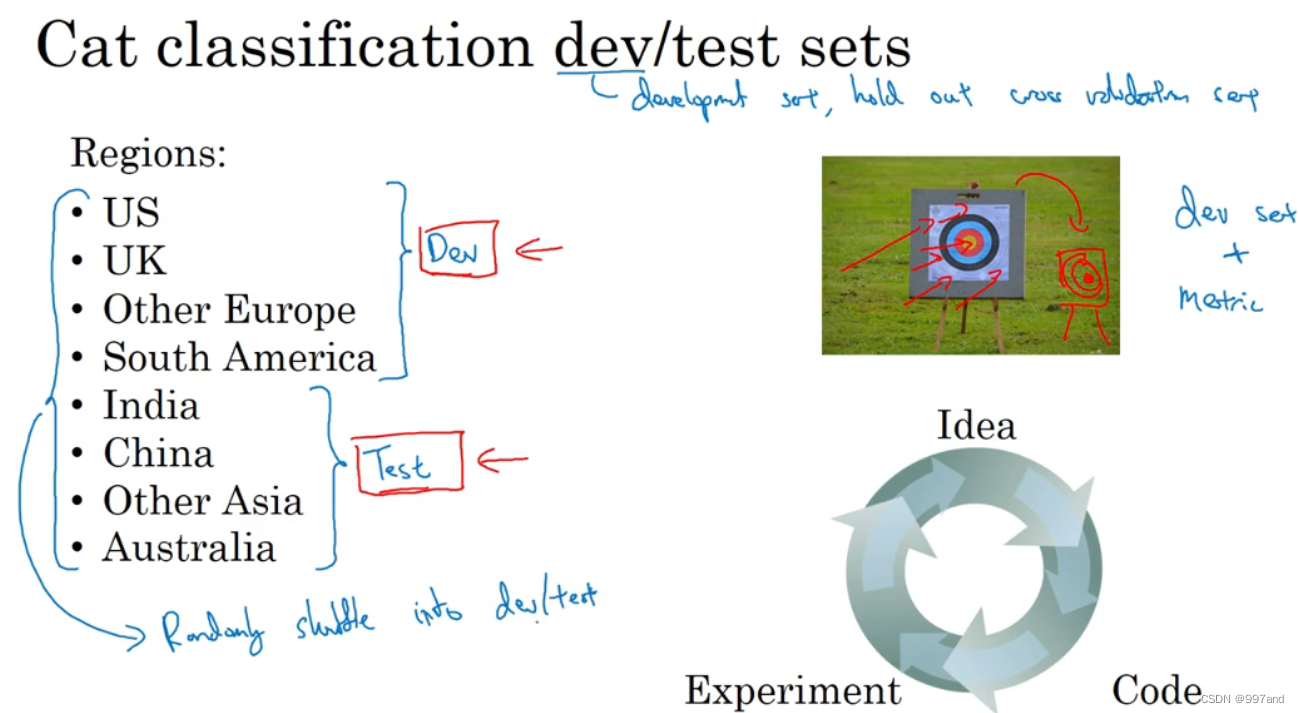
Development set , Also called development set, Sometimes called preserving cross validation sets (hold out cross validation set).
As an example , How to set up a development set and a test set ?
You can select four of these areas , The first four constitute the development set , The other four make up the test set . The truth is awful . It is recommended that the development set and the test set come from the same distribution .
It may take a few months to perform poorly , It is recommended to shuffle all data randomly , Put in the development set and the test set , It all comes from the same distribution .
A team aims at one goal in three months , After three months, another goal collapsed .
Select such development and test sets , It can reflect the data that will be obtained in the future ,, Data considered important .
6、 ... and 、 The size of the development set and the test set (Size of dev and test sets)

All data 70/30 The proportion is divided into training set and test set ;
Or training set 、 Development set 、 The test set is divided into 60/20/20;
In the present age , Onemillion samples ,98 Training set ,1 Development set D,1 Test set T
Only training set and development set .
summary : Big data era ,70/30 No longer applicable , Now it is popular to divide a large amount of data into training sets , A small amount is divided into development set and test set . The previous experience method is to ensure that the development set is large enough , Achieve a goal , Evaluate different ideas ,A Good or not B good . The test set is to evaluate the final cost variance .
7、 ... and 、 When to change development / Test sets and metrics ?(When to change dev/testt sets and metrics)

