当前位置:网站首页>[don't bother to strengthen learning] video notes (II) 1. What is Q-learning?
[don't bother to strengthen learning] video notes (II) 1. What is Q-learning?
2022-07-24 09:16:00 【Your sister Xuan】
【 Don't bother with reinforcement learning videos 】 The notebook
The first 4 section What is? Q-Learning?
4.1 Q Learn about
Our code of action : Good behavior can get Reward , Bad behavior will gain punishment .
My name is Xiao Ming , I am a freshman of a University , The first day of class , You don't know that being distracted in class will fail , You sit in the first row , You have two choices : Listening and wandering , You choose to be distracted continuously , The teacher hung up for you . You have remembered this painful lesson , Continue to listen carefully when repairing ( Of course, this is an extreme case ).
There is currently a Q surface , As shown in the figure below : Q The table shows each state ( s 1 , s 2 , … … s_1,s_2,…… s1,s2,……), Corresponding to all actions ( a 1 , a 2 , … … a_1,a_2,…… a1,a2,……) Of “Q value ”,Q Value can indicate that the corresponding action is selected in the current state Return .
Q The table shows each state ( s 1 , s 2 , … … s_1,s_2,…… s1,s2,……), Corresponding to all actions ( a 1 , a 2 , … … a_1,a_2,…… a1,a2,……) Of “Q value ”,Q Value can indicate that the corresponding action is selected in the current state Return .
Q What is the function of the table ?
hypothesis Q The table already exists , We choose the initial state as s 1 s_1 s1( Go home from school ), The choice of action is Q In the table s 1 s_1 s1 States correspond to Q The most valuable action a 2 a_2 a2( homework ), Then automatically transfer to the state s 2 s_2 s2( Doing homework ), Again on the basis of Q Table select action a 2 a_2 a2( homework )…… In reciprocating .
4.2 Q Table update
 Or the above process , When we go through Q Table select action a 1 a_1 a1 after , arrive s 2 s_2 s2 state .
Or the above process , When we go through Q Table select action a 1 a_1 a1 after , arrive s 2 s_2 s2 state .
Above picture maxQ( s 2 s_2 s2) It is an estimate made before taking the second action , That is, the maximum possible current state Q value (Q( s 2 s_2 s2, a 2 a_2 a2)), Multiply the front by one γ \gamma γ, be called Attenuation factor , It expresses the influence of future values on the present , It will be mentioned in detail later . Add a... At the end R, Indicates the current state s 1 s_1 s1 Next, choose the action a 2 a_2 a2 Immediate rewards ( Suppose now R by 0, If you don't finish your homework, you won't be rewarded ), Get real Q( s 1 s_1 s1, a 2 a_2 a2) value .Q The original value in the table is the estimated value , disparity ( That is, the part that needs to be adjusted )= real Q value - original Q value .
Last updated Q value = The original Q value + α ∗ \alpha* α∗ disparity , among α \alpha α For learning rate ( Affect learning speed ).
4.3 Q Learning algorithms
 Q In fact, part of the actual value of is also used Q The values in the table are estimated , The update process is the process described above .
Q In fact, part of the actual value of is also used Q The values in the table are estimated , The update process is the process described above .
The first algorithm 5 That's ok , state s Choose action a when , It uses ϵ − g r e e d y \epsilon-greedy ϵ−greedy Method , such as ϵ \epsilon ϵ=0.9, There is 0.9 The probability of choosing is the greatest Q Value action , But there are 0.1 The probability of choosing any other action , The purpose is to add some randomness , Follow the principle of extensive sampling .
4.4 Attenuation factor γ \gamma γ
 As shown in the figure above ,Q( s 1 s_1 s1) Our estimate is not only s 2 s_2 s2, According to the same rules, it can continue to expand , You can find , Its and subsequent status s 3 、 s 4 … … s_3、s_4…… s3、s4…… Have a relationship , These can be used to estimate the actual Q value .
As shown in the figure above ,Q( s 1 s_1 s1) Our estimate is not only s 2 s_2 s2, According to the same rules, it can continue to expand , You can find , Its and subsequent status s 3 、 s 4 … … s_3、s_4…… s3、s4…… Have a relationship , These can be used to estimate the actual Q value .
When γ = 1 \gamma=1 γ=1 when , Equivalent to more consideration of future rewards , It's not ignored at all .
When γ ⊆ ( 0 , 1 ) \gamma\subseteq(0,1) γ⊆(0,1) when , The greater the numerical , The more attention you pay to the future , It can be said that the more intelligent agents “ vision ”.
When γ = 0 \gamma=0 γ=0 when , Completely regardless of the future , Only the current return value .
Last one :【 Don't bother to strengthen learning 】 Video notes ( One )3. Why use reinforcement learning ?
Next :【 Don't bother to strengthen learning 】 Video notes ( Two )2. Write a Q Small examples of learning
边栏推荐
- Data center: started in Alibaba and started in Daas
- JUC powerful auxiliary class
- Tiktok live broadcast with goods marketing play
- 分类与回归的区别
- The next stop of data visualization platform | gifts from domestic open source data visualization datart "super iron powder"
- S2b2b system standardizes the ordering and purchasing process and upgrades the supply chain system of household building materials industry
- Detailed explanation of the whole process of R & D demand splitting | agile practice
- C # briefly describe the application of Richter's replacement principle
- Re6:读论文 LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification fro
- How can tiktok transport videos not be streaming limited?
猜你喜欢

Data collection solution for forestry survey and patrol inspection

How to import CAD files into the map new earth and accurately stack them with the image terrain tilt model

Publish your own library on NPM
![[FFH] websocket practice of real-time chat room](/img/9a/ffd31fe8783804d40edeca515cc96c.png)
[FFH] websocket practice of real-time chat room

科目1-3

Run little turtle to test whether the ROS environment in the virtual machine is complete
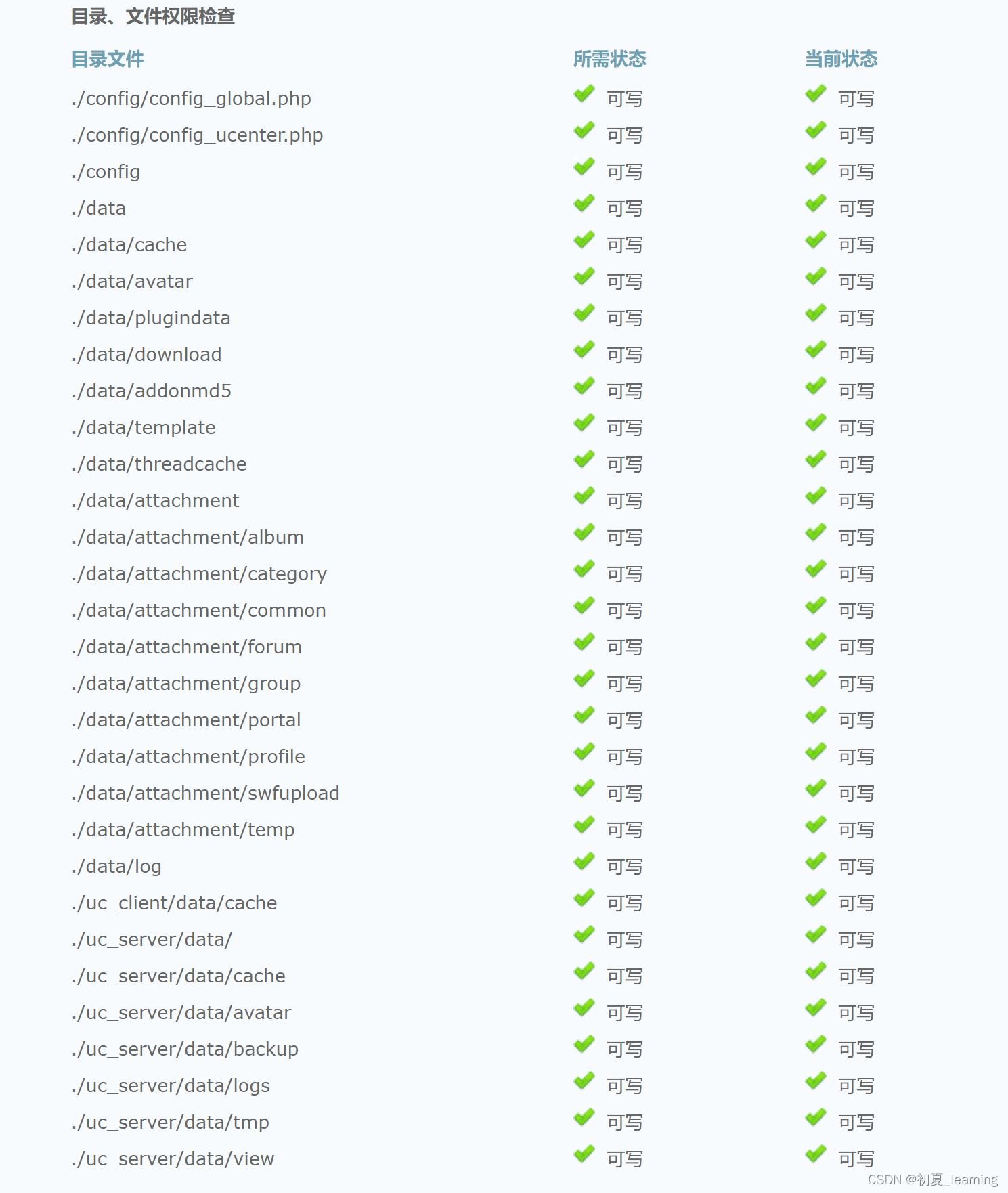
Discuz论坛搭建详细过程,一看就懂

The difference between & &, | and |

Assignment operator (geritilent software - Jiuye training)

Matlab各函数说明
随机推荐
[Luogu p3426] SZA template (string) (KMP)
Six pictures show you why TCP shakes three times?
Office fallback version, from 2021 to 2019
[FFH] openharmony gnawing paper growth plan -- Application of cjson in traditional c/s model
我们说的组件自定义事件到底是什么?
What is tiktok creator fund and how to withdraw it?
Assignment operator (geritilent software - Jiuye training)
Guys, what parameters can be set when printing flinksql so that the values can be printed? This later section is omitted. It's inconvenient. I read the configuration on the official website
Functions of tiktok enterprise number
来阿里一年后我迎来了第一次工作变动....
Why does TCP shake hands three times instead of two times (positive version)
How can tiktok transport videos not be streaming limited?
03_ UE4 advanced_ illumination
Virtual machine terminator terminal terminator installation tutorial
Getting started with sorting - insert sorting and Hill sorting
We were tossed all night by a Kong performance bug
Tiktok 16 popular categories, tiktok popular products to see which one you are suitable for?
LeetCode刷题系列-- 174. 地下城游戏
Advantages of using partitions
C language practice questions + Answers: