当前位置:网站首页>Preparation and operation & Maintenance Guide for 'high concurrency & high performance & high availability service program'
Preparation and operation & Maintenance Guide for 'high concurrency & high performance & high availability service program'
2022-06-24 13:10:00 【51CTO】
introduction :
Remember far away 2012 in , Because I want to write high concurrency programs , I chose to change my job . At the beginning, I wrote a program to support the concurrency of tens of thousands of devices ( Our IOT device business needs to maintain a long connection ), With the development of enterprises , Gradually grow to 100000 、 Hundreds of thousands of equipment , At that time, we also paid attention to the performance of single machines , Therefore, various threading models are closely followed 、I/O Model …… Constantly tap your potential , When I was really unable to dig, I began to use distributed solutions . For example, a high-performance open source service model : https://github.com/yaocoder/HPNetServer
later , I was lucky to start my career in this group , Led the creation and operation of an Internet platform level product serving millions of users , We have also practiced high concurrency & High performance & Preparation, operation and maintenance of highly available services .
later , I went out to Beijing to start my own business for several years , After the failure, he returned to his former company , At this time, the platform already has tens of millions of users , A million days to live . But because of the continuous adjustment of personnel , Used to be responsible for high concurrency & Experienced colleagues with high-performance services have successively gone to Beijing's first-line factories , At this time, the R & D team is concerned about how to write O & m high concurrency & High performance & Limited experience with highly available services , So a few months ago, I combined my own practical experience with the knowledge sharing of other experts in the industry to compile such a guidance manual , Hope to give such guidance to the team : To find problems 、 Set a goal 、 Practice .
also , Before writing this manual , And I read and practiced a Book ten years ago 《 Build high performance Web Site 》 Read it again , Although the technology is updating iterations , But good books and ideas never grow old , I also hope that each of our former programmers will not be old , Or the society and the company will not despise us . To youth forever !
One 、 To find problems
1. Understanding of platform business
The status quo of the platform business determines the characteristics of the service , Such as the effective number of users of the platform / Quantity of equipment , Business peak period 、 Business peak 、 The situation during the business downturn
Take our business as an example :
Typical 2B Again 2C The business of , Provide... For kindergartens SaaS System and home school interaction platform linking families . It has served tens of thousands of kindergartens and tens of millions of family users .
- The user volume at the park end does not involve high concurrency and high performance , Just ensure high availability .
- There are tens of millions of users on the parent side , It's highly concurrent 、 High availability 、 Standard scenarios for high-performance services .
- From user usage scenarios , It is used when parents send their children in the morning and when parents rest at noon APP At the peak of , The working day of the kindergarten belongs to the peak period , Nights and weekends are low .
- From the characteristics of business development , At the beginning of the school year, the business is at its peak + Peak increase period , The original system is facing great challenges and pressures .
2. An understanding of the metrics used to measure system performance
In the actual work, it is found that many background colleagues lack understanding of the basic performance measurement indicators , Unable to evaluate the performance level of the system .
Some common metrics
RT( response time )
The time the system responds to the request
Throughput( throughput )
Throughput refers to the number of requests processed by the system in unit time , Inversely proportional to response time
Number of concurrent users
Online at the same time ( establish TCP A long connection ) The number of users
RPS(Requests Per Second)
QPS( Queries Per Second)
For a query service , Number of response requests per second
TPS(Transactions Per Second )
The number of transactions processed by the server per second .TPS Include a message in and a message out , Plus a database access
Average load (Load averages)
It means within unit time , The number of processes in both runnable and nondisruptive States . therefore , It includes not only the ones in use CPU The process of , It also includes waiting CPU And wait for I/O The process of .
- CPU Intensive processes , Use a large number of CPU Will cause the average load to rise , At this time, the two are the same
- I/O Intensive processes , wait for I/O It also causes the average load to rise , but CPU Usage is not necessarily high
- Wait a lot CPU The average load will also increase due to process scheduling , At this time CPU The usage rate will also be higher
……
Examples of pressure test reports
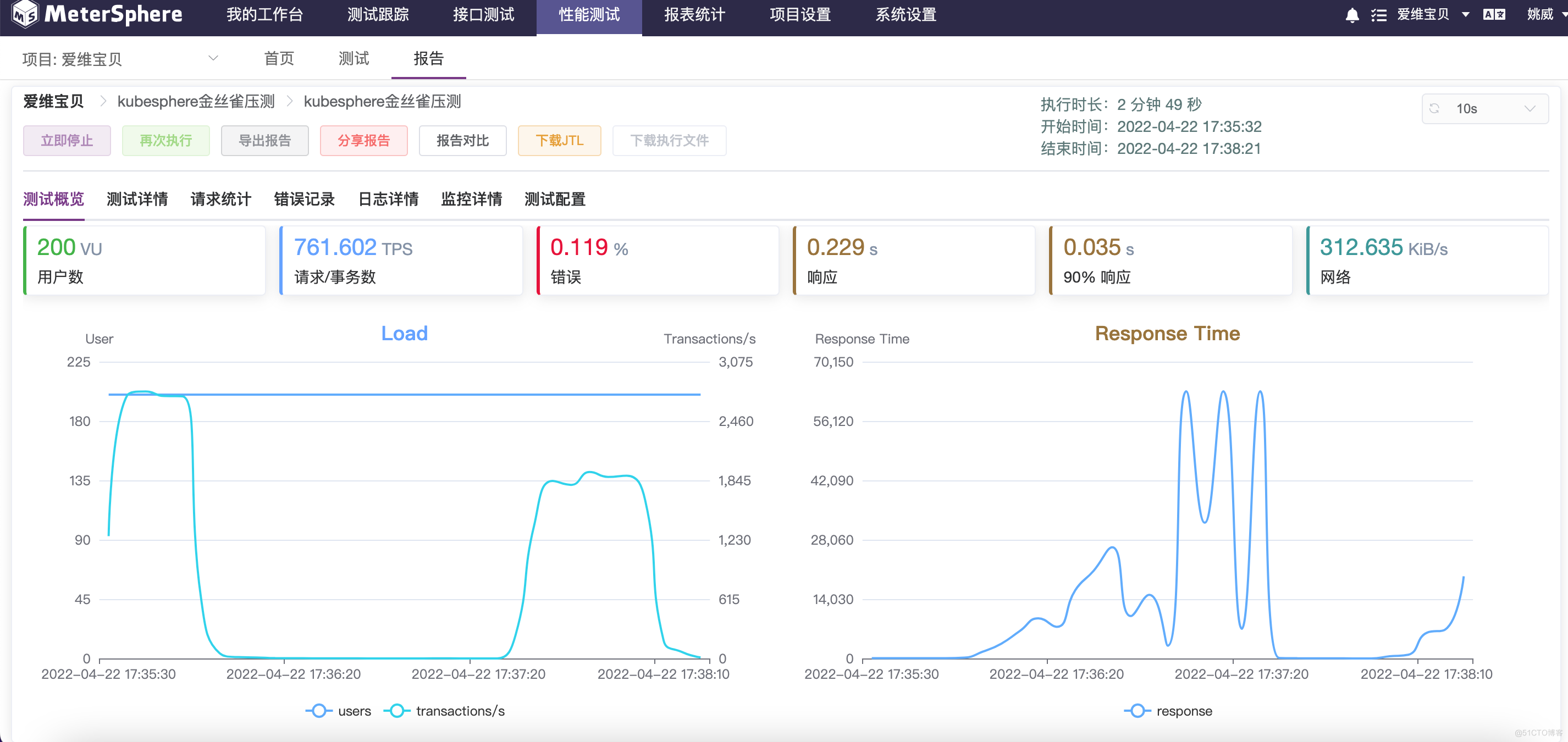
chart MeterSphere Pressure test report
3. For the technical framework 、 Knowledge of technical components
