当前位置:网站首页>高可用性的ResourceManager
高可用性的ResourceManager
2022-06-22 15:23:00 【ZH519080】
YARN的架构图

有图可知,ResourceManager(RM)对整个集群的重要就不言而喻了吧。但是由于多种原因可能会造成ResourceManager出现问题,由于单位的集群ResourceManager也出现问题,今天我分析一下ResourceManager的High Availability(高可用性)。
ResourceManager的作用:负责协调集群上计算资源的分配,与NodeManager、MRApplicationMaster、HeartBeat等进行进行交互。
ResourceManager的高可用性:在Hadoop-2.4之前,ResourceManager是集群的单点故障。ResourceManager的高可用性是以“Active/Standby(活动/备用)”的形式增加一个节点冗余,并利用Zookeeper集群,把Active的ResourceManager状态信息写入Zookeeper用于启动Standby ResourceManager,以消除这个单点故障。如下图所示。

ResourceManager HA是通过“Active/Standby”架构来实现的。一个ResourceManager处于活动状态,一个或多个ResourceManager处于备用状态以实现接管活动状态下的发生的任何状况。当Active出现状况需要自动启用Standby的ResourceManager时,时通过Failover-Controller(故障转移控制器)来实现的。
官网:
http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
RM 故障转移控制器
当不启用自动故障转移时,管理员必须手动将其中一个ResourceManager由Standby状态转换为Active状态。从一个ResourceManager转移到另一个ResourceManager需要首先将Active状态的ResourceManager转换为Standby状态的ResourceManager,之后才可将Standby状态ResourceManager装换为Active状态的 ResourceManager,这些操作都是通过“yarn rmadmin CLI”来完成。
在集群中任意节点上启动Zookeeper的zkfc的初始化状态:
sudo -u hdfs zkfc -formatZK
启动自动故障转移功能,start-dfs.sh脚本将在任何运行NameNode的主机上自动启动ZKFC守护进程,一旦ZKFC启动完毕则自动选择一个Standby NameNode最为新的Active NameNode。若手动管理集群中的服务,可在每台Standby NameNode上执行命令:
sudo -u hadoop-daemon.sh start zkfc
或者手动转换的命令:
sudo -u hdfs haadmin -transitionToActive/transitionToStandby
其中haadmin工具是用运行HDFS HA的管理客户端工具
可以选择嵌入基于Zookeeper的ActiveStandbyElector来决定哪个RM应该是启动的,当RM的活动停止或无响应时,另一个RM被自动选择为Active RM,整个集群的资源调配功能由新的Active RM来接管。但是,RM HA不需要像HDFS那样运行单独的ZKFC守护进行,因为嵌入在RM中的ActiveStandbyElector充当故障检测器和Leader Elector,而不是单独的ZKFC进程。
当有多个RM时,把集群中的所有的yarn-site.xml配置文件中添加所有的RM的主机名或IP地址。MRApplicationMaster和NodeManager尝试以循环方式连接RM,直到它们连接Active RM,若ResourceManager停止或无响应,它们将继续轮询直到遇到新的Active为止。
关于ResourceManager高可用性的yarn-site.xml文件的部分配置:
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- RM的Active/Standby的自动切换>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.recover.enabled</name>
<value>true</value>
</property
<!--RM故障自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>zysdmaster000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>standbymaster000,standbymaster001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>standbymaster000</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>standbymaster001</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>standbymaster000:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>standbymaster001:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zysdslave001:2181,zysdslave002:2181,zysdslave003:2181,zysdslave004:2181</value>
</property>
边栏推荐
猜你喜欢

Static assertion static_ assert

SLAM十四讲之第6讲--非线性优化

SAP web service 无法使用 SOAMANAGER 登陆到SOA管理页面

Summary of safari compatibility issues
![[C language] deeply analyze the relationship between pointer and array](/img/f3/432eeee17034033361e05dde67aac3.jpg)
[C language] deeply analyze the relationship between pointer and array
![[wechat applet custom bottom tabbar]](/img/04/2ea4ab3fd8571499190a9b3c9990b2.png)
[wechat applet custom bottom tabbar]

CUMT study diary - quick notes of digital image processing examination

ABAP query tutorial in sap: sq01, sq02, sq03-017

过气剧本杀,被露营“复活”
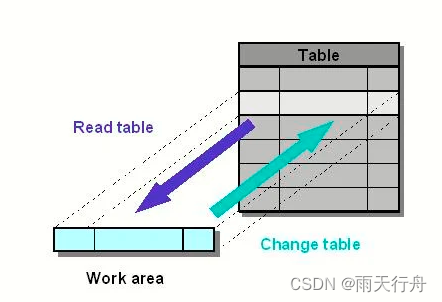
SAP ABAP 内部表:创建、读取、填充、复制和删除-06
随机推荐
4.字符串(倒序且大小写转换)
直播无顶流:董宇辉这么火,还有人看刘畊宏吗?
NiO uses writable events to handle the situation of one-time write incompleteness
对ABAP程序调优的学习(四)LOOP WHERE KEY
mysql 字符串字段转浮点型字段
迭代器与生成器
[wechat applet to obtain the height of custom tabbar] is absolutely available!!!
面对默认导入失败的情况
【小程序项目开发-- 京东商城】uni-app开发之配置tabBar & 窗口样式
nio使用可写事件处理一次性写不完情况
In case of default import failure
What is SAP ABAP? Type, ABAP full form and meaning
jsp學習之(二)---------jsp脚本元素和指令
【C语言】深度剖析整型和浮点型在内存中的存储
大话局部性原理
sql语法检测
Interface (optimization type annotation)
双向数据绑定v-model与v-decorator
Runtime -- explore the nature of classes, objects, and classifications
Task scheduling design of collection system