The index used is the classification error rate ,A Better . but A Because some cases will push bad pictures , So for the company ,A Better .
The classification error rate index shall be written as shown in the figure .m_dev Is the number of development set examples ,y_pred Represents the predicted value ,I Represents a function : Count the number of samples in which the expression is true .
The above indicators will treat bad and correct pictures equally , Add the weight item w, If picture x Not bad drawings w=1; if , It may be 10 even to the extent that 100. If you want to normalize constants , Add .
The significance of the evaluation index is to tell which classifier is more suitable for .
1. Know how to define an indicator to measure the performance of what you want to do , A completely independent step
2. Then consider separately how to improve the performance of the system on this indicator . May approach the target , The learning algorithm is optimized for a certain cost function .
How to define J Is not important , The key is orthogonalization

Two cat classifiers A and B, Another example of problems with metrics and development set tests , Professional picture shooting .
It's best not to run too long without evaluation metrics and development sets .
8、 ... and 、 Why is it human performance (Why human-level performance)

1. Because of deep learning , Machine learning is getting better ;
2. The workflow of machine learning system can be designed carefully .
Over time , When continuing to train the algorithm , Maybe the model is getting bigger , More and more data , But the performance cannot exceed a certain theoretical upper limit , This is the so-called Bayesian optimal error rate (Bayes optimal error), Sometimes writing Bayesian.
Why surpass human performance , Progress slows down ?
1. The human level is not far from the Bayesian optimal error rate in many tasks , There is not much room for improvement beyond human performance ;
2. Perform worse than humans , There are actually some tools available to improve performance , Beyond the human performance tool is not easy to use .
Better people can make people tag data
Nine 、 Deviation can be avoided (Avoidable bias)

Human error rate 1%, The learning algorithm reaches 8% Training error rate and 10% Development error rate . Focus on reducing deviations , For example, training a larger neural network or running for a long time with gradient descent .
The second example in the second column : Focus on reducing variance , Try regularization .
Take this difference , The Bayesian error rate or the difference between the estimated Bayesian error rate and the training error rate is called avoidable deviation .
Ten 、 Understand human performance (Understanding human-level performance)

Classify and judge radiology images , As shown in the figure, there are four categories :
If the level exceeds one radiologist, it can have deployment value .
The difference between training error and development error can measure or estimate how serious the variance problem of learning algorithm is .
First example , take 1% Namely 4%, take 0.5% Namely 4.5%, The gap is 1%, In this case, focus should be on reducing the deviation , Such as training a larger network .
Second example , disparity 4%, Reduce variance , Such as regularizing or getting a larger training set .
Third , use 0.5% Estimating Bayesian error rate has a lot to do with , It indicates that deviation and variance may exist . This happens only when the algorithm is well trained .
11、 ... and 、 Super performance (Surpassing human-level performance)

The first example on the left
The second example on the right , I don't know whether to reduce bias or variance 
Twelve 、 Improve your model performance (Improving model performance)

