当前位置:网站首页>Interpretation of the paper: develop a prediction model based on multi-layer deep learning to identify DNA N4 methylcytosine modification
Interpretation of the paper: develop a prediction model based on multi-layer deep learning to identify DNA N4 methylcytosine modification
2022-07-23 12:22:00 【Windy Street】
Developing a Multi-Layer Deep Learning Based Predictive Model to Identify DNA N4-Methylcytosine Modifications
Article address :https://www.frontiersin.org/articles/10.3389/fbioe.2020.00274/full
DOI:https://doi.org/10.3389/fbioe.2020.00274
Periodical :Frontiers in Bioengineering and Biotechnology(2 District )
Influencing factors :5.89
Release time :2020 year 4 month 21 Japan
data :http://server.malab.cn/Deep4mcPred/Download.html
The server :http://server.malab.cn/Deep4mcPred
1. The article summarizes
1. A prediction model based on multi-layer deep learning is proposed :Deep4mcPred. Integrate residual network for the first time (Residual Network) And recurrent neural networks (Recurrent Neural Network) To build a multi-layer deep learning prediction system .
2. The deep learning model does not need specific features when training the prediction model , It can automatically learn advanced features and capture 4mC Site specificity , Conducive to differentiation 4mC site .
3. Deep learning methods are common Compared with the prediction results of traditional machine learning, the benchmark test set is better , indicate Deep4mcPred stay DNA 4mC More effective in site prediction .
4. The attention mechanism introduced into the in-depth learning framework can be used to capture key features .
5. Developed a web server :http://server.malab.cn/deep4mcpred.
2. Preface
With the development of high flux technology , Found in bacteria 4mC, Found in protecting the genome from restrictive modification (R-M) It plays an important role in the invasion of the system .
Previous methods have improved recognition 4mC Site performance , But too few datasets are used , It cannot fully reflect the whole genome and establish a good performance model .
3. data
Chen And others put forward a Golden Benchmark data set , For performance evaluation and comparison . however , The size of the dataset is too small to train in-depth learning models . therefore , The author constructed a larger data set in this study , They strictly follow Chen The data processing program introduced in learning , The purpose is to ensure that the processed data set is the most representative .
(1) Positive samples
Treatment process :
- Collected all 41bp Long sequence of , from methsmrt The database has real 4mC site .
- Deleted the use ModQV The sequence of scores , Instead of calling the default threshold for modifying the location according to the methyl group analysis technical description .
- Used CD-BIT Software ( have 80% The threshold of ) Reduce masculine identity , The potential to avoid performance bias .
Positive samples were collected from three species : Arabidopsis (A. Thilana), Caenorhabditis elegans (C. elegans) And Drosophila melanogaster (D. Melanogaster). Details of positive samples from the three species are listed in table 1. Randomly selected 20,000 A positive sample of model training .
(2) Negative samples
Negative samples are also cytosine centered 41bp Sequence , But not by SMRT Sequencing technology identifies . under these circumstances , The number of negative samples of each species is much larger than the corresponding positive samples . To avoid data imbalance , Randomly select the same number of sequences as the positive samples to form the negative samples .
4. Method
4.1 Sequence characteristics
One-hot code :
“A”:(1,0,0,0)
“G”:(0,1,0,0)
“C”:(0,0,1,0)
“T”:(0,0,0,1)
“N”:(0,0,0,0)
4.2 Deep learning model framework

For a given DNA Sequence , The neural network is composed of four layers : Input layer ,ResNet layer ,LSTM Layer and attention layer , Pictured 1 Shown . The first layer is the input layer . The sequence of the data set consists of One-hot code , And the obtained features are sent to the subsequent ResNet Layer . Through this kind of ResNet Model , It can be based on ordinary CNN Models to build deeper Networks , Used to extract effective global functions , The output eigenvector is used as LSTM Layer of the input . stay LSTM Layer , two-way LSTM The model is used to collect feature information from two directions . In the last layer of attention , Introduce attention mechanisms to integrate LSTM Layer output to get more relevant feature information . Last , Attach a fully connected neural network after the attention model (FC), And perform Softmax Activate the function for prediction .
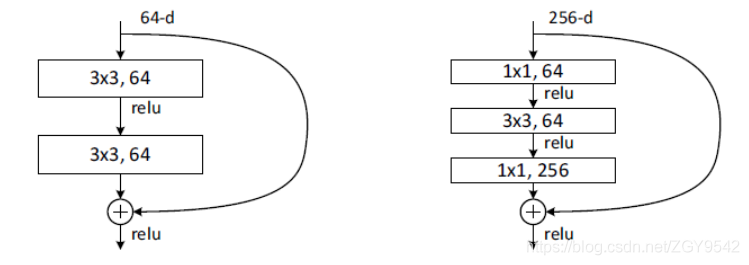
4.2.1 Residual neural network (ResNet)
With the deepening of convolutional neural network , The worse the optimization effect , The accuracy of test data and training data is reduced . This is because the deepening of the network will cause the problem of gradient explosion and gradient disappearance .
At present, there are solutions to this phenomenon : Normalize the input data and the data of the middle layer , This method can ensure that the network adopts random gradient descent in back propagation (SGD), So as to make the network converge . however , This method is only useful for dozens of layers of networks , When the network goes deeper , This method is useless .
To solve this problem ,ResNet There is ,Reset The internal residual blocks of utilize jump connection , Reduce the gradient disappearance problem caused by depth increase in convolutional neural network .
ResNet There are two kinds of , A two-layer structure , A three-layer structure :
4.2.2 Long and short term memory network (LSTM)
Due to gradient explosion or gradient disappearance ,RNN There's a long-term dependency problem , It's hard to build a long-distance dependency , So a gating mechanism is introduced to control the speed of information accumulation , Including selectively adding new information , And selectively forget the accumulated information . It's more classic based on gating RNN Yes LSTM( Long and short term memory network ) and GRU( Gated loop unit network ).
4.2.3 Attention mechanism (Attention)
Attention mechanism can quickly filter out high-level information from noise , Recently, it has shown great success in many related classification tasks , To take advantage of this , The author's in the model LSTM The attention mechanism is applied behind the layer .
Advantages of attention mechanism :
- Less parameters
The complexity of the model follows CNN、RNN comparison , Less complexity , Fewer parameters . Therefore, the requirements for calculation are smaller .- Fast
Attention It's solved RNN The problem of not parallel computing .Attention The calculation of each step of the mechanism does not depend on the calculation result of the previous step , So it can be with CNN Parallel processing .- The effect is good
stay Attention Before the introduction of the mechanism , There is a problem that everyone has been very distressed : Long distance information will be weakened , It's like a person with weak memory , Can't remember the past, things are the same .Attention It's about choosing the point , Even if the text is longer , Can also grasp the key points from the middle , Don't lose important information .
4.2.4 Softmax
After paying attention to the module, send it to Softmax The vector generated after the layer is used as input for classification .
Softmax Function mapping and neuron output to (0-1) Number between , And reduce the sum to . let me put it another way , The output score of each category can be passed Softmax Convert to relative probability . therefore , The prediction tag can be determined by comparing the prediction probability of each class .
5. result
5.1 Comparison between the proposed method and existing methods

