当前位置:网站首页>Mit-6.824-lab4a-2022 (ten thousand words explanation - code construction)
Mit-6.824-lab4a-2022 (ten thousand words explanation - code construction)
2022-06-24 13:59:00 【Xingping XP】
List of articles
Preface
Although the difficulty of the experiment is easy, But the feeling only stays in test, It is still difficult to understand or implement the code .
One 、 Experimental background
This experiment does not need to be studied like previous experiments paper And so on , But just by introduction It is still a little difficult to understand .
- this lab4A Also mentioned in the introduction , He and lab3 In fact, it is similar . A similar reason is if lab3 It's using raft Consensus to achieve a put/get Simple access to database , that lab4A In fact, it is to change a more real business scenario , utilize raft Unified configuration . Also is to put/get Operation between , Switch to query/leave/join/move Wait for the operation .
- The overall architecture diagram :
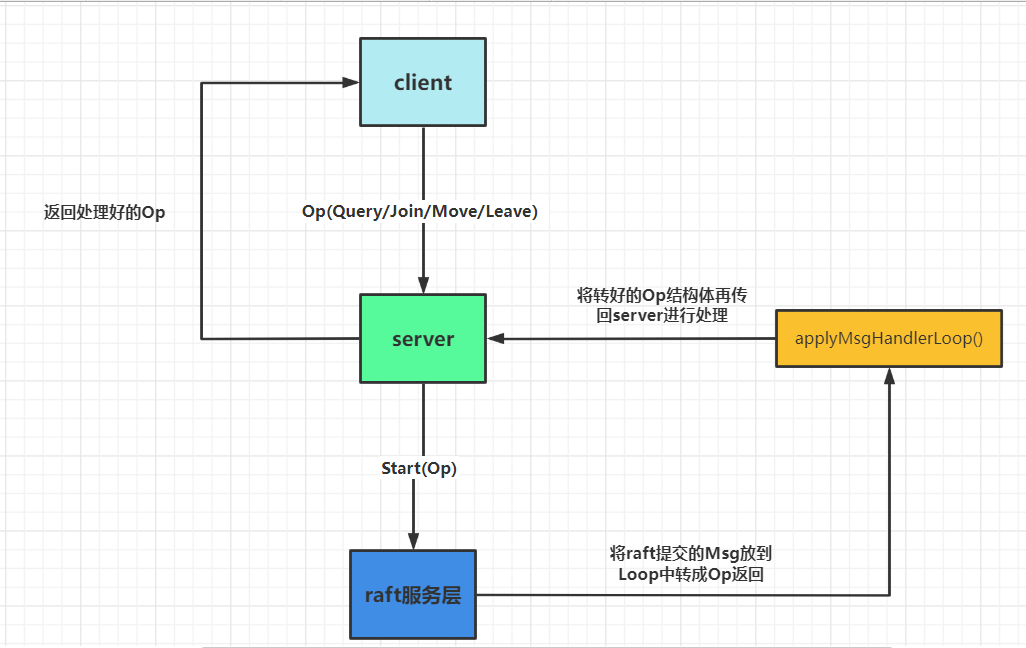
It is worth mentioning that there is no Implement snapshot , Because in lab3B Snapshot is implemented in because start When I passed in a maxSize, Beyond this size Snapshot is required , and lab4A There is no mention of , In fact, it is easy to understand here . - Next, I will focus on lab4A What is the configuration of .
First you will find that in server There is a config section :
configs []Config // indexed by config num
It actually stores the configuration information of a series of versions , The latest subscript corresponds to the latest configuration .
Then click on it to have a look config Construction :
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
You can see that there are three members :
Configuration number of a corresponding version , The group information corresponding to the partition ( The slices in the experiment are 10 individual ), List of server mapping names corresponding to each group ( That is, group information ).
From this we can actually sum up the following relationship :
A slice is processed by a group , One-to-one relationship . A group can be used to process multiple slices , So join the group as long as it does not exceed the number of slices , The added group can improve the performance of the system . That is, what was mentioned in the introduction :
thus total system throughput (puts and gets per unit time) increases in proportion to the number of groups.
Two 、RPC
2.1、RPC General overview
What to do with each operation, including how to implement it, is also described in the introduction :
- The Join RPC is used by an administrator to add new replica groups. Its argument is a set of mappings from unique, non-zero replica group identifiers (GIDs) to lists of server names.
- The Leave RPC’s argument is a list of GIDs of previously joined groups. The shardctrler should create a new configuration that does not include those groups, and that assigns those groups’ shards to the remaining groups. The new configuration should divide the shards as evenly as possible among the groups, and should move as few shards as possible to achieve that goal.
- The Move RPC’s arguments are a shard number and a GID. The shardctrler should create a new configuration in which the shard is assigned to the group. The purpose of Move is to allow us to test your software. A Join or Leave following a Move will likely un-do the Move, since Join and Leave re-balance.
- The Query RPC’s argument is a configuration number. The shardctrler replies with the configuration that has that number. If the number is -1 or bigger than the biggest known configuration number, the shardctrler should reply with the latest configuration. The result of Query(-1) should reflect every Join, Leave, or Move RPC that the shardctrler finished handling before it received the Query(-1) RPC.
Here is a simple translation explanation :
- Join : Join a new group , Create a new configuration , After adding a new group, you need to redo Load balancing .
- Leave: Evacuate a given group , And carry on Load balancing .
- Move: For the specified slice , Assign the specified group .
- Query: Query a specific configuration version , If the given version number does not exist in the slice subscript , Directly return to the latest configuration version .
Therefore, we can see four operations , These four operations can be simply regarded as adding, deleting, modifying and querying the configuration . But here we can see that load balancing is still needed , Therefore, the relationship between the above groups and slices can be seen as the following figure :
2.2、RPC Realization
Therefore, I understand well 4 individual RPC What does it do or is it easy to implement ( According to lab3 Just realize ):
//The Join RPC is used by an administrator to add new replica groups. Its argument is a set of mappings from unique,
//non-zero replica group identifiers (GIDs) to lists of server names.
// Join The parameter is a group , A group corresponds to gid -> lists of server names.
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// encapsulation Op To the lower level start
op := Op{
OpType: JoinType, SeqId: args.SeqId, ClientId: args.ClientId, JoinServers: args.Servers}
//fmt.Printf("[ ----Server[%v]----] : send a Join,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// Set timeout ticker
timer := time.NewTicker(JoinOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a JoinAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// encapsulation Op To the lower level start
op := Op{
OpType: LeaveType, SeqId: args.SeqId, ClientId: args.ClientId, LeaveGids: args.GIDs}
//fmt.Printf("[ ----Server[%v]----] : send a Leave,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// Set timeout ticker
timer := time.NewTicker(LeaveOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a GetAsk :%+v,replyOp:+%v\n", kv.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// encapsulation Op To the lower level start
op := Op{
OpType: MoveType, SeqId: args.SeqId, ClientId: args.ClientId, MoveShard: args.Shard, MoveGid: args.GID}
//fmt.Printf("[ ----Server[%v]----] : send a MoveOp,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// Set timeout ticker
timer := time.NewTicker(MoveOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a GetAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
return
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
// Query Configuration of corresponding configuration number
// The shardctrler replies with the configuration that has that number. If the number is -1 or bigger than the biggest
// known configuration number, the shardctrler should reply with the latest configuration. The result of Query(-1) should
// reflect every Join, Leave, or Move RPC that the shardctrler finished handling before it received the Query(-1) RPC.
func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) {
// Your code here.
_, ifLeader := sc.rf.GetState()
if !ifLeader {
reply.Err = ErrWrongLeader
return
}
// encapsulation Op To the lower level start
op := Op{
OpType: QueryType, SeqId: args.SeqId, ClientId: args.ClientId, QueryNum: args.Num}
//fmt.Printf("[ ----Server[%v]----] : send a Query,op is :%+v \n", sc.me, op)
lastIndex, _, _ := sc.rf.Start(op)
ch := sc.getWaitCh(lastIndex)
defer func() {
sc.mu.Lock()
delete(sc.waitChMap, lastIndex)
sc.mu.Unlock()
}()
// Set timeout ticker
timer := time.NewTicker(QueryOverTime * time.Millisecond)
defer timer.Stop()
select {
case replyOp := <-ch:
//fmt.Printf("[ ----Server[%v]----] : receive a QueryAsk :%+v,replyOp:+%v\n", sc.me, args, replyOp)
if op.ClientId != replyOp.ClientId || op.SeqId != replyOp.SeqId {
reply.Err = ErrWrongLeader
} else {
reply.Err = OK
sc.seqMap[op.ClientId] = op.SeqId
if op.QueryNum == -1 || op.QueryNum >= len(sc.configs) {
reply.Config = sc.configs[len(sc.configs)-1]
} else {
reply.Config = sc.configs[op.QueryNum]
}
}
case <-timer.C:
reply.Err = ErrWrongLeader
}
}
3、 ... and 、Loop And Handler
about loop In fact, it is also related to lab3 Be the same in essentials while differing in minor points :
func (sc *ShardCtrler) applyMsgHandlerLoop() {
for {
select {
case msg := <-sc.applyCh:
//fmt.Printf("[----Loop-Receive----] Msg: %+v\n ", msg)
// Walk normally Command
if msg.CommandValid {
index := msg.CommandIndex
op := msg.Command.(Op)
//fmt.Printf("[ ~~~~applyMsgHandlerLoop~~~~ ]: %+v\n", msg)
// Determine whether the request is repeated
if !sc.ifDuplicate(op.ClientId, op.SeqId) {
sc.mu.Lock()
switch op.OpType {
case JoinType:
//fmt.Printf("[++++Receive-JoinType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.JoinHandler(op.JoinServers))
case LeaveType:
//fmt.Printf("[++++Receive-LeaveType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.LeaveHandler(op.LeaveGids))
case MoveType:
//fmt.Printf("[++++Receive-MoveType++++] : op: %+v\n", op)
sc.seqMap[op.ClientId] = op.SeqId
sc.configs = append(sc.configs, *sc.MoveHandler(op.MoveGid, op.MoveShard))
}
sc.seqMap[op.ClientId] = op.SeqId
sc.mu.Unlock()
}
// Will return ch return waitCh
sc.getWaitCh(index) <- op
}
}
}
}
And the processing of various information are also mentioned in the introduction :
// JoinHandler Handle Join Come in gid
// The shardctrler should react by creating a new configuration that includes the new replica groups. The new
//configuration should divide the shards as evenly as possible among the full set of groups, and should move as few
//shards as possible to achieve that goal. The shardctrler should allow re-use of a GID if it's not part of the
//current configuration (i.e. a GID should be allowed to Join, then Leave, then Join again).
func (sc *ShardCtrler) JoinHandler(servers map[int][]string) *Config {
// Take out the last one config Add groups
lastConfig := sc.configs[len(sc.configs)-1]
newGroups := make(map[int][]string)
for gid, serverList := range lastConfig.Groups {
newGroups[gid] = serverList
}
for gid, serverLists := range servers {
newGroups[gid] = serverLists
}
// GroupMap: groupId -> shards
// Record how many slices each group has (group -> shards One to many , Therefore, load balancing is required , A partition can only correspond to one group )
GroupMap := make(map[int]int)
for gid := range newGroups {
GroupMap[gid] = 0
}
// Record how many slices are stored in each packet
for _, gid := range lastConfig.Shards {
if gid != 0 {
GroupMap[gid]++
}
}
// There is no need for load balancing , Initialization phase
if len(GroupMap) == 0 {
return &Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: newGroups,
}
}
// Load balancing is required
return &Config{
Num: len(sc.configs),
Shards: sc.loadBalance(GroupMap, lastConfig.Shards),
Groups: newGroups,
}
}
// LeaveHandler Handle groups that need to leave
// The shardctrler should create a new configuration that does not include those groups, and that assigns those groups'
// shards to the remaining groups. The new configuration should divide the shards as evenly as possible among the groups,
// and should move as few shards as possible to achieve that goal.
func (sc *ShardCtrler) LeaveHandler(gids []int) *Config {
// use set It feels better, but go There's no built-in set..
leaveMap := make(map[int]bool)
for _, gid := range gids {
leaveMap[gid] = true
}
lastConfig := sc.configs[len(sc.configs)-1]
newGroups := make(map[int][]string)
// Take out the latest configuration groups Group to populate
for gid, serverList := range lastConfig.Groups {
newGroups[gid] = serverList
}
// Delete corresponding gid Value
for _, leaveGid := range gids {
delete(newGroups, leaveGid)
}
// GroupMap: groupId -> shards
// Record how many slices each group has (group -> shards One to many , Therefore, load balancing is required , A partition can only correspond to one group )
GroupMap := make(map[int]int)
newShard := lastConfig.Shards
// Yes groupMap To initialize
for gid := range newGroups {
if !leaveMap[gid] {
GroupMap[gid] = 0
}
}
for shard, gid := range lastConfig.Shards {
if gid != 0 {
// If this group is leaveMap in , Is set to 0
if leaveMap[gid] {
newShard[shard] = 0
} else {
GroupMap[gid]++
}
}
}
// Delete it directly
if len(GroupMap) == 0 {
return &Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: newGroups,
}
}
return &Config{
Num: len(sc.configs),
Shards: sc.loadBalance(GroupMap, newShard),
Groups: newGroups,
}
}
// MoveHandler Assign the specified group to the specified partition
// The shardctrler should create a new configuration in which the shard is assigned to the group. The purpose of Move is
// to allow us to test your software. A Join or Leave following a Move will likely un-do the Move, since Join and Leave
// re-balance.
func (sc *ShardCtrler) MoveHandler(gid int, shard int) *Config {
lastConfig := sc.configs[len(sc.configs)-1]
newConfig := Config{
Num: len(sc.configs),
Shards: [10]int{
},
Groups: map[int][]string{
}}
// Fill and assign
for shards, gids := range lastConfig.Shards {
newConfig.Shards[shards] = gids
}
newConfig.Shards[shard] = gid
for gids, servers := range lastConfig.Groups {
newConfig.Groups[gids] = servers
}
return &newConfig
}
Four 、 Load balancing
In fact, the above ones are the same as those written before , about Lab4A In fact, load balancing is one of the difficulties . Why do we need to implement loadBalance?
This may happen if load balancing is not implemented :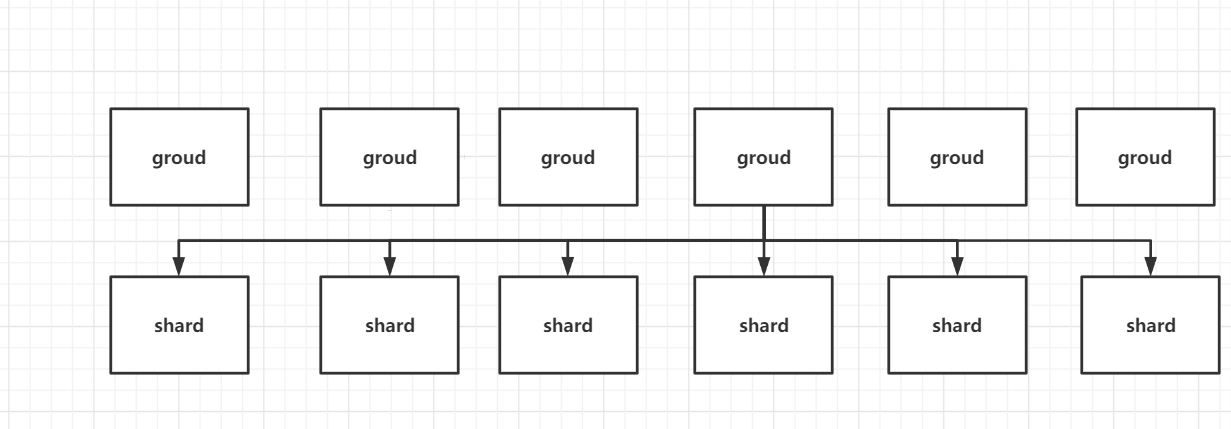
So this is the extreme case , Yes 6 Groups handle 6 A shard , however 6 Pieces are processed by one group , The pressure that causes this group will be particularly high . After load balancing, the group allocation partition should be like this :
Therefore, load balancing is required when joining or leaving a group . The load balancing process should be :
- First, sort according to the load , Remember that if you have the same load , Need to be right gid Also sort , Generate Unique sequence , Otherwise there will be consistency problems (TestMulti), The main reasons for sorting are as follows :
- Fewer exchanges can be made by sorting , Of course, make sure that there is no Move And other operations affect the load .
- It is not possible to share the ideal load , Such as 10 Divide into pieces 4 A group cannot be {2.5,2.5,2.5,2.5}. It should be
{3,3,2,2}. In this case, we can pass the expected number according to the sorted sequence , Determine which groups need to load more than one partition . - The unique sequence after sorting needs to be mapped to the load partition map( See the overall load code for details ).
// according to sortGroupShard Sort
// GroupMap : groupId -> shard nums
func sortGroupShard(GroupMap map[int]int) []int {
length := len(GroupMap)
gidSlice := make([]int, 0, length)
// map Convert into ordered slice
for gid, _ := range GroupMap {
gidSlice = append(gidSlice, gid)
}
// Let the high load pressure row in front
// except: 4->3 / 5->2 / 6->1 / 7-> 1 (gids -> shard nums)
for i := 0; i < length-1; i++ {
for j := length - 1; j > i; j-- {
if GroupMap[gidSlice[j]] < GroupMap[gidSlice[j-1]] {
gidSlice[j], gidSlice[j-1] = gidSlice[j-1], gidSlice[j]
}
}
}
return gidSlice
}
Then cycle through each round to find the overloaded , And more free , Just complement each other .
Suppose there are now 10 A shard , Assigned to 4 A set of , And the current load is {3,3,3,1}, Is the first 3 individual 3 Should be 2, Because it is not the group that needs to be allocated more than one group overload . and Free The is 1, After the exchange, it is for {3,3,2,2}.
// Load balancing
// GroupMap : gid -> servers[]
// lastShards : shard -> gid
func (sc *ShardCtrler) loadBalance(GroupMap map[int]int, lastShards [NShards]int) [NShards]int {
length := len(GroupMap)
ave := NShards / length
remainder := NShards % length
sortGids := sortGroupShard(GroupMap)
// First put the part with more load free
for i := 0; i < length; i++ {
target := ave
// Determine whether this number needs more allocations , Because it is impossible to divide them equally , At the forefront should be ave+1
if !moreAllocations(length, remainder, i) {
target = ave + 1
}
// Overload
if GroupMap[sortGids[i]] > target {
overLoadGid := sortGids[i]
changeNum := GroupMap[overLoadGid] - target
for shard, gid := range lastShards {
if changeNum <= 0 {
break
}
if gid == overLoadGid {
lastShards[shard] = InvalidGid
changeNum--
}
}
GroupMap[overLoadGid] = target
}
}
// For less loaded group Allocate the extra group
for i := 0; i < length; i++ {
target := ave
if !moreAllocations(length, remainder, i) {
target = ave + 1
}
if GroupMap[sortGids[i]] < target {
freeGid := sortGids[i]
changeNum := target - GroupMap[freeGid]
for shard, gid := range lastShards {
if changeNum <= 0 {
break
}
if gid == InvalidGid {
lastShards[shard] = freeGid
changeNum--
}
}
GroupMap[freeGid] = target
}
}
return lastShards
}
func moreAllocations(length int, remainder int, i int) bool {
// The purpose is to judge index Are you arranging ave+1 The forefront of the :3、3、3、1 ,ave: 10/4 = 2.5 = 2, After load balancing, it should be 2+1,2+1,2,2
if i < length-remainder {
return true
} else {
return false
}
}
- Although I now explain this code, the reader may think it is relatively simple , But in fact, it is still a little difficult to fully realize the process of load balancing . The load balancing method is far more than just me , The author's way is First add in, then sort, and finally swap . The time complexity should depend on the sorting complexity , Of course, the author here uses a simple bubble , The time complexity is n², If you use a quick row 、 Merge and so on can be optimized to n*logn.
- There is also a faster way , That is to change the entire code structure , Realize a The data structure of a large top heap or a small top heap . So in join perhaps leave Will be sorted automatically , The insertion complexity is logn. But every time you need to rebuild the heap , Because heap has no Traverse this statement , So it's actually quite complicated , Another reason is go In fact, there is no built-in The data structure of the heap .
5、 ... and 、 summary
In the twinkling of an eye lab4 了 , For this experiment, it is easy to understand and pass the implementation .
gitee:2022-6.824, If the follow-up lab Implement current lab, Please refer to master Branch .
边栏推荐
- Getting to know cloud native security for the first time: the best guarantee in the cloud Era
- 位于相同的分布式端口组但不同主机上的虚拟机无法互相通信
- Eight major trends in the industrial Internet of things (iiot)
- kotlin 异步流
- [5g NR] 5g NR system architecture
- HarmonyOS-3
- Can a team do both projects and products?
- Dragon lizard developer said: first time you got an electric shock, so you are such a dragon lizard community| Issue 8
- 4个不可不知的“安全左移”的理由
- 杰理之红外滤波【篇】
猜你喜欢

HarmonyOS.2

国内首款开源MySQL HTAP数据库即将发布,三大看点提前告知

Tupu software is the digital twin of offshore wind power, striving to be the first

万用表的使用方法
![[R language data science] (XIV): random variables and basic statistics](/img/87/3606041a588ecc615eb8013cdf9fb1.png)
[R language data science] (XIV): random variables and basic statistics

华为 PC 逆势增长,产品力决定一切

How to manage tasks in the low code platform of the Internet of things?

Activity生命周期

《中国数据库安全能力市场洞察,2022》报告研究正式启动

How to avoid serious network security accidents?
随机推荐
2022 coal mine gas drainage operation certificate examination questions and simulation examination
Kotlin keyword extension function
杰理之可能出现有些芯片音乐播放速度快【篇】
Kotlin initialization block
Jerry added an input capture channel [chapter]
90%的项目经理都跳过的坑,你现在还在坑里吗?
项目经理的晋级之路
Jerry's seamless looping [chapter]
Ti Xing Shu'an joined the dragon lizard community to jointly create a network security ecosystem
The hidden corner of codefarming: five things that developers hate most
远程办公之:在家露营办公小工具| 社区征文
Autorf: learn the radiation field of 3D objects from single view (CVPR 2022)
Kotlin anonymous function and lambda
Operation of simulated examination platform of examination question bank for B certificate of Jiangxi provincial safety officer in 2022
PM也要学会每天反省
Source code analysis handler interview classic
The real project managers are all closed-loop masters!
【深度学习】NCHW、NHWC和CHWN格式数据的存储形式
Jerry has opened a variety of decoding formats, and the waiting time from card insertion to playback is long [chapter]
Eight major trends in the industrial Internet of things (iiot)