当前位置:网站首页>Unmanned driving: Some Thoughts on multi-sensor fusion
Unmanned driving: Some Thoughts on multi-sensor fusion
2022-06-25 00:08:00 【naca yu】
Preface
thank Shangtang academic 2022/06/22 Based on BEV Look around perception live course , Take advantage of this opportunity , Summed up my previous work , The main contents are as follows :
- FOV and BEV Common solutions , The two perspectives are Visual inspection technology and principle To compare , And sum up the Advantages and disadvantages ;
- The fusion schemes from two perspectives are summarized : Especially in the current academic circles “ Cold door ” Of Millimeter wave radar (Radar) And “ hot ” Of Laser radar (lidar) Compare the fusion schemes of , Different from laser radar , The editor put forward a more suitable needle for Radar Fusion scheme .
The editor's research in this field is not deep 、 I know little about the layout of the industry , Only as their own learning summary and knowledge sharing , If there are any mistakes and mistakes , Please point out , thank you ~
One 、FOV visual angle

FOV As one of the closest human perspectives , Has a long history , Today, 2D\3D object detection All from FOV Start from Perspective , Sensually ,FOV Perspective can provide rich texture information 、 In depth information , At the same time, it can meet the requirements of common target detection perspectives, such as mask detection 、 Face recognition and other tasks , On the other hand ,FOV The data information of is easy to collect, such as imagenet、coco etc. . however ,FOV There are also some drawbacks to our information : Occlusion problem , Scale problem ( Different objects have different scales at different depths )、 Difficult to integrate with other modes 、 High fusion loss (Lidar Radar Etc. are suitable for BEV visual angle ) etc. .
1.1 Common solutions
The technical proposal is divided into two parts , One side , This paper briefly introduces the pure visual inspection method , On the other hand , Focus on FOV Fusion technology from the perspective of , It is divided into lidar+camera And radar+camera Two types of , The two classes are highly similar in terms of fusion technology , many Radar Our fusion methods are inspired by Lidar Fusion method .
1.1.1 FOV Detection method under pure vision
There is not much here , It is mainly divided into one-stage, two-stage, anchor-based, anchor-free.
besides ,3D There are some representative methods in the detection field :
The improved 2D test method :FCOS3D

The author of the paper FCOS On the basis of , Yes Reg Branch for partial modification , Make it possible to return centerpoint At the same time , Add other indicators : Center offset 、 depth 、3D bbox Size, etc , The realization of will 2D The detector is used for 3D Detector crossing . besides , Include YOLO3D Etc , The traditional 2D detector After simple modification, it is directly used in 3D The method of detection , Although the revision has achieved some results , But the image itself lacks accurate depth information , In addition, the structure is not as good as before 2D A certain prior structure is added to the detection , The effect is average .Method of generating pseudo point cloud from image :Pseudo-Lidar

It can be seen from the formula that , Depth information is very important for us to estimate the location of the target , Known pixel coordinates and camera internal parameters , We also need to know the depth to determine the location of the target , So depth information is important for 3D It is very important for target detection .

Getting in-depth information has also become 3D The key task of target detection : The solutions are mainly divided into :
A special training backbone Encoding depth information But this method is not accurate , 2. Process the in-depth information into pseudo-lidar As point cloud information . Third, through BEV Learn in a way BEV Feature to image mapping , Avoid the error loss caused by direct prediction of depth information .
Here is the second way to learn , A paper is called ”Pseudo-LiDAR from Visual Depth Estimation“, The depth information collected by stereo or binocular or monocular depth estimation is taken as depth information and processed into pseudo laser point cloud , After that, the detection head based on point cloud is used 3D object detection .
- Conventional 2D test method :CenterNet

CenterNet It is an anchor based detection method , This anchor based detection method , Can not only return to the target 2D attribute , about depth,orientation etc. 3D Attributes can also be predicted , Therefore, this method can also be used for human posture recognition ,3D Target detection, etc .
- summary
Sum up , Currently based on FOV The detection method of is still unable to escape from the tradition 2D The paradigm of the detection framework , But the traditional framework is 3D I think there are the following problems :1. The pre training model fails to introduce distance information during training , As a result, it is difficult for some pre training models to be directly fine tuned for depth estimation .2. 3D Object detection is different from 2D testing , There is occlusion between different objects , And FOV There is a problem of object deformation when detecting from a visual angle .
1.1.2 FOV The fusion method of perspectives
FOV The fusion method of perspectives , It is mainly divided into :lidar+camera And radar+camera Two kinds of .
- FOV:Lidar + Camera
Lidar And Camera Of FOV Fusion of perspectives , There are several classic schemes :
PointPainting: Image aided point cloud detection , parallel

