当前位置:网站首页>Redis+Caffeine两级缓存,让访问速度纵享丝滑
Redis+Caffeine两级缓存,让访问速度纵享丝滑
2022-06-24 19:28:00 【InfoQ】
RedisMemCacheRedisGuava cacheCaffeine
优点与问题
- 本地缓存基于本地环境的内存,访问速度非常快,对于一些变更频率低、实时性要求低的数据,可以放在本地缓存中,提升访问速度
- 使用本地缓存能够减少和
Redis类的远程缓存间的数据交互,减少网络I/O开销,降低这一过程中在网络通信上的耗时
准备工作
CaffeineRedis<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.8.1</version>
</dependency>
application.ymlRedisspring:
redis:
host: 127.0.0.1
port: 6379
database: 0
timeout: 10000ms
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
RedisTemplateredisRedisTemplateConnectionFactoryV1.0版本
CaffeineCacheMapkeyvalueCache@Configuration
public class CaffeineConfig {
@Bean
public Cache<String,Object> caffeineCache(){
return Caffeine.newBuilder()
.initialCapacity(128)//初始大小
.maximumSize(1024)//最大数量
.expireAfterWrite(60, TimeUnit.SECONDS)//过期时间
.build();
}
}
CacheinitialCapacity:初始缓存空大小
maximumSize:缓存的最大数量,设置这个值可以避免出现内存溢出
expireAfterWrite:指定缓存的过期时间,是最后一次写操作后的一个时间,这里
expireAfterAccessrefreshAfterWriteCacheService@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
@Override
public Order getOrderById(Long id) {
Order order = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return order;
}
@Override
public void updateOrder(Order order) {
orderMapper.updateById(order);
}
@Override
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
}
OrderServicepublic Order getOrderById(Long id) {
String key = CacheConstant.ORDER + id;
Order order = (Order) cache.get(key,
k -> {
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(k);
if (Objects.nonNull(obj)) {
log.info("get data from redis");
return obj;
}
// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(k, myOrder, 120, TimeUnit.SECONDS);
return myOrder;
});
return order;
}
CachegetCaffeineRedisRedisRedisCaffeinegetCaffeineRedis
RedisCaffeine
RedisCaffeineRedisRedisCaffeinepublic void updateOrder(Order order) {
log.info("update order data");
String key=CacheConstant.ORDER + order.getId();
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(key,order,120, TimeUnit.SECONDS);
// 修改本地缓存
cache.put(key,order);
}
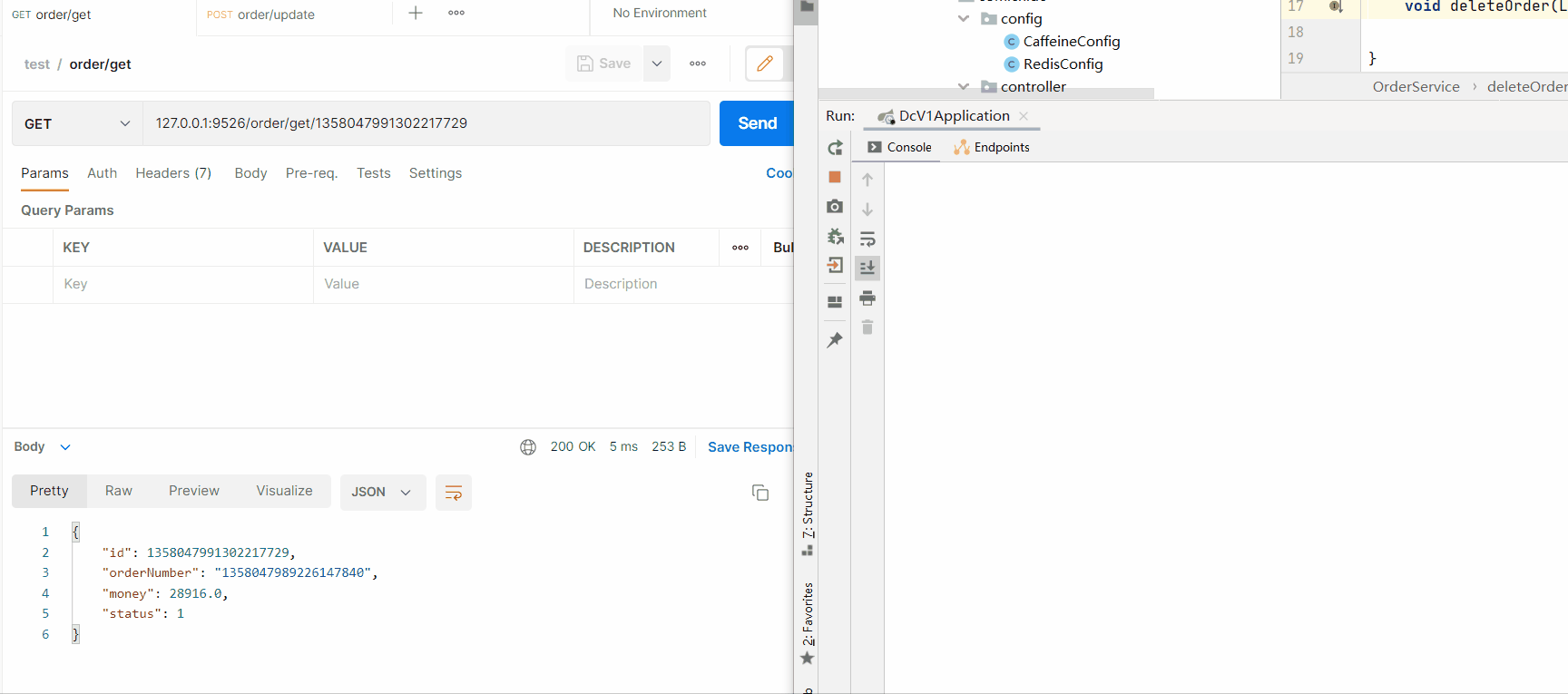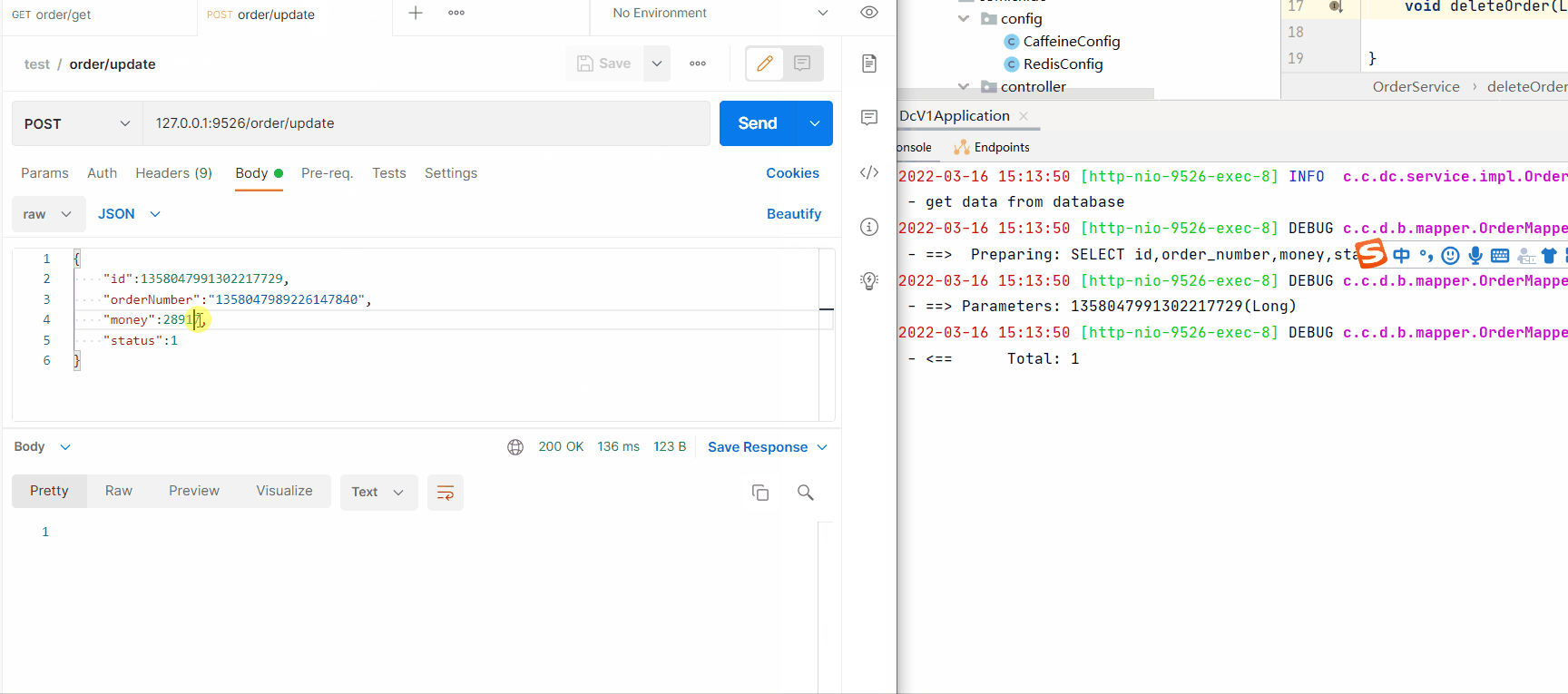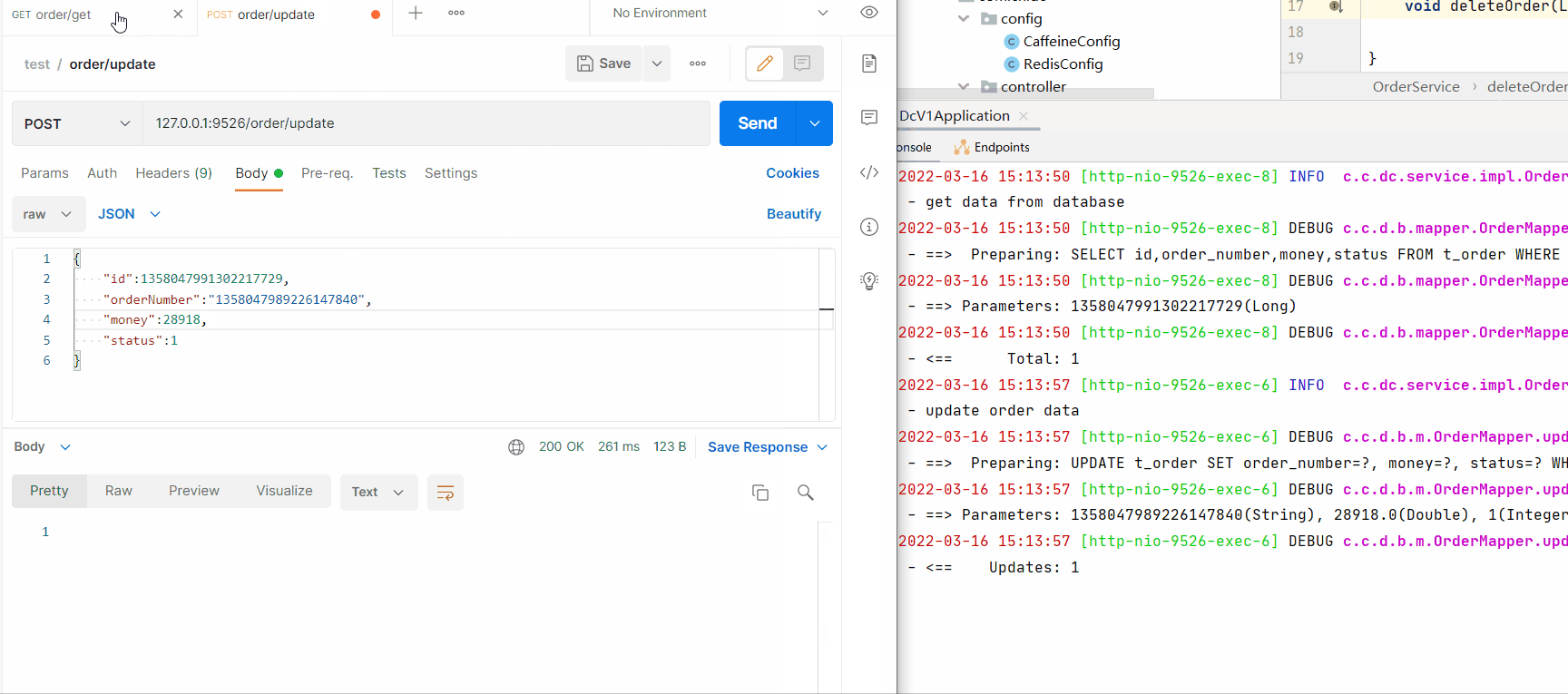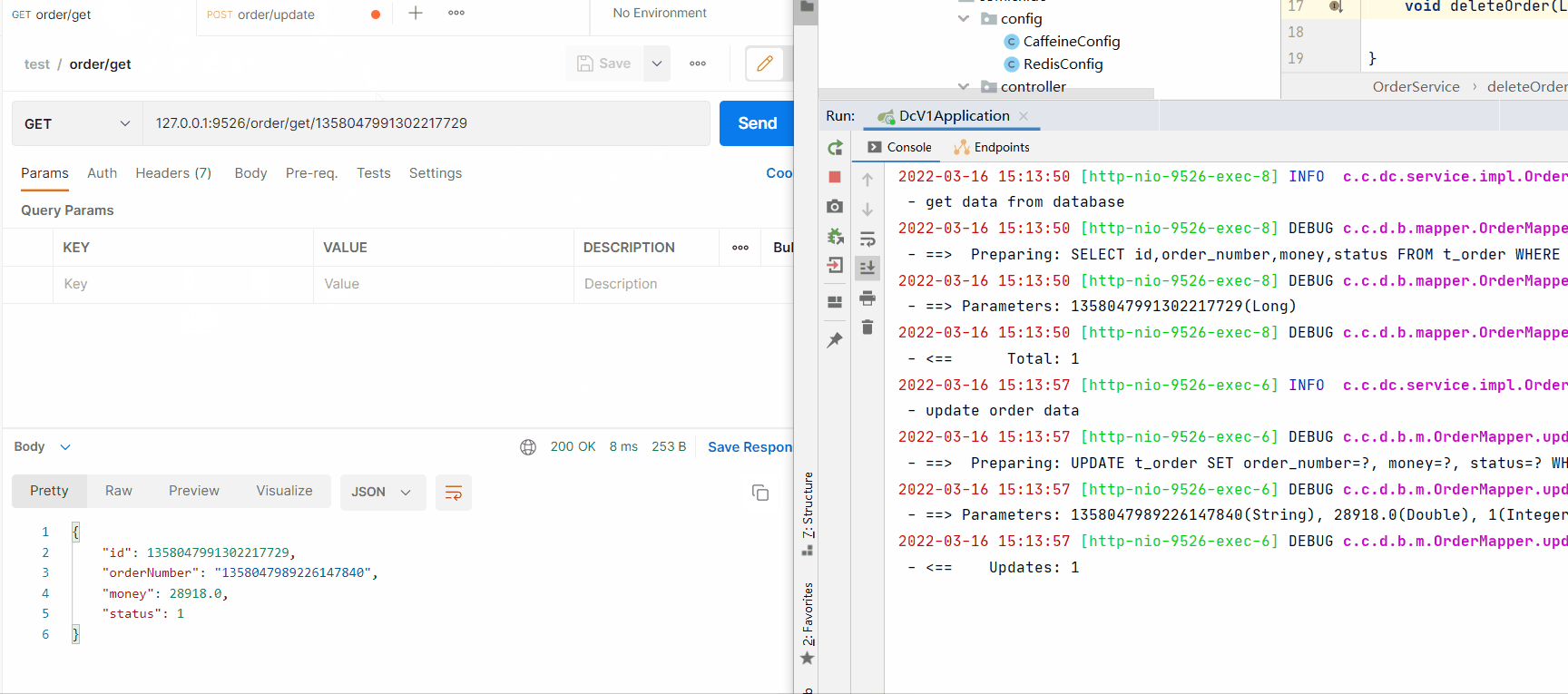
ReidsCaffeinepublic void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
String key= CacheConstant.ORDER + id;
redisTemplate.delete(key);
cache.invalidate(key);
}

V2.0版本
springCacheManager@Cacheable:根据键从缓存中取值,如果缓存存在,那么获取缓存成功之后,直接返回这个缓存的结果。如果缓存不存在,那么执行方法,并将结果放入缓存中。
@CachePut:不管之前的键对应的缓存是否存在,都执行方法,并将结果强制放入缓存
@CacheEvict:执行完方法后,会移除掉缓存中的数据。
CacheBeanspringCacheManager@Configuration
public class CacheManagerConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager=new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.initialCapacity(128)
.maximumSize(1024)
.expireAfterWrite(60, TimeUnit.SECONDS));
return cacheManager;
}
}
@EnableCachingCaffeineService@Cacheable@Cacheable(value = "order",key = "#id")
//@Cacheable(cacheNames = "order",key = "#p0")
public Order getOrderById(Long id) {
String key= CacheConstant.ORDER + id;
//先查询 Redis
Object obj = redisTemplate.opsForValue().get(key);
if (Objects.nonNull(obj)){
log.info("get data from redis");
return (Order) obj;
