当前位置:网站首页>A review of text contrastive learning
A review of text contrastive learning
2022-06-24 14:08:00 【Echo in May】
I'm the directory
Abstract
Comparative learning (Contrastive Learning) The idea of the first came into being in CV field , The main idea is , Given a sample , Data enhancement , Consider the enhanced results as positive examples ; then , All other samples are regarded as negative examples . By drawing closer to the positive sample 、 Pull away the distance between negative samples , Comparative learning can be done without supervision ( Self supervision ) Learning more stable sample representation in context , And facilitate the migration of downstream tasks .
Classical methods of contrastive learning include Moco as well as SimCLR, Probably represents two different ideas of comparative learning .Moco It mainly maintains a global queue in memory (memory bank) To store the current representation of all samples , When one mini-batch When learning from a sample of , Just put the top layer corresponding to batch size Data out of the queue , The corresponding samples can be matched , And USES the Momentum Contrast Technology updates the samples in the queue .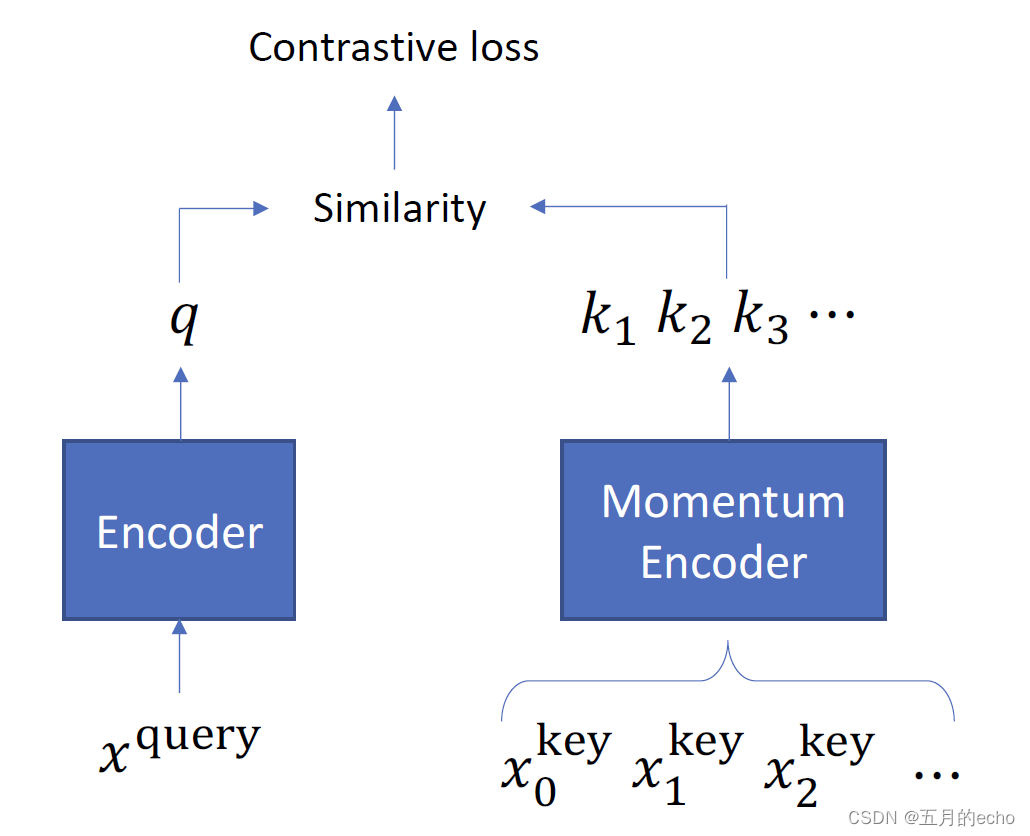
and SimCLR Is the same mini-batch All other samples in are considered as negative examples , Then compare . therefore , Even though SimCLR It's easy , But in order to improve the universality of the model to negative samples , Usually you need a very large one batch(4096 At this level ), So we ordinary people can't afford to play . The following contrastive learning in text representation is also based on these two branches , So let's warm up first ( detailed CV Overview of comparative learning Please move on to teacher Li Mo's video ).