The author thinks that ,FOV to BEV Inaccurate depth information will lead to poor fusion effect , stay FOV The sparsity of pure point cloud detection results in the problem of false recognition and poor classification , In order to solve the problem of lack of texture information in pure LIDAR point cloud , With PointPainting The first fusion method integrates the image segmentation results into the point cloud image , Enrich point cloud semantics , Improved detection performance .MV3D:lidar Auxiliary image , parallel
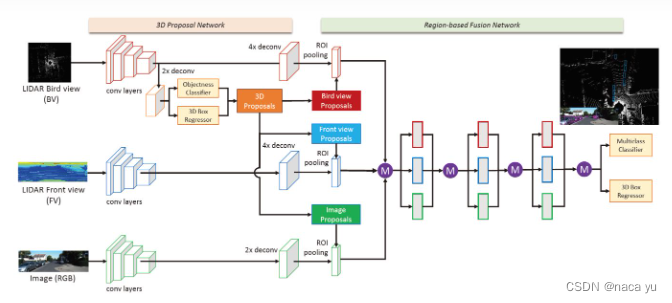
The author thinks that , Radar point cloud mainly has the following problems :1) sparsity (2) Disorder (3) Redundancy , This is through BEV For the first time in the perspective region proposal Post projection to lidar FV With images FV Layer to target ROI Pooling, Re pass deep fusion Fusion features , The last part 3D Regression and classification .F-PointNet: Image aided radar , Serial

stay RGB Running on the image 2D detector, Produced 2D bbox Used to define 3D The cone contains the foreground target point cloud . Then based on the 3D Point cloud (centerfusion Our inspiration comes from this ), Use PointNet++ Network implementation 3D Instance segmentation and subsequent implementation 3D Bounding box estimates .
- summary :
Sum up , Our list is based on FOV Fusion network of perspectives , It is mainly divided into image assisted types, such as pointpainting,proposal-level Type as MV3D, The serial image aided radar type is as follows F-PointNet, All three are in FOV Next , Use the image or radar data as an export or auxiliary to help detect another mode , stay FOV From the perspective of : First, although FOV It is more favorable for image mode , However, the depth and shape capability of radar will be limited by image mode , For example, project a point cloud onto an image , For targets with the same depth, the radar feature similarity is high, but the radar similarity of different parts of the same object is low , This is the opposite of the camera . Second, radar point cloud will restrict the rich texture of the image , for example pointpainting Although small objects have rich textures, only a few of them correspond to sparse radar points, resulting in the loss of information .
- FOV: Radar + Camera: I wrote a blog summary before , No more details here - > The article links
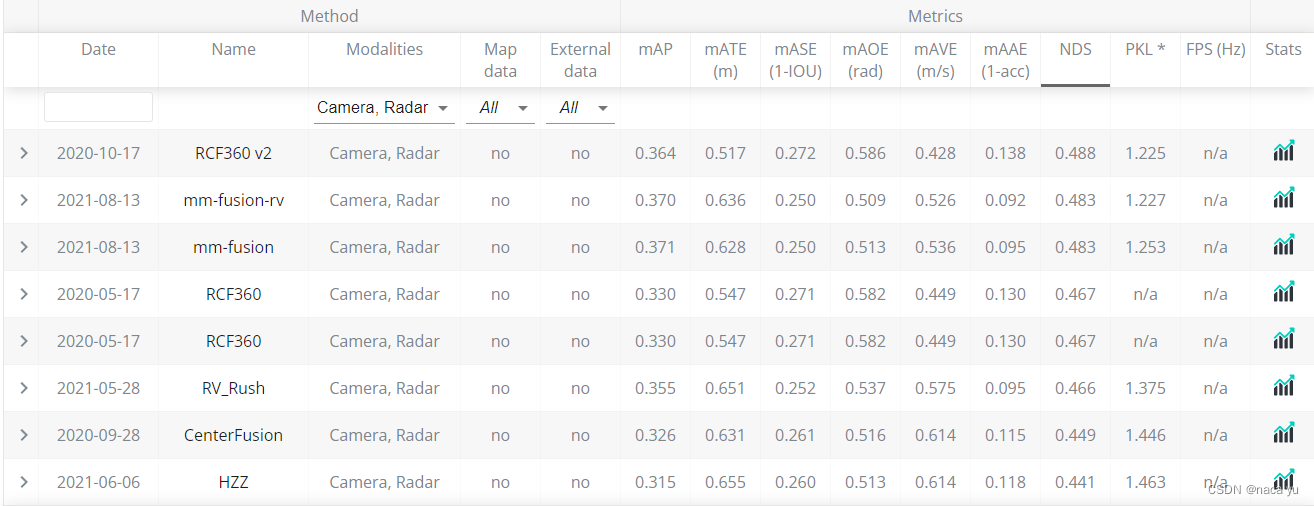
Two 、BEV visual angle