}
// Redis没有则查询 DB
log.info("get data from database");
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
redisTemplate.opsForValue().set(key,myOrder,120, TimeUnit.SECONDS);
return myOrder;
}
@CacheablevaluecacheNamesCachecacheNameCachecacheNameCachevaluecacheNamesCachekeykeySpringELkey#参数名
#参数对象.属性名
#p参数对应下标
@CacheableRedisCaffeine@CachePutCache@CachePut(cacheNames = "order",key = "#order.id")
public Order updateOrder(Order order) {
log.info("update order data");
orderMapper.updateById(order);
//修改 Redis
redisTemplate.opsForValue().set(CacheConstant.ORDER + order.getId(),
order, 120, TimeUnit.SECONDS);
return order;
}
voidkeyRedis@CacheEvictRedis@CacheEvict(cacheNames = "order",key = "#id")
public void deleteOrder(Long id) {
log.info("delete order");
orderMapper.deleteById(id);
redisTemplate.delete(CacheConstant.ORDER + id);
}
springCacheManagerCachespringRedisV3.0版本
spring@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DoubleCache {
String cacheName();
String key(); //支持springEl表达式
long l2TimeOut() default 120;
CacheType type() default CacheType.FULL;
}
cacheName + keykeyCacheCacheNamel2TimeOutRedistypepublic enum CacheType {
FULL, //存取
PUT, //只存
DELETE //删除
}
keyspringElpublic static String parse(String elString, TreeMap<String,Object> map){
elString=String.format("#{%s}",elString);
//创建表达式解析器
ExpressionParser parser = new SpelExpressionParser();
//通过evaluationContext.setVariable可以在上下文中设定变量。
EvaluationContext context = new StandardEvaluationContext();
map.entrySet().forEach(entry->
context.setVariable(entry.getKey(),entry.getValue())
);
//解析表达式
Expression expression = parser.parseExpression(elString, new TemplateParserContext());
//使用Expression.getValue()获取表达式的值,这里传入了Evaluation上下文
String value = expression.getValue(context, String.class);
return value;
}
elStringkeymappublic void test() {
String elString="#order.money";
String elString2="#user";
String elString3="#p0";
TreeMap<String,Object> map=new TreeMap<>();
Order order = new Order();
order.setId(111L);
order.setMoney(123D);
map.put("order",order);
map.put("user","Hydra");
String val = parse(elString, map);
String val2 = parse(elString2, map);
String val3 = parse(elString3, map);
System.out.println(val);
System.out.println(val2);
System.out.println(val3);
}
123.0
Hydra
null
CacheCacheCaffeineRedisTemplateRedis@Slf4j @Component @Aspect
@AllArgsConstructor
public class CacheAspect {
private final Cache cache;
private final RedisTemplate redisTemplate;
@Pointcut("@annotation(com.cn.dc.annotation.DoubleCache)")
public void cacheAspect() {
}
@Around("cacheAspect()")
public Object doAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
//拼接解析springEl表达式的map
String[] paramNames = signature.getParameterNames();
Object[] args = point.getArgs();
TreeMap<String, Object> treeMap = new TreeMap<>();
for (int i = 0; i < paramNames.length; i++) {
treeMap.put(paramNames[i],args[i]);
}
DoubleCache annotation = method.getAnnotation(DoubleCache.class);
String elResult = ElParser.parse(annotation.key(), treeMap);
String realKey = annotation.cacheName() + CacheConstant.COLON + elResult;
//强制更新
if (annotation.type()== CacheType.PUT){
Object object = point.proceed();