5.2 By integrating the effect of attention mechanism on performance


6. summary
Deep4mCPred It is the first prediction method based on deep learning , Integrated residual network (ResNet) And bidirectional long-term and short-term memory network (BiLSTM) To build a multi-layer deep learning prediction model .
There is no need to specify features when training prediction models , It can automatically learn advanced functions and capture 4mC Characteristics of loci , It is beneficial to distinguish non 4mC He Zhen 4mC site .
The attention mechanism introduced into the in-depth learning framework can be used to capture key features .
边栏推荐
- opencv库安装路径(别打开这个了)
- 论文解读:《基于注意力的多标签神经网络用于12种广泛存在的RNA修饰的综合预测和解释》
- 时间序列的数据分析(三):经典时间序列分解
- 怎么建立数据分析思维
- K-nucleotide frequencies (KNF) or k-mer frequencies
- Nt68661 screen parameter upgrade-rk3128-start up and upgrade screen parameters yourself
- 论文解读:《Deep-4mcw2v: 基于序列的预测器用于识别大肠桿菌中的 N4- 甲基胞嘧啶(4mC)位点》
- Analyze the pre integration of vio with less rigorous but logical mathematical theory
- ARM架构与编程6--重定位(基于百问网ARM架构与编程教程视频)
- Data mining scenario - false invoice
猜你喜欢

单片机学习笔记1--资料下载、环境搭建(基于百问网STM32F103系列教程)

Gartner调查研究:中国的数字化发展较之世界水平如何?高性能计算能否占据主导地位?
论文解读:《基于预先训练的DNA载体和注意机制识别增强子-启动子与神经网络的相互作用》

把LVGL所有控件整合到一个工程中展示(LVGL6.0版本)

How to build a liquid cooling data center is supported by blue ocean brain liquid cooling technology

ARM架构与编程1--LED闪烁(基于百问网ARM架构与编程教程视频)

单片机学习笔记6--中断系统(基于百问网STM32F103系列教程)

利用or-tools来求解路径规划问题(VRP)

论文解读:《一种利用二核苷酸One-hot编码器识别水稻基因组中N6甲基腺嘌呤位点的卷积神经网络》

Data analysis of time series (II): Calculation of data trend
随机推荐
Chaoslibrary · UE4 pit opening notes
数据分析(一)
论文解读:《BERT4Bitter:一种基于transformer(BERT)双向编码器表示用于改善苦肽预测的基础模型》
Interpretation of the paper: attention based multi label neural network for comprehensive prediction and interpretation of 12 widely existing RNA modifications
对字符串函数的使用和理解(1)
High level API of propeller realizes image rain removal
Green data center: comprehensive analysis of air-cooled GPU server and water-cooled GPU server
Interpretation of the paper: using attention mechanism to improve the identification of N6 methyladenine sites in DNA
单片机学习笔记8--按键和外部中断(基于百问网STM32F103系列教程)
数字经济“双碳”目标下,“东数西算”数据中心为何依靠液冷散热技术节能减排?
“東數西算”下數據中心的液冷GPU服務器如何發展?
Connaissance du matériel 1 - schéma et type d'interface (basé sur le tutoriel vidéo complet de l'exploitation du matériel de baiman)
单片机学习笔记5--STM32时钟系统(基于百问网STM32F103系列教程)
How to build a liquid cooling data center is supported by blue ocean brain liquid cooling technology
Use pyod to detect outliers
生命科学领域下的医药研发通过什么技术?冷冻电镜?分子模拟?IND?
opencv库安装路径(别打开这个了)
What technologies are used in pharmaceutical research and development in the field of life sciences? Cryoelectron microscope? Molecular simulation? IND?
对字符串函数的使用和理解(2)
硬件知識1--原理圖和接口類型(基於百問網硬件操作大全視頻教程)