BEV Features have the following advantages :1. It can support multi-sensor fusion , Facilitate downstream multi task sharing feature.2. Different objects in BEV There is no deformation problem from the perspective , It can make the model focus on solving classification problems .3. It can fuse multiple perspectives to solve the occlusion problem and object overlap problem . however ,BEV Features also have some problems , for example grid The size of affects the granularity of detection , And there are a lot of background storage redundancy , because BEV It stores global semantic information .
You can see , The following figure BEV The detection methods have been among the best , I guess : On the one hand, it's because BEV Features recent fires , The academic community is concerned about BEV The recent model is biased towards BEV, On the other hand, maybe BEV Features are more than FOV It is suitable for automatic driving 3D object detection .
2.1 Common solutions
- Pure Camera
DETR3D: Implication BEV features

The author imitates DETR Methods , Use 900 individual object queries As query, The way 6 individual decoder Complete attention modeling , At the end of the day set-prediction How to predict the target 3D attribute , The author's innovation lies in decoder Medium "object queries refinement", Also is to queries To predict queries Corresponding 3D Location , Then, through the conversion matrix between the camera and the point cloud, it is converted to 2D Position and extract local features by bilinear interpolation add To raw queries As the next decoder block The input of , To sum up, it is through queries Implicit fusion of image features , Carry out a discrete BEV Feature construction and prediction .
But this method is not good for large target detection , One of them is through F.grid_sample() Extract local image information , Lack of overall semantic information .BEVFormer: Explicit BEV features
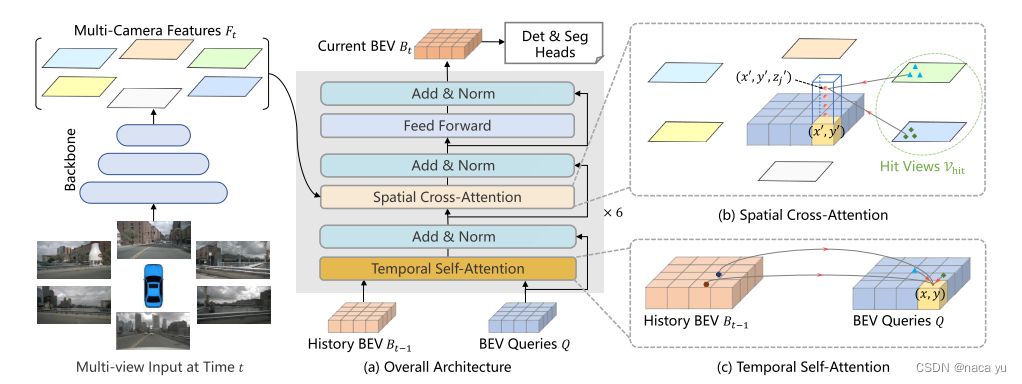
The author initializes a HWC The rules of 、 Explicit BEV queries As queries. meanwhile , Time sequence information of the previous time is added , Spatial information of the current moment . There are two main innovation modules :TSA and SCA, That is, temporal attention and spatial attention . say concretely , Every moment is the same as the last moment BEV queries do deformable Type of local attention , At the same time grid Divided into multiple heights , Multiple squares of the same height do spatial local attention to different images , Finally, the original BEV queries The size of BEV Feature as input to the next frame , At the same time, it is used as a feature map for downstream tasks such as map segmentation and target detection .
The editor thinks , such BEV feature At present, it is only used for single-mode information , For how to integrate multiple modes , Especially when introducing Radar Wait for the sparse point cloud , How to integrate into BEV in , second , How to measure accuracy and grid Measuring size is also a problem , also ,BEV The introduction of features limits the maximum detection distance , In the freeway scene , It is very important to detect distant targets , How to balance BEV The size and detection distance of is also a problem to be considered .
- Lidar + camera

Transfusion

The author considers the following questions :1. lidar The feature sparseness, especially the feature sparseness in the distance, will lead to the degradation of detection performance .2. Images lack spatial information , Difficult to apply directly to 3D Detecting such tasks with spatial information requirements .3. Whether it's lidar-to-camera The resulting loss of spatial location is still camera-to-lidar Resulting in the loss of semantic features , Traditional fusion methods are difficult to meet the needs of spatial and texture features .
Based on the above questions , The author puts forward Transfusion: First , The two types of special diagnosis use their own common backbone Extract feature information , after LidarBEV adopt image guidance send queries With image information , Adding a certain prior can make the model converge faster , The results are more accurate . After the lidar decoder The output of is used for lidar-camera decoder Part of the queries Fusion detection of image features .DeepFusion

Here we mainly propose : One :inverse aug And learnable align, The alignment problem of modal fusion after data enhancement and the adaptive alignment between modes are solved respectively , The way of integration here is to lidar As the main data source queries Merge as kv The image features of , And will query The corresponding image features are extracted and compared with radar features concat And fusion is used for feature detection .BEVFusion

This work must be based on :"Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D" This article , This article BEVFusion The essence of work is to LSS On the basis of , It accelerates the process of estimating the depth probability distribution , On this basis, radar is introduced BEV Features and fusion . This article is BEV The opening work of the integration mode , It still tops the list , At the same time, another version of this article mainly introduces the robustness of the model ( Ablation experiments were performed for another modal deletion ), This one emphasizes its efficiency , For example, the process of depth probability estimation is accelerated by tens of times .
- Radar + Camera: about BEV From the perspective of integration , At present, I haven't seen this year's integration scheme adopt , But a few years ago, there was a paper that directly projected image pixels onto BEV And combine Radar Features are used to detect .
2.2 summary
2.2.1 The perspective of integration

2.2.2 Comparison of fusion methods
Above BEV In the way of integration , One takes one mode as another q Go with another mode ( As k、v) Do attention and extract corresponding features for fusion , One is to treat the two modes separately , Transferred to the BEV Fusion from the perspective :
- The key of the first method is the alignment of the two modes ,lidar Often as Q Fusion of image features , This will not only exist because lidar Query omission caused by feature sparseness , And because of lidar Denseness results in multiple q Problems that map to the same goal .
- The key of the second method is that the image is from FOV The angle of view changes to BEV The alignment rate of the view angle , The result also depends on finding a better way to FOV Project features onto BEV in , This projection method includes LSS The depth probability division mentioned above , May refer to link , But this method has strong discreteness in depth , There are still many problems in the accurate estimation of depth : For example, the object boundary is fuzzy , It is quite different from the real scene .
3、 ... and 、Lidar object detection
be based on Lidar I will not introduce too much about the test of , May refer to link .
3.1 PointNet

3.2 PointPillars

3.3 VoxelNet

3.4 Pseudo-lidar
As described above
Four 、Radar And Camera The future of integration
4.1 Radar stay NuScenes Status of tasks

Radar detection performance is poor , And many companies in the industry have eliminated Radar Deployment of , I think there are several reasons :
- Radar points have noise problems , Compared with the traditional convolution learning method Pooling Although pooling can improve the confidence of the model in the foreground objects , But still can not effectively filter out the background noise , Background noise refers to the point cloud reflected by the surrounding background objects , In most scenarios , Most of the point cloud is background noise , The reason is that the radar signal itself lacks image information and has sparsity , Only through the depth of the radar itself 、 Location 、 The reflection intensity and other information cannot judge the semantic relationship of the point cloud
- The radar point has a flash point problem , Because of some Ghost point( Metal in dust, etc ) It will cause flash point problem and cause emergency brake failure , Such problems cannot be avoided in a single frame , The usual solution is to project the previous multi frame image onto the current frame , But this will lead to radar point offset error due to the movement of the target object , The reason is , Is the lack of timing information filtering
- Fusion method of radar and camera data : Previous work has been based on CNN, It has the assumption of translation invariance and local correlation for data , And it has inherent advantages for texture information , But for the radar mode , By visualizing the feature map , It is found that the radar feature map after fusion only plays an auxiliary role in enhancing the foreground objects , The fusion of the two has a bias towards image modality , Can not effectively use the advantages of radar mode itself
- The sparsity of radar