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
cache.put(realKey, object);
return object;
}
//删除
else if (annotation.type()== CacheType.DELETE){
redisTemplate.delete(realKey);
cache.invalidate(realKey);
return point.proceed();
}
//读写,查询Caffeine
Object caffeineCache = cache.getIfPresent(realKey);
if (Objects.nonNull(caffeineCache)) {
log.info("get data from caffeine");
return caffeineCache;
}
//查询Redis
Object redisCache = redisTemplate.opsForValue().get(realKey);
if (Objects.nonNull(redisCache)) {
log.info("get data from redis");
cache.put(realKey, redisCache);
return redisCache;
}
log.info("get data from database");
Object object = point.proceed();
if (Objects.nonNull(object)){
//写入Redis
redisTemplate.opsForValue().set(realKey, object,annotation.l2TimeOut(), TimeUnit.SECONDS);
//写入Caffeine
cache.put(realKey, object);
}
return object;
}
}
- 通过方法的参数,解析注解中
key的springEl表达式,组装真正缓存的key
- 根据操作缓存的类型,分别处理存取、只存、删除缓存操作
- 删除和强制更新缓存的操作,都需要执行原方法,并进行相应的缓存删除或更新操作
- 存取操作前,先检查缓存中是否有数据,如果有则直接返回,没有则执行原方法,并将结果存入缓存
Service@DoubleCache(cacheName = "order", key = "#id",
type = CacheType.FULL)
public Order getOrderById(Long id) {
Order myOrder = orderMapper.selectOne(new LambdaQueryWrapper<Order>()
.eq(Order::getId, id));
return myOrder;
}
@DoubleCache(cacheName = "order",key = "#order.id",
type = CacheType.PUT)
public Order updateOrder(Order order) {
orderMapper.updateById(order);
return order;
}
@DoubleCache(cacheName = "order",key = "#id",
type = CacheType.DELETE)
public void deleteOrder(Long id) {
orderMapper.deleteById(id);
}
Service总结
码农参上边栏推荐
- XTransfer技术新人进阶秘诀:不可错过的宝藏Mentor
- Mysql优化查询速度
- Call process of package receiving function
- 如何做到全彩户外LED显示屏节能环保
- Pattern recognition - 1 Bayesian decision theory_ P1
- What does CTO (technical director) usually do?
- Antdb database online training has started! More flexible, professional and rich
- Bld3 getting started UI
- Volcano成Spark默认batch调度器
- 双链表实现
猜你喜欢
![在每个树行中找最大值[分层遍历之一的扩展]](/img/5b/81ff20b61c0719ceb6873e44878859.png)
在每个树行中找最大值[分层遍历之一的扩展]

多路转接select

Memcached comprehensive analysis – 2 Understand memcached memory storage

C语言-关键字1

多线程收尾

Byte software testing basin friends, you can change jobs. Is this still the byte you are thinking about?

XTransfer技术新人进阶秘诀:不可错过的宝藏Mentor

VirtualBox虚拟机安装Win10企业版

leetcode:1504. 统计全 1 子矩形的个数

Datakit 代理实现局域网数据统一汇聚
随机推荐
Antdb database online training has started! More flexible, professional and rich
将二维数组方阵顺时针旋转90°
Apple mobile phone can see some fun ways to install IPA package
Sslhandshakeexception: no subject alternative names present - sslhandshakeexception: no subject alternative names present
架构实战营 第 6 期 毕业总结
[featured] how do you design unified login with multiple accounts?
memcached全面剖析–2. 理解memcached的內存存儲
Graduation summary of phase 6 of the construction practice camp
socket(2)
即构「畅直播」上线!提供全链路升级的一站式直播服务
66 pitfalls in go programming language: pitfalls and common errors of golang developers
When to send the update windows message
EditText 控制软键盘出现 搜索
Introduce the overall process of bootloader, PM, kernel and system startup
Datakit 代理实现局域网数据统一汇聚
栈的两种实现方式
TCP_ Nodelay and TCP_ CORK
力扣每日一题-第25天-496.下一个更大元素Ⅰ
手动事务的几个类
介绍BootLoader、PM、kernel和系统开机的总体流程