Supervise learning to be practical :
1. The algorithm fits the training set well
2. It is good to extend it to the development set and the test set
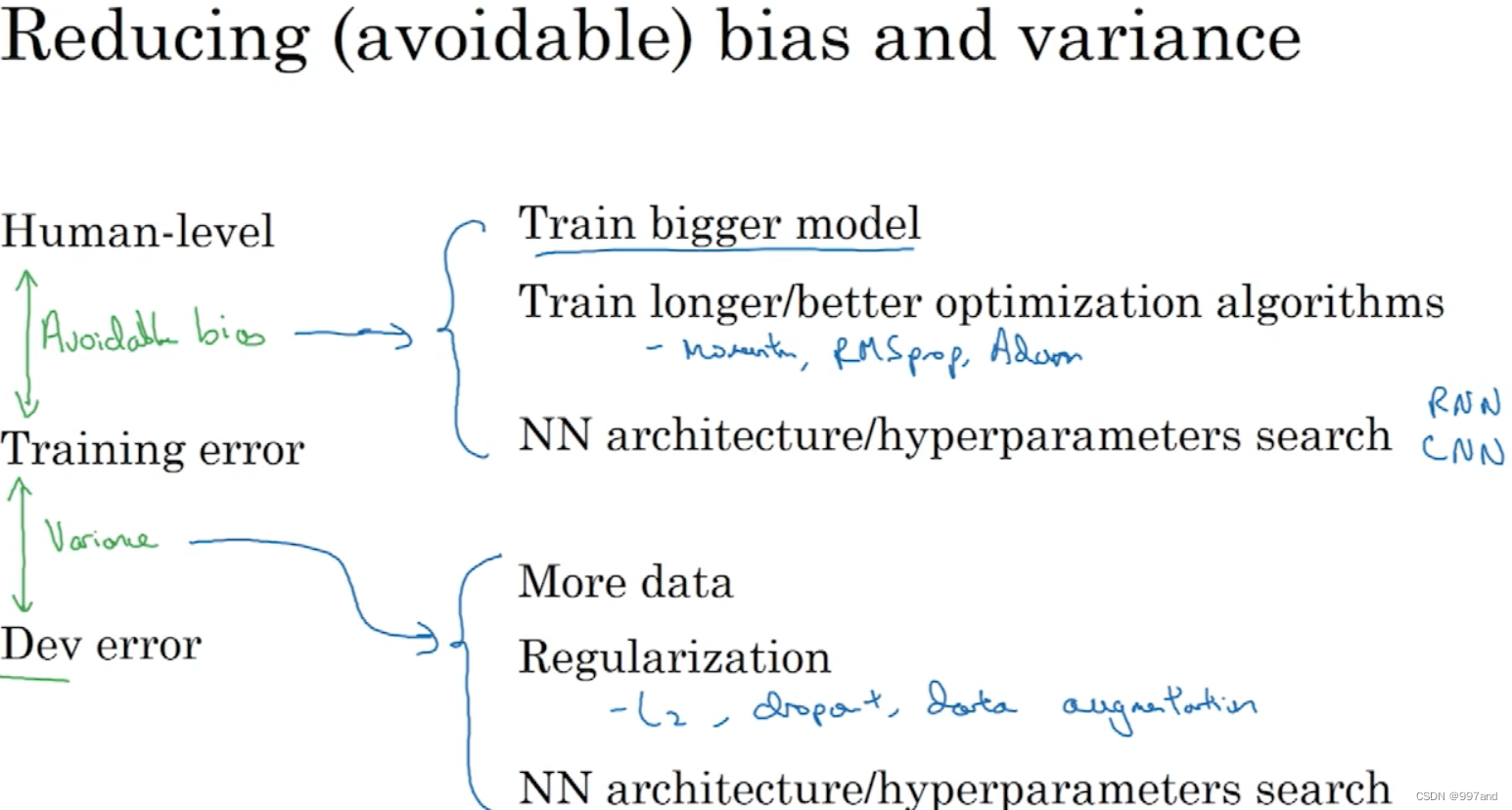
Reduce avoidable deviations : Larger models or Train longer or With better optimization algorithms ,Momentum/RMSprop or Better algorithm ,Adam. Or new neural network architecture or Better super parameters .
When variance is a problem , More data or Regularization ,L2/dropout or Data to enhance or Different neural network architectures or Super parameter search
1
边栏推荐
- 軟件測試自動化測試之——接口測試從入門到精通,每天學習一點點
- C language programming detailed version (learning note 1) I can't understand it after reading, and I can't help it.
- Typescript learning
- \W and [a-za-z0-9_], \Are D and [0-9] equivalent?
- QT base64 encryption and decryption
- Conversation Qiao Xinyu: l'utilisateur est le gestionnaire de produits Wei Brand, zéro anxiété définit le luxe
- Software defect management - a must for testers
- 单元测试界的高富帅,Pytest框架,手把手教学,以后测试报告就这么做~
- Management system itclub (medium)
- 6G显卡显存不足出现CUDA Error:out of memory解决办法
猜你喜欢

渗透学习-靶场篇-pikachu靶场详细攻略(持续更新中-目前只更新sql注入部分)

使用sqlite3语句后出现省略号 ... 的解决方法

登录凭证(cookie+session和Token令牌)

average-population-of-each-continent

Secret script of test case design without leakage -- module test

Experience sharing of meituan 20K Software Test Engineers

Solution to the error of VMware tool plug-in installed in Windows 8.1 system

Deep learning has a new pit! The University of Sydney proposed a new cross modal task, using text to guide image matting
VMware virtual machine PE startup
Windwos 8.1系统安装vmware tool插件报错的解决方法
随机推荐
Gbase 8A OLAP analysis function cume_ Example of dist
It smells good. Since I used Charles, Fiddler has been completely uninstalled by me
Go from introduction to actual combat - task cancellation (note)
同花顺炒股软件可靠吗??安全嘛?
\W and [a-za-z0-9_], \Are D and [0-9] equivalent?
Matlab finds the position of a row or column in the matrix
MONTHS_BETWEEN函数使用
爬虫笔记(3)-selenium和requests
crontab定时任务常用命令
Selenium上传文件有多少种方式?不信你有我全!
关于davwa的SQL注入时报错:Illegal mix of collations for operation ‘UNION‘原因剖析与验证
爬虫笔记(2)- 解析
Typescript learning
How many ways does selenium upload files? I don't believe you have me all!
Login credentials (cookie+session and token token)
[LeetCode]30. Concatenate substrings of all words
QT large file generation MD5 check code
二维数组中修改代价最小问题【转换题意+最短路径】(Dijkstra+01BFS)
Management system itclub (Part 1)
Codeforces Round #721 (Div. 2)