4.2 Status quo of industry convergence solutions
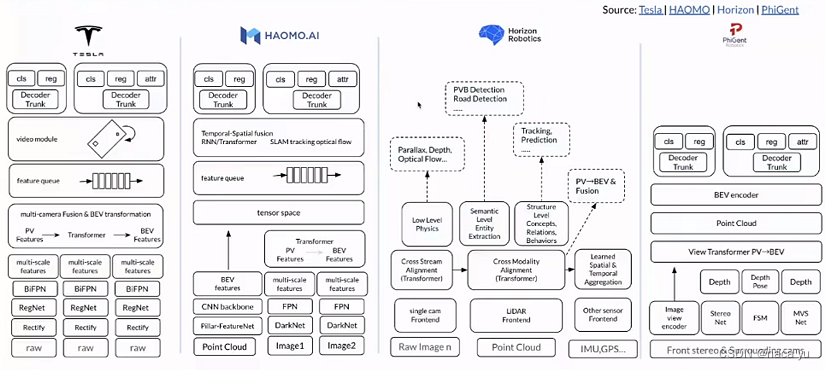
Pictured above , The integration method adopted by the industry has tended to be unified BEV normal form , Downstream feature extraction , Feature transformation , The introduction of timing information to the upstream has high similarity , And they all share the same scene features , And utilize multiple head Perform different downstream tasks separately , Horizon divides downstream tasks into low,semantic And other tasks at different levels , This is slightly different .
5.3 Radar & lidar Integration trend with camera
BEV At present, the characteristics tend to be recognized in academia and industry , Mainly because it is merging 、 Perceptual robustness 、 The adaptability of multiple downstream tasks , Especially in recent lists BEV Model excellence ,BEV Although it feels closer to the truth , But admit it , Today, BEV Features are still not comparable to multimodal BEV features , Simultaneous multimodal BEV There are still many problems to be solved .
about Radar The integration of , Can't directly lidar The scheme of is used for Radar, There are several reasons : First of all , Millimeter wave radar noise accounts for a high proportion , It's hard to learn ; second , Millimeter wave radar features are sparse , Difficult to use as q Index image features ; Third , Millimeter wave radar has strong penetration and strong reflection to metal , These features can effectively improve the detection performance for bad weather ;
For how in BEV Fusion from the perspective of Radar and Camera Well ? Some challenging points :1. How to introduce sparse millimeter wave radar into BEV visual angle ?2. How to reduce the noise of millimeter wave radar ?3. How to make full use of millimeter wave radar , It can improve the robustness when other modes are unstable ?
reference : To be sorted out
边栏推荐
猜你喜欢









随机推荐
Discrete mathematics and its application detailed explanation of exercises in the final exam of spring and summer semester of 2018-2019 academic year
Difficult and miscellaneous problems: A Study on the phenomenon of text fuzziness caused by transform
ArcGIS加载免费在线历史影像作为底图(不需要插件)
Investment analysis and prospect forecast report of global and Chinese triglycine sulfate industry from 2022 to 2028
Daily calculation (vowel case conversion)
Report on operation mode and future development trend of global and Chinese propenyl isovalerate industry from 2022 to 2028
vim使用命令
走近Harvest Moon:Moonbeam DeFi狂欢会
UE4 WebBrowser图表不能显示问题
5年,从“点点点”到现在的测试开发,我的成功值得每一个借鉴。
canvas螺旋样式的动画js特效
Tremblement de terre réel ~ projet associé unicloud
Analysis report on the "fourteenth five year plan" and development trend of China's engineering project management industry from 2022 to 2028
Reservoir dam safety monitoring
wx小程序跳转页面
Outer screen and widescreen wasted? Harmonyos folding screen design specification teaches you to use it
Signal integrity (SI) power integrity (PI) learning notes (I) introduction to signal integrity analysis
微搭低代码中实现增删改查
I suddenly find that the request dependent package in NPM has been discarded. What should I do?
Andersen global strengthens the Middle East platform with Palestinian member companies