当前位置:网站首页>Partage de l'architecture du système de paiement du Groupe letv pour traiter 100 000 commandes simultanées élevées par seconde
Partage de l'architecture du système de paiement du Groupe letv pour traiter 100 000 commandes simultanées élevées par seconde
2022-06-22 16:51:00 【Marshal Eagle】
Avec la mise à jour du matériel de letv,La pression sur les demandes de paiement du Groupe letv a été multipliée par des centaines, voire des milliers.Dernière étape de l'achat de marchandises,Il est particulièrement important de garantir aux utilisateurs un paiement rapide et stable.Donc, dans15Année11Mois,Nous avons procédé à une mise à niveau complète de l'architecture de l'ensemble du système de paiement,Avec un traitement stable par seconde10La capacité de dix mille commandes.Il fournit un soutien puissant pour les activités de shopping et de shopping de letv Ecology sous toutes ses formes.
Un.、Sous - table de stockage
Inredis,memcachedÀ l'ère de l'Internet, où les systèmes de mise en cache sont omniprésents,Il n'est pas compliqué de construire un système qui supporte 100 000 lectures seulement par seconde,Il n'y a rien de plus que l'extension du noeud de cache par un hachage cohérent,Extension horizontalewebServeurs, etc.Le système de paiement traite 100 000 commandes par seconde,Ce qu'il faut, c'est des centaines de milliers de mises à jour de base de données par seconde(insertPlusupdate),C'est une tâche impossible sur n'importe quelle base de données indépendante,Donc la première chose que nous devons faire est de faire un bon de commande(Abréviationsorder)Sous - base et sous - table.
Lors des opérations de base de données,Il y a généralement des utilisateursID(Abréviationsuid)Champ,Nous avons donc choisi deuidSous - base de données sous - table.
Stratégie de sous - base nous avons choisi“Sous - bibliothèque binaire”,Ce qu'on appelle“Sous - bibliothèque binaire”Ça veut dire:Nous sommes en train d'agrandir la base de données,C'est tout.2Pour agrandir la capacité.Par exemple,:1La station a été agrandie pour2Table,2La station a été agrandie pour4Table,4La station a été agrandie pour8Table,Et ainsi de suite..L'avantage de cette approche de sous - base est que,Nous sommes en expansion,C'est tout.DBASynchronisation des données au niveau du tableau, Au lieu d'écrire vos propres scripts pour la synchronisation des données au niveau de la ligne .
Il ne suffit pas d'avoir des sous - bibliothèques , Après des tests de résistance continus, nous avons découvert ,Dans la même base de données, La mise à jour simultanée de plusieurs tables est beaucoup plus efficace que la mise à jour simultanée d'une table. , Donc, dans chaque sous - bibliothèque, nous allons order Tableau divisé en 10Part:order_0,order_1,….,order_9.
Enfin, nous avonsorderLa montre est8 Dans les sous - bibliothèques (No.1À8,Correspondant séparémentDB1ÀDB8), Dans chaque sous - bibliothèque 10Sous - tables(No.0À9,Correspondant séparémentorder_0Àorder_9), La structure de déploiement est illustrée ci - dessous :
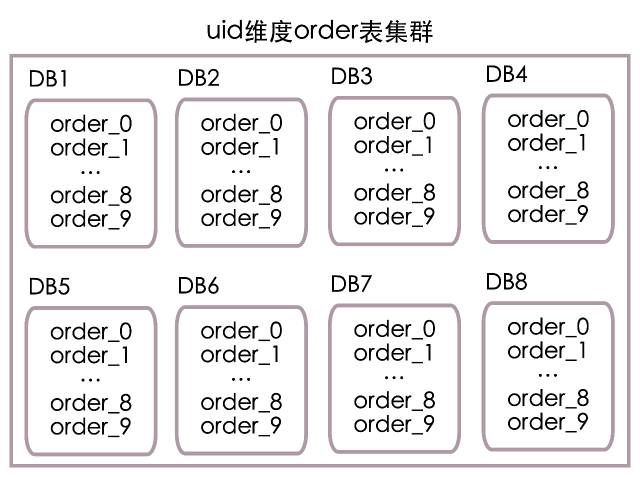
Selonuid Calculer le numéro de base de données :
Numéro de la base de données = (uid / 10) % 8 + 1
Selonuid Feuille de calcul No. :
Tableau n° = uid % 10
Quanduid=9527Heure,Selon l'algorithme ci - dessus,En fait,uidDivisé en deux parties952Et7,Parmi eux952Module8Plus1égal à1 Pour le numéro de base de données ,Et7 Numéro du tableau .Alors...uid=9527 Les informations de commande pour DB1Dans la bibliothèqueorder_7Recherche de tableaux. Voir la figure ci - dessous pour le processus d'algorithme spécifique. :

Avec la structure et l'algorithme de la Sous - base de données et de la Sous - table, la dernière étape consiste à trouver l'outil de mise en oeuvre de la Sous - base de données et de la Sous - table. , À l'heure actuelle, il existe environ deux types d'outils de sous - base et de sous - table sur le marché. :
- Sous - base de données client sous - table , Terminer la Sous - base de données et la Sous - table du client ,Connexion directe à la base de données
- Utilisation d'un intergiciel de sous - base de données et de sous - table , Intergiciel de sous - base et de sous - base du client , Sous - base de données et sous - table par Middleware
Les deux types d'outils sont disponibles sur le marché ,Je ne vais pas les énumérer ici., Dans l'ensemble, les deux types d'outils présentent des avantages et des inconvénients . Sous - base de données client sous - table en raison de la connexion directe à la base de données , Par conséquent, la performance est supérieure à l'utilisation d'un intergiciel de sous - base de données et de sous - table. 15%À20%. L'utilisation de l'intergiciel de sous - base de données et de sous - table a permis une gestion unifiée de l'intergiciel. , Isoler les opérations de sous - base et de sous - Table des clients , La Division des modules est plus claire ,PratiqueDBAGestion unifiée.
Nous avons choisi de diviser les tables dans la Sous - bibliothèque du client , Parce que nous avons développé et ouvert notre propre cadre d'accès à la couche de données , Son nom de code est “Mangue”, Mango Frame Native supporte la fonction de sous - base de données et de sous - table , Et très simple à configurer .
- Mangue page d'accueil :mango.jfaster.org
- Mango source :github.com/jfaster/mango
2.、OrdreID
Système de commandeID Doit avoir des caractéristiques uniques au niveau mondial , La façon la plus simple est d'utiliser la séquence de la base de données , Une auto - augmentation unique au niveau mondial peut être obtenue à chaque opération ID, Si vous voulez supporter le traitement par seconde 1010 000 commandes, Cela nécessitera au moins une génération par seconde 1010 000 commandesID, Générer une auto - augmentation à partir de la base de données ID Il est évident que les exigences ci - dessus ne peuvent être remplies. . Donc nous ne pouvons obtenir que des commandes uniques au niveau mondial en utilisant des calculs de mémoire ID.
JAVA Le seul et unique IDÇa doit être ça.UUIDC'est,MaisUUID Trop long et contient des lettres , Ne convient pas comme commande ID. Par comparaison et filtrage répétés ,Nous avons empruntéTwitterDeSnowflakeAlgorithmes, L'unicité globale a été réalisée ID. Voici l'ordre. ID Structure simplifiée de :

L'image ci - dessus est divisée en3Sections:
- Horodatage
La granularité de l'horodatage ici est en millisecondes ,Générer une commandeIDHeure,UtiliserSystem.currentTimeMillis()Comme horodatage.
- Numéro de la machine
Chaque serveur de commande se verra attribuer un numéro unique ,Générer une commandeIDHeure, Utilisez ce numéro unique directement comme numéro de machine .
- Numéro de série auto - augmenté
Lorsqu'il y a plus d'une commande générée dans la même milliseconde sur le même serveur IDSur demande, Augmente ce numéro de séquence en millisecondes , La milliseconde suivante ce numéro de séquence continue à partir de 0C'est parti.. Par exemple, il y a 3 Commandes générées IDDemandes,Voilà.3CommandesID Les sections auto - incrémentales de 0,1,2.
Là - haut3 Combinaison de parties , Nous pouvons rapidement générer des commandes uniques au niveau mondial ID. Mais ce n'est pas tout. , La plupart du temps, nous ne suivons que les commandes ID Demande directe d'information sur la commande , Parce qu'il n'y en a pas. uid, Nous ne savons pas dans quelle sous - base de données nous interrogeons dans la Sous - table , Traverser toutes les tables de toutes les bibliothèques ?Ça ne marchera pas.. Nous devons donc ajouter les informations de la Sous - liste à la commande IDAllez., Voici les commandes avec les informations de la Sous - table ID Schéma de structure simplifié :

Commandes globales que nous produisons ID L'en - tête ajoute des informations sur les sous - bases et les sous - tables , Comme ça, seulement sur commande ID, Nous pouvons également obtenir rapidement les informations de commande correspondantes .
Qu'est - ce que les informations de la Sous - base de données et de la Sous - table contiennent? ? La première partie traite de , Nous appuyons sur le formulaire de commande uid La dimension est divisée en 8Bases de données,Par base de données10Tableau, L'information la plus simple sur les sous - bases de données et les sous - tables n'a besoin que d'une longueur de 2 La chaîne pour stocker ,No1 Numéro de base de données de stockage de bits ,Plage de valeurs1À8,No2 Numéro de la table de dépôt ,Plage de valeurs0À9.
Ou selon la première partie uid Algorithme de calcul du numéro de base de données et du numéro de tableau ,Quanduid=9527Heure, Informations sur la Sous - base =1, Informations sur les sous - Tableaux =7, Les combiner , Les informations de la Sous - base de données et de la Sous - table à deux chiffres sont les suivantes: ”17”. Voir la figure ci - dessous pour le flux d'algorithme spécifique :

Il n'y a aucun problème à utiliser les numéros de tableau ci - dessus comme information de sous - Tableau , Cependant, l'utilisation du numéro de base de données comme information de sous - base de données présente des dangers cachés. , Tenir compte des besoins futurs en matière d'expansion ,Nous devons8 Extension de la bibliothèque à 16Bibliothèque, Plage de valeurs 1À8 Les informations de la Sous - base de données ne seront pas prises en charge 1À16 Scénario de sous - base pour , Le routage de la Sous - base de données ne sera pas effectué correctement , Nous avons abrégé la question d'appel en une perte de précision de l'information de la Sous - base. .
Pour résoudre le problème de la perte de précision de l'information de la Sous - base , Nous avons besoin de redondance pour la précision de l'information de la Sous - base , C'est - à - dire que les informations de la Sous - base que nous sauvegardons maintenant doivent supporter l'expansion future . Nous supposons ici qu'à la fin, nous étendrons notre capacité à 64Base de données, Donc le nouvel algorithme d'information de sous - base est :
Informations sur la Sous - base = (uid / 10) % 64 + 1
Quanduid=9527Heure, Selon le nouvel algorithme , Informations sur la Sous - base =57,Ici.57 N'est pas un vrai numéro de base de données , Il est redondant et s'étend finalement à 64 Précision de l'information de la Sous - base de données . Nous n'avons actuellement que 8Base de données, Le numéro réel de la base de données doit également être calculé selon la formule suivante: :
Numéro réel de la base de données = ( Informations sur la Sous - base - 1) % 8 + 1
Quanduid=9527Heure, Informations sur la Sous - base =57, Numéro réel de la base de données =1, Sous - base de données sous - table information =”577”.
Parce que nous avons choisi le module 64 Pour sauvegarder les informations de sous - base après redondance de précision , La longueur de l'enregistrement des informations de la Sous - base de données est déterminée par 1Ça devient2, La longueur de la dernière sous - base de données est 3. Voir la figure ci - dessous pour le processus d'algorithme spécifique. :
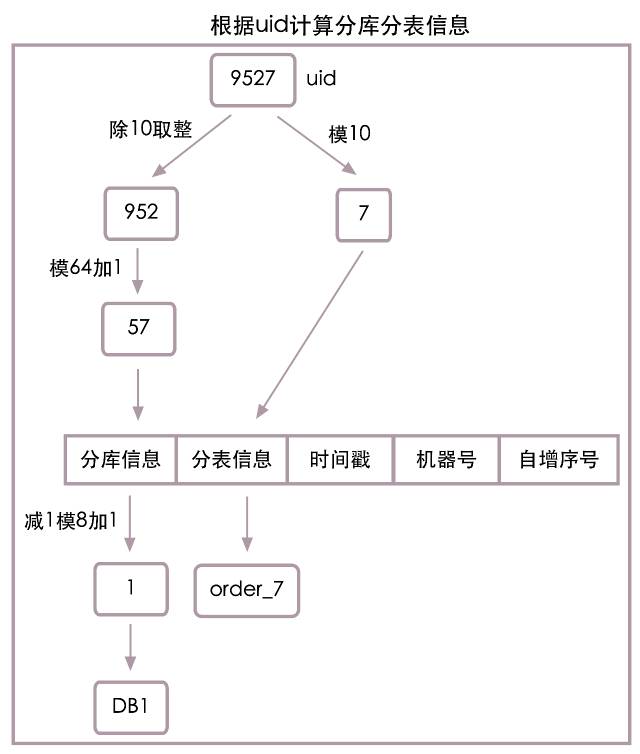
Comme le montre la figure ci - dessus, Le module est utilisé pour calculer l'information de la Sous - base de données 64 La méthode est redondante pour la précision de l'information de la Sous - base , De cette façon, lorsque notre système devra être étendu 16Bibliothèque,32Bibliothèque,64 Il n'y aura plus de problèmes avec la Bibliothèque .
Ordre ci - dessus ID La structure a bien répondu à nos besoins d'expansion actuels et futurs , Mais compte tenu de l'incertitude de l'entreprise, ,On commandeID Plus loin. 1 Bit utilisé pour identifier l'ordre IDVersion de, Ce numéro de version est redondant , Il n'est pas utilisé pour le moment . Voici la commande finale ID Schéma de structure simplifié :

SnowflakeAlgorithmes:github.com/twitter/snowflake
Trois、Conformité finale
Jusqu'à présent,Nous avons adoptéorderTableauuid Sous - base de données sous - Table des dimensions ,C'est fait.order Écrire et mettre à jour simultanément le tableau en surélévation ,Et peut passer à traversuidEt commandesIDDemander des informations sur la commande. Mais en tant que système de paiement collectif ouvert , Nous devons également passer par les secteurs d'activité ID( Aussi connu sous le nom de marchand ID,Abréviationsbid) Pour obtenir des informations sur les commandes ,Nous avons donc introduitbidDimensionorder Groupe de tableaux ,Oui.uidDimensionorder Le Groupe de tableaux est redondant d'une copie à bidDimensionorder Groupe de tableaux ,Selonbid Lors de l'interrogation des informations de commande , Il suffit de vérifier. bidDimensionorder Regroupement des tables .
Le schéma ci - dessus est simple , Mais gardez - en deux. order La cohérence des données dans les grappes de tableaux est un problème . Les deux groupes de tables sont évidemment dans des groupes de bases de données différents , Si une transaction distribuée fortement cohérente est introduite dans l'écriture et la mise à jour , Cela réduira certainement considérablement l'efficacité du système. , Augmenter le temps de réponse du service ,C'est inacceptable, Nous avons donc introduit une file d'attente de messages pour la synchronisation asynchrone des données , Pour assurer la cohérence finale des données . Bien sûr, diverses exceptions à la file d'attente des messages peuvent également entraîner des incohérences dans les données. , Nous avons donc introduit un service de surveillance en temps réel , Calcul en temps réel des différences de données entre les deux Clusters , Et une synchronisation cohérente .
Voici un diagramme simplifié de synchronisation de la cohérence :

Quatre、Base de données très disponible
Aucune machine ou service ne peut garantir un fonctionnement stable en ligne sans défaillance . Comme à un moment donné. , Arrêt d'une base de données principale , À ce stade, nous ne pouvons pas lire ou écrire la bibliothèque , Les services en ligne seront touchés .
La disponibilité élevée de la base de données signifie : Lorsque la base de données a des problèmes pour diverses raisons , Récupération en temps réel ou rapide des services de base de données et réparation des données , Du point de vue de l'ensemble de la grappe , Comme s'il n'y avait pas de problème. .Il est important de noter que, Le Service de base de données de récupération ici ne signifie pas nécessairement la réparation de la base de données originale , Cela comprend également le passage du service à une autre base de données de rechange. .
Les principales tâches de la base de données hautement disponible sont la récupération de la base de données et la réparation des données. , En général, le temps qu'il nous faut pour terminer ces deux tâches , Mesure de la disponibilité élevée . Il y a un cercle vicieux. , Plus le temps de récupération de la base de données est long , Plus les données sont incohérentes , Plus il faudra de temps pour corriger les données , Le temps de réparation global sera plus long . Par conséquent, la restauration rapide de la base de données est devenue la priorité absolue de la haute disponibilité de la base de données. , Imaginez si nous pouvions échouer dans la base de données 1 Récupération complète de la base de données en secondes , La correction des données incohérentes et des coûts peut également réduire considérablement .
L'image ci - dessous est l'une des structures maître - esclave les plus classiques :
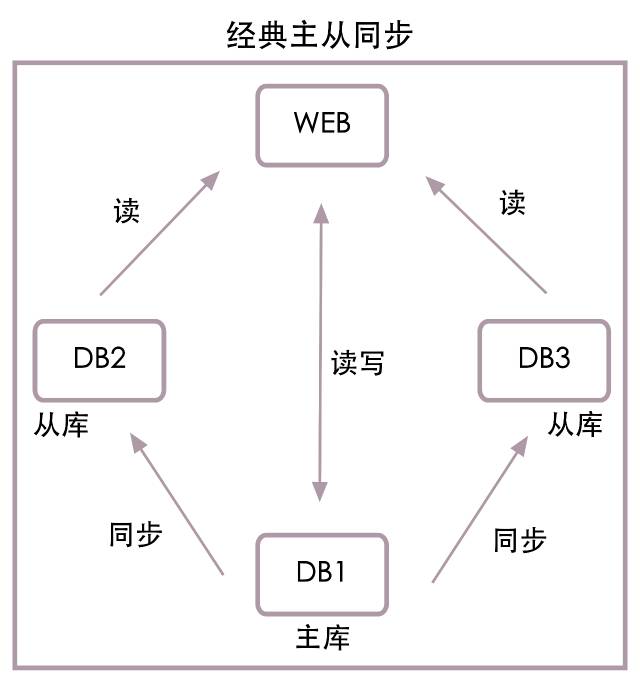
Dans l'image ci - dessus1TablewebServeur et3Base de données,Parmi euxDB1C'est la bibliothèque principale,DB2EtDB3C'est de la bibliothèque..Nous supposons iciweb Le serveur est maintenu par l'équipe de projet , Et le serveur de base de données est DBAEntretien.
Quand on sort de la bibliothèque DB2En cas de problème,DBA L'équipe de projet sera informée , L'équipe de projet DB2Deweb Supprimer de la liste de configuration du Service ,RedémarrerwebServeur, Ce noeud qui a mal tourné DB2 Ne sera plus accessible , Récupération de l'ensemble du Service de base de données ,Attendez.DBARéparationDB2Heure, L'équipe de projet DB2Ajouter àwebServices.
Quand la bibliothèque principaleDB1En cas de problème,DBAOui.DB2 Passer à la bibliothèque principale , Et informer l'équipe de projet ,Utilisation par l'équipe de projetDB2 Remplacer la bibliothèque principale existante DB1,RedémarrerwebServeur,Voilà.web Le Service utilisera la nouvelle bibliothèque principale DB2,EtDB1 Ne sera plus accessible , Récupération de l'ensemble du Service de base de données ,Attendez.DBARéparationDB1Heure,Encore.DB1En tant queDB2 De la bibliothèque .
La structure classique ci - dessus présente de gros inconvénients : Qu'il y ait un problème avec la Bibliothèque primaire ou secondaire ,Tout est nécessaire.DBA Travailler avec l'équipe de projet pour terminer la récupération du Service de base de données , C'est difficile d'automatiser , Et la restauration est trop lente. .
Nous pensons que, L'exploitation et l'entretien de la base de données devraient être séparés de l'équipe de projet ,Quand il y a un problème avec la base de données,Doit:DBA Réaliser une récupération unifiée , Services opérationnels de l'équipe de projet non requis , Cela facilite l'automatisation , Réduire le temps de récupération du service .
Regardez d'abord le diagramme de structure disponible à partir de la hauteur de la bibliothèque :

Comme le montre la figure ci - dessus,web Le serveur ne se connectera plus directement à partir de la bibliothèque DB2EtDB3,C'est la connexion.LVSÉquilibrage de la charge,ParLVS Connexion à partir de la bibliothèque .L'avantage est queLVS Capacité de détecter automatiquement la disponibilité des bibliothèques esclaves ,De la bibliothèqueDB2Après arrêt,LVS Aucune demande de lecture de données ne sera envoyée à DB2.En même tempsDBA Lorsque vous avez besoin d'ajouter ou de supprimer un noeud de bibliothèque esclave , Il suffit d'agir seul LVSC'est tout., Le profil de mise à jour de l'équipe de projet n'est plus nécessaire , Redémarrer le serveur pour coopérer .
Voir le diagramme de la structure disponible de la hauteur de la bibliothèque principale :

Comme le montre la figure ci - dessus,web Le serveur ne se connectera plus directement à la bibliothèque principale DB1,C'est la connexion.KeepAlive Virtual out of a Virtual ip, Ensuite, vous pouvez mettre ce virtuel ip Mapping to Primary Library DB1Allez.,Ajouter en même tempsDB_bakDe la bibliothèque,Synchronisation en temps réelDB1Données dans.Dans des conditions normaleswebToujours là.DB1Lire et écrire des données,QuandDB1Après arrêt, Le script met automatiquement DB_bak Définir comme bibliothèque principale ,Et virtuelipMapping toDB_bakAllez.,web Le Service utilisera des DB_bak Accès en lecture et en écriture en tant que bibliothèque principale . Ça ne prendra que quelques secondes , Pour compléter la récupération du Service de base de données primaire .
Combiner la structure ci - dessus , Obtenir le diagramme de structure maître - esclave haute disponibilité :

La base de données haute disponibilité contient également des correctifs de données , Parce que lorsque nous manipulons les données de base, , Tout est enregistré avant la mise à jour , Plus un service de base de données de récupération rapide en temps quasi réel , Donc la quantité de données réparées n'est pas grande , Un simple script de récupération complète rapidement la réparation des données .
Cinq、Classement des données
Système de paiement en plus de la Feuille de commande de paiement de base et de la Feuille de flux de paiement , Il existe également des fiches de configuration et des fiches d'information sur l'utilisateur. . Si toutes les opérations de lecture sont effectuées sur la base de données , Les performances du système seront considérablement réduites , Nous avons donc introduit un mécanisme de classement des données .
Nous avons simplement divisé les données du système de paiement en 3Niveau:
No1Niveau:Données de commande et données de flux de paiement;Ces deux données exigent beaucoup de temps réel et de précision,Donc n'ajoutez pas de cache,Les opérations de lecture et d'écriture permettront d'accéder directement à la base de données.
No2Niveau:Données relatives aux utilisateurs;Ces données sont pertinentes pour l'utilisateur,Caractéristique de lire plus et d'écrire moins,Donc nous utilisonsredisPour mettre en cache.
No3Niveau:Informations sur la configuration des paiements;Ces données ne concernent pas les utilisateurs,Avec une petite quantité de données,Lire fréquemment,Caractéristiques à peine modifiées,Donc nous utilisons la mémoire locale pour la mise en cache.
Il y a un problème de synchronisation des données avec le cache de mémoire local ,Parce que les informations de configuration sont mises en cache en mémoire, La mémoire locale ne peut pas détecter les modifications des informations de configuration dans la base de données , Cela peut entraîner des incohérences entre les données de la base de données et celles de la mémoire locale. .
Pour résoudre ce problème, Nous avons développé une plateforme de messagerie très disponible , Lorsque les informations de configuration sont modifiées , Nous pouvons utiliser la plateforme push , Envoyer des messages de mise à jour de profil à tous les serveurs du système de paiement , Le serveur met automatiquement à jour les informations de configuration lorsqu'il reçoit un message , Et donner une rétroaction sur le succès .
Six、 Tuyaux épais et fins
Piratage, Les retraits frontaux et d'autres causes peuvent entraîner une augmentation du nombre de demandes. , Si nos services sont décimés par une vague de demandes , Pour récupérer , C'est un processus très douloureux et fastidieux .
Un exemple simple, Notre capacité actuelle de traitement des commandes est moyenne 10 Dix mille commandes par seconde ,Pic14 Dix mille commandes par seconde , Si la même seconde 100 10 000 demandes d'accès au système de paiement , Il ne fait aucun doute que tout notre système de paiement va s'effondrer. , Un flot de demandes subséquentes pourrait empêcher notre grappe de services de démarrer , Le seul moyen est de couper tout le trafic. , Redémarrer l'ensemble du cluster , Importer lentement le trafic .
Nous sommes à l'extérieur web Ajouter une couche au serveur “ Tuyaux épais et fins ”, Ça résout le problème. .
Voici un schéma de structure simple pour les tuyaux épais et fins :

Voir l'organigramme ci - dessus ,http Demande d'accès webPré - Cluster, Passe d'abord par un tuyau épais et fin. . L'entrée est rugueuse , Nous définissons le support maximum 100 10 000 demandes par seconde , Les demandes redondantes sont rejetées. . L'extrémité de sortie est mince , Nous définissons webCluster10 10 000 demandes par seconde .Reste90 Dix mille demandes seront mises en file d'attente dans les tuyaux épais et fins ,Attendez.web Une fois que le cluster a traité l'ancienne demande , Avant qu'une nouvelle demande ne sorte du pipeline ,Voilà.webTraitement groupé.Voilà.web Le nombre de demandes traitées par le cluster ne dépassera jamais par seconde 10(En milliers de dollars des États - Unis), Sous cette charge , Tous les services de la grappe fonctionnent dans les collèges et les universités , L'ensemble du cluster n'arrête pas non plus le service en raison d'une demande croissante .
Comment réaliser des tuyaux épais et fins ?nginx Le support est déjà disponible dans la version commerciale , Pour plus d'informations, veuillez rechercher
nginx max_conns,Il est important de noter quemax_conns Est le nombre de connexions actives , En plus des paramètres spécifiques, vous devez déterminer le maximum TPSExtérieur, Le temps de réponse moyen doit également être déterminé .
边栏推荐
- vs2017 在调试状态不显示QString值的解决方法
- SAP script tutorial: se71, se78, SCC1, vf03, so10-013
- jsp学习之(三)--------- jsp隐式对象
- STM32 ADC acquisition via DMA (HAL Library)
- Spark Streaming-Receiver启动和数据接收
- 面对默认导入失败的情况
- Windows8.1 64 installed by mysql5.7.27
- Interface idempotent design
- NiO file and folder operation examples
- Special research on Intelligent upgrading of heavy trucks in China in 2022
猜你喜欢

【C语言深度解剖】关键字if&&else&&bool类型

图计算Hama-BSP模型的运行流程
JS获取数据类型方法总结

视频会议时听不到声音该如何处理?

The world's "first" IEEE privacy computing "connectivity" international standard led by insight technology was officially launched
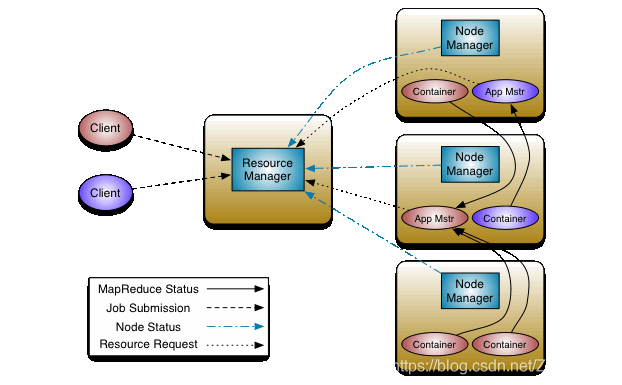
高可用性的ResourceManager

jMeter使用案例
![Prometheus监控之Consul监控 [consul-exporter]](/img/9e/8547b2c38143ab0e051c1cf0b04986.png)
Prometheus监控之Consul监控 [consul-exporter]

jsp学习之(二)---------jsp脚本元素和指令
![[wechat applet to obtain the height of custom tabbar] is absolutely available!!!](/img/ed/7ff70178f03b50cb7bec349c1be5e0.png)
[wechat applet to obtain the height of custom tabbar] is absolutely available!!!
随机推荐
spark-shuffle的读数据源码分析
同花顺怎么开户?网上开户安全么?
【C语言】深度剖析整型和浮点型在内存中的存储
[C language] deeply analyze the storage of integer and floating-point types in memory
Uniapp wechat applet obtains page QR code (with parameters)
LETV group payment system architecture sharing for processing 100000 high concurrent orders per second
MYSQL_ERRNO : 1292 Truncated incorrect date value At add_num :1
JS获取数据类型方法总结
Summary of Changan chain usage skills
How to use IDM to accelerate Baidu cloud
ERROR 1364 (HY000): Field ssl_cipher doesnt have a default value
如何为政企移动办公加上一道“安全锁”?
Machine learning notes - Hagrid - Introduction to gesture recognition image data set
Test for API
jsp学习之(二)---------jsp脚本元素和指令
双向数据绑定v-model与v-decorator
面对默认导入失败的情况
Analysis of the writer source code of spark shuffle
[pop up box at the bottom of wechat applet package] I
JS method for judging data type of interview questions