In the actual work, I found that many colleagues have different opinions about the adopted technical framework 、 The technical components are limited to understanding and basic application , But I don't know it well , Limited application , Can not play its effective value .
Common microservices in server architecture , database ( Relational type 、NoSQL), Message queue , Cloud service components, etc .
4. Understanding of technical principles
It is a great taboo to do a good job in technical work , If there is a lack of understanding of technical principles , Cause potential problems at the same time , The problem cannot be quickly located .
For example, we encountered the service unavailability problem in the opening season of a certain year , Cascading impact due to response timeout of some interfaces of the system , As a result, the cluster single server has accumulated too many TCP Concurrent connections , Accordingly, a variety of core resources of the system are exhausted . Because of this performance, colleagues directly choose to expand resources horizontally , I didn't realize that it was the slow response of the interface that caused the accumulation of concurrent connections socket Handle resource exhaustion and CPU The problem of high load caused by waiting , It wastes resources and does not solve problems .
This scenario involves
- Yes TCP and Socket Understanding of programming principles
- A long connection : It means that multiple data packets can be sent continuously on one connection , During connection hold , If no packets are sent , Both parties need to send link detection packets .
- Short connection : Short connection refers to data interaction between communication parties , Just establish a connection , When the data is sent , Disconnect the connection , That is, each connection only completes the sending of one service .
- Concurrent connections : Concurrent connection means that the client sends a request to the server and establishes TCP The sum of the connections
- ……
5. The overall view of the system
Covering system development 、 The system test 、 Service governance 、 Operation and maintenance guarantee
Remove technology development , Fault injection during system test 、 Pressure test …… Etc. drill , Automatic capacity reduction and expansion in service management 、 Fusing the drop …… Etc. drill , Monitoring in the operation and maintenance guarantee link 、 The alarm 、 Processing mechanism, etc .
6. Technical debt
Business complexity 、 Data complexity 、 Technical complexity
- In the process of requirements and business accumulation, the system architecture is complicated 、 Complexity of data architecture , System reconfiguration is required at a certain time .
- In the early stage of technology selection, the technical framework is backward , The technical framework needs to be upgraded at a certain time .
Two 、 Set a goal
The goal of the system : High performance 、 High availability 、 High expansion
1. High performance
- The performance reflects the parallel processing ability of the system , That is, as mentioned earlier Throughput( throughput ) indicators . With limited server resources , The improvement of parallel processing capability means the reduction of cost .
- Performance reflects the responsiveness of the system , That's what I mentioned earlier RT( response time ) indicators . The shorter the response time, the better the user experience , This means that the value of users is increased .
2. High availability
- Availability refers to the time when the system can normally provide services , High availability reflects that the system has high fault free operation capability .
You can imagine the impact of a service outage that supports hundreds of millions of users . It's usually used SLA( Service level agreement ) To restrain , The measure is : Usability = ( In a certain period ) Normal operation time / The total running time of the system , Generally, several are used 9 To describe the usability of the system .
| Availability | 9 The number of | Annual downtime ( minute ) | Applicable products | remarks |
|---|---|---|---|---|
| 0.999 | Three 9 | 500(8.8 God ) | General server | Test environment , Cannot be used in production environment |
| 0.9999 | four 9 | 50 | Enterprise services | Minimum requirements for production environment |
| 0.99999 | Five 9 | 5 | General carrier grade services | Large mall level applications |
| 0.999999 | six 9 | 0.5 | More demanding carrier level services | Financial grade server |
3. High expansion
- It indicates the expansion ability of the system , During peak traffic periods, capacity expansion needs to be completed in a short time without interrupting existing services , Smoothly and stably undertake peak flow .
In our business scenarios, such as : The opening season and hot operations
- High scalability needs to be considered : Own application service cluster , database 、 cache 、 Message queue and other middleware , Cloud server 、 bandwidth 、 Third parties such as load balancers rely on . When the concurrency level reaches a certain critical point , Each of the above may become a bottleneck for expansion .
3、 ... and 、 Practice
1. High performance practices
1.1 cache
- Multi level cache : Use CDN、 Local cache 、 Distributed cache caches static data or dynamic data with low update frequency . At the same time, pay attention to the hotspots in the cache scene key、 Cache avalanche ( Cache penetration 、 Cache breakdown 、 Cache concurrency ) Dealing with data consistency and other problems .
- Cache preheating : Warm up data to local cache or distributed cache in advance by asynchronous task .
- Precomputation : For example, non real-time personalized recommendation scenarios , You can cache the recommended pages calculated in advance , When a user logs in, he or she can directly obtain .
1.2 database
- The optimization of database, table and index of relational database .
- With the help of search engine technology ( Such as Elasticsearch) Solve complex query problems .
- Use of new high-performance distributed database , such as HBase、 ClickHouse etc. .
1.3 Traffic management
- Cluster deployment , Automatically shrink and expand capacity through load balancing mechanism , Reduce single service pressure .
- Cut the peak and fill the valley of the flow , adopt MQ( Message queue ) Take the flow .
1.4 Procedure and architecture
- Concurrent processing , Multithreading will be serialized through .
- Asynchronism , Passing secondary processes through multithreading 、MQ、 Even delay tasks for asynchronous processing .
- Reduce IO frequency , For example, batch read and write of database and cache 、RPC Batch interface call of .
- Reduce network transmission or IO The size of the data packet when , Including the use of lightweight communication protocols 、 The right data structure 、 Reduce cache key Size 、 Compressed cache value etc. .
- The use of various pooling technologies , Reasonable setting of pool size , Include HTTP Request pool 、 Thread pool ( consider CPU Intensive or IO Set the core parameters intensively )、 Database and Redis Connection pool, etc .
- Program logic optimization , Adopt more efficient algorithms .
- Lock selection , Read more and write less with optimistic lock , Or consider reducing lock conflicts through a smaller granularity segmented lock .
- JVM Optimize ,GC The choice of algorithm, etc , Reduce... As much as possible GC Frequency and time .
2. High availability practices
2.1 Service and traffic management
- For stateless Services : When the current node fails, quickly use the load balancing component or service governance framework to switch to another available node .
- For stateful Services : Adopt the active standby or hot standby scheme to implement the failover . such as MySQL The master-slave switch of 、Redis Sentinels and Cluster Cluster pattern 、MongoDB The replica set mode of is the same as Sharding Pattern .
- Interface level : Reasonable timeout settings 、 Retrial strategy and idempotent design .
- Service failure and degradation : To ensure high availability of core services , Non core services can be sacrificed , Fuse if necessary .
- Current limiting treatment : Directly reject or return the error code to the request that exceeds the processing capacity of the system .
For service degradation and flow restriction , Note that the client also needs to be designed for fault tolerance , Minimize the impact on the user experience
- MQ( Message queue ): Message reliability guarantee , Include producer The retrying mechanism of the client 、broker Side persistence 、consumer Terminal ack Mechanism, etc .
Components and technical framework that may be involved in the above contents :
- Load balancing component : Such as nginx、 Public cloud elastic load service, etc ;
- Service governance framework : Such as Dubbo、Spring Cloud、K8s + Service Mesh(Istio)
2.2 Operation, maintenance and monitoring
- Fault injection and disaster recovery drill : Deliberately create system failure , Test the high availability of the system .
- Reduce release risk : Blue and green deployment 、 Rolling deployment 、 The canary ( Grayscale ) Release .
- Monitoring alarm : Build a comprehensive monitoring and alarm system at the infrastructure and service application levels , Such as CPU、 Memory 、 disk 、 Network monitoring alarm , as well as Web The server 、JVM、 database 、 Monitoring alarms of various middleware and business application indicators .
3. Highly scalable practices
3.1 Business layer split : Microservice architecture
3.1.1 Domain Driven Design (DDD) To split the microservices in the business dimension
Business domain modeling
According to the process or function boundary , Preliminary division of subdomain boundaries , The sub domain is divided into general sub domain and core sub domain . Carry out the event storm in the sub domain , Find the boundary context boundary , Complete domain modeling .
Business unit design
Take domain modeling as the benchmark to carry out unit design , Build a micro front-end to realize the front-end page logic of the domain model , Construct the domain logic of the domain model of the microservice implementation downward . Combine microservices and micro front ends into business units , Complete the integration 、 Testing and deployment .
Build enterprise level foreground applications
According to the enterprise business process , Combine and arrange micro front-end pages of different business units , Realize the business connectivity and integration of the business capabilities of different business units in the enterprise level foreground .
The decoupling of the middle stage and the backstage
The domain event driven mechanism is used to realize the communication between the platform and micro services , And the decoupling of business logic between the middle office and the back office , Realize data fusion .
3.1.2 A reasonable layered architecture for microservices

chart Microservice layered architecture
Reference books : 《 Middle platform architecture and Implementation —— be based on DDD Micro service 》, author Ou Chuang Xin …, Press. Mechanical industry press
3.1.3 Microservice framework ( ecology ) The choice of
Dubbo、Spring Cloud、K8s + Service Mesh Comparison of
Most of the following summaries are from CSDN user :chentian114 The article 《 Public concerns and problems of microservices in technology stack selection Dubbo、Spring Cloud and K8s Horizontal comparison 》, What our team has personally practiced is from Dubbo to turn to K8s+ServiceMesh(Istio) Technology ecology of .
- Technical practice comparison
| Dubbo | SpringCloud | K8s + ServiceMesh | |
|---|---|---|---|
| Service discovery and LB | ZK/Nacos + client | Eureka + Ribbon | K8s service |
| API gateway | N/A | Zuul/Spring Cloud Gateway | Ingress Gateway |
| Configuration Management | Diamond/Nacos | Spring Cloud Config | ConfigMaps/Secrets |
| Fusing and current limiting | Sentinel | Hystrix | HealthCheck/Probe/ServiceMesh |
| Log monitoring | ELK | ELK | EFK |
| Metrics monitor | Dubbo Admin/Monitor | Actuator/MicroMeter+Promethus | Heapster+Promethus |
| Call chain monitoring | N/A | Spring Cloud Sleuth/Zipkin | Jaeger/Zipkin |
| Application packaging | Jar/War | Uber Jar/War | Docker Image/Helm |
| Service language framework | Dubbo RPC + Java | Spring(Boot)REST + Java | frame 、 Language has nothing to do |
| Publish and schedule | N/A | N/A | kube-Scheduler |
| Auto scaling and self healing | N/A | N/A | kube-Scheduler/AutoScaler |
| Process isolation | N/A | N/A | Docker/Pod |
| Environmental management | N/A | N/A | Namespace/Authorization |
| Resource allocation | N/A | N/A | CPU/Mem limit,Namespace Quotas |
| Traffic management | N/A | N/A | ServiceMesh |
- Comparison of ecological advantages and disadvantages
| Dubbo | SpringCloud | K8s + ServiceMesh | |
|---|---|---|---|
| advantage | Ali endorsement , Mature and stable ,RPC High performance , Traffic management is more detailed | Netflix/Pivotal Recite , The community is active , Good development experience , Good abstraction and componentization | Google 、CNCF Recite , Good abstraction and componentization , The micro service ecosystem is unified and complete , Support for heterogeneous languages , The community is active |
| Insufficient | Older technology 、 Slow update ,SDK High degree of coupling , Support only Java Technology stack , Low community activity | Support only Java Technology stack , Running consumes resources | The technical threshold is high ,ServiceMesh Of sidecar The mechanism has a certain performance loss |
3.2 Split the data layer
Vertical split according to business dimension , Perform horizontal split according to data feature dimension ( Sub database and sub table )
4. Extended practice : Cloud native technology system
Please see the
Github: https://github.com/yaocoder/Architect-CTO-growth
If the access is not smooth, please refer to
Gitee: https://gitee.com/yaocoder/Architect-CTO-growth
边栏推荐
- [highlights] summary of award-winning activities of Tencent cloud documents
- How can ffmpeg streaming to the server save video as a file through easydss video platform?
- Post processing - deep camera deformation effects
- Continuous testing | key to efficient testing in Devops Era
- How to solve the problem that MBR does not support partitions over 2T, and lossless transfer to GPT
- Creation and use of unified links in Huawei applinking
- Internet of things? Come and see Arduino on the cloud
- 敏捷之道 | 敏捷开发真的过时了么?
- How to efficiently analyze online log
- go Cobra命令行工具入门
猜你喜欢

【2022国赛模拟】摆(bigben)——行列式、杜教筛

CVPR 2022 | interprétation de certains documents de l'équipe technique de meituan

Use abp Zero builds a third-party login module (I): Principles
使用 Abp.Zero 搭建第三方登录模块(一):原理篇

快速了解常用的消息摘要算法,再也不用担心面试官的刨根问底

Reading notes of returning to hometown
![[data mining] final review (sample questions + a few knowledge points)](/img/90/a7b1cc2063784fb53bb89b29ede5de.png)
[data mining] final review (sample questions + a few knowledge points)

WPF from zero to 1 tutorial details, suitable for novices on the road

手把手教你用AirtestIDE无线连接手机!

Getting started with the go Cobra command line tool
随机推荐
Concept + formula (excluding parameter estimation)
[database] final review (planning Edition)
IOMMU (VII) -vfio and mdev
Are you still working hard to select *? Then put away these skills
巴比特 | 元宇宙每日必读:618成绩已然揭晓,在这份还算满意的答卷背后,数字藏品做出了多少贡献?...
Brief introduction to cluster analysis
I enlighten a friend and my personal understanding of the six patriarchs' Tan Jing
申请MIMIC数据库失败怎么办?从失败到成功的经验分享给你~
About me, a 19 line programmer
Troubleshooting and optimization of files that cannot be globally searched by ordinary users in easydss video platform customization project
实现领域驱动设计 - 使用ABP框架 - 创建实体
我开导一个朋友的一些话以及我个人对《六祖坛经》的一点感悟
问个sql view的问题
Open source monitoring system Prometheus
The difference between apt and apt get
[day ui] affix component learning
[2022 national tournament simulation] BigBen -- determinant, Du Jiao sieve
The text to voice function is available online. You can experience the services of professional broadcasters. We sincerely invite you to try it out
What should I do if I fail to apply for the mime database? The experience from failure to success is shared with you ~
[log service CLS] Tencent cloud log service CLS accesses CDN