However, contrastive learning in texts seems to have some limitations , Because compared to the flip of the picture 、 Translation and other enhancements , Text enhancement seems more laborious . therefore , narrow sense ( Inherit Moco or SimCLR such CV Comparative learning method ) There is not much work on text contrast learning . therefore , The purpose of this paper is to NLP The comparative study in gives a brief summary .
CERT,2020
Code:【https://github.com/UCSD-AI4H/CERT】
This article is one of the earlier articles on comparative study of language models that I have found , But now it seems to be hanging on arxiv On ( I don't understand ). This paper gives a comparative study in NLP A very clear advantage description in : The pre training language model focuses on token Level tasks , Therefore, there is no good learning about the representation of the corresponding sentence level . therefore , This paper adopts Moco In the framework of sentence level contrastive learning , The enhanced technology uses the most commonly used Back translation (back translation). The execution process is also well understood :
First , Pre training in the source domain , And on the target field text CSSL( Contrast self supervised learning ) The optimization of the , The result of this step is called CERT. after , Fine tune the target domain task with the label , Get the final tuned model .
CLEAR,2020

Again , This paper still focuses on sentence level tasks , But and CERT A little different is , Adopted SimCLR To perform contrastive learning , Different data augmentation strategies are discussed , Include :random-words-deletion, spans-deletion, synonym-substitution, and reordering. also , The process of the model is also slightly different ,CLEAR take MLM as well as CL Do joint training , Pre train the upstream language model , Then fine tune the downstream tasks . The main structure of the model is as follows :
s 1 ~ \tilde{s_1} s1~, s 2 ~ \tilde{s_2} s2~ Respectively represent two different augmented samples generated by the same augmented strategy for the same sample , Then they were fed to the same one BERT, And get two different representations . So for a batch size by N N N The input of , Finally, there is 2 N 2N 2N Samples . after , g ( ) g() g() Is a complete reference SimCLR 了 , because SimCLR Add an... To the original text a nonlinear projection head Can improve performance ( No reason , Is that the experimental results will improve ), Therefore, this article also follows the example of , The corresponding projection is added after the output . The loss function is commonly used in comparative learning :
CL The overall comparative learning loss is defined as the sum of all the positive losses in a small batch :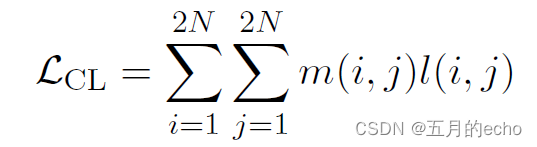
The optimization goal of the final language model is :
The specific experimental details and results will not be discussed .
DeCLUTR,2021 ACL
Code:【https://github.com/JohnGiorgi/DeCLUTR】
The follow-up work is to adopt SimCLR The framework of , The main difference lies in the way of sampling .DeCLUTR Is based on beta Distribute sampling a clause with an indefinite length , Then use this clause as an example after enhancement :
alike , The overall loss is the comparative loss and MLM The sum of the losses :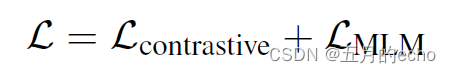
ConSERT:ACL 2021
Code:【https://github.com/yym6472/ConSERT】
On the whole , It is not much different from the previous and follow-up work , Based on BERT The framework of comparative learning is as follows :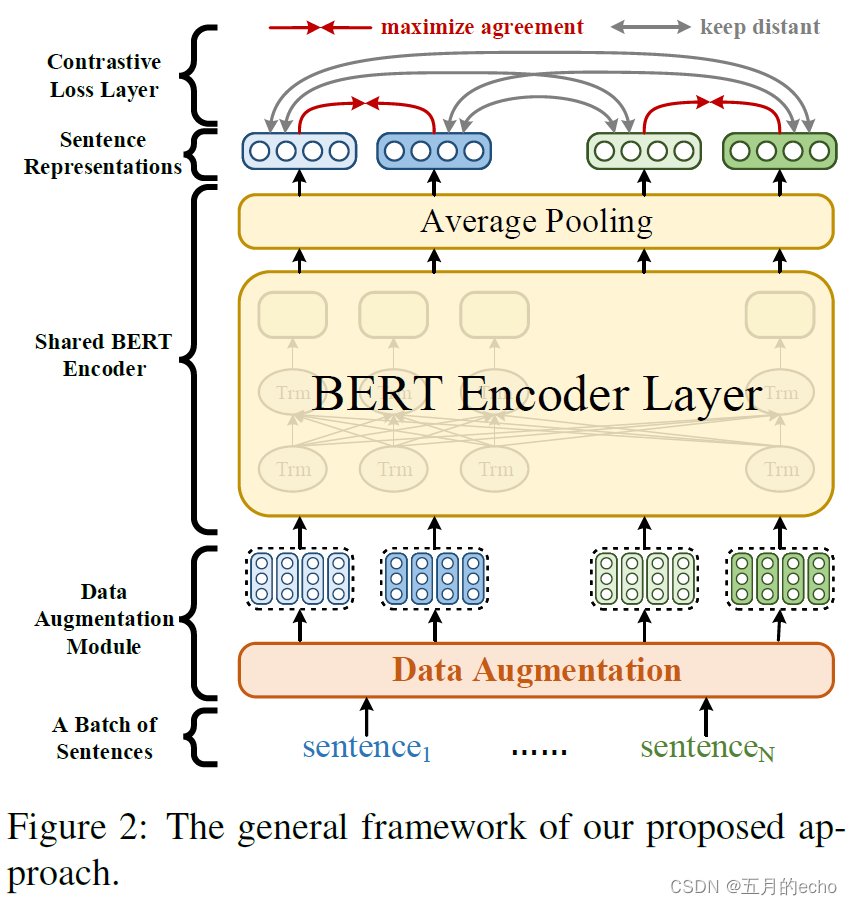
This article explores four different data enhancement methods :
- Adversarial Attack. Use fast gradient values (FGV) To implement this strategy , It uses gradients directly to calculate perturbations .
- Token Shuffling. By changing the position id To the embedded layer , Keep the token id In the same order .
- Cutoff. By randomly deleting some tokens or feature To achieve .
- Dropout. At a certain probability tokens Randomly delete elements from the embedded layer of , And set their values to zero .
This paper also explores the combined effects of the above different augmentation strategies :
Self-Guided Contrastive Learning for BERT Sentence Representations, ACL 2021

This article takes a very interesting enhancement strategy , Guarantee BERT Different layer The consistency of the learned representations . Because the author thinks , Data enhancement inevitably produces noise , Therefore, it is difficult to ensure the semantic consistency between the enhanced results and the original samples . The framework of the model is as follows :
First , about BERT, Produce two copies, One is a fixed parameter , go by the name of B E R T F BERT_F BERTF; The other is fine-tuning according to downstream tasks , go by the name of B E R T T BERT_T BERTT. second , Also give a mini-batch Medium b b b A sentence , utilize B E R T F BERT_F BERTF Calculation token-level It means H i , k ∈ R l e n ( s i ) × d H_{i,k}\in \mathcal{R}^{len(s_i)×d} Hi,k∈Rlen(si)×d as follows :
after , Sentence level representation h i , k h_{i,k} hi,k Use a simple maximum pool to get . among , k ∈ [ 1 , l ] k\in [1,l] k∈[1,l], l l l by BERT The number of layers . then , Apply a layer level sampling function σ \sigma σ, Get the final representation of the positive example :
Third , after B E R T T BERT_T BERTT The representation of the obtained sentence c i c_i ci as follows :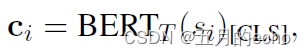
such , A collection of enhanced samples X X X Has been determined :
Then there is the commonly used comparison loss NT-Xent loss: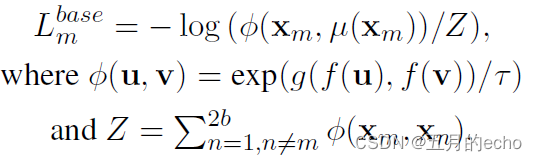
The meaning of specific symbols will not be explained , Is to draw closer to the positive sample , Pull away the distance between negative samples , Well understood. :
then , In theory , Even though B E R T T BERT_T BERTT The fine-tuning , But we still need to try our best to ensure and B E R T F BERT_F BERTF The distance is not very far , So a regularization is added :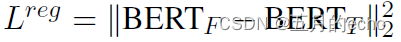
The final loss is the joint loss function :
SimCSE:EMNLP2021
Code:【https://github.com/princeton-nlp/SimCSE】
The method presented in this paper is quite elegant , Introduced dropout Methods to enhance the sample . Pass the same sentence to the pre trained encoder twice : By applying the standard twice dropout, You can get two different embeddeds as the positive . then , In unsupervised and supervised (natural language inference,NLI) The corresponding performance is explored in two different types of enhancement tasks .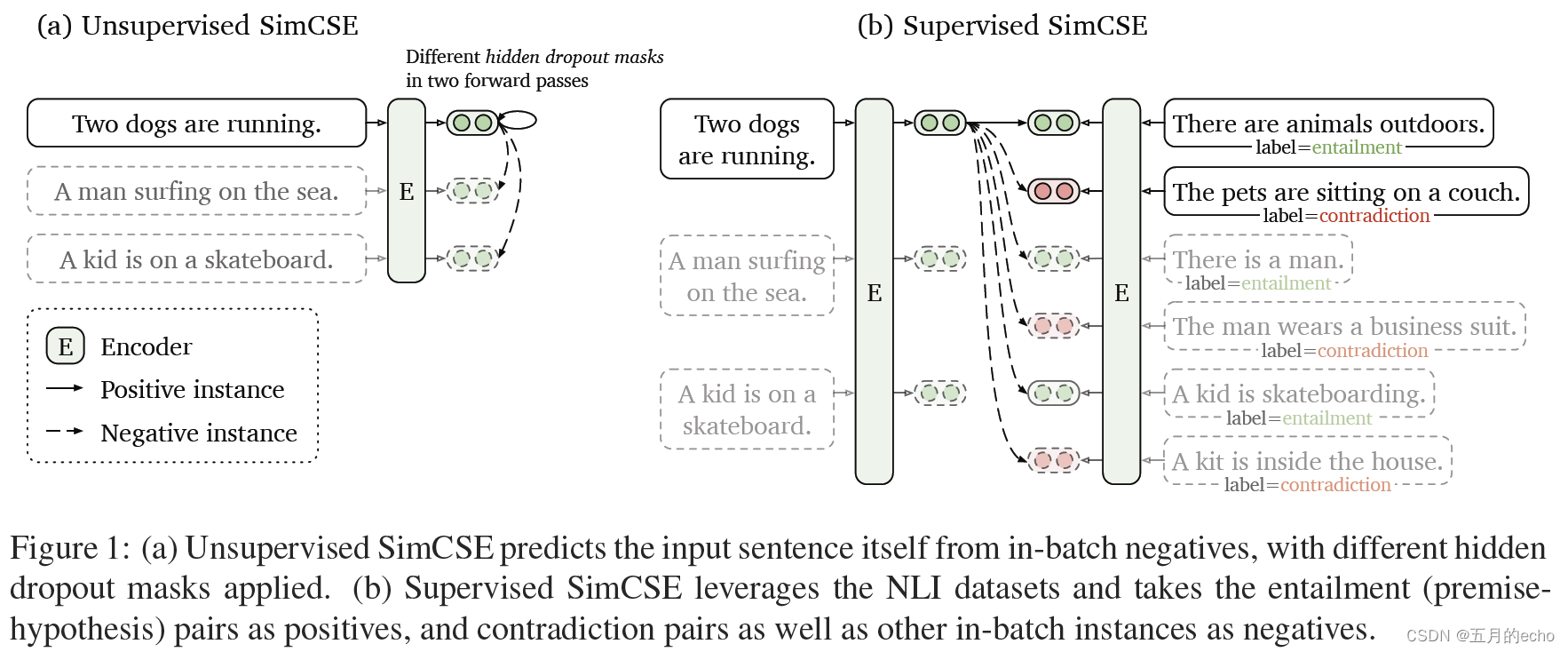
here NLI The reason is that there is supervision , Mainly because NLI Itself is a task of matching text pairs , So it is a comparison of a pair of texts , Matching is a positive example , A mismatch is a negative example . What this article puts forward dropout Method is better than some common enhancement methods , For example, cutting 、 Delete 、 Synonym substitution works better :
Pairwise Supervised Contrastive Learning of Sentence Representations,EMNLP 2021
ESimCSE, arxiv2021
SimCSE Each of the orthographies in actually contains the same length information , After all, it is through an input dropout And here comes . therefore , Use these for training unsup-SimCSE There may be bias , It tends to think that sentences of the same or similar length are more semantically similar . Through statistical observation , This paper finds that there is such a problem . To alleviate this problem , We simply repeat the input sentences , Modify the input sentence , Then pass the revised sentences to the trained..., respectively Transformer Encoder , The training process after that is almost the same .
ESimCSE Execute on the batch Word repetition operation , Therefore, the length of the alignment can be changed without changing the sentence semantics . When the predictions are right , This mechanism weakens the same length hint of the model . Besides ,ESimCSE There's also a so-called momentum contrast (momentum contrast) Several previous small batch model outputs are maintained in the queue of , This can enlarge the negative pair involved in the loss calculation ( What is modeled here is MOCO). This mechanism allows pairs to be more fully compared in comparative learning .
DiffCSE,NAACL2021

Code:【https://github.com/voidism/DiffCSE】
The work of this paper is based on SimCSE On the basis of , Added one difference prediction Additional forecast targets for :
difference prediction It is mainly used to distinguish a person who is maks In the sentence of token Whether it was mask Yes . First , Given length is T T T The input of x x x, Using random mask Get to include [MASK] Version of x ′ x' x′, Then use another pretrained Of MLM As Generator, Right quilt mask Of token To restore , The sentence at this time is expressed as x ′ ′ x'' x′′. after , With the help of D D D To judge a token Is it replaced :
Actually , The work is essentially right token A reasonable combination of sentence level pre training task and sentence level pre training task .
PromptBERT,arxiv2022
边栏推荐
猜你喜欢

![Jerry's infrared filtering [chapter]](/img/6b/7c4b52d39a4c90f969674a5c21b2c7.png)
![二叉树中最大路径和[处理好任意一颗子树,就处理好了整个树]](/img/d0/91ab1cc1851d7137a1cab3cf458302.png)





随机推荐
2022年煤炭生产经营单位(安全生产管理人员)考试题模拟考试平台操作
SAP Marketing Cloud 功能概述(四)
数学之英文写作——基本中英文词汇(几何与三角的常用词汇)
Grendao usage problems
Mit-6.824-lab4a-2022 (ten thousand words explanation - code construction)
Kotlin coordination channel
js去除字符串空格
Prometheus pushgateway
杰理之增加一个输入捕捉通道【篇】
杰理之可能出现有些芯片音乐播放速度快【篇】
Ti Xing Shu'an joined the dragon lizard community to jointly create a network security ecosystem
Jerry's test mic energy automatic recording automatic playback reference [article]
Google waymo proposed r4d: remote distance estimation using reference target
2022 recurrent training question bank and answers for hoisting signal Rigger (special type of construction work)
HarmonyOS. two
MIT-6.824-lab4A-2022(万字讲解-代码构建)
从谭浩强《C程序设计》上摘录的ASCII码表(常用字符与ASCII代码对照表)
2022 Quality Officer - Equipment direction - post skills (Quality Officer) recurrent training question bank and online simulation examination
位于相同的分布式端口组但不同主机上的虚拟机无法互相通信
Dragon lizard developer said: first time you got an electric shock, so you are such a dragon lizard community| Issue 8