当前位置:网站首页>Google &huggingface| zero sample language model structure with the strongest ability
Google &huggingface| zero sample language model structure with the strongest ability
2022-06-23 14:46:00 【Zhiyuan community】
from GPT3 To Prompt, More and more people find that large models learn from zero samples (zero-shot) Has a very good performance under the setting of . This makes everyone feel AGI More and more people are looking forward to the arrival of .
But there is one thing that makes people very confused :19 year T5 adopt “ Adjustable parameter ” Find out , When designing the pre training model ,Encoder-Decoder Model structure of + MLM Mission , Downstream missions finetune The effect is the best . But in the 2202 The present of , Mainstream big models use only decoder Model structure design , such as OpenAI Of GPT series 、Google Of PaLM [1]、Deepmind Of Chinchilla [2] wait . Why is that ? Are there problems with the design of these large models ?
Today I bring an article Hugging Face and Google The article . This article is related to T5 The ideas in the experiment are similar , Through a lot of comparative design , Get a big conclusion : If it's for the model zero-shot Generalization ability ,decoder structure + Language model tasks are best ; If you multitask finetuning,encoder-decoder structure + MLM Best mission .
Besides finding the best way to train , Through a large number of experiments , Also found the best and most cost-effective training methods . Only one ninth of the training calculation is required !
Thesis title :
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Thesis link :
https://arxiv.org/abs/2204.05832
边栏推荐
- [deeply understand tcapulusdb technology] tmonitor system upgrade
- Binding events of wechat applet in wx:for
- 小米为何深陷芯片泥潭?
- Helm 基础入门 Helm介绍与安装
- What is the working status of software testing with a monthly salary of 7500
- 2021-04-15
- The well-known face search engine provokes public anger: just one photo will strip you of your pants in a few seconds
- Google Earth engine (GEE) -- Comparative Case Analysis of calculating slope with different methods
- How to make food nutrition label
- [compréhension approfondie de la technologie tcaplusdb] données de construction tcaplusdb
猜你喜欢

Distributed database uses logical volume to manage storage expansion

百万奖金等你来拿,首届中国元宇宙创新应用大赛联合创业黑马火热招募中!
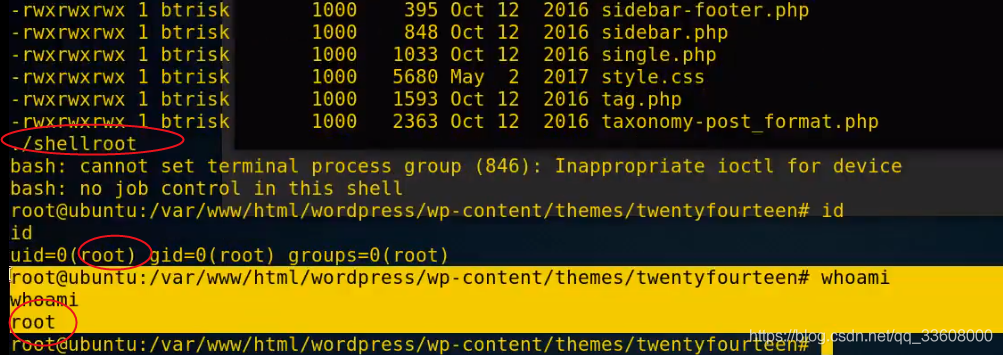
Penetration test - right raising topic

Instructions for laravel8 Beanstalk

Thinking and Practice on Quality Standardization (suitable for product, development, testing and management post learning)

Soaring 2000+? The average salary of software testing in 2021 has come out, and I can't sit still

信贷产品额度定价场景下的回归模型效果评估

2021-04-15

【DataHub】LinkedIn DataHub学习笔记
Unity realizes the function of playing Ogg format video
随机推荐
Soaring 2000+? The average salary of software testing in 2021 has come out, and I can't sit still
[in depth understanding of tcapulusdb technology] tcapulusdb construction data
知名人脸搜索引擎惹众怒:仅需一张照片,几秒钟把你扒得底裤不剩
From the establishment to the actual combat of the robotframework framework, I won't just read this learning note
How to ensure long-term stable operation of EDI system
2021-05-22
微信小程序引导用户添加小程序动画页
2021-06-03
Thinking and Practice on Quality Standardization (suitable for product, development, testing and management post learning)
Babbitt | metauniverse daily must read: meta, Microsoft and other technology giants set up the metauniverse Standards Forum. Huawei and Alibaba joined. NVIDIA executives said that they welcomed partic
大厂架构师:如何画一张大气的业务大图?
狂奔的极兔,摔了一跤
Gold three silver four, busy job hopping? Don't be careless. Figure out these 12 details so that you won't be fooled~
Use of pyqt5 tool box
Binding events of wechat applet in wx:for
Cause analysis and intelligent solution of information system row lock waiting
SAP inventory gain / loss movement type 701 & 702 vs 711 & 712
[deeply understand tcapulusdb technology] tmonitor background one click installation
Mysql数据库---日志管理、备份与恢复
Un million de bonus vous attend, le premier concours d'innovation et d'application de la Chine Yuan cosmique Joint Venture Black Horse Hot